







1. VMware搭建Ubuntu16.04 spark集群
- VMware 安装Ubuntu16.04
- Ubuntu 启用root用户登陆
- 安装 VMware tools
- 安装jdk1.8,配置环境变量
- 安装ssh
- 虚拟机设置固定ip
- 设置/etc/hostname 本系统的名字(如:Master,Worker1);设置/etc/hosts 主从机的ip对应
- ssh无密码验证配置
- 安装hadoop2.7.3,配置环境变量
- 格式化文件系统 hadoop namenode -format
./start-dfs.sh 启动hdfs
jps 查看jvm进程 浏览器master:50070
./start-yarn.sh 启动资源管理框架
jps 查看jvm进程 浏览器master:8088 - 安装spark-2.0.0-bin-hadoop2.7,配置环境变量
2. Eclipse 编写第一个Spark程序
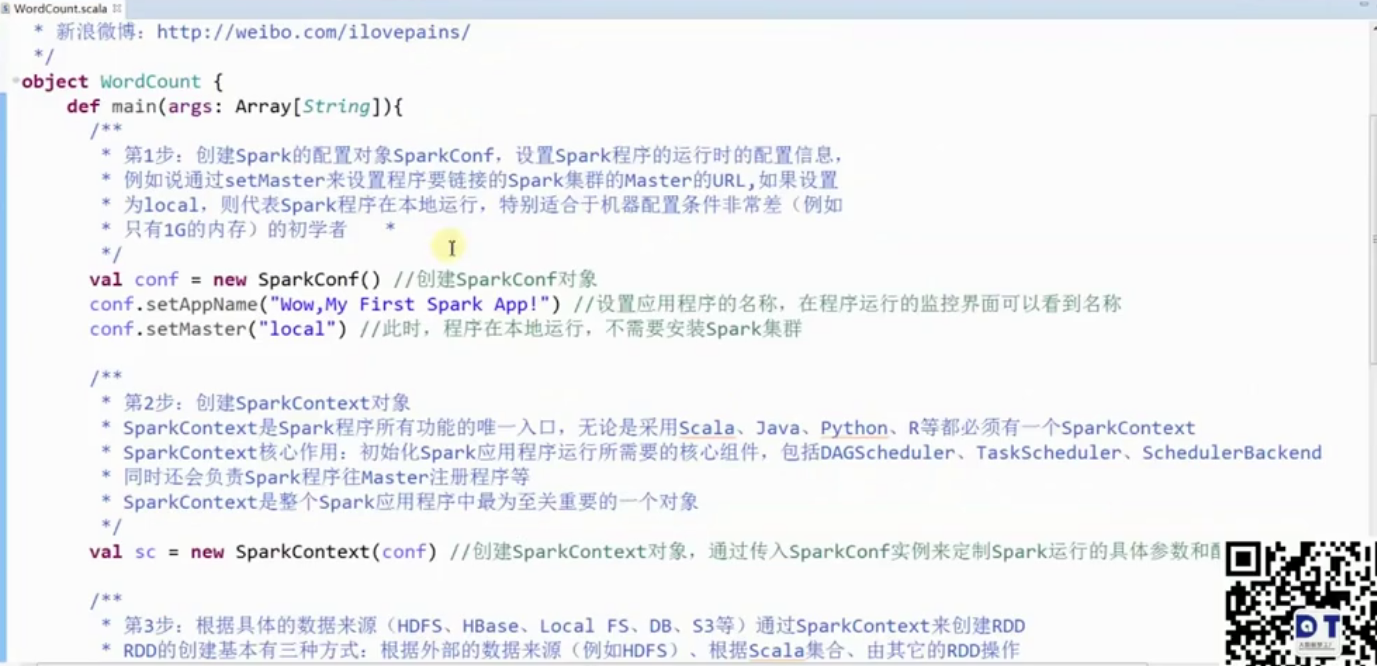
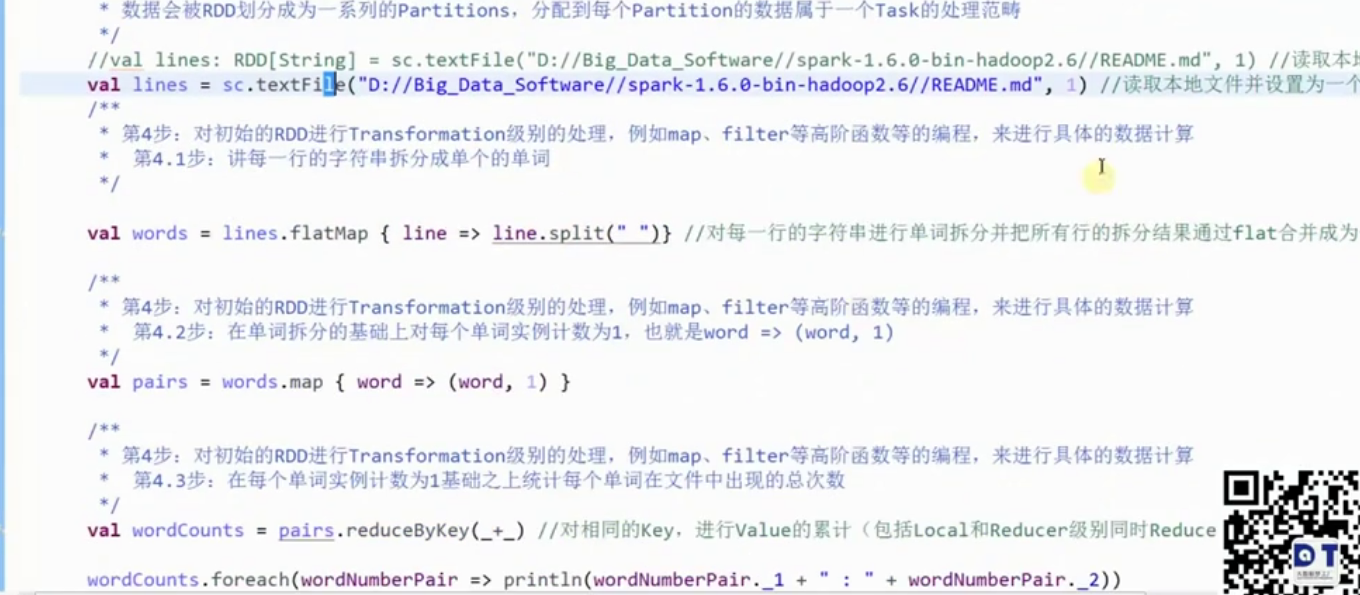
sc.stop()
3. RDD
