







Lstm可以看成是RNN的一种特殊形式,是一种改进后的循环神经网络。
可以解决RNN 不能处理长距离依赖问题。
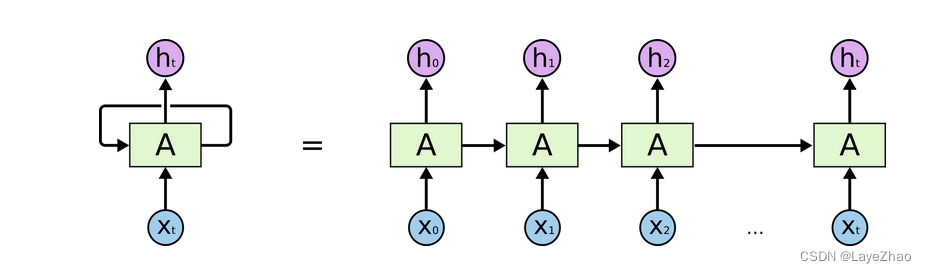
LSTM具体特征可以总结为在隐藏层传递时多了一个单元状态和三个门(遗忘门,输入门,输出门),共同作用于原始RNN的隐藏层单元。
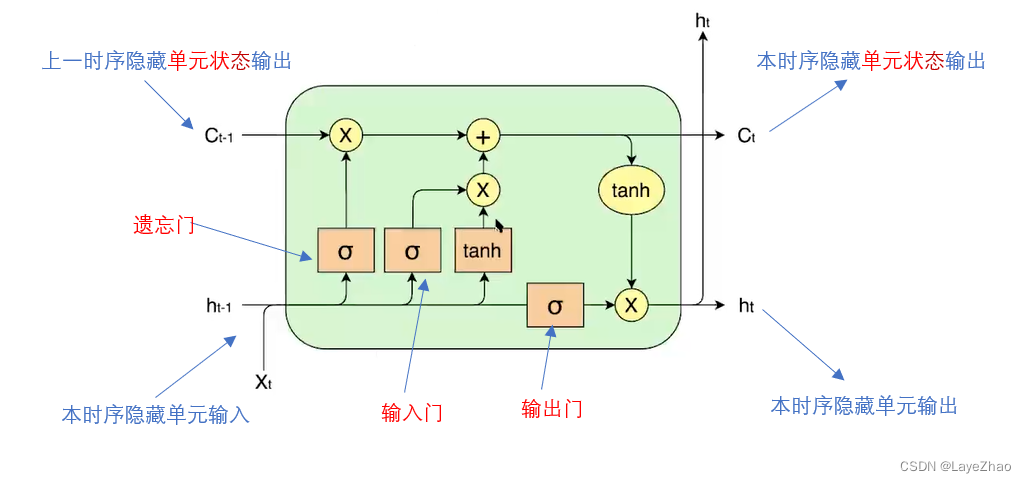
其中遗忘门 作用于上一时序隐藏状态
。决定上一时序隐藏单元状态对当前隐藏单元的作用大小。
输入门 作用于当前隐藏单元的输入
(输入为上一时序隐藏单元的输出
和当前隐藏单元的输入 )。决定当前输入对当前隐藏单元的作用大小。
遗忘门联合输入门决定了当前隐藏层状态输出 ,输出门
作用于当前输出之上,产生当前隐藏单元输出
其中 都是当前隐藏单元的输入的线性组合,再通过sigmoid函数进行归一化:
1.Pytorch中Lstm 实现----torch.nn.lstm函数
参数:
-
input_size:输入数据的特征数,上图中X的维度
-
hidden_size:隐藏单元大小,上图中h的维度
-
num_layer:隐藏层数。LSTM在空间上可多层堆叠
-
bias:偏置
-
bidirectional:是否为双向LSTM
-
batch_first:作用于输入数据时,将batch作为第一个维度
2.整个模型输入数据是个三维张量,大小为(seq_len,batch,input_size)
-
seq_len:时间步数。
相当于输入一个句子,包含几个单词。一个句子每个单词依次输入模型,在时间上产生步数。通常所有句子 padding为固定长度
-
input_size:输入数据的特征数,也是输入隐藏单元数据的大小,相当于每个单词的特征维度(的维度)
-
batch:批量大小。相当于一次输入给模型多少个句子同时处理。
例如输入以下诗句:
鹅鹅鹅
曲项向天歌
白毛浮绿水
红掌拨清波
假设每个字的特征维度是6,规定批次为4。
那么此例中:seq_len=5(第一句自动padding为5个字符),batch=4,input_size=6
每次输入模型4个字符,第一批次为:“鹅”,“曲”,“白”,“红”
那么问题来了,这4个词不在同一个句子中,彼此的隐藏状态应该相互独立,不应影响不同句子中下一个时序单词。
我们有两个记录隐藏单元数据的参数:h,c。在h,c中,同一批次中每个句子的每个单词(时序)的状态是分开保存的。
3.除了输入数据外,输入模型的还有各隐藏单元的两个初始状态( 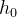 ,
, 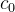 )。注意,pytorch中,我们不是必须对初始状态进行初始化。
)。注意,pytorch中,我们不是必须对初始状态进行初始化。
其大小依然是一个张量
-
h0(num_layers*num_directions,batch,hidden_size)
-
c0( num_layers*num_directions,batch,hidden_size)
num_layers:LSTM层数,隐藏单元的层数(空间维度)
hidden_size:隐藏单元的维度( 的维度)
batch:批量大小
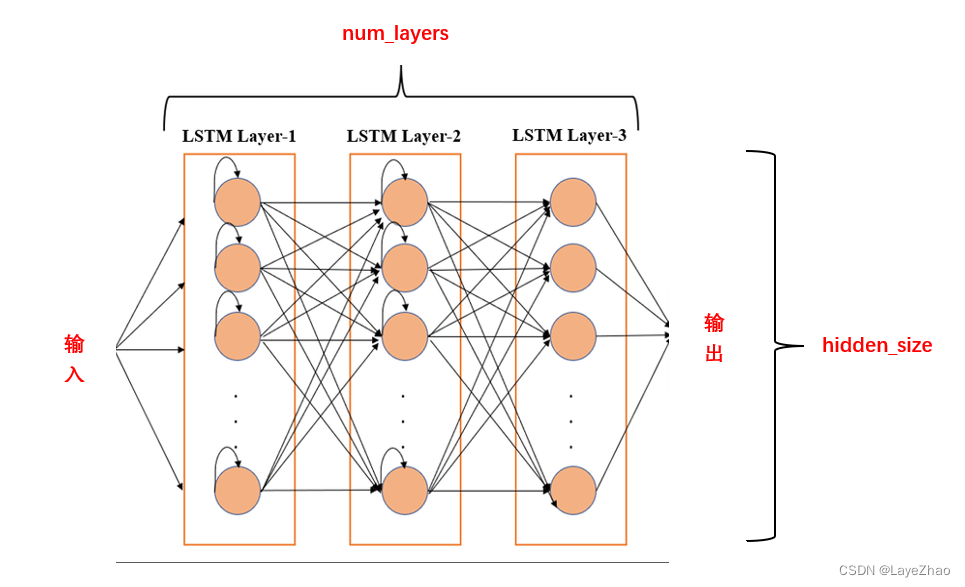
另一维度batch(批量大小)在图中无法显示,它其实是保证同一批次间不同单词都有自己的状态数据。你可以想象同一时序重复上图batch次。
