







本文依据《数据挖掘概念与技术》第三版(韩家炜)中的DBScan算法来实现的,其伪代码如下(截图):

因为实验的需要,本文用经纬度数据作为测试数据,该距离计算参考了博主的文章(https://blog.csdn.net/xiejm2333/article/details/73297004);如需要直角坐标数据,则将dbEpsilon函数中的两点距离距离计算公式直接改为欧拉公式即可。
算法中的数据结构说明:
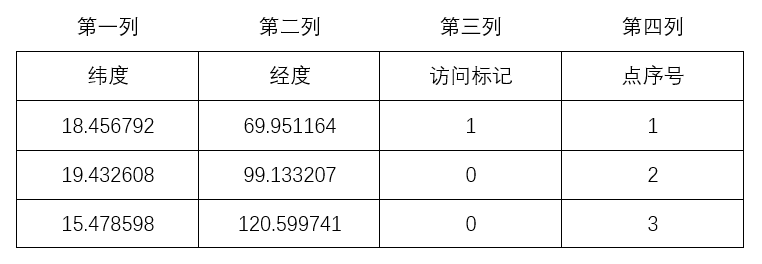
实验所用测试数据地址:链接: https://pan.baidu.com/s/1JF74dKSWDum83XMozkjlPA 密码: 24fw
聚类结果保存在
C_all中,并以cell的形式对各簇加以区分;同时,cluster.txt也保存了结果,以0 0 0 0 加以区分各簇
算法的主程序:
clc;
clear;
%设定半径,公里
epsilon=100;
%邻域密度阈值,发生次数
minPts=10;
%读取数据文件,生成点矩阵
fileID = fopen('D:\matlabFile\GTD\gtd.txt');
DS=textscan(fileID,'%f %f');
fclose(fileID);
%将cell类型转换为矩阵类型,这里的数据二维坐标点,附加其类型属性
%组合DS中的前两列,由cell转换为矩阵
Dataset=cat(2,DS{1},DS{2});
%删除空值,默认值为999
index=find(Dataset(:,1)==999);
Dataset(index,:)=[];
countD=size(Dataset,1);
%零矩阵
temp=zeros(countD,1);
%增加第三列,全部置位0,代表unvisited,如果为1,代表visited,如果为2,代表噪声
Dataset=cat(2,Dataset,temp);
%生成整数序列,与每一个点对应
sequence=zeros(1,countD);
sequence=(1:1:countD);
%增加第四列,给坐标添加序号
Dataset=cat(2,Dataset,sequence');
%该临时数据集包含所有标记为unvisited的点
Dataset_temp=Dataset;
%绘制初始点图
% scatter(Dataset(:,1),Dataset(:,2),'filled');
%簇的集合
C_all=cell(1,1);
%所有符合条件的点集合,集中存储,方便查询
C=zeros(1,4);
flag=0;
while flag==0
%判断Dataset是否遍历完毕
if size(Dataset_temp,1)~=0
%随机选择一个对象p,在剩余的Dataset中
randC=randperm(size(Dataset_temp,1),1);
p=Dataset_temp(randC,:);
%将Dataset_temp中的这个点剔除
Dataset_temp(randC,:)=[];
%将p从Dataset中剔除,之后要重新加入,保证Dataset始终是完整的
Dataset_1=Dataset;
%在原数据库中找到p,标记为visited
Dataset(p(1,4),3)=1;
%标记p为visited
p(1,3)=1;
Dataset_1(p(1,4),:)=[];
%寻找在半径范围之内的对象
%存放临时对象
N=dbEpsilon(p,Dataset_1,epsilon);
%新建的簇,用来保存符合条件的p
C_temp=p;
%判断p邻域内对象数量是否满足minPts的要求
if size(N,1)>=minPts
%遍历临时对象集N,寻找新的对象
flag_1=0;
count=0;
while flag_1==0
%如计数器与N的行数相同,则结束循环
if count==size(N,1)
flag_1=1;
else
count=count+1;
for i=1:size(N,1)
%判断抽取出的对象是否是unvisited,否则标记为visited
if N(i,3)==0
t=N(i,:);
t(1,3)=1;
N(i,3)=1;
Dataset(t(1,4),3)=1;
%Dataset_temp中删除标记为visited的点,使得Dataset_temp里的数据始终为unvisited
ind1=find(Dataset_temp(:,4)==t(1,4));
Dataset_temp(ind1,:)=[];
%将抽取的对象从Dataset_2中剔除
Dataset_2=Dataset_1;
ind2=find(Dataset_2(:,4)==t(1,4));
Dataset_2(ind2,:)=[];
%寻找所抽取对象epsilon范围内的对象
N_temp=dbEpsilon(t,Dataset_2,epsilon);
%判断抽取对象邻域范围内的对象数量是否满足minPts条件
if size(N_temp,1)>=minPts;
%判断N_temp中点是否已经存在于N,如不存在,则加入
for j=1:size(N_temp,1)
ind3=find(N(:,4)==N_temp(j,4));
if isempty(ind3)
N=cat(1,N,N_temp(j,:));
end
end
end
%判断抽取对象是否已经是簇的成员
ind4=find(C(:,4)==t(1,4));
if isempty(ind4)
%将t添加到点集合
C=cat(1,C,t);
%判断抽取对象是否已经是簇C_temp的成员
ind5=find(C_temp(:,4)==t(1,4));
if isempty(ind5)
C_temp=cat(1,C_temp,t);
end
end
end
end
end
end
if size(C_temp,1)>minPts
C_all{size(C_all,1)+1,1}=C_temp;
end
else
%在原Dataset中找到p,标记为噪声
ind6=find(Dataset(:,4)==p(1,4));
Dataset(ind6,3)=2;
end
else
flag=1;
end
end
C_all(1,:)=[];
FID=fopen('cluster.txt','wt');
for k=1:size(C_all,1)
for i=1:size(C_all{k,1},1)
for j=1:size(C_all{k,1},2)-1
fprintf(FID, '%f ', C_all{k,1}(i,j));
end
fprintf(FID,'\n');
end
fprintf(FID, '%f %f %f %f ', [0 0 0 0]);
fprintf(FID,'\n');
end
fclose(FID);
function result=dbEpsilon(p_t,Dataset,epsilon)
N=zeros(1,4);
%地球半径,单位:公里
R=6378.137;
%角度转换成弧度
p=[rad(p_t(1,1)),rad(p_t(1,2))];
for i=1:size(Dataset,1)
%计算两个对象的欧式距离
q_temp=Dataset(i,:);
q=[rad(q_temp(1,1)),rad(q_temp(1,2))];
%两点纬度之差
lat=p(1,1)-q(1,1);
%两点经度之差
lon=p(1,2)-q(1,2);
%计算两点之间的距离
dist=2*asin(sqrt((sin(lat/2.0))^2+cos(p(1,1))*cos(q(1,1))*(sin(lon/2.0))^2));
%弧长乘以地球半径
dist=dist*R;
if dist<=epsilon
N=cat(1,N,q_temp);
end
end
%删除第一行空值
N(1,:)=[];
result=N;
end
function result=rad(value)
result=value * pi/180.0;
end














 1622
1622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









