






图1、网络结构图
yolov1网络结构图是由24个卷积层、2个全连接层构成,其作者也说过灵感来自用于图像分类的GoogLeNet模型,但是与GoogLeNet模型不同的是简单的使用了1×1简化层和3×3卷积层(类似M. Lin, Q. Chen, and S. Y an. Network in network. CoRR,abs/1312.4400, 2013. 2),可以在上图看到。
输入的图像为448448,经过以上的结构,输出的为77*1024的张量,是第7个图样。在激活函数上,最后一层输出时用了线性激活函数,其余层都使用的是Leaky Relu激活函数。
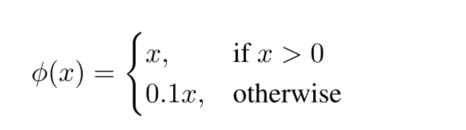
图2、Leaky Relu激活函数
YOLO相对于其他的(例如rcnn、fast-rcnn、faster-rcnn等)来说,它的优势就是YOLO设计实现了端到端的培训和实时速度,同时保持了较高的平均精度。具体的话就是将目标检测的各个部分统一为一个单一的神经网络,网络使用整个图像的特征来预测每个边界框。它还可以同时预测图像中所有类的所有边框。这意味着我们的网络对完整的图像和图像中的所有对象进行全局推理。
2、yolo-v1损失函数

图3、损失函数
3、yolo-v1和yolo-v4对比
yolo-v4说简单
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









