







1.concat函数(多列合并拼接)
用||或concat函数
select concat(id,username) str from app_user;
select id||username str from app_user;
2.wm_concat函数
函数wm_concat(列名),该函数可以把列值以","号分隔起来,并显示成一行。
//2.1 行转列 ,默认逗号隔开
select wm_concat(name) name from Table;
//2.2 逗号替换成"|"
select replace(wm_concat(name),',','|') from Table;
//2.3 逗号替换为’,‘ 便于 in 查询时使用。
select ''''||replace(wm_concat(name), ',' , ''',''')||'''' name from Table
//2.4 按ID分组合并name
select id,wm_concat(name) name from Table group by id;
3.pivot 列转行
pivot(聚合函数 for 列名 in(类型)) ,其中 in('') 中可以指定别名,in中还可以指定子查询。
例:select * from (select name, nums from demo) pivot (sum(nums) for name in ('苹果' 苹果, '橘子', '葡萄', '芒果'));
4. unpivot 行转列
unpivot没有聚合函数,xiaoshou、jidu字段也是临时的变量。
例:select id , name, jidu, xiaoshou from Fruit unpivot (xiaoshou for jidu in (q1, q2, q3, q4) )
5.TRANSLATE()函数
描述:文本替换函数。
使用方式:
TRANSLATE(列/字符串,'待转换值/字段,'预转换值');例1:SELECT 'ABCDEFGH', TRANSLATE('ABCDEFGH', 'AB', '**') FROM DUAL;
解析:上述SQL将AB转换为**,便于理解,不多解释。
例2:SELECT 'ABCDEFGH', TRANSLATE('ABCDEFGH', 'AE', '**') FROM DUAL;
SELECT 'ABCDEFGH', TRANSLATE('ABCDEFGH', 'AE', '12') FROM DUAL;
解析:图一是将AE转换为**,观察可知前者待转换值与预转换值为字符一一对应,互补打扰;图二是将AE转换为12,观察可知待转换值与预转换值的对应关系都是从左至右一一对相应。
例3:SELECT 'ABCDEFGH', TRANSLATE('ABCDEFGH', 'AE', '*') FROM DUAL;
解析:待转换值字符数量大于预转换值字符数量,自动补(空白,不占据位置),效果如上:字符A转换为*,字符E消失了。
例4:SELECT 'ABCDEFGH', TRANSLATE('ABCDEFGH', 'AE', '123456') FROM DUAL;
解析:待转换值字符数量小于预转换值字符数量,效果如上:字符A转换为1,字符E转换为2,其余预转换值无效。



