






既然是讲原理,那些
“
为什么需要
RAID6”
、
“RAID6
的优势
”
等内容就都省去了。直接进入枯燥无趣的理论。
一、 RAID5 和 XOR 运算
为了照顾初学者,还是先把相关基本概念介绍一下,老手可以跳过这部分直接看下面。(别低头!是看本帖下面,想些什么呐~)
XOR 运算是数理逻辑的基本运算之一,在课本上的符号是一个圆圈里面一个加号。实在懒得用插入符号功能,大家就凑合着看吧。
两个数字之间的 XOR 运算定义是:
1 XOR 1 = 0
1 XOR 0 = 1
0 XOR 1 = 1
0 XOR 0 = 0
(忽然想起试行新车牌的时候,有些深圳人用三位二进制数标记性别。 010 是男的, 101 是女的。 Sorry ,扯远了。)
多个数字 XOR 的时候,有两个特点:
A )结果与运算顺序无关。也就是 (a XOR b) XOR c = a XOR (b XOR c) 。
B )各个参与运算的数字与结果循环对称。如果 a XOR b XOR c = d ,那么 a = b XOR c XOR d ; b = a XOR c XOR d ; c = a XOR b XOR d 。
磁盘阵列中的 RAID5 之所以能够容错,就是利用了 XOR 运算的这些特点。上面例子中的 a 、 b 、 c 、 d 就可以看作是四颗磁盘上的数据,其中三个是应用数据,剩下一个是校验。碰到故障的时候,甭管哪个找不到了,都可以用剩下的三个数字 XOR 一下算出来。
在实际应用中,阵列控制器一般要先把磁盘分成很多条带(英文叫 Stripe ,注意不是 Stripper ),然后再对每组条带做 XOR 。
见下面第一个图。
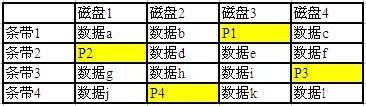
P1 = 数据 a XOR 数据 b XOR 数据 c
P2 = 数据 d XOR 数据 e XOR 数据 f
P3 = 数据 g XOR 数据 h XOR 数据 i
P4 = 数据 j XOR 数据 k XOR 数据 l
扫盲部分就讲这么多,再不懂就 google 吧,满山遍野都是 RAID5 算法的介绍。
二、 RAID6 和 Reed-Solomon 编码
本来想写成 “ 李德 - 所罗门编码 ” ,但那样就不方便大家一边看帖子一边 google 了。
Reed-Solomon 编码是通讯领域中经常碰到的一个算法,已经有 15 年以上的历史了。(靠!讲存储嘛,跟通讯有个鸟关系?)
其实很多校验算法都是通讯领域最先研究出来,然后才应用到其他领域的。前面说到的 XOR 算法对一组数据只能产生一个校验,搞通讯的工程师们觉得不够可靠,于是就研究出很多能对一组数据产生多个校验的算法。 Reed-Solomon 编码是其中应用最广泛的一个,咱们以前经常用的 ADSL 、 xDSL 、高速 Modem 都有采用。后来手机、卫星电视、数字电视、 CD 唱片、 DVD 、条码系统、还有 …… (有完没完!说存储呢!)连高级点儿的服务器内存也用这个算法做校验和纠错。(总算跟存储沾上点儿边~)
现在存储的工程师也觉得 RAID5 中只能容忍一颗磁盘离线不够理想,需要一种容忍多颗磁盘离线的技术,自然就会想到 Reed-Solomon 编码啦。把这种算法应用到存储中,就可以让 N 颗磁盘的空间装应用数据, M 颗磁盘的空间装校验码(对一组 N 个数据生成 M 个校验,但实际上校验码是分散在所有磁盘上的),这样只要离线的磁盘不大于 M 颗,数据就不会丢失。
Reed-Solomon 编码理论中有一个公式:
N + M + 1 = 2 的 b 次方(在电脑里写公式真是麻烦!)
其中 b 是校验字的位数。(校验字是生成校验过程需要用的一个东东,不是最后的校验码。)举例来说,如果用 8 位的字节做校验字,那么 M + N = 255 ,而 RAID6 是特指 M = 2 ,这样 N = 253 。
就是说,用 8 位字节做校验字的话,理论上一个 RAID6 的磁盘组可以容下 253 颗磁盘。
当然啦,实际应用中,太多的磁盘一起做运算会严重影响性能,所以阵列控制器和芯片的设计者都会把磁盘组的容量限制在 16 颗左右。
(做了这么多无聊算术题,还是没提 RAID6 到底是啥!)
