







1. SGD图示
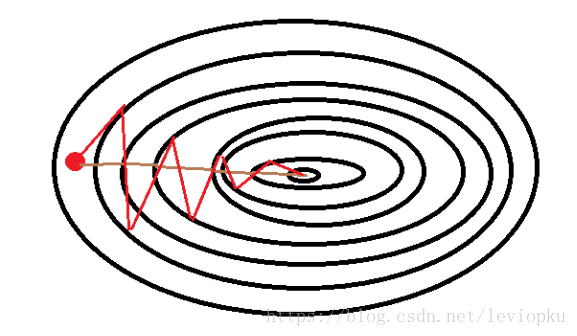
红色表示SGD的收敛路径,棕色表示梯度下降的收敛路径。普通的GD算法就是计算出每一时刻最陡的下降趋势(梯度),SGD在随机挑选某一分量的梯度方向进行收敛,详细解释可继续往下看。
2. SGD公式理解
注:这一部分引用自知乎用户Qi Qi,原回答链接
随机梯度下降主要用来求解类似于如下求和形式的优化问题:
普通梯度下降算法:
当
n
n
很大时,每次迭代计算所有的会非常耗时。随机梯度下降的想法就是: 每次在
∇fi
∇
f
i
中随机选取一个计算代替如上的
∇f
∇
f
,以这个随机选取的方向作为下降的方向。
由于
E[∇fik(wt,xik,yik)]
E
[
∇
f
i
k
(
w
t
,
x
i
k
,
y
i
k
)
]
=
∇f(wt)
∇
f
(
w
t
)
, 当选取学习率
ηt=O(1/t)
η
t
=
O
(
1
/
t
)
时,算法在期望的意义下收敛。
注意到在
wt
w
t
靠近极小值点
w∗
w
∗
时,
∇f(w∗)
∇
f
(
w
∗
)
≠ 0,这导致随机梯度下降法精度低。由于方差的存在,要使得算法收敛,就需要
ηt
η
t
随t逐渐减小。因此导致函数即使在强凸且光滑的条件下,收敛速度也只有
O(1/T)
O
(
1
/
T
)
. 后来提出的变种SAG,SVRG,SDCA都是在降方差,为了保证在
wt
w
t
→
w∗
w
∗
时,方差趋于0。以上提到的几种变种都能达到线性收敛速度。
3. momentum 动量
“动量”这个概念源自于物理学,解释力在一段时间内作用所产生的物理量。我们没必要往复杂想,其实我们可以将动量约等于惯性。我们对惯性的基本理解就是: 当你跑起来,由于惯性的存在你跑起来会比刚起步加速的时候更轻松,当你跑过头,想调头往回跑,惯性会让你拖着你。
在普通的梯度下降法
w=w+v
w
=
w
+
v
中,每次
x
x
的更新量为
如果这一时刻更新度 vt v t 与上一时刻更新度 vt−1 v t − 1 的方向相同,则会加速。反之,则会减速。加动量的优势有两点:
1. 加速收敛
2. 提高精度(减少收敛过程中的振荡)


















 4098
4098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











