




1.Maven工程【父子结构搭建】
- 打开IDEA,新建Maven Project【spark】,填写Maven的GAV
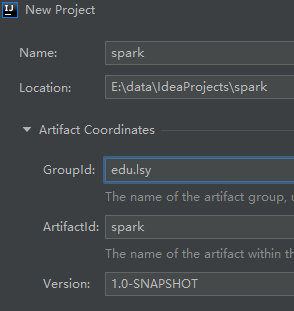
- 创建好maven项目之后,点击Enable Auto-Import
- 修改spark的pom.xml文件
<!--表明当前项目是一个父项目,没有具体代码,只有声明的公共部分-->
<packaging>pom</packaging>
--------------------------
src就没用了,可以删除- 在spark project下 new module:添加子项目【spark-core】
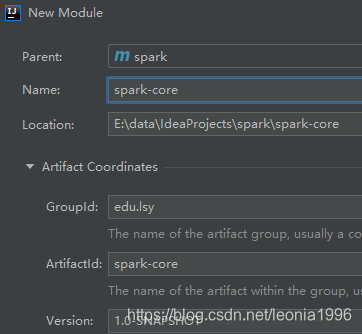
- 修改spark-core的pom.xml文件
<!--表明当前项目是一个父项目,没有具体代码,只有声明的公共部分-->
<packaging>pom</packaging>
--------------------------
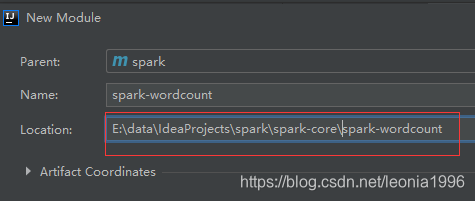
src就没用了,可以删除- 在spark-core模块下 new module:新建子项目【spark-wordcount】
注意:第三层级创建时注意location,手动更改为spark-core下面
spark的pom.xml中
<modules>应该有<module>spark-core</module>
---------------------------------------------------------------------
spark-core的pom.xml中
<parent>是spark
<modules>应该有<module>spark-wordcount</module>
---------------------------------------------------------------------
spark-wordcount的pom.xml中
<parent>是spark-core- 至此,Maven项目的父子结构基本完成
2.修改spark的pom.xml
- 对于开发过程中所需要的文件进行配置
- 声明公有的属性
<!--声明公有的属性-->
<properties>
<spark.version>2.1.1</spark.version>
<scala.version>2.11.8</scala.version>
<log4j.version>1.2.17</log4j.version>
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