4.LSTM的输出数据也是一个三维张量,大小为(seq_len,batch,num_directions*hidden_size)
内容为最后一层隐藏单元的输出
参数意义同上
此外,
5.输出数据还有(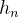 ,
,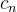 ),保存第n个时序中各隐藏单元状态
),保存第n个时序中各隐藏单元状态
其大小为:
-
hn(num_layers*num_directions,batch,hidden_size)
-
cn( num_layers*num_directions,batch,hidden_size)
参数意义同上
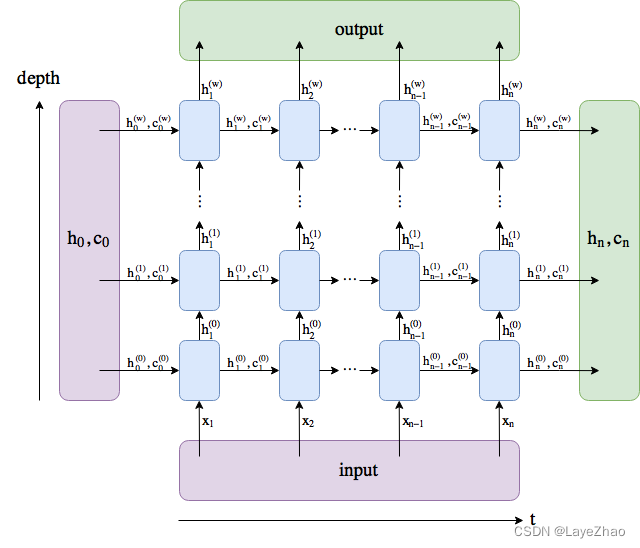
将上图旋转90度,再扩展为不同时序。输入,输出,隐藏单元输出和状态整体如下图所示
6.一个调用例子:
input_size=300;hidden_size=100;num_layers=1;batch_size=64;seq_len=7

7.一个应用实例
利用LSTM模型作为encoder层,拼接线性变换模型(nn.Linear)作为decoder层,实现一个情感分类模型,
以下是模型创建的代码片段:
class SentimentNet(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
bidirectional, weight, labels, use_gpu, **kwargs):
super(SentimentNet, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.use_gpu = use_gpu
self.bidirectional = bidirectional
self.embedding = nn.Embedding.from_pretrained(weight)
self.embedding.weight.requires_grad = False
self.encoder = nn.LSTM(input_size=embed_size, hidden_size=self.num_hiddens,
num_layers=num_layers, bidirectional=self.bidirectional,
dropout=0)
if self.bidirectional:
self.decoder = nn.Linear(num_hiddens * 4, labels)
else:
self.decoder = nn.Linear(num_hiddens * 2, labels)
def forward(self, inputs):
embeddings = self.embedding(inputs)
states, hidden = self.encoder(embeddings.permute([1, 0, 2]))
encoding = torch.cat([states[0], states[-1]], dim=1)
outputs = self.decoder(encoding)
return outputs
数据清洗和模型训练等其他代码请参见此项目















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