RDD:Resillient Distributed DataSet 弹性分布数据集.RDD是Spark中的抽象数据结构类型,任何数据在Spark中都被表示为RDD。从编程的角度来看,RDD可以简单看成是一个数组。和普通数组的区别是,RDD中的数据是分区存储的,这样不同分区的数据就可以分布在不同的机器上,同时可以被并行处理。因此,Spark应用程序所做的无非是把需要处理的数据转换为RDD,然后对RDD进行一系列的变换和操作从而得到结果。
所谓弹性为一下七点:
1、自动的进行内存和磁盘数据存储的切换;
2、基于Lineage的高效容错(第n个节点出错,会从第n-1个节点恢复,血统容错);
3、Task如果失败会自动进行特定次数的重试(默认4次);
4、Stage如果失败会自动进行特定次数的重试(可以值运行计算失败的阶段);只计算失败的数据分片
5, checkpoint和persist
6,数据调度弹性:DAG TASK和资源 管理无关
7,数据分片的高度弹性,repartition
RDD的7种基本的创建方式
1,使用程序中的集合创建RDD;
2,使用本地文件系统创建RDD;
3,使用HDS创建RDD
4,基于DB创建RDD
5,基于NoSQL,例如HBase
6,基于S3创建RDD
7,基于数据流创建RDD
4. Transformation Action 算子
凡是Action级别的操作都会触发sc.runjob.
