









问题描述
用tensorflow训练或者inference模型的时候,有时候会遇到运行越来越慢,最终内存被占满,导致电脑死机的问题,我们称之为内存溢出。出现这种问题很可能是因为在一个session中,graph循环建立重复的节点所导致的Lazy load问题。
举例说明
举个例子,用tensorflow循环做多次加法运算,常见的做法是:
x = tf.Variable(10, name='x')
y = tf.Variable(20, name='y')
z = tf.add(x, y)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for _ in range(10):
sess.run(z)在session开始之前graph如下:
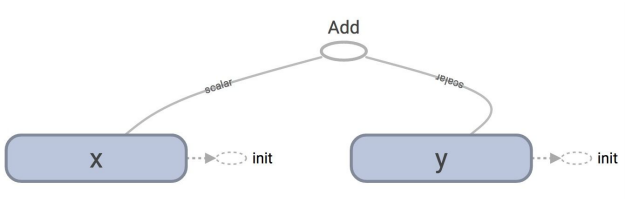
有可能有人想省点力气,把z = tf.add(x, y) 加法操作直接写到session中:
x = tf.Variable(10, name='x')
y = tf.Variable(20, name='y')
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for _ in range(10):
sess.run(tf.add(x, y)) # 只在需要时才创建节点在session开始之前graph如下:
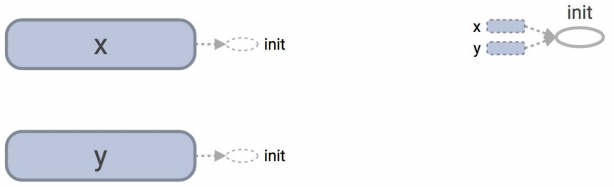
可以发现在graph中看不到加法操作了,是不是真的简化了呢?对单步操作可能是简化了,但是当遇到如本例中的循环操作时,这种将tensorflow op写到循环中的做法会产生Lazy load的问题,让你的内存逐渐被占满,为什么?
原因解释
循环结束之后我们将两种操作方法各自graph中的节点通过print (tf.get_default_graph().as_graph_def()) 命令打印出来,正常操作的graph protobuf如下:
node {
name: "Add"
op: "Add"
input: "x/read"
input: "y/read"
attr {
key: "T"
value {
type: DT_INT32
}
}
}可见graph中只有一个加法操作的节点,而第二种将加法写在session循环中的方法用同样的命令将其graph protobuf打印出来,得到的是重复的10个上述节点。所以,如果循环不是10个,而是更多个,则会导致graph中的节点越来越多,最终导致内存溢出。
解决方法
将一些算术操作通过tf.placeholder写在session外,session中通过feed_dict={x: X}填入数据。session里如果有循环,切记不要在循环中进行tf操作。















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