喂!喂!别走啊,很快就讲到 RAID6 的实现啦。
卖了这么多关子,实在是因为 RAID6 这个概念所指的意义太混乱。从功能上讲,能实现两颗磁盘掉线容错的,都叫 RAID6 。(至少我认识的销售们都这么认为。)但是实行这一功能的方式却有很多很多。(沉默 3 分钟)
真的很多!哎哟!别打啊~
Intel 的 P+Q RAID6 , NetApp 的 RAID-DP , HP 的 RAID5-DP ,还要很多实验室中的原型机都能实行这个功能。但是由于机制不同,各种所谓的 RAID6 ,其性能表现、磁盘负载分布、错误恢复方式都完全不同。
你让我从哪说起好哩?
三、基于 P+Q 的 RAID6
在 Intel 的 80333IOP 芯片中,有一个新的引擎叫 P+Q 单元,是专门用来处理 RAID6 加速的。详情请查阅 Intel 官方网站,讲座到此结束 …… (鸡蛋、西红柿、拖鞋。咦!这是谁的臭袜子?)
真当我什么都不懂啊!好,接着说。
对比 RAID5 的机制, Intel 的 P+Q RAID6 是这样写磁盘的:
见下面第二个图。
一、 RAID5 和 XOR 运算
为了照顾初学者,还是先把相关基本概念介绍一下,老手可以跳过这部分直接看下面。(别低头!是看本帖下面,想些什么呐~)
XOR 运算是数理逻辑的基本运算之一,在课本上的符号是一个圆圈里面一个加号。实在懒得用插入符号功能,大家就凑合着看吧。
两个数字之间的 XOR 运算定义是:
1 XOR 1 = 0
1 XOR 0 = 1
0 XOR 1 = 1
0 XOR 0 = 0
(忽然想起试行新车牌的时候,有些深圳人用三位二进制数标记性别。 010 是男的, 101 是女的。 Sorry ,扯远了。)
多个数字 XOR 的时候,有两个特点:
A )结果与运算顺序无关。也就是 (a XOR b) XOR c = a XOR (b XOR c) 。
B )各个参与运算的数字与结果循环对称。如果 a XOR b XOR c = d ,那么 a = b XOR c XOR d ; b = a XOR c XOR d ; c = a XOR b XOR d 。
磁盘阵列中的 RAID5 之所以能够容错,就是利用了 XOR 运算的这些特点。上面例子中的 a 、 b 、 c 、 d 就可以看作是四颗磁盘上的数据,其中三个是应用数据,剩下一个是校验。碰到故障的时候,甭管哪个找不到了,都可以用剩下的三个数字 XOR 一下算出来。
在实际应用中,阵列控制器一般要先把磁盘分成很多条带(英文叫 Stripe ,注意不是 Stripper ),然后再对每组条带做 XOR 。
见下面第一个图。
P1 = 数据 a XOR 数据 b XOR 数据 c
P2 = 数据 d XOR 数据 e XOR 数据 f
P3 = 数据 g XOR 数据 h XOR 数据 i
P4 = 数据 j XOR 数据 k XOR 数据 l
扫盲部分就讲这么多,再不懂就 google 吧,满山遍野都是 RAID5 算法的介绍。
二、 RAID6 和 Reed-Solomon 编码
本来想写成 “ 李德 - 所罗门编码 ” ,但那样就不方便大家一边看帖子一边 google 了。
Reed-Solomon 编码是通讯领域中经常碰到的一个算法,已经有 15 年以上的历史了。(靠!讲存储嘛,跟通讯有个鸟关系?)