reduceByKey 是Transformation ,lazy级别的
reduce 是 Action
Action级别的操作:
reduce,collect,count,countByKey,take,saveAsTextFile
算子
1. map、filter、flatmap
2. reduceByKey、groupByKey
3. join、cogroup
5. 广播 broadcastNumber
val number = 10
val broadcastNumber = sc.broadcast(Number)
val data = sc.parallelize(1 to 10000)
val bn = data.map(_* broadcastNumber.value)
bn.collect 6. 累加器 accumulator
val sum = sc.accumlator(0) //初始值为0
val data = sc.parallelize(1 to 100)
val result = data.foreach(item => sum += item)
7. Spark架构
- 默认的资源分配方式:在每个Work上为当前程序分配一个ExecutorBackend进程,且默认情况下会最大化的使用core和momory。
- 一个work 上可以有多个executor
- 在excecutor 中一次性最多能够运行多少并发的Task取决于当前Executor能够使用的cores数量
- 线程不关心具体Task中运行什么代码,所以Task 和Thread和解耦合,所以Thread是可以被复用
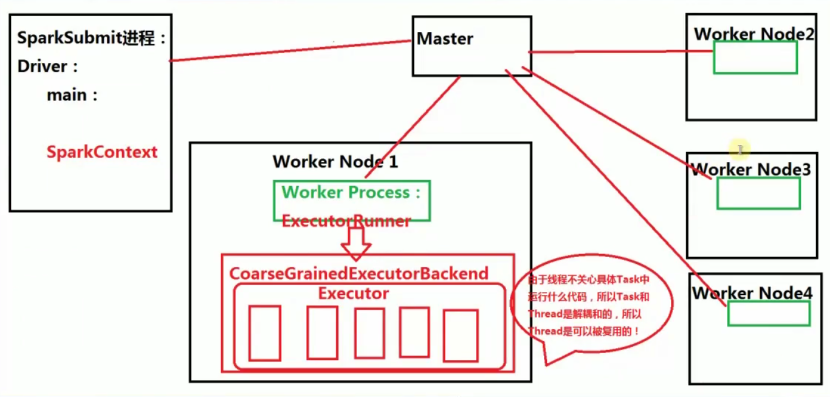
- 当Spark集群启动的时候,首先启动Master进程(全局资源管理器),负责整个集群的资源管理和分配,以及接收程序作业的提交且为作业分配资源。每个工作节点默认都会启动一个Work Process,来管理当前节点的Memory、CPU等计算资源,并向Mster汇报Worker还能够正常工作(即心跳)。当应用程序提交作业给Master的时候,Master 会为程序分配ID并分配计算资源,默认情况下为当前的应用程序在每个Worker Process下分配一个CoarseGrainedExecutorBackend进程(一个节点有可能会有多个Worker Process),该进程默认情况下会最大限度的使用当前节点上的的CPU和内存。当Driver 本身没有问题的话,Driver就会进行作业的调度来驱动CoarseGrainedExecutorBackend 中Excutor的线程来具体干活。这也就并发执行了。
- Work Process 管理当前节点的CPU和内存等计算资源实际上是通过Master来管理每台机器上的计算资源
- Worker节点上有Worker Process,Worker Process会接收Master的指令,为当前要运行的应用程序分配CoarseGrainedExecutorBackend 进程
- Spark的一个应用程序中可以应为不同的Action产生众多的Job,每个Job至少有一个Stage,Stage里面的内容一定是在Executor中执行的,而且Stage必须从前往后执行。
“`
8. RDD依赖关系
- 宽依赖是指一个父RDD的Partition会被多个子RDD的Partition所使用,例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖,宽依赖会产生shuffle
- 窄依赖是指每个父RDD的一个Partition最多被子RDD的一个Partition所使用,例如map、filter、union等都会产生窄依赖【map、filter等Transformation的操作来说,它们只是按照具体的map、filter里面的函数,进行具体的转换,它并不是涉及其他的处理。实质上是数据从一种形式转换成另外一种形式。Union操作是将多个RDD合并成一个RDD,它所有的父RDD的Partition不会有任何变化】
- 总结:如果父RDD的一个Partition被一个子RDD的Partition所使用就是窄依赖,否则的话就是宽依赖。如果子RDD中的Partition对父RDD的Partition依赖的数量不会随着RDD数据规模的改变而改变的话,就是窄依赖,否则的话就是宽依赖。
- 特别说明:对join操作有两种情况,如果说join操作的时候每个partition仅仅和已知的Partition进行join,这次是join操作就是窄依赖;其它情况【input not co-partitioned 会产生shuffle操作,而co-partitioned是哪几个固定的Partition进行join】的join操作就是宽依赖;
因为是确定的partition数量的依赖关系,所有就是窄依赖,得出一个推论,窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖(也就是说对父RDD的依赖的Partition的数量不会随着RDD数据规模的改变而改变)
注意:
1,从后往前推理,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到该Stage中;
2,每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的!
3,最后一个Stage里面的任务的类型是ResultTask,前面其它所有的Stage里面的任务的类型都是ShuffleMapTask【原因是它需要将自己的计算结果shuffle到下一个RDD中】;
4,代表当前Stage的算子一定是该Stage的最后一个计算步骤!!!
表面上是数据在流动,实质上算子在流动:
1, 数据不动代码动;
2,在一个Stage内幕算子为何会流动(Pipeline)?首先是算子合并,也就是所谓的函数式编程的执行的时候最终进行函数的展开从而把一个Stage内部的多个算子合并成为一个大算子(其内部包含了当前Stage中所有算子对数据的计算逻辑);其次是由于Tranformation操作的Lazy特性!!!在具体算子交给集群的Executor计算之前首先会通过Spark Framework(DAGScheduler)进行算子的优化(基于数据本地性的Pipeline)
9. Spark Job物理执行
- Spark Application里面可以产生1个或者多个Job,例如spark-shell默认启动的时候内部就没有Job,只是作为资源的分配程序,可以在spark-shell里面写代码产生若干个Job,普通程序中一般而言可以有不同的Action,每一个Action一般也会触发一个Job,【Action会触发其他Action操作】
- 基于Pipeline的思想,数据被使用的时候才开始计算,从数据流动的视角来说,是数据流动到计算的位置!!!实质上从逻辑的角度来看,是算子在数据上流动!
