










 这篇博客介绍了如何使用Decord库在Python中高效地提取视频帧,相比于OpenCV,Decord提供了更快的帧读取速度。文章通过对比Decord和OpenCV的实现,展示了Decord在批量处理和内存管理方面的优势,并提供了并行处理视频帧的示例代码,以利用多核CPU提升处理速度。
这篇博客介绍了如何使用Decord库在Python中高效地提取视频帧,相比于OpenCV,Decord提供了更快的帧读取速度。文章通过对比Decord和OpenCV的实现,展示了Decord在批量处理和内存管理方面的优势,并提供了并行处理视频帧的示例代码,以利用多核CPU提升处理速度。
**更新(2020 年 7 月):**我现在使用并建议使用Decod在 Python 中更快地加载视频。您可以进一步查看原始的 OpenCV 版本。😃
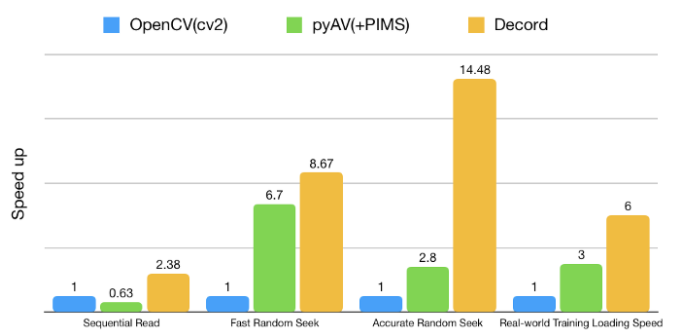
速度比较。来自Decod的 Github 页面。
下面是一个如何使用 Decod 提取帧的示例脚本。它与 OpenCV 版本有相似之处,但更快、更简洁、更简单。请注意,它根据参数使用批量收集或顺序读取来提取帧every。我已将阈值设置为25和total阈值 ,1000因为这适合我的系统的内存限制和 CPU 能力。
import cv2 # still used to save images out
import os
import numpy as np
from decord import VideoReader
from decord import cpu, gpu
def extract_frames(video_path, frames_dir, overwrite=False, start=-1, end=-1, every=1):
"""
Extract frames from a video using decord's VideoReader
:param video_path: path of the video
:param frames_dir: the directory to save the frames
:param overwrite: to overwrite frames that already exist?
:param start: start frame
:param end: end frame
:param every: frame spacing
:return: count of images saved
"""
video_path = os.path.normpath(video_path) # make the paths OS (Windows) compatible
frames_dir = os.path.normpath(frames_dir) # make the paths OS (Windows) compatible
video_dir, video_filename = os.path.split(video_path) # get the video path and filename from the path
assert os.path.exists(video_path) # assert the video file exists
# load the VideoReader
vr = VideoReader(video_path, ctx=cpu(0)) # can set to cpu or gpu .. ctx=gpu(0)
if start < 0: # if start isn't specified lets assume 0
start = 0
if end < 0: # if end isn't specified assume the end of the video
end = len(vr)
frames_list = list(range(start, end, every))
saved_count = 0
if every > 25 and len(frames_list) < 1000: # this is faster for every > 25 frames and can fit in memory
frames = vr.get_batch(frames_list).asnumpy()
for index, frame in zip(frames_list, frames): # lets loop through the frames until the end
save_path = os.path.join(frames_dir, video_filename, "{:010d}.jpg".format(index)) # create the save path
if not os.path.exists(save_path) or overwrite: # if it doesn't exist or we want to overwrite anyways
cv2.imwrite(save_path, cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)) # save the extracted image
saved_count += 1 # increment our counter by one
else: # this is faster for every <25 and consumes small memory
for index in range(start, end): # lets loop through the frames until the end
frame = vr[index] # read an image from the capture
if index % every == 0: # if this is a frame we want to write out based on the 'every' argument
save_path = os.path.join(frames_dir, video_filename, "{:010d}.jpg".format(index)) # create the save path
if not os.path.exists(save_path) or overwrite: # if it doesn't exist or we want to overwrite anyways
cv2.imwrite(save_path, cv2.cvtColor(frame.asnumpy(), cv2.COLOR_RGB2BGR)) # save the extracted image
saved_count += 1 # increment our counter by one
return saved_count # and return the count of the images we saved
def video_to_frames(video_path, frames_dir, overwrite=False, every=1):
"""
Extracts the frames from a video
:param video_path: path to the video
:param frames_dir: directory to save the frames
:param overwrite: overwrite frames if they exist?
