







先从schema.xml中截取一段示例:
<table name="goods" primaryKey="ID" type="global" dataNode="dn1,dn2" />
<!-- random sharding using mod sharind rule -->
<table name="hotnews" primaryKey="ID" dataNode="dn1,dn2,dn3"
rule="mod-long" />
2、逻辑表名:hotnews,所属分片:dn1、dn2、dn3;
分片规则:mod-long,注意按实际情况修改分片规则文件(conf目录下的rule.xml文件)
primaryKey为分片字段,SQL语句按primaryKey查找可以快速定位到具体分片,(primaryKey在配置文件中指定,可以不是主键)
常用分片规则如下:
一、连续分片规则:
1)范围分片:
<function name="rang-long"
class="org.opencloudb.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
<property name="defaultNode">0</property>
</function># range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2分片字段取值:500M~1000M,划分到dataNode2
分片字段取值:1000M~1500M,划分到dataNode3
上述定义的范围外的分片字段,划分划分到dataNode1
注:<property name="defaultNode">0</property>,适用于每个分片规则,当遇到无法识别的值,指定默认的路由规则
2)按月分片:
二、离散分片规则:
1)枚举
<function name="hash-int"
class="org.opencloudb.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
#vim partition-hash-int.txt
10000=0
10010=1
2)取模
<function name="mod-long" class="org.opencloudb.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
3)一致性hash分片(远期MyCAT可能放弃该算法)
<function name="murmur"
class="org.opencloudb.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定
,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库>节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍。注意虚拟节点过少会导致数据分布不均匀 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重>,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就>是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性
,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定>,就不会输出任何东西 -->
</function>
三、综合分片规则
1)先范围后取模
<function name="rang-mod" class="org.opencloudb.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function># vim partition-range-mod.txt
# range start-end ,data node group size
0-200M=5
200M1-400M=1
400M1-600M=4
600M1-800M=4
800M1-1000M=6
2)先日期后hash
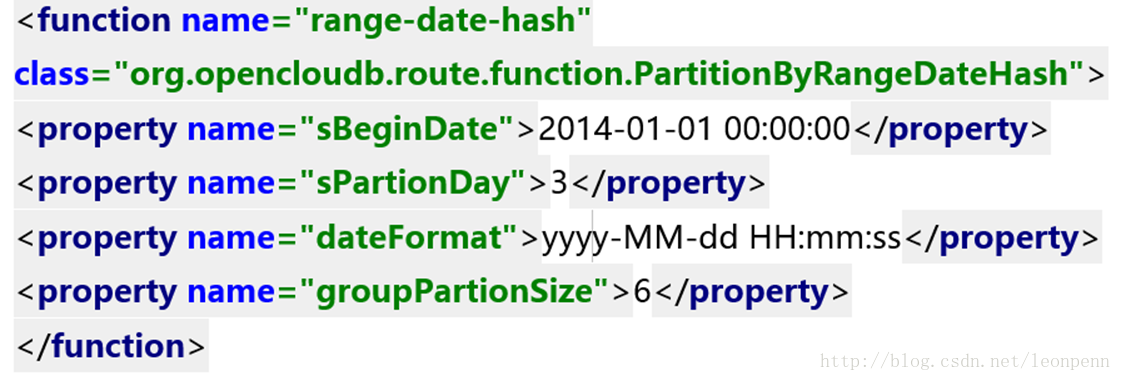
切分的一些思路:
1、涉及复杂查询的,可以根据原表的数据量大小估算切分后的单个分片表的数据量在1000万左右(无复杂查询的数据量可大到5000万)。
2、根据最频繁的、最重要的查询条件来选择合适的分片字段。谨慎选择,分片字段一经选择无法修改。
3、范围类不需要考虑扩容数据迁移问题,哈希类、取模类需要迁移。
4、根据ER分片,有关联关系的表配置相同分片规则可以优化join操作。
5、配置类的数据、或更新频率较少的表,考虑采用全局表。
6、活跃数据优先采用离散分片规则。
7、历史非活跃数据优先采用连续分片规则。
跨分片数据聚合机制
当后端分片返回数据给MyCAT的时,特别是遇到报表统计类查询时,会使得在MyCAT内完成分页、排序、分组、统计操作,严重消耗内存资源。
分页:
假设客户端发送给MyCAT:select * from table_1 limit 100;
MyCAT:将该SQL推送到下属的分片
分片分别计算结果返回给MyCAT,由于每次分片返回数据的速度不尽相同,故可能存在随机结果集的问题。
(堆)排序:
跨分片join机制:
MySQL端实现join,MyCAT端进行合并
需要在每个分片中,参与join的多个表符合可以进行join
每个分片各自进行join操作,作为部分结果集,发送到MyCAT进行整合。
具体可以实现上述操作的表有以下4种:
1)不分片的表之间进行join
2)采用相同分片规则、且用分片字段做join的表
3)ER分片表
4)分片表+全局表
其余表的join,需要下推到MyCAT实现,否则会导致数据不全。
Catlet存在的问题:需要实时计算结果资源消耗必然很大、无法支持大表join
http://www.cnblogs.com/756623607-zhang/p/6656022.html















 1806
1806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