从算法构建的角度而言:肯定是算子作用于数据,所以是算子在数据上流动;方便算法的构建!
从物理执行的角度而言:是数据流动到计算的位置;方便系统最为高效的运行!
对于pipeline而言,数据计算的位置就是每个Stage中最后的RDD,一个震撼人心的内幕真相就是:每个Stage中除了最后一个RDD算子是真实的以外,前面的算子都是假的!!!
9. Shuffle
Shuffle中文翻译为“洗牌”,需要Shuffle的关键性原因是某种具有共同特征的数据需要最终汇聚到一个计算节点上进行计算。运行Task的时候才会产生Shuffle
Hash Shuffle
15. key不能是Array 【key如果是Array,则就无法非常友好的计算具体的hashcode值】
16. Hash Shuffle不需要排序
17. 思考:不需要排序的Hash Shuffle是否一定比需要排序的Sorted Shuffle速度更快?不一定!如果数据规模比较小的情形下,Hash Shuffle会比Sorted Shuffle速度快(很多)!但是如果数据量大,此时Sorted Shuffle一般都会比Hash Shuffle快(很多)
【数据量大的情况下,Sorted Shuffle比Hash Shuffle快的原因:如果数据规模比较 大,可能Hash Shuffle无法处理,因为hash的方式时会有key和句柄之类,还有许 多小文件,此时,磁盘的性能会成为瓶颈,内存也会变成瓶颈。Sorted Shuffle会极 大地节省磁盘、内存的访问,更有利于更大规模的数据运算】
18. 每个ShuffleMapTask会根据key的哈希值计算出当前的key需要写入的Partition,然后把决定后的结果写入当单独的文件,此时会导致每个Task产生R(指下一个Stage的并行度)个文件,如果当前的Stage中有M个ShuffleMapTask,则会M*R个文件!!!
注意:Shuffle操作绝大多数情况下都要通过网络,如果Mapper和Reducer在同一台机器上,此时只需要读取本地磁盘即可。
Hash Shuffle的两大死穴:第一:Shuffle前会产生海量的小文件于磁盘之上,此时会产生大量耗时低效的IO操作;第二:内存不共用!!!由于内存中需要保存海量的文件操作句柄和临时缓存信息,如果数据处理规模比较庞大的话,内存不可承受,出现OOM等问题!
Sort-Based Shuffle
1,Shuffle一般包含两阶段任务:第一部分,产生Shuffle数据的阶段(Map阶段,额外补充,需要实现ShuffleManager中getWriter来写数据(数据可以BlockManager写到Memory、Disk、Tachyon等,例如像非常快的Shuffle,此时可以考虑把数据写在内存中,但是内存不稳定,建议采用MEMORY_AND_DISK方式));第二部分,使用Shuffle数据的阶段(Reduce阶段,额外的补充,需要实现ShuffleManager的getReader,Reader会向Driver去获取上一下Stage产生的Shuffle数据);
10. Spark集群部署
1, 从Spark Runtime的角度来讲由五大核心对象:Master、Worker、Executor、Driver、CoarseGrainedExecutorBackend;
2, Spark在做分布式集群系统设计的时候:最大化功能独立、模块化封装具体独立的对象、强内聚松耦合。
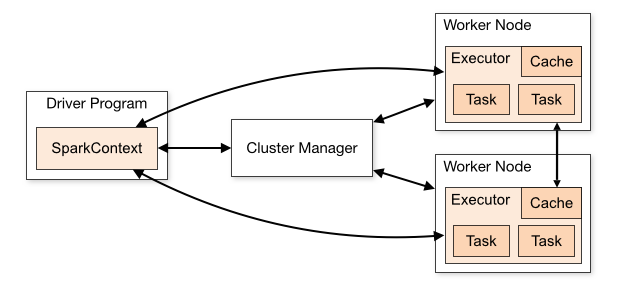
3,当Driver中的SparkContext初始化的时候会提交程序给Master,Master如果接受该程序在Spark中运行的话,就会为当前的程序分配AppID,同时会分配具体的计算资源,需要特别注意的是,Master是根据当前程序提交的配置信息来给集群中的Worker发指令分配具体的计算资源,但是,Master发出指令后并不关心具体的资源是否已经分配,转来说Master是发指令后就记录了分配的资源,以后客户端再次提交其它的程序的话就不能使用该资源了。其弊端是可能会导致其它要提交的程序无法分配到本来应该可以分配到的计算资源;最终的优势在Spark分布式系统功能若耦合的基础上最快的运行系统(否则如果Master要等到资源最终分配成功后才通知Driver的话,就会造成Driver阻塞,不能够最大化并行计算资源的使用率)。
