







 本文介绍了如何创建一个垃圾邮件过滤系统,包括数据预处理、训练模型、交叉验证和评估指标计算。首先,从公开数据源下载并解压数据集,接着通过Python进行数据预处理,创建特征向量。然后,利用数据预处理管道,训练逻辑回归模型,通过交叉验证得到近99%的准确率。最后,计算出精确率和召回率,结果显示模型性能优秀。
本文介绍了如何创建一个垃圾邮件过滤系统,包括数据预处理、训练模型、交叉验证和评估指标计算。首先,从公开数据源下载并解压数据集,接着通过Python进行数据预处理,创建特征向量。然后,利用数据预处理管道,训练逻辑回归模型,通过交叉验证得到近99%的准确率。最后,计算出精确率和召回率,结果显示模型性能优秀。
本博客所有内容均整理自《Hands-On Machine Learning with Scikit-Learn & TensorFlow》一书及其GitHub源码。
看《Hands-On》一书至第三章,习题里面后两题是实际操作的编程题,自己初步动手效果不错,特此记录一下。
运行环境:Jupyter Notebook 语言:Python3.6.4
0、题目描述
总体目标:创建一个垃圾邮件过滤系统
基本步骤:
- 从http://spamassassin.apache.org/old/publiccorpus/网址下载开源数据,包括垃圾邮件和普通邮件
- 解压数据集,观察并熟悉数据格式
- 将数据集分成训练集和测试集
- 制作一个针对该数据集的数据预处理管道,将每一封邮件转换成特征向量的形式
- 添加超参数
- 训练几种机器学习分类器,计算精确率和召回率
1、数据获取
根据题目要求,我们第一步要去下载数据集,其实这一步可以直接打开网址手动下载,但是既然是用Python语言做处理,我们就索性使用Python写代码去下载。
import os
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT = "http://spamassassin.apache.org/old/publiccorpus/"
HAM_URL = DOWNLOAD_ROOT + "20030228_easy_ham.tar.bz2"
SPAM_URL = DOWNLOAD_ROOT + "20030228_spam.tar.bz2"
SPAM_PATH = os.path.join("datasets", "spam")
def fetch_spam_data(spam_url=SPAM_URL, spam_path=SPAM_PATH):
if not os.path.isdir(spam_path):
os.makedirs(spam_path)
for filename, url in (("ham.tar.bz2", HAM_URL), ("spam.tar.bz2", SPAM_URL)):
path = os.path.join(spam_path, filename)
if not os.path.isfile(path):
urllib.request.urlretrieve(url, path)
tar_bz2_file = tarfile.open(path)
tar_bz2_file.extractall(path=SPAM_PATH)
tar_bz2_file.close()这一步实现下载数据和创建文件路径,首先,我们把所有的文件路径先人为设好,虽然此时根本就没有这样的路径,但是可以先将其设好,然后使用以下两句来通过代码创建path_you_want_to_create(这里具体的路径就随个人自定义了)路径:
if not os.path.isdir(spam_path):
os.makedirs(spam_path)创建好路径之后,我们使用以下两句来实现网络数据向指定路径的下载:
if not os.path.isfile(path):
urllib.request.urlretrieve(url, path)下载完成之后就是解压了,这里其实我相当于是开了上帝视角,提前就知道下载下来的数据是tar格式的压缩文件,于是使用tarfile.open()函数去打开,使用extractall()函数去解压。
定义好了函数之后,直接调用该函数就可以创建路径,下载数据,并解压。
fetch_spam_data()至此,数据获取过程结束!
2、数据预处理
题目明确要求,下载并解压数据之后,我们必须观察并熟悉数据格式,然后将数据分成训练集和测试集,再制作一个数据预处理的特征管道来对数据进行清洗,这一系列的操作组合起来,就是数据预处理过程。
我们首先将解压好的数据打开看看。
HAM_DIR = os.path.join(SPAM_PATH, "easy_ham")
SPAM_DIR = os.path.join(SPAM_PATH, "spam")
ham_filenames = [name for name in sorted(os.listdir(HAM_DIR)) if len(name) > 20]
spam_filenames = [name for name in sorted(os.listdir(SPAM_DIR)) if len(name) > 20]这里我对数据进行了一次排序,相当于做了一次整理,要求name长度大于20,是因为防止下载的数据不全,因为不管是垃圾邮件还是普通邮件,肯定都是不止20封的。
获取到数据之后,我们首先来看一下垃圾邮件和普通邮件分别有多少封。
len(ham_filenames)
len(spam_filenames)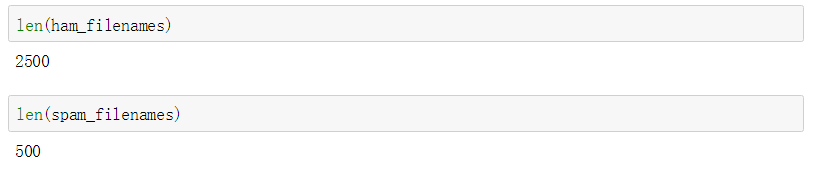
根据结果显示,被标为垃圾邮件的有500封,被标为普通邮件的有2500封。很明显,这个实际结果的分类情况是不均衡的。
接下来,我们就要实际去获取邮件的具体内容了,这需要用到email模块,我们根据该模块自定义一个获取邮件内容的函数,并调用该函数来分别获取垃圾邮件和普通邮件。
import email
import email.policy
def load_email(is_spam, filename, spam_path=SPAM_PATH):
directory = "spam" if is_spam else "easy_ham"
with open(os.path.join(spam_path, directory, filename), "rb") as f:
return email.parser.BytesParser(policy=email.policy.default).parse(f)
ham_emails = [load_email(is_spam=False, filename=name) for name in ham_filenames]
spam_emails = [load_email(is_spam=True, filename=name) for name in spam_filenames]email模块的具体使用方式暂且忽略,从代码中可以看出,我们通
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