其实很多校验算法都是通讯领域最先研究出来,然后才应用到其他领域的。前面说到的 XOR 算法对一组数据只能产生一个校验,搞通讯的工程师们觉得不够可靠,于是就研究出很多能对一组数据产生多个校验的算法。 Reed-Solomon 编码是其中应用最广泛的一个,咱们以前经常用的 ADSL 、 xDSL 、高速 Modem 都有采用。后来手机、卫星电视、数字电视、 CD 唱片、 DVD 、条码系统、还有 …… (有完没完!说存储呢!)连高级点儿的服务器内存也用这个算法做校验和纠错。(总算跟存储沾上点儿边~)
现在存储的工程师也觉得 RAID5 中只能容忍一颗磁盘离线不够理想,需要一种容忍多颗磁盘离线的技术,自然就会想到 Reed-Solomon 编码啦。把这种算法应用到存储中,就可以让 N 颗磁盘的空间装应用数据, M 颗磁盘的空间装校验码(对一组 N 个数据生成 M 个校验,但实际上校验码是分散在所有磁盘上的),这样只要离线的磁盘不大于 M 颗,数据就不会丢失。
Reed-Solomon 编码理论中有一个公式:
N + M + 1 = 2 的 b 次方(在电脑里写公式真是麻烦!)
其中 b 是校验字的位数。(校验字是生成校验过程需要用的一个东东,不是最后的校验码。)举例来说,如果用 8 位的字节做校验字,那么 M + N = 255 ,而 RAID6 是特指 M = 2 ,这样 N = 253 。
就是说,用 8 位字节做校验字的话,理论上一个 RAID6 的磁盘组可以容下 253 颗磁盘。
当然啦,实际应用中,太多的磁盘一起做运算会严重影响性能,所以阵列控制器和芯片的设计者都会把磁盘组的容量限制在 16 颗左右。
(做了这么多无聊算术题,还是没提 RAID6 到底是啥!)
喂!喂!别走啊,很快就讲到 RAID6 的实现啦。
卖了这么多关子,实在是因为 RAID6 这个概念所指的意义太混乱。从功能上讲,能实现两颗磁盘掉线容错的,都叫 RAID6 。(至少我认识的销售们都这么认为。)但是实行这一功能的方式却有很多很多。(沉默 3 分钟)
真的很多!哎哟!别打啊~
Intel 的 P+Q RAID6 , NetApp 的 RAID-DP , HP 的 RAID5-DP ,还要很多实验室中的原型机都能实行这个功能。但是由于机制不同,各种所谓的 RAID6 ,其性能表现、磁盘负载分布、错误恢复方式都完全不同。
你让我从哪说起好哩?
三、基于 P+Q 的 RAID6
在 Intel 的 80333IOP 芯片中,有一个新的引擎叫 P+Q 单元,是专门用来处理 RAID6 加速的。详情请查阅 Intel 官方网站,讲座到此结束 …… (鸡蛋、西红柿、拖鞋。咦!这是谁的臭袜子?)
真当我什么都不懂啊!好,接着说。
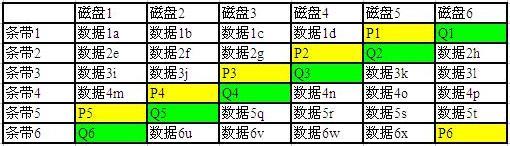
对比 RAID5 的机制, Intel 的 P+Q RAID6 是这样写磁盘的:
见下面第二个图。
P
和
Q
都是横的。
看这个图。
P1 =数据 1a XOR 数据 1b XOR 数据 1c XOR 数据 1d
Q1 = 1a 的 GF XOR 1b 的 GF XOR 1c 的 GF XOR 1d 的 GF
另外, M>2 时,一般叫 RAIDn ,只有当 M = 2 的时候才叫 RAID6 。
看这个图。
P1 =数据 1a XOR 数据 1b XOR 数据 1c XOR 数据 1d
Q1 = 1a 的 GF XOR 1b 的 GF XOR 1c 的 GF XOR 1d 的 GF
另外, M>2 时,一般叫 RAIDn ,只有当 M = 2 的时候才叫 RAID6 。
这里每个条带中的 P ,跟 RAID5 里面的 P 意义完全一样,就是同一条带中除 Q 以外其它数据的 XOR 运算结果。
而 Q 呢,就是理解这个技术的关键所在了。
咳~咳~听好了。
Q 是同一条带中各数据的女朋友们进行 XOR 运算的结果。
别翻白眼啊,书上就是这么写的啊!哦,还是英文的,我翻译给你听。
“ 把条带中每个数据分别 GF 一下,然后这些结果再 XOR ,就得到 Q 。 ”
(大哥,你到底懂不懂啊! GF 是 Galois Field 的缩写,是法国著名数学家伽罗瓦发明的一种数学变换。)
哦,想起来了。伽罗瓦嘛,发明群论的那个。生于法国大革命前,二十出头就英年早逝,还是为了个姑娘跟人决斗被打死的。最著名的成果就是给 3 次以上方程判了死刑。是我人生第二偶像啊 ……
(唐僧!)