需要补充说明的是:Spark在默认情况下由于集群中一般都只有一个Application在运行,所有Master分配资源策略的弊端就没有那么明显了。
11. SparkOn Yarn
http://bbs.pinggu.org/thread-4637621-1-1.html
1、Yarn是Hadoop推出整个分布式(大数据)集群的资源管理器,负责资源的管理和分配,基于Yarn我们可以在同一个大数据集群上同时运行多个计算框架,例如Spark,MapReduce、Storm等;
2、SparkOn Yarn运行工作流程图
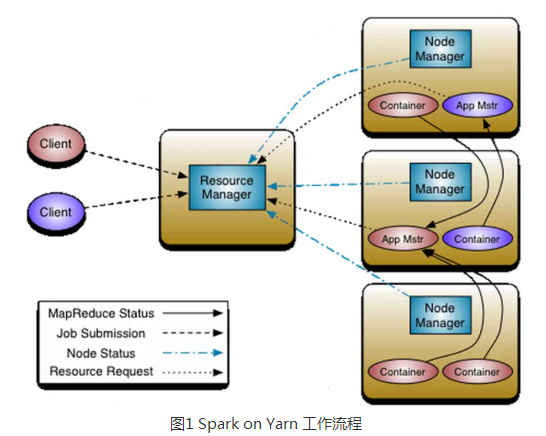
注意:Container要向NodeManager汇报资源信息,Container要向App Mstr汇报计算信息;
重构根本的思想是将 JobTracker 两个主要的功能分离成单独的组件,这两个功能是资源管理和任务调度 / 监控。新的资源管理器全局管理所有应用程序计算资源的分配,每一个应用的 ApplicationMaster 负责相应的调度和协调。一个应用程序无非是一个单独的传统的 MapReduce 任务或者是一个 DAG( 有向无环图 ) 任务。ResourceManager 和每一台机器的节点管理服务器能够管理用户在那台机器上的进程并能对计算进行组织。
事实上,每一个应用的 ApplicationMaster 是一个详细的框架库,它结合从 ResourceManager 获得的资源和 NodeManager 协同工作来运行和监控任务。
上图中 ResourceManager 支持分层级的应用队列,这些队列享有集群一定比例的资源。从某种意义上讲它就是一个纯粹的调度器,它在执行过程中不对应用进行监控和状态跟踪。同样,它也不能重启因应用失败或者硬件错误而运行失败的任务。
ResourceManager 是基于应用程序对资源的需求进行调度的 ; 每一个应用程序需要不同类型的资源因此就需要不同的容器。资源包括:内存,CPU,磁盘,网络等等。可以看出,这同现 Mapreduce 固定类型的资源使用模型有显著区别,它给集群的使用带来负面的影响。资源管理器提供一个调度策略的插件,它负责将集群资源分配给多个队列和应用程序。调度插件可以基于现有的能力调度和公平调度模型。
上图中 NodeManager 是每一台机器框架的代理,是执行应用程序的容器,监控应用程序的资源使用情况 (CPU,内存,硬盘,网络 ) 并且向调度器汇报。
每一个应用的 ApplicationMaster 的职责有:向调度器索要适当的资源容器,运行任务,跟踪应用程序的状态和监控它们的进程,处理任务的失败原因。
3,客户端Client向ResourceManager提交Application,ResourceManager接受应用并根据集群资源状况决定在某个具体Node上来启动当前提交的应用程序的任务调度器Driver(ApplicationMaster),决定后ResourceManager会命令具体的某个Node上的资源管理器NodeManager来启动一个新的JVM进程运行程序的Driver部分,当ApplicationMaster启动的时候(会首先向ResourceManager注册来说明自己负责当前程序的运行)会下载当前Application相关的Jar等各种资源并基于此决定具体向ResourceManager申请资源的具体内容,ResourceManager接受到ApplicationMaster的资源分配的请求之后会最大化的满足资源分配的请求并发送资源的元数据信息给ApplicationMaster,ApplicationMaster收到资源的元数据信息后会根据元数据信息发指令给具体机器上的NodeManager让NodeManager来启动具体的Container,Container在启动后必须向AppplicationMaster注册,当ApplicationMaster获得了用于计算的Containers后,开始进行任务的调度和计算,直到作业执行完成。需要补充说的是,如果ResourceManager第一次没有能够完全完成ApplicationMaster分配的资源的请求,后续ResourceManager发现集群中有新的可用资源时,会主动向ApplicationMaster发送新的可用资源的元数据信息以提供更多的资源用于当前程序的运行!
