







代码是 https://www.cnblogs.com/HolyShine/p/11176843.html 的。这里添加了一些更多注释。
'''
PrefixSpan算法实现
Author: 西木野Maki/holy5pb@163.com
'''
data = [
[1, 4, 2, 3],
[0, 1, 2, 3],
[1, 2, 1, 3, 4],
[2, 1, 2, 4, 4],
[1, 1, 1, 2, 3],
[0, 0, 0, 2, 3],
[0, 0, 0, 2, 3],
[0, 0, 0, 2, 3],
[0, 0, 0, 2, 3],
[0, 0, 0, 2, 3],
]
def rmLowSup(D,Cx, postfixDic,minSup):
'''
根据当前候选集合删除低support的候选集
'''
Lx = Cx
for iset in Cx:
print("iset=",iset)
print ("len(postfixDic[iset])/len(D)=",len(postfixDic[iset])/len(D))
if len(postfixDic[iset])/len(D) < minSup:
#观察以iset为首项的前缀的数量在总体样本的比例
Lx.remove(iset)
postfixDic.pop(iset)
return Lx, postfixDic
def createC1(D, minSup):
'''生成第一个候选序列,即长度为1的集合序列
'''
C1 = [] #初始的记录了每一个可能的前缀值
postfixDic={} # 集合对应的每个序列的所在位置的开始位置,{(1,):{0:2,3:1}}表示前缀(1,)在0序列的结尾为2, 3序列的结尾为1
# 仅仅记录了第一次出现时的情景。如果在一个记录里反复出现,那么后面出现的情况不予讨论。
lenD = len(D)
for i in range(lenD):
for idx, item in enumerate(D[i]):
if tuple([item]) not in C1:
postfixDic[tuple([item])]={}
C1.append(tuple([item]))
if i not in postfixDic[tuple([item])].keys():
postfixDic[tuple([item])][i]=idx
L1, postfixDic = rmLowSup(D, C1, postfixDic, minSup)
#在removeLowSupport之后,L1相当于是对C1中低置信度成分的剔除。
return L1, postfixDic
def genNewPostfixDic(D,Lk, prePost):
'''根据候选集生成相应的PrefixSpan后缀
参数:
D:数据集
Lk: 选出的集合
prePost: 上一个前缀集合的后缀
基于假设:
(1,2)的后缀只能出现在 (1,)的后缀列表里
e.g.
postifixDic[(1,2)]={1:2,2:3} 前缀 (1,2) 在第一行的结尾是2,第二行的结尾是3
'''
postfixDic = {}
for Ck in Lk:
# (1,2)的后缀只能出现在 (1,)的后缀列表里
postfixDic[Ck]={}
tgt = Ck[-1]
prePostList = prePost[Ck[:-1]]
for r_i in prePostList.keys():
for c_i in range(prePostList[r_i]+1, len(D[r_i])):
if D[r_i][c_i]==tgt:
postfixDic[Ck][r_i] = c_i
break
# print(postfixDic)
return postfixDic
def psGen(D, Lk, postfixDic, minSup, minConf):
'''生成长度+1的新的候选集合
'''
retList = []
lenD = len(D)
# 访问每一个前缀
for Ck in Lk:
item_count = {}
# 统计item在多少行的后缀里出现。而item的取值范围即为下面循环中的 j
# 访问出现前缀的每一行
for i in postfixDic[Ck].keys():
# 从前缀开始访问每个字符
item_exsit={}
for j in range(postfixDic[Ck][i]+1, len(D[i])):
#从后缀的末尾开始到事件的结束,依次遍历元素
if D[i][j] not in item_count.keys():
item_count[D[i][j]]=0
if D[i][j] not in item_exsit:
item_count[D[i][j]]+=1
item_exsit[D[i][j]]=True
c_items = []
# 根据minSup和minConf筛选候选字符
for item in item_count.keys():
print (item_count[item])
print (lenD)
print ((postfixDic[Ck]))
print ("item_count[item]/lenD=",item_count[item]/lenD)
print ("item_count[item]/len(postfixDic[Ck]=",item_count[item]/len(postfixDic[Ck]))
print ("****************")
if item_count[item]/lenD >= minSup and item_count[item]/len(postfixDic[Ck])>=minConf:
c_items.append(item)
# 将筛选后的字符组成新的候选项,加入候选集合
for c_item in c_items:
retList.append(Ck+tuple([c_item]))
return retList
def PrefixSpan(D, minSup=0.5, minConf=0.5):
L1, postfixDic = createC1(D, minSup)
L = [L1]
k=2
while len(L[k-2])>0:
# 生成新的候选集合
Lk = psGen(D, L[k-2], postfixDic,minSup, minConf)
# 根据新的候选集合获取新的后缀
postfixDic = genNewPostfixDic(D,Lk,postfixDic)
# 加入到集合中
L.append(Lk)
k+=1
return L
if __name__ =='__main__':
L = PrefixSpan(data,minSup=0.3,minConf=0.5)
for i in range(len(L)-1,-1,-1):
for Cx in L[i]:
print(Cx)关于minSup和minConf的理解——
minSup:由某一前缀构成的序列在总样本的比例
minConf:由某一前缀构成的序列在出现了该前缀中的样本的比例
比如样本为:
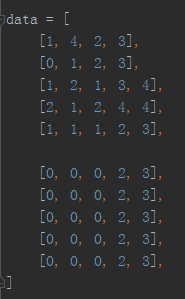
考察序列(1,4)的minSup,则有 minSup = 3/10=0.3
而对于minConf,由(1,4)可知其前缀为1,在样本中1前缀的数量为5,则minConf = 3/5=0.6
minSup = minConf * 前缀在样本中的比例。显然minConf >= minSup
同时应注意,一个事件集中可有多种序列。

1的后缀的概率相加和不一定小于1。序列的出现不存在互斥性!
假设有序列[a,b,a,c,e],预测接下来是否有f。
准确率最高的情况,就是让[a,b,a,c,e,f]的minConf和minSup都很高。形如
此时,
![]()
如果给出了 (0,0,0,2)的序列,那么预测0,0,0,2,3是很稳的。因为由0,0,0,2得出0,0,0,2,3的概率是1。且0,0,0,2,3出现的概率也很高。可以认为,minConf提供了预测的准确性,而minSup提供了预测准确性的过拟合性
如果不能满足,那么应该优先考虑准确性。
形如数据集为:

挖掘的结果为:
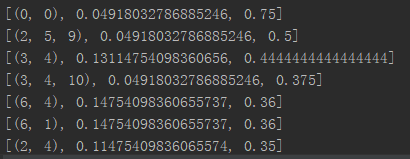
可见,(0,0)出现的概率虽然较小,但由于其较高的可信度,在一个0后仍然要预测0
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