这个 GF 变换呢,就是这个淘气的伽同学当年为了逃避老师点名,而发明的一种教室换座位方法。按照这种方法,每个人都不会坐在自己的座位上,而且每个人都肯定会有座位。而且任意个同学的座位号进行 XOR 运算之后,仍然跑不出这个教室里的座位号。
(这个伽同学好像很无聊噢!没办法,人家聪明嘛!)
扯太远啦!回到正题。
在 Intel 80333IOP 中存着两个表格,分别对应 GF 正向变换和反向变换。任何一个 8 位二进制数,都可以直接在表格中查到对应的 GF 变换结果。(我还是想把这个结果说成是源数据的女朋友~)
这两个表格分别在 Intel 80333IOP 研发手册的第 445 页和 446 页,不过我估计大部分人会懒得去看。也是,看了又能怎么样呢?反正 Intel 已经把那玩意固化到芯片里了。
哇!都半夜 2 点了,说完 P+Q RAID6 的恢复,我要先 zZZ…… 了。
如果一颗磁盘掉线,根本不需要 Q 用 P 直接就搞定了,跟 RAID5 一样。
如果两颗磁盘掉线,又分做两种情况:
A )坏的地方有 Q 。这种情况跟 RAID5 坏一颗磁盘一样,用 XOR 就恢复了。
B )坏的地方没有 Q 。用 GF 变换加 XOR 一起搞定。
结合上面表格的例子,如果磁盘 5 和磁盘 6 掉线。那条带 1 和条带 2 就属于情况 A ;而条带 3 、 4 、 5 和 6 属于情况 B 。
上回书说到
P+Q
的
RAID6
在
Intel
芯片里的实现。
其实 P+Q 只是一种算法, Intel IOP 里面的硬件加速引擎并不是必须的。有一些产品就采用了 PowerPC 等不含 P+Q 引擎的 CPU ,一样不耽误 P+Q RAID6 功能。
GF 转换表在软件里完成就是了。(不敢提女朋友的事了,怕 Host 说我~)
四、准 RAID6 技术
除了 P+Q RAID6 ,还要好多种办法可以实现对两颗磁盘掉线的容错。
Billylee 提供的 Intel 讲义中就提到一种 Dual-XOR 算法,这种方法就是取横向和斜向两个方向进行 XOR 运算,这样每个应用数据都在两个校验中留下痕迹,当两颗磁盘掉线时,就可以恢复数据。
但是 Dual-XOR 的恢复工作异常复杂艰苦,并不实用。很多技术人员研究这种算法的意义,完全是把它当作未经优化的原型思想。
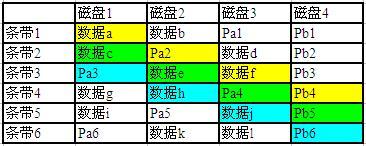
如图, Pa 是横向的校验,跟 RAID5 完全一样:
Pa1 = 数据 a XOR 数据 b
Pa2 = 数据 c XOR 数据 d
…………
Pa6 = 数据 k XOR 数据 l
Pb 是斜向校验,定义为:
Pb4 = 数据 a XOR Pa2 XOR 数据 f
Pb5 = 数据 c XOR 数据 e XOR Pa4
Pb6 = Pa3 XOR 数据 h XOR 数据 j
可以看出 Dual-XOR 的校验生成过程比 P+Q 要简单,但是根据 “ 麻烦守恒定律 ” ,正向工作简单的事情,一般反向工作都会复杂。
备份和恢复一般也遵循这个规律。
(别跟我提 CDP ,那东西遵循的是广义麻烦守恒定律。每个 I/O 都打个时间标签,还都当宝贝存着不扔,这能是个不麻烦的事吗? Sorry ,又扯远了。)
当两颗磁盘掉线的时候, Dual-XOR 的算法只能支持逐个数据块的恢复,而且不同条带之间还要共同参与计算。
比如图中的磁盘 1 和 2 掉线,恢复数据 e 的时候,就要至少动用到数据 f 、 Pb3 、 Pa4 和 Pb5 。而数据 c 和 Pa3 的恢复还要依赖数据 e 的恢复。
总之恢复起来是件贼头痛的事情!