补充说明:
1)如果是Hadoop的MapReduce计算的话Container不可以复用,如果是Spark on Yarn的话Container可以复用;
2)Container具体的销毁是由ApplicationMaster来决定的;
3)ApplicationMaster 发指令给NodeManager让NodeManager销毁Container。
4、Spark on Yarn的运行实战:
a) Client模式:方便在命令终端
天机解密:Standalone模式下启动Spark集群(也就是启动Master和Worker)其实启动的是资源管理器,真正作业计算的时候和集群资源管理器没有任何关系,所以Spark的Job真正执行作业的时候不是运行在我们启动的Spark集群中的,而是运行在一个个JVM中的,只要在JVM所在的集群上安装配置了Spark即可!当没有启动yarn和spark-all的时候运行提交上述作业,会提示找不到Server,此时集群会一直尝试retry连接
5、Spark on Yarn模式下Driver与ApplicationMaster的关系:
a) Cluster:Driver位于ApplicationMaster进程中,我们需要通过Hadoop默认指定的8088端口来通过Web控制台查看当前的Spark程序运行的信息,例如进度、资源的使用(Cluster的模式中Driver在AppMaster中);
b)Client:Driver在提交代码的机器上,此时ApplicationMaster依旧位于集群中且只负责资源的申请和launchExecutor,此时启动后的Eexcutor并不会向ApplicationMaster进程注册,而是向Driver注册!!!
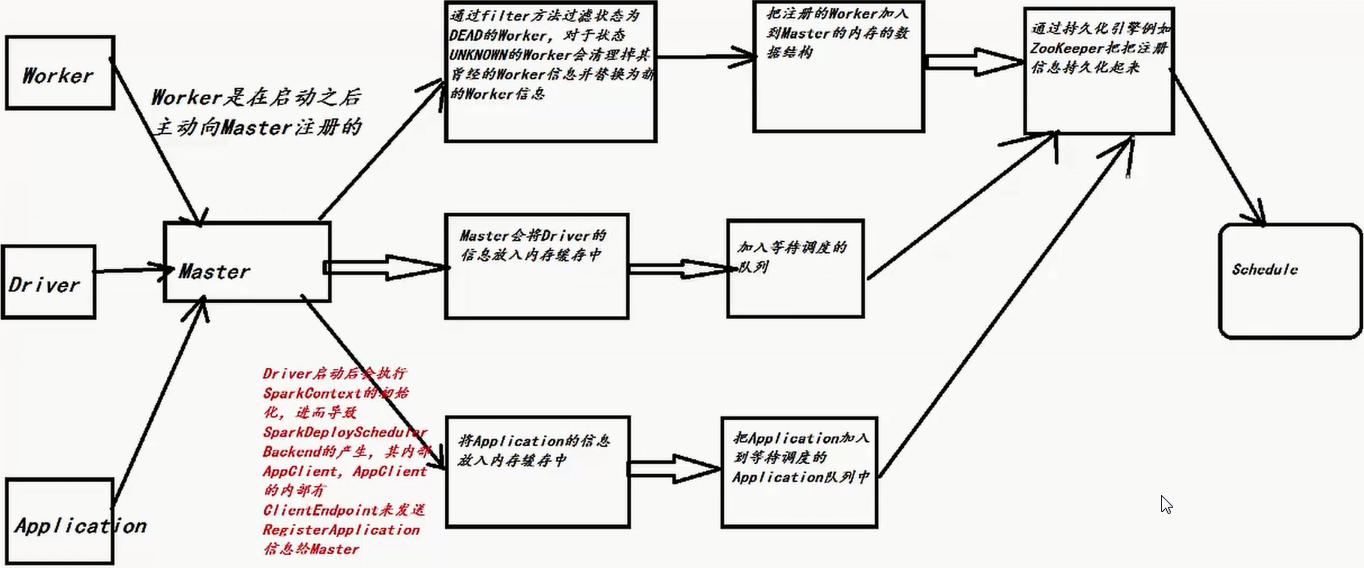
12. Master 注册机制
13. 资源调度
http://bbs.pinggu.org/thread-4638090-1-1.html
一、任务调度与资源调度的区别
1、任务调度是通过DAGScheduler、TaskScheduler、SchedulerBackend等进行的作业调度;
2、资源调度是指应用程序如何获得资源;
3、任务调度是在资源调度的基础上进行的,没有资源调度那么任务调度就成为了无源之水无本之木!
