






Java8--Stream流
一、简介
stream流操作是Java 8提供一个重要新特性,它允许开发人员以声明性方式处理集合,其核心类库主要改进了对集合类(Collection)的 API和新增Stream操作。Stream类中每一个方法都对应集合上的一种操作。将真正的函数式编程引入到Java中,能 让代码更加简洁,极大地简化了集合的处理操作,提高了开发的效率和生产力。
二、概念
stream是数据渠道,用于操作数据源(集合、数组)所生产的元素序列。这一类操作称作局和操作
操作基本流程:
1、将原始数据或数组对象转换为stream流。(获取)
2、对stream流中的元素进行一系列的过滤、查找等中间操作(Intermediate Operations),然后仍返回 一个Stream流对象 (中间操作)
3、对stream流进行统计、遍历、收集等终结操作(Terminal Operation)获取想要的结果。(搜集)
三、种类
stream流分为二种流
-
stream 顺序流
主线程按顺序对流执行操作。
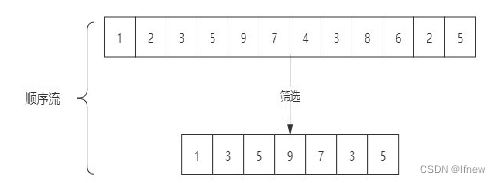
-
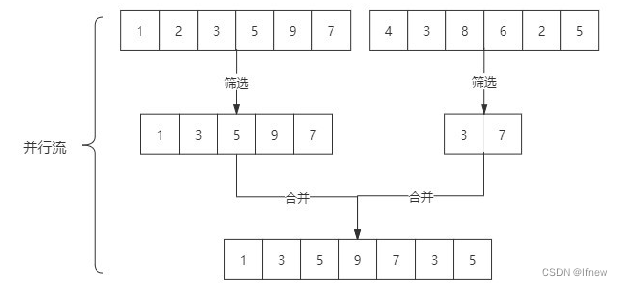
parallelStream 并行流
内部以多线程并行执行的方式对流 进行操作,但前提是流中的数据处理没有顺序要求。如果流中 的数据量足够大,并行流可以加快处速度。
四、获取流的3种方式
- 所有的Collection集合都可以使用接口中的默认方法stream()获取Stream流对象。该方法来自StreamSupport类的静态方法。
List<String>list=ArrayList<String>()
//生成流
list.stream
- Stream接口的of()静态方法可以获取基本类型和包装类数组、引用类型数组和单个元素的stream对象。of(T… values)方法为可变参数或of(T t)。
stream<Integer>stream=Stream.of(1,2,3,4,5,6);
stream.forEach(System.out::println)
- Arrays数组工具类的stream()静态方法可以获取数组元素的stream流对象。
Integer[] arr={1,2,3,4,5,6,7}
Stream<Integer> stream=Arrays.stream(arr)
五、stream流中间操作
- 筛选(filter)
//挑选红色的橙子
oranges.stream().filter(a -> a.getColor().equals("red")).forEach(System.out::println);
System.out.println("----------------");
- 排序(sorted)
// 按颜色排序
oranges.stream().sorted(Comparator.comparing(Orange::getColor)).forEach(System.out::println);
System.out.println("----------------");
- 截取(limit)
//只要前5个橙子
oranges.stream().sorted(Comparator.comparing(Orange::getWeight).reversed()).sorted(Comparator.comparing(Orange::getColor)).limit(5).forEach(System.out::println);
System.out.println("----------------");
- 跳过( skip)
//想要前五个中的后两个橙子
oranges.stream()
.sorted(Comparator.comparing(Orange::getWeight).reversed())
.sorted(Comparator.comparing(Orange::getColor))
.limit(5)
.skip(3)
.forEach(System.out::println);
System.out.println("----------------");
- 合并(concat)
//合并2个集合
ArrayList<String> arrayList1=new ArrayList<>();
arrayList1.add("橘子A")
arrayList1.add("橘子B")
ArrayList<String> arrayList1=new ArrayList<>();
arrayList1.add("橘子C")
arrayList1.add("橘子D")
Stream.concat(arrayList1.stream(),arrayList2.stream().forEach(s-->System.out.println(s))
- 收集(collect)
//将数据过滤重新归集到新的集合中
ArrayList<DownData> arrayList=new ArrayList<>();
arrayList.stream()
.filter(distinctByKey(DownData::getDataId))
.collect(Collectors.toList())
- 规约(reduce)
//将流规约成一个值的操作,用函数式编程的术语来说叫折叠
List<Integer>numList=Arrays.asList(1,2,3,4,5);
int result =numList.stream().reduce((a,b)->a+b).get();
System.out.println(result);
六、示例
提示:该示例因为业务中需要将两个集合通过一个字段关起来并合并
//集合A
List<TotalPerformanceCross> totalPerformanceCrossList = MongoDBUtil.conditionalQuery(new Query(criteria), TotalPerformanceCross.class, "TotalPerformanceCross");
//集合B
List<SysDimensionDataMarket> sysDimensionDataMarketList = MongoDBUtil.conditionalQuery(new Query(criteria1), SysDimensionDataMarket.class, "SysDimensionDataMarket");
// 使用 Stream 进行关联和合并操作
//以集合A为主集合
List<SysDimensionDataMarket> result = sysDimensionDataMarketList.stream()
.map(sysDimensionDataMarket -> {
// 根据关联字段查找 totalPerformanceCrossList 中的匹配记录
TotalPerformanceCross matchedRecord = totalPerformanceCrossList.stream()
//设置关联的字段
.filter(totalPerformance -> totalPerformance.getPmLineCode().equals(sysDimensionDataMarket.getPmLineCode()))
.findFirst() // 找到第一个匹配的记录
.orElse(null);
//如果集合B没有一对象和集合A关联这将合并的到A的字段值设置为0
if (matchedRecord == null) {
// 如果没有匹配的记录,将四个字段设置为0
sysDimensionDataMarket.setPerformance(0);
sysDimensionDataMarket.setMonthPerformance(0);
sysDimensionDataMarket.setFullMonthPerformance(0);
sysDimensionDataMarket.setGrowthRate(0);
} else {
// 如果有匹配的记录,根据需要做相应的操作
sysDimensionDataMarket.setPerformance(matchedRecord.getPerformance());
sysDimensionDataMarket.setMonthPerformance(matchedRecord.getMonthPerformance());
sysDimensionDataMarket.setFullMonthPerformance(matchedRecord.getFullMonthPerformance());
sysDimensionDataMarket.setGrowthRate(matchedRecord.getGrowthRate());
}
return sysDimensionDataMarket;
})
.collect(Collectors.toList());
return result;















 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