其实 P+Q 只是一种算法, Intel IOP 里面的硬件加速引擎并不是必须的。有一些产品就采用了 PowerPC 等不含 P+Q 引擎的 CPU ,一样不耽误 P+Q RAID6 功能。
GF 转换表在软件里完成就是了。(不敢提女朋友的事了,怕 Host 说我~)
四、准 RAID6 技术
除了 P+Q RAID6 ,还要好多种办法可以实现对两颗磁盘掉线的容错。
Billylee 提供的 Intel 讲义中就提到一种 Dual-XOR 算法,这种方法就是取横向和斜向两个方向进行 XOR 运算,这样每个应用数据都在两个校验中留下痕迹,当两颗磁盘掉线时,就可以恢复数据。
但是 Dual-XOR 的恢复工作异常复杂艰苦,并不实用。很多技术人员研究这种算法的意义,完全是把它当作未经优化的原型思想。
如图, Pa 是横向的校验,跟 RAID5 完全一样:
Pa1 = 数据 a XOR 数据 b
Pa2 = 数据 c XOR 数据 d
…………
Pa6 = 数据 k XOR 数据 l
Pb 是斜向校验,定义为:
Pb4 = 数据 a XOR Pa2 XOR 数据 f
Pb5 = 数据 c XOR 数据 e XOR Pa4
Pb6 = Pa3 XOR 数据 h XOR 数据 j
可以看出 Dual-XOR 的校验生成过程比 P+Q 要简单,但是根据 “ 麻烦守恒定律 ” ,正向工作简单的事情,一般反向工作都会复杂。
备份和恢复一般也遵循这个规律。
(别跟我提 CDP ,那东西遵循的是广义麻烦守恒定律。每个 I/O 都打个时间标签,还都当宝贝存着不扔,这能是个不麻烦的事吗? Sorry ,又扯远了。)
当两颗磁盘掉线的时候, Dual-XOR 的算法只能支持逐个数据块的恢复,而且不同条带之间还要共同参与计算。
比如图中的磁盘 1 和 2 掉线,恢复数据 e 的时候,就要至少动用到数据 f 、 Pb3 、 Pa4 和 Pb5 。而数据 c 和 Pa3 的恢复还要依赖数据 e 的恢复。
总之恢复起来是件贼头痛的事情!
虽然
Intel
的
Dual-XOR
理论意义大于实际意义,但其改良的版本
RAID-DP
却已经被
NetApp
产品化。
NetApp
之所以喜欢这个类似
Dual-XOR
的
RAID-DP
算法,原因也很简单。
NetApp 原本用的就是 RAID4 ,而不是 RAID5 ,其算法的中心思想就是每次 I/O 只跟两颗磁盘打交道就 OK ,自然就不会在乎 RAID-DP 中很多动作都只跟两、三颗磁盘打交道。
(这个思想也许在很多 RAID5 的 Fans 看来有点奇怪,难道不是磁头越多性能就越好吗?但是人家 NetApp 这么多年的经验都集中在 WAFL 文件系统上,而 WAFL 文件系统又是专门针对这种思想优化的。所以 NetApp 对这个略有异类的思想不仅没有放弃,而且越研究越起劲。)

NetApp 原本用的就是 RAID4 ,而不是 RAID5 ,其算法的中心思想就是每次 I/O 只跟两颗磁盘打交道就 OK ,自然就不会在乎 RAID-DP 中很多动作都只跟两、三颗磁盘打交道。
(这个思想也许在很多 RAID5 的 Fans 看来有点奇怪,难道不是磁头越多性能就越好吗?但是人家 NetApp 这么多年的经验都集中在 WAFL 文件系统上,而 WAFL 文件系统又是专门针对这种思想优化的。所以 NetApp 对这个略有异类的思想不仅没有放弃,而且越研究越起劲。)
这个递归式数据恢复机制简直像在玩
RPG
游戏,但是对
WAFL
文件系统来说,却的确是最合适的选择之一。
除了 RAID-DP ,还有 X-Code 编码、 ZZS 编码、 Park 编码 …… 都可以看做是 “ 准 RAID6” 。