:param every: extract every this many frames
:return: path to the directory where the frames were saved, or None if fails
"""
video_path = os.path.normpath(video_path) # make the paths OS (Windows) compatible
frames_dir = os.path.normpath(frames_dir) # make the paths OS (Windows) compatible
video_dir, video_filename = os.path.split(video_path) # get the video path and filename from the path
# make directory to save frames, its a sub dir in the frames_dir with the video name
os.makedirs(os.path.join(frames_dir, video_filename), exist_ok=True)
print("Extracting frames from {}".format(video_filename))
extract_frames(video_path, frames_dir, every=every) # let's now extract the frames
return os.path.join(frames_dir, video_filename) # when done return the directory containing the frames
if __name__ == '__main__':
# test it
video_to_frames(video_path='test.mp4', frames_dir='test_frames', overwrite=False, every=5)
我’已经与影片做了很多多年来一两件事,我经常需要做的是提取视频帧,并将其保存为单独的图像。随着时间的推移,我不得不处理更大、更容易出错的视频文件,并且最近确定了一个不错的脚本,我想我会分享它。
让我们从基本功能开始,它可以毫不费力地从单个视频中提取帧。这个被调用的函数extract_frames()需要一个视频路径、一个帧目录的路径,以及一些额外的东西,比如我们是否想要覆盖已经存在的帧,或者只每 x 帧执行一次。
import cv2
import os
def extract_frames(video_path, frames_dir, overwrite=False, start=-1, end=-1, every=1):
"""
Extract frames from a video using OpenCVs VideoCapture
:param video_path: path of the video
:param frames_dir: the directory to save the frames
:param overwrite: to overwrite frames that already exist?
:param start: start frame
:param end: end frame
:param every: frame spacing
:return: count of images saved
"""
video_path = os.path.normpath(video_path) # make the paths OS (Windows) compatible
frames_dir = os.path.normpath(frames_dir) # make the paths OS (Windows) compatible
video_dir, video_filename = os.path.split(video_path) # get the video path and filename from the path
assert os.path.exists(video_path) # assert the video file exists
capture = cv2.VideoCapture(video_path) # open the video using OpenCV
if start < 0: # if start isn't specified lets assume 0
start = 0
if end < 0: # if end isn't specified assume the end of the video
end = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))
capture.set(1, start) # set the starting frame of the capture
frame = start # keep track of which frame we are up to, starting from start
while_safety = 0 # a safety counter to ensure we don't enter an infinite while loop (hopefully we won't need it)
saved_count = 0 # a count of how many frames we have saved
while frame < end: # lets loop through the frames until the end
_, image = capture.read() # read an image from the capture
if while_safety > 500: # break the while if our safety maxs out at 500
break
# sometimes OpenCV reads None's during a video, in which case we want to just skip
if image is None: # if we get a bad return flag or the image we read is None, lets not save
while_safety += 1 # add 1 to our while safety, since we skip before incrementing our frame variable
continue # skip
if frame % every == 0: # if this is a frame we want to write out based on the 'every' argument
while_safety = 0 # reset the safety count
save_path = os.path.join(frames_dir, video_filename, "{:010d}.jpg".format(frame)) # create the save path
if not os.path.exists(save_path) or overwrite: # if it doesn't exist or we want to overwrite anyways
cv2.imwrite(save_path, image) # save the extracted image
saved_count += 1 # increment our counter by one
frame += 1 # increment our frame count
capture.release() # after the while has finished close the capture
return saved_count # and return the count of the images we saved
您可能会注意到我们使用了一个带有有点奇怪的while_safety计数器的 while 循环。这是因为有时 OpenCV 会返回空帧,在这种情况下,我们只想继续读取而不增加frame计数器。这增加了无限循环已经存在的任何潜力,这就是为什么while_safety每次frame不使用计数器时都使用计数器并递增的原因。
虽然上面的代码很简单,但实际上很慢,结果提取和保存帧需要一段时间。幸运的是,如今的计算机往往具有多个 CPU 内核,可以并行执行操作。因此,让我们扩展上述代码以在所有 CPU 内核上添加并行处理。
为此,我们编写了一个包装函数video_to_frames(),该函数首先将视频分成 length 的块chunk_size,然后extract_frames()在每个块上调用上面看到的函数。
from concurrent.futures import ProcessPoolExecutor, as_completed
import cv2
import multiprocessing
import os
import sys
def print_progress(iteration, total, prefix='', suffix='', decimals=3, bar_length=100):
"""
Call in a loop to create standard out progress bar
:param iteration: current iteration
:param total: total iterations
:param prefix: prefix string
:param suffix: suffix string
:param decimals: positive number of decimals in percent complete
:param bar_length: character length of bar
:return: None
"""
format_str = "{0:." + str(decimals) + "f}" # format the % done number string
percents = format_str.format(100 * (iteration / float(total))) # calculate the % done
filled_length = int(round(bar_length * iteration / float(total))) # calculate the filled bar length
bar = '#' * filled_length + '-' * (bar_length - filled_length) # generate the bar string
sys.stdout.write('\r%s |%s| %s%s %s' % (prefix, bar, percents, '%', suffix)), # write out the bar
sys.stdout.flush() # flush to stdout
def extract_frames(video_path, frames_dir, overwrite=False, start=-1, end=-1, every=1):
"""
Extract frames from a video using OpenCVs VideoCapture
:param video_path: path of the video
:param frames_dir: the directory to save the frames
:param overwrite: to overwrite frames that already exist?
