







最开始学习爬虫的时候,我用的是urllib2和BeautifulSoup这两个库,使用这两个库的时候,所有爬虫的框架都要自己写,一开始还觉得没什么,到最后写的越来越多的时候就觉得很麻烦,因为我的重点是爬取数据分析数据啊,不是浪费时间去写什么爬虫框架。
后来了解到scrapy这个框架,用这个框架写爬虫的话感觉真的非常爽,因为它真的很高效。比如原来你用urllib2和BeautifulSoup写个200行的爬虫代码,用scrapy40行左右就可以搞定。
一、了解scrapy框架
1、什么是scrapy
scrapy是一个用python编写的,轻量级,简单轻巧,使用简单的爬虫框架。它使用Twisted异步网络库处理网络通讯。scrapy的框架如下:
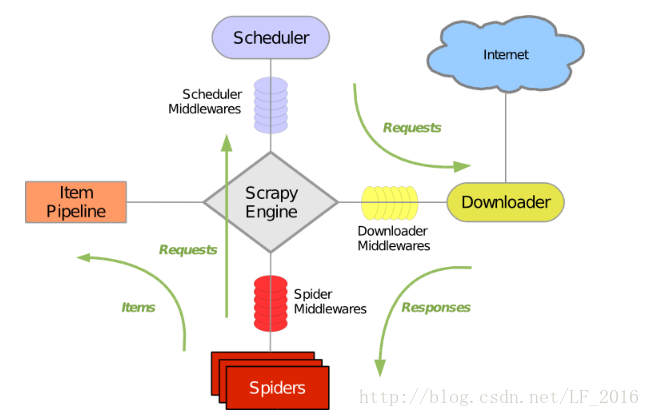
2、scrapy中的各组件
2.1、Scrapy Engine
Scrapy的引擎,用来处理整个系统的数据流处理。
2.2、Scheduler
调度器,Scheduler接受从引擎发送过来的请求,压入队列之中,在引擎再次请求的时候返回给引擎。
2.3、Downloader
拿到请求之后,下载网页,并将下载的网页送给Spider进行处理。
2.4、Spiders
Spiders是蜘蛛,主要是解析网页的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









