







Python爬取网易云音乐搜索并下载歌曲!
1.准备工作
我在网易云音乐试了一下,发现是它是一个动态网页,里面的内容都是JS生成的,所以不太好爬取。这时候就要有第三方网站“帮”我们爬取了。
我找了个第三方软件,可以用它来爬出歌曲ID,我们在爬取它的源代码,把ID取出来(好像有点绕口)
2.“实地”观察
我们进入到这个网站,发现这个网站一个有5个下载源可以搜索:
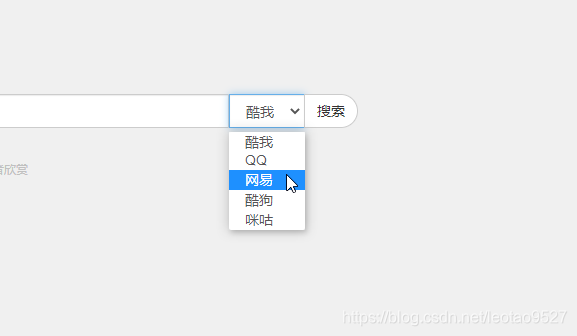
今天我们的目标是下载网易云音乐的歌曲,有兴趣的小伙伴可以试着爬取其他网站的歌曲,原理是一样的。我们随便搜索一个歌曲,查看网址。
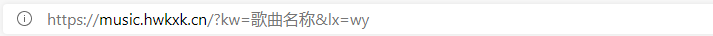
我们发现网址"kw="后面代表是歌曲的名称,而"lx="后面代表的是下载源。
我们再来看看源代码:
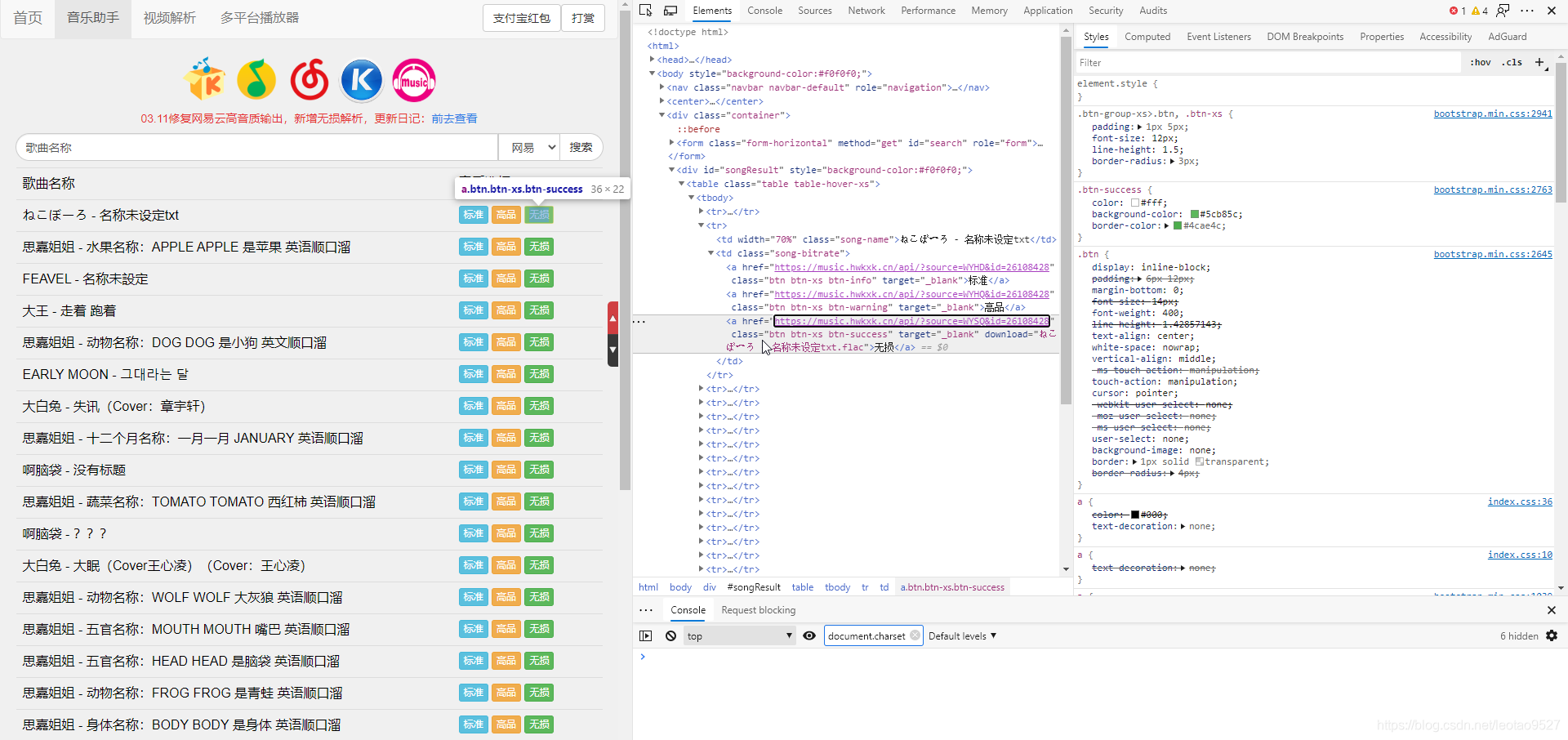
我们看到,一个a标签里面正有我们想要的东西:下载链接和歌曲名称。

