







 本文介绍了关联分析的概念,包括频繁项集和关联规则,并通过Apriori算法详细解释了如何在Python中实现关联规则挖掘。以沃尔玛的'啤酒与尿布'故事为背景,阐述了Apriori算法的工作原理,如支持度和置信度计算,以及算法的步骤。最后,给出了一个简单的数据集,展示了Apriori算法的运行结果,包括生成的频繁项集和满足最低可信度的关联规则。
本文介绍了关联分析的概念,包括频繁项集和关联规则,并通过Apriori算法详细解释了如何在Python中实现关联规则挖掘。以沃尔玛的'啤酒与尿布'故事为背景,阐述了Apriori算法的工作原理,如支持度和置信度计算,以及算法的步骤。最后,给出了一个简单的数据集,展示了Apriori算法的运行结果,包括生成的频繁项集和满足最低可信度的关联规则。
对于一个算法的讲解,我的习惯是从一个比较小的例子或者从背景开始讲起,所以前面是引入,对机器学习有一点了解的可以跳过前奏,直接看算法部分,希望我的讲解对大家有所帮助:
- 案例
-“啤酒与尿布”的故事产生于20世纪90年代的美国沃尔玛超市中,沃尔玛的超市管理人员分析销售数据时发现了一个令人难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中,这种独特的销售现象引起了管理人员的注意,经过后续调查发现,这种现象出现在年轻的父亲身上。

那么,这个结论是如何得出的呢?下面我们先简单介绍几个相关概念
关联分析:从大规模数据集中寻找物品间的隐含关系被称作关联分析或者关 联规则学习。这些关系可以有两种形式:频繁项集或者关联规则。
频繁项集:经常出现在一块的物品的集合,也就是所有支持度大于最小支持度的项集称为频繁项集。
关联规则:暗示两种物品之间可能存在很强的关系,形如A->B的表达式,A、B均为某子集,且A与B的交集为空。
通过一个简单的例子认识一下概念:
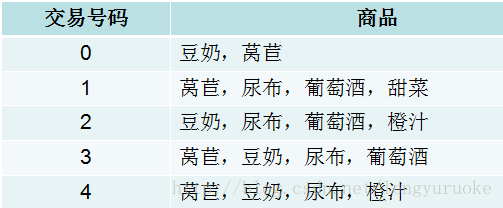
{葡萄酒,尿布,豆奶}这个集合就是频繁项集。尿布—>葡萄酒就是一个关联规则。
寻找频繁项集时,频繁定义是什么???
再引入两个概念
支持度:定义为数据集中包含该项集的记录所占比例。
{豆奶}的支持度为4/5。
{豆奶,尿布}的支持度为3/5。、
置信度(可信度):针对一条诸如{尿布}—>{葡萄酒}的关联规则来定义的。
这条规则定义为支持度({尿布,葡萄酒})/支持度({尿布})=(3/5)/(4/5)=75%
支持度和可信度是用来量化关联分析是否成功的方法,那么,假设想要找到支持度大于某个值的所有项集,如何做???
(最简单的办法就是生成物品所有可能清单,对每一种组合计算其频繁程度。但当物品种类众多时呢???)
下面我们正式进入Apriori算法:
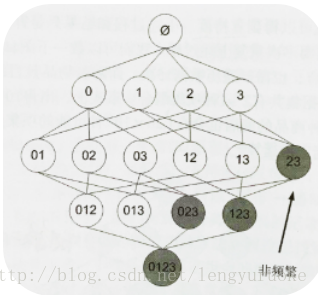
原理: 如果某个项集是频繁的,那么它的所有子集也是频繁的,换句话说,如果一个项集是非频繁集,那么它的所有超集也是非频繁的。
图中,若已知阴影项集{2,3}是非频繁的。利用Apriori原理,项集{0,2,3},{1,2,3},{0,1,2,3}也是非频繁的。也就是说,一旦计算出了{2,3}的支持度,知道它是非频繁集厚,就不需要再计算{0,2,3},{1,2,3},{0,1,2,3}的支持度了,避免了项集数目的指数增长。
算法流程图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