6.ROW_NUMBER()函数
描述: 在Oracle数据库中,
ROW_NUMBER()函数是用于为结果集中的每一行分配一个唯一的序号的。这个函数可以在查询中使用,以便在分组、排序或其他操作中生成带有行号的结果集。语法:
ROW_NUMBER() OVER ([PARTITION BY partition_expression] [ORDER BY order_expression [ASC | DESC]] [START WITH start_number] [INCREMENT BY increment])参数说明:
PARTITION BY partition_expression:这个可选参数允许你将结果集划分为多个分区,并为每个分区中的行分配行号。例如,如果你想为每个部门的员工分配行号,可以使用PARTITION BY department_id。
ORDER BY order_expression [ASC | DESC]:这个可选参数用于指定行号的排序顺序。默认情况下,行号按照升序(ASC)分配。如果你想按照降序(DESC)分配行号,可以在ORDER BY子句后添加DESC关键字。
START WITH start_number:这个可选参数允许你指定行号的起始值。默认情况下,行号从1开始。
INCREMENT BY increment:这个可选参数允许你指定行号的增量值。默认情况下,行号逐行递增使用场景实例:获取每个分组中的一条数据内容。
使用示例:
SELECT * FROM ( SELECT your_columns, ROW_NUMBER() OVER (PARTITION BY group_column ORDER BY order_column) AS rn FROM your_table ) t WHERE rn = 1;示例说明:
your_columns:要选择的列。
group_column:用于分组的列。
order_column:用于确定每个分组中行顺序的列。
your_table:要查询的表名。
7.dbms_lob.instr() 函数
描述: 在Oracle中,
dbms_lob.instr个函数用于在大型对象(LOB)数据类型中进行字符串搜索。它可以用于在BLOB、CLOB和NCLOB数据类型中查找一个指定的子字符串,并返回该子字符串在LOB数据中的位置。该函数返回一个表示子字符串在LOB数据中位置的数字。如果找到匹配项,则返回该位置的字符数;否则返回0。语法:
dbms_lob.instr( locator in clob, string in varchar2, start in number, nth_match in number default 1, compare in number default dbms_lob.binary_compare ) return number;参数说明:
locator:一个有效的CLOB、BLOB或NCLOB列的locator。它是一个指向LOB数据的指针。
string:要搜索的子字符串。
start:指定搜索的起始位置,以字符数为单位。如果为0或负数,则从LOB数据的开头开始搜索。
nth_match:指定要返回的匹配项的序号。如果省略或为0,则只返回第一个匹配项。如果为正数,则返回指定序号的匹配项。
compare:指定用于比较子字符串和LOB数据的比较方法。可以是指定比较方法的静态函数,例如dbms_lob.binary_compare或dbms_lob.text_compare。使用场景:获取一个字符串中,某一字符串所在位置,或判断某字符串是否存在
使用实例:
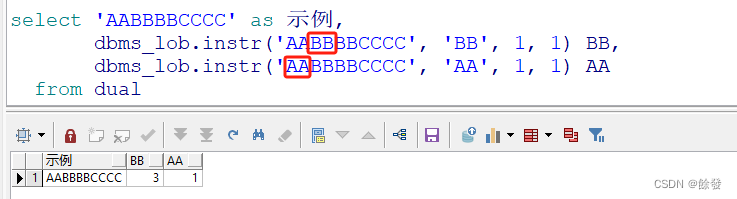
8.utl_raw.cast_to_raw() 函数
描述:
UTL_RAW.CAST_TO_RAW是Oracle数据库中的一个函数,用于将指定的数据类型转换为RAW类型。语法:
UTL_RAW.CAST_TO_RAW(argument IN RAW) RETURN RAW;参数说明:
使用场景:将某一字符串转换为 RAW 类型。
使用示例:
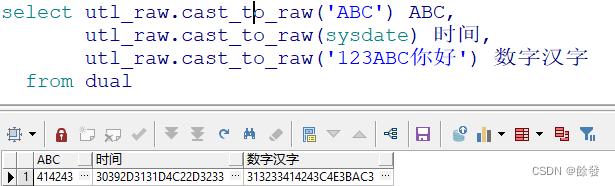
9.REGEXP_SUBSTR()函数
描述:Oracle的REGEXP_SUBSTR()函数用于在字符串中查找符合正则表达式模式的子字符串,并返回第一个匹配项。它可以使用正则表达式语法来定义搜索模式。
语法:
REGEXP_SUBSTR(source_string, search_pattern [, position [, occurrence [, match_param ]]])参数说明:
source_string:要搜索的源字符串。
search_pattern:要查找的正则表达式模式。
position(可选):指定在源字符串中开始搜索的位置,默认为 1(从第一个字符开始)。
occurrence(可选):指定要返回的匹配项的序号,默认为 1(第一个匹配项)。
match_param(可选):指定匹配的参数,可以是以下之一:
'i':执行不区分大小写的匹配。
'c':区分大小写的匹配。
'n':执行不区分大小写和不区分音标的匹配。
'm':多行模式,将元字符视为行边界。应用场景:
使用示例:
select 'W25689Q-X-swsw' 原值, REGEXP_SUBSTR('W25689Q-X', '[^-X]+', 1, 1) 展示 from dual;

10.regexp_replace()函数
描述:
REGEXP_REPLACE()是一个用于在字符串中替换与正则表达式模式匹配的部分的函数。它在 Oracle、MySQL 和 PostgreSQL 等数据库中都有支持。语法:
REGEXP_REPLACE(source_string, search_pattern, replacement_string [, position [, occurrence [, match_param ]]])参数说明:
source_string:要进行替换操作的源字符串。search_pattern:要搜索的正则表达式模式。replacement_string:替换匹配部分的字符串。position(可选):指定在源字符串中开始搜索的位置,默认为 1(从第一个字符开始)。occurrence(可选):指定要替换的匹配项的序号,默认为 1(第一个匹配项)。match_param(可选):指定匹配的参数,可以是以下之一:
'i':执行不区分大小写的匹配。'c':区分大小写的匹配。'n':执行不区分大小写和不区分音标的匹配。'm':多行模式,将元字符视为行边界。应用场景:
使用示例:
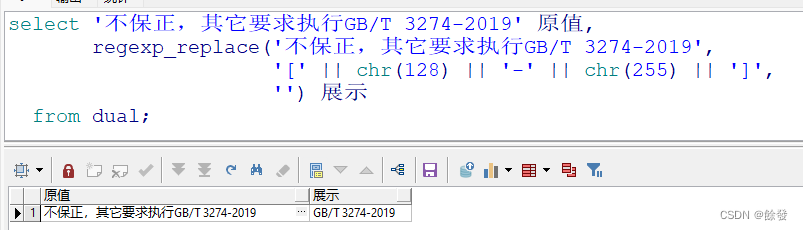















 245
245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