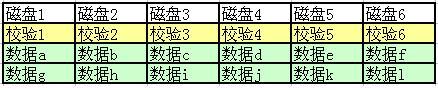
下面这个图是 X-Code 的解释

P3x = 数据 33 XOR 数据 35 XOR 数据 32
Px4 = 数据 44 XOR 数据 24 XOR 数据 54
其他的校验是啥意思,不需要一一列出来了吧~
除了 RAID-DP ,还有 X-Code 编码、 ZZS 编码、 Park 编码 …… 都可以看做是 “ 准 RAID6” 。
下面这个图是 X-Code 的解释
P3x = 数据 33 XOR 数据 35 XOR 数据 32
Px4 = 数据 44 XOR 数据 24 XOR 数据 54
其他的校验是啥意思,不需要一一列出来了吧~
X-Code
从理论上看,的确是个负载均衡、计算简单(只有
XOR
,没有类似
GF
一样的变换)、磁盘对称度很高的算法。但是实际应用还是有问题。
上面的例子是 5 颗磁盘的 X-Code 编码方式,例子中的 5 个条带是一个整体,一起处理。如果写入的数据不多,没有写满前 3 个条带,就需要在写入的同时,把未更新的数据读出来,凑齐 3x5 个数据,再一起计算校验码。
如果是 6 颗磁盘,那就要 6 个条带作为一个整体。
7 颗磁盘一个 RAID 组,就需要 7 个条带一个整体。
8 颗磁盘一个 RAID 组,就需要 8 个条带一个整体。
9 颗磁盘一个 RAID 组,就需要 9 个条带一个整体。
10 颗磁盘一个 RAID 组,就需要 10 个条带一个整体 ……
(打住!在这发帖子又没稿费,不用拼命凑字!)
总之这个算法的 “ 重复单元 ” 有点大。在实际应用中,这么大的 “ 重复单元 ” 使 X-Code 的应用面临两个问题:计算量大和空间浪费。(可能还有其他问题,比如名字太难听,总让人联想到黄色的东东。)
ZZS 也叫俄罗斯编码, bingo !猜对了,真聪明。这就是三个俄罗斯人在 1983 年提出的一种编码方式, ZZS 就是三个人名字首字母缩写,跟 S.H.E. 演唱组的命名规则一样。
与 X-Code 相比, ZZS 的 “ 重复单元 ” 就小很多 ——7 颗磁盘的时候, 3 个条带是一个整体。
人家 ZZS 论文里给出的是数学公式: n 颗磁盘的时候, (n-1)/2 个条带是一个整体。
从这个公式你应该能发现 ZZS 编码的一个要求 …… (我知道,只支持单数颗磁盘。)
嘿嘿!你错了!实际上, ZZS 算法只支持磁盘的个数为素数: ……5 、 7 、 11 、 13 、 17……
不过人家 ZZS 组合(暂时就这么称呼吧)也指出, ZZS 算法允许其中一颗磁盘上面全写 0 。这样就可以在应用中支持 4 、 6 、 10 、 12 、 16…… (素数 -1 )颗盘了。
什么?还没明白?在计算的时候,内存里虚拟一个全 0 的影子盘不就行啦!

Park 编码
Park 是名 IBM 的员工,在 Yorktown 上班。他的业余爱好是 …… ( Sorry ,又差点跑题)
相比俄国人训练有素的数学功底,美国人既没有兴趣,也没有耐心再从算法上去优化 “ 双重校验 ” 的技术。但是美国人讲求实际的思想还是挺值得称道。
这不,人家 Park 就说了, “ 研究了这么多算法,最终目的不就是坏两颗盘数据仍可恢复吗。到头来算法搞得那么复杂,还不如我的看家本领 —— 穷举法 —— 更实在。 ”
Park 同志是这样说的,也是这样做的(凝重的音乐声响起~)
他编了一个程序,让计算机帮他搜索给定磁盘数量的校验分布模式。
结果你猜怎么着,人家还真有收获。从 3 颗磁盘到 38 颗磁盘,除了 8 颗磁盘和 9 颗磁盘的情况,其他情况 Park 都找到了满足要求的校验分布模式。
什么?你问满足的是什么要求?两颗磁盘掉线数据可恢复啊。汗!