二、资源调度内幕
1)因为Master负责资源管理和调度,所以资源调度的方法shedule位于Master.scala这个类中,当注册程序或者资源发生改变的时候都会导致schedule的调用;
2)Schedule调用的时机:每次有新的应用程序提交或者集群资源状况发生改变的时候(包括Executor增加或者减少、Worker增加或者减少等);
3)当前Master必须是Alive的方式采用进行资源的调度,如果不是ALIVE的状态会直接返回,也就是Standby Master不会进行Application的资源调用!
4)使用Random.shuffle把Master中保留的集群中所有Worker的信息随机打乱;
5)接下来要判断所有Worker中哪些是ALIVE级别的Worker,ALIVE才能够参与资源的分配工作;
6)当SparkSubmit指定Driver在Cluster模式的情况下,此时Driver会加入waitingDrivers等待列表中,在每个DriverInfo的DriverDescription中有要启动Driver时候对Worker的内存及Cores的要求等内容才能launch driver,如果内存和cores没有,worker不会launch driver:如果是client模式,不会有等待提交driver,因为application提交driver就启动了。下面参数中如果有supervise,则driver挂掉后可以自动重启,前提是driver是在集群中的,重启次数好像是5次。在符合资源要求的情况下然后采用随机打乱后的一个Worker来启动Driver,Master发指令给Worker,让远程的Worker启动Driver;
7) 先启动Driver才会发生后续的一切的资源调度的模式;
8)Spark默认为应用程序启动Executor的方式是FIFO的方式,也就是所有提交的应用程序都是放在调度的等待队列中的,先进先出,只有满足了前面应用程序的资源分配的基础上才能够满足下一个应用程序资源的分配;
9)为应用程序具体分配Executor之前要判断应用程序是否还需要分配Core,如果不需要则不会为应用程序分配Executor;
10)具体分配Executor之前要对要求Worker必须是ALIVE的状态且必须满足Application对每个Executor的内存和Cores的要求,并且在此基础上进行排序产生计算资源由大到小的usableWorkers数据结构;
11)为应用程序分配Executors有两种方式,第一种方式是尽可能在集群的所有Worker上分配Executor,因为这样是更好的响应并发处理能力的,更好的利用机器的并发资源,这种方式往往会带来潜在的更好的数据本地性;
12)具体在集群上分配Cores的时候会尽可能的满足我们的要求,所以下面求了一个最小值;
13)如果是每个Worker下面只能够为当前的应用程序分配一个Executor的话,每次是分配一个Core!
14)准备具体要为当前应用程序分配的Executor信息后,Master要通过远程通信发指令给Worker来具体启动ExecutorBackend进程;
15)紧接着给我们应用程序的Driver发送一个ExecutorAdded的信息;
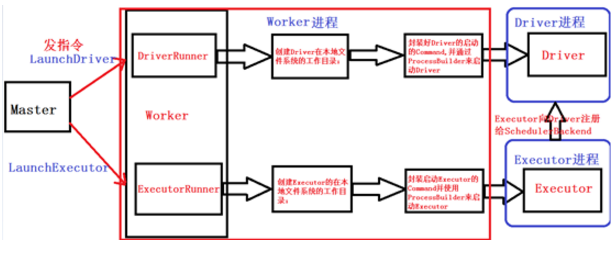
14. Worker原理
http://bbs.pinggu.org/thread-4638174-1-1.html
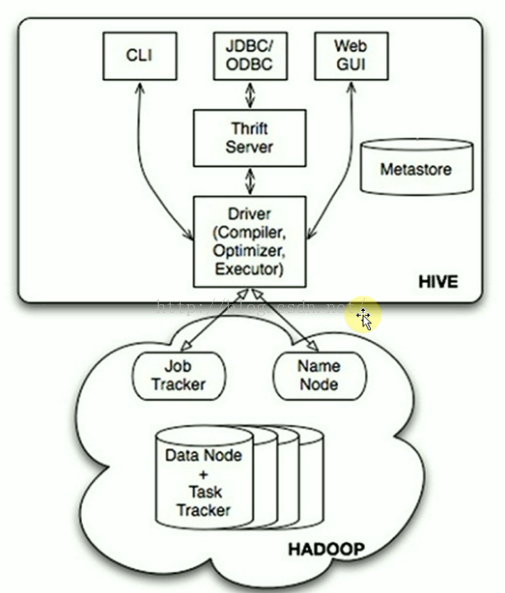
15. Hive本质
- Hive是分布式数据仓库,同时又是查询引擎,所以SparkSQL取代的只是Hives的查询引擎,在企业实际生产环境下,Hive+SparkSQL是目前最为经典的数据分析组合。
- Hive本身就是一个简单单机版本的软件,主要负责:
A) 把HQL翻译成Mapper(s)-Reducer-Mapper(s)的代码,并且可能产生很多MapReduce的JOB。
B)把生成的MapReduce代码及相关资源打包成jar并发布到Hadoop集群中运行(这一切都是自动的) - Hive本身的架构如下所示:
- 可以通过CLI(命令终端)、JDBC/ODBC、Web GUI访问Hive。JavaEE或.net程序可以通过Hive处理,再把处理的结果展示给用户。也可以直接通过Web页面操作Hive。
※ Hive本身只是一个单机版本的的软件,怎么访问HDFS的呢?