有了下载链接和歌曲名称就好办了,接下来是码代码环节!
3.开始码代码!
我这里做了一个用户界面和UI,还有一个新的下载方式:链接下载。想看链接下载的小伙伴可以跳过本章,看第4章节:搜索并下载。
链接下载
首先,我们得知道一个网址:http://music.163.com/song/media/outer/url?id=?.mp3
这是什么呢?这是一个下载链接,在"id="处填上歌曲的ID就可以下载了。

我们随便打开一个音乐,发现网址上正好有"id=???"这样的格式,我们只要用正则表达式来提取ID,再在把ID填到上面的网址中就可以了,代码:
import re
import urllib.request
import tkinter.messagebox as box
# 设置下载函数
def urldownload():
url = lefturl.get() # 这里是我UI的输入框,不想用UI的可以直接input
try:
# 解析歌曲id
urlid = re.findall('id=(.*)', url)[0]
# 获取下载网页
durl = 'http://music.163.com/song/media/outer/url?id=%s.mp3' % urlid
# 下载歌曲
urllib.request.urlretrieve(durl, '绝对路径\名称.mp3')
# 提示下载完毕
box.showinfo(title='提示', message='音乐已下载完毕!\n已保存至download文件夹!')
except:
box.showerror(title='错误', message='下载链接错误!')
4.搜索并下载
想要得到下载链接和名称,我们首先得得到网页的源代码:
# 搜索函数
def searchdownload(name):
# 从网站的Requests Header中获取
url = 'https://music.hwkxk.cn/?kw=%s&lx=wy' % name
html = requests.get(url=url).text
print(html)
可是运行完后,输出的是乱码,这是怎么回事?
这时候,我们可以先把网页内容转成单字节编码,再转成UTF-8,修改如下:
import requests
# 搜索函数
def searchdownload(name):
# 从网站的Requests Header中获取
url = 'https://music.hwkxk.cn/?kw=%s&lx=wy' % name
html = requests.get(url=url).text
html = html.encode('ISO-8859-1')
html = html.decode('UTF-8')
print(html)
这时候,就没有乱码了。
接下来,就来爬取歌曲名称和下载链接:

我们看到,这个歌曲的a标签的class名是“btn btn-xs btn-success”,但是这只是一个歌曲的class,我们要找到"所有歌曲的class"。
我们看到右边的"styles",发现这个class才是"所有a标签的class"。
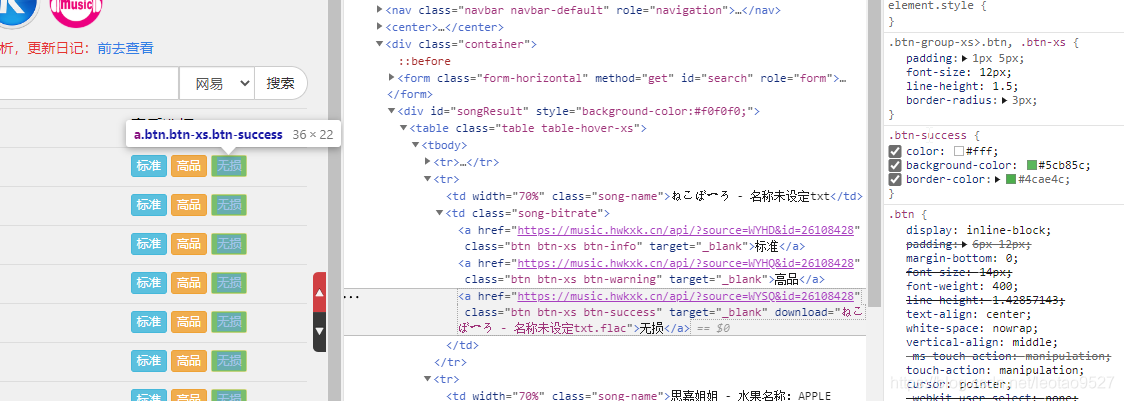
现在来码代码:
import bs4
import requests
# 搜索函数
def searchdownload(name):
# 从网站的Requests Header中获取
url = 'https://music.hwkxk.cn/?kw=%s&lx=wy' % name
html = requests.get(url=url).text
html = html.encode('ISO-8859-1')
html = html.decode('UTF-8')
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1000
1000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