:param start: start frame
:param end: end frame
:param every: frame spacing
:return: count of images saved
"""
video_path = os.path.normpath(video_path) # make the paths OS (Windows) compatible
frames_dir = os.path.normpath(frames_dir) # make the paths OS (Windows) compatible
video_dir, video_filename = os.path.split(video_path) # get the video path and filename from the path
assert os.path.exists(video_path) # assert the video file exists
capture = cv2.VideoCapture(video_path) # open the video using OpenCV
if start < 0: # if start isn't specified lets assume 0
start = 0
if end < 0: # if end isn't specified assume the end of the video
end = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))
capture.set(1, start) # set the starting frame of the capture
frame = start # keep track of which frame we are up to, starting from start
while_safety = 0 # a safety counter to ensure we don't enter an infinite while loop (hopefully we won't need it)
saved_count = 0 # a count of how many frames we have saved
while frame < end: # lets loop through the frames until the end
_, image = capture.read() # read an image from the capture
if while_safety > 500: # break the while if our safety maxs out at 500
break
# sometimes OpenCV reads None's during a video, in which case we want to just skip
if image is None: # if we get a bad return flag or the image we read is None, lets not save
while_safety += 1 # add 1 to our while safety, since we skip before incrementing our frame variable
continue # skip
if frame % every == 0: # if this is a frame we want to write out based on the 'every' argument
while_safety = 0 # reset the safety count
save_path = os.path.join(frames_dir, video_filename, "{:010d}.jpg".format(frame)) # create the save path
if not os.path.exists(save_path) or overwrite: # if it doesn't exist or we want to overwrite anyways
cv2.imwrite(save_path, image) # save the extracted image
saved_count += 1 # increment our counter by one
frame += 1 # increment our frame count
capture.release() # after the while has finished close the capture
return saved_count # and return the count of the images we saved
def video_to_frames(video_path, frames_dir, overwrite=False, every=1, chunk_size=1000):
"""
Extracts the frames from a video using multiprocessing
:param video_path: path to the video
:param frames_dir: directory to save the frames
:param overwrite: overwrite frames if they exist?
:param every: extract every this many frames
:param chunk_size: how many frames to split into chunks (one chunk per cpu core process)
:return: path to the directory where the frames were saved, or None if fails
"""
video_path = os.path.normpath(video_path) # make the paths OS (Windows) compatible
frames_dir = os.path.normpath(frames_dir) # make the paths OS (Windows) compatible
video_dir, video_filename = os.path.split(video_path) # get the video path and filename from the path
# make directory to save frames, its a sub dir in the frames_dir with the video name
os.makedirs(os.path.join(frames_dir, video_filename), exist_ok=True)
capture = cv2.VideoCapture(video_path) # load the video
total = int(capture.get(cv2.CAP_PROP_FRAME_COUNT)) # get its total frame count
capture.release() # release the capture straight away
if total < 1: # if video has no frames, might be and opencv error
print("Video has no frames. Check your OpenCV + ffmpeg installation")
return None # return None
frame_chunks = [[i, i+chunk_size] for i in range(0, total, chunk_size)] # split the frames into chunk lists
frame_chunks[-1][-1] = min(frame_chunks[-1][-1], total-1) # make sure last chunk has correct end frame, also handles case chunk_size < total
prefix_str = "Extracting frames from {}".format(video_filename) # a prefix string to be printed in progress bar
# execute across multiple cpu cores to speed up processing, get the count automatically
with ProcessPoolExecutor(max_workers=multiprocessing.cpu_count()) as executor:
futures = [executor.submit(extract_frames, video_path, frames_dir, overwrite, f[0], f[1], every)
for f in frame_chunks] # submit the processes: extract_frames(...)
for i, f in enumerate(as_completed(futures)): # as each process completes
print_progress(i, len(frame_chunks)-1, prefix=prefix_str, suffix='Complete') # print it's progress
return os.path.join(frames_dir, video_filename) # when done return the directory containing the frames
if __name__ == '__main__':
# test it
video_to_frames(video_path='test.mp4', frames_dir='test_frames', overwrite=False, every=5, chunk_size=1000)


















 2388
2388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