后来,一个名叫徐力浩(音)的中国人补上了 8 颗盘和 9 颗盘的校验分布表。(咱们中国人到底还是比米国人聪明那么一点点,哈~)
现在 Park 编码已经对从 3 颗到 38 磁盘的所有情况,都能给出双重校验分布方法。但是各种分布方法之间根本没有联系,所以只能在给定磁盘数量的时候,去查 Park 编码表。
Park 编码的样子都是以 3 个条带为一个 “ 重复单元 ” ,其中 1 个条带专门用来存校验,另外 2 个存数据。
全文完
上面的例子是 5 颗磁盘的 X-Code 编码方式,例子中的 5 个条带是一个整体,一起处理。如果写入的数据不多,没有写满前 3 个条带,就需要在写入的同时,把未更新的数据读出来,凑齐 3x5 个数据,再一起计算校验码。
如果是 6 颗磁盘,那就要 6 个条带作为一个整体。
7 颗磁盘一个 RAID 组,就需要 7 个条带一个整体。
8 颗磁盘一个 RAID 组,就需要 8 个条带一个整体。
9 颗磁盘一个 RAID 组,就需要 9 个条带一个整体。
10 颗磁盘一个 RAID 组,就需要 10 个条带一个整体 ……
(打住!在这发帖子又没稿费,不用拼命凑字!)
总之这个算法的 “ 重复单元 ” 有点大。在实际应用中,这么大的 “ 重复单元 ” 使 X-Code 的应用面临两个问题:计算量大和空间浪费。(可能还有其他问题,比如名字太难听,总让人联想到黄色的东东。)
ZZS 也叫俄罗斯编码, bingo !猜对了,真聪明。这就是三个俄罗斯人在 1983 年提出的一种编码方式, ZZS 就是三个人名字首字母缩写,跟 S.H.E. 演唱组的命名规则一样。
与 X-Code 相比, ZZS 的 “ 重复单元 ” 就小很多 ——7 颗磁盘的时候, 3 个条带是一个整体。
人家 ZZS 论文里给出的是数学公式: n 颗磁盘的时候, (n-1)/2 个条带是一个整体。
从这个公式你应该能发现 ZZS 编码的一个要求 …… (我知道,只支持单数颗磁盘。)
嘿嘿!你错了!实际上, ZZS 算法只支持磁盘的个数为素数: ……5 、 7 、 11 、 13 、 17……
不过人家 ZZS 组合(暂时就这么称呼吧)也指出, ZZS 算法允许其中一颗磁盘上面全写 0 。这样就可以在应用中支持 4 、 6 、 10 、 12 、 16…… (素数 -1 )颗盘了。
什么?还没明白?在计算的时候,内存里虚拟一个全 0 的影子盘不就行啦!
Park 编码
Park 是名 IBM 的员工,在 Yorktown 上班。他的业余爱好是 …… ( Sorry ,又差点跑题)
相比俄国人训练有素的数学功底,美国人既没有兴趣,也没有耐心再从算法上去优化 “ 双重校验 ” 的技术。但是美国人讲求实际的思想还是挺值得称道。
这不,人家 Park 就说了, “ 研究了这么多算法,最终目的不就是坏两颗盘数据仍可恢复吗。到头来算法搞得那么复杂,还不如我的看家本领 —— 穷举法 —— 更实在。 ”
Park 同志是这样说的,也是这样做的(凝重的音乐声响起~)
他编了一个程序,让计算机帮他搜索给定磁盘数量的校验分布模式。
结果你猜怎么着,人家还真有收获。从 3 颗磁盘到 38 颗磁盘,除了 8 颗磁盘和 9 颗磁盘的情况,其他情况 Park 都找到了满足要求的校验分布模式。
什么?你问满足的是什么要求?两颗磁盘掉线数据可恢复啊。汗!
后来,一个名叫徐力浩(音)的中国人补上了 8 颗盘和 9 颗盘的校验分布表。(咱们中国人到底还是比米国人聪明那么一点点,哈~)
现在 Park 编码已经对从 3 颗到 38 磁盘的所有情况,都能给出双重校验分布方法。但是各种分布方法之间根本没有联系,所以只能在给定磁盘数量的时候,去查 Park 编码表。
Park 编码的样子都是以 3 个条带为一个 “ 重复单元 ” ,其中 1 个条带专门用来存校验,另外 2 个存数据。
全文完
form http://bbs.dostor.com/ by pekics 译自:《Xyratex_White_Paper_Raid_6_Implementations》
注:
R6是双校验盘R5, 写速度比R5慢
R5EE是R5加冗余热备区,数据重建速度比R6快,写速度比R6更慢
R6和R5EE适合MTBF差的硬盘,如SATA
对读写密集型应用使用R10, 它具备R0的写速度,大于R1的数据保护能力, 数据重建速度只受拷贝速度的限制















 9262
9262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