=> 在Hive用Table的方式插入数据、检索数据等,这就需要知道数据放在HDFS的什么地方以及什么地方属于什么数据,Metastore就是保存这些元数据信息的。Hive通过访问元数据信息再去访问HDFS上的数据。
可以看出HDFS不是一个真实的文件系统,是虚拟的,是逻辑上的,HDFS只是一套软件而已,它是管理不同机器上的数据的,所以需要NameNode去管理元数据。DataNode去管理数据。
Hive通过Metastore和NameNode打交道。
16. SparkSQL和DataFrame
SparkSQL之所以是除了SparkCore外最大的和最受关注的组件,原因是:
A)处理一切存储介质和各种格式的数据(同时可以方便地扩展SparkSQL的功能来支持更多类型的数据,例如Kudo,Kudo在存储和计算效率间取得了完美的平衡),包括实时数据处理。
B)SparkSQL把数据仓库的计算能力推向了新的高度。不仅有无敌的计算速度(SparkSQL比Shark快了至少一个数量级,而Shark比Hive快了至少一个数量级。尤其是在Tungsten成熟以后会更加无可匹敌)。更为重要的是把数据仓库的计算复杂度推向了历史上全新的高度(SparkSQL后续推出的DataFrame可以让数据仓库直接使用机器学习图计算等复杂的算法库来对数据仓库进行深度数据价值挖掘),Hive只是进行数据多维度查询。SparkSQL可以进行机器学习、图计算,所以是里程碑式的技术。
C)SparkSQ(DataFrame、DataSet)不仅是数据仓库的引擎,也是数据挖掘的引擎,更为重要的是SparkSQL是数据科学计算和分析引擎!!!
D) 后来的DataFrame让Spark(SQL)一举成为大数据计算引擎的技术实现霸主(尤其是在Tungsten的强力支持下)
传统数据库仅剩的应用场景:实时事务性分析。
E)Hive+SparkSQL+DataFrame是目前至少在中国所有的大数据项目至少90%无法逃脱该技术组合,
Hive负责廉价的数据仓库存储;SparkSQL负责高速计算;DataFrame负责复杂的数据挖掘;DataFrame是一个新的API
①以DataFrame形式读取本地hdfs文件
//集群模式
// val ss = SparkSession.builder
// .master("spark://Master:7077")
// .appName("Spark SQL basic example")
// .config("spark.some.config.option", "some-value")
// .getOrCreate()
//本地模式
val ss = SparkSession.builder
.master("local")
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
val df = ss.read.json("hdfs://Master:9000/library/examples/src/main/resources/people.json")
df.show()
df.printSchema()②以DataFrame形式读取本地text文件
```
val ss = SparkSession.builder
.master("local")
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
// txt文件内容
// 1 spark 7
// 2 hadoop 13
val personRDD = ss.sparkContext.textFile("/root/Software/SparkCode/test.txt")
//隐式转换 For implicit conversions from RDDs to DataFrames
import ss.implicits._
val df = personRDD.map(_.split((" "))).map(p =>Person(p(0).toInt,p(1).trim,p(2).toInt)).toDF()
df.show()
df.printSchema()
df.createOrReplaceTempView("people")
val personList = ss.sql("select * from people where age between 10 and 14")
.collect().map(item => Person(item.getAs("id"), item.getAs("name"), item.getAs("age")))
personList.foreach(println)16. Parquet
1)Parquet是列式存储格式的一种文件类型,列式存储有以下的核心优势:
a)可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量。
b)压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码(例如RunLength Encoding和Delta Encoding)进一步节约存储空间。
c)只读取需要的列,支持向量运算,能够获取更好的扫描性能。
期待的方式:DataSource -> Kafka -> Spark Streaming -> Parquet -> Spark SQL(ML、GraphX等)-> Parquet -> 其它各种Data Mining等
















 483
483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











