






 文章介绍了倒排索引的概念,作为优化搜索效率的工具,对比了正排索引的局限性,并详细阐述了倒排索引的存储结构和优化,包括邻接矩阵和邻接表的类比。同时,提到了在MySQL中全文索引的应用,以及不同版本对全文索引的支持情况和配置细节。
文章介绍了倒排索引的概念,作为优化搜索效率的工具,对比了正排索引的局限性,并详细阐述了倒排索引的存储结构和优化,包括邻接矩阵和邻接表的类比。同时,提到了在MySQL中全文索引的应用,以及不同版本对全文索引的支持情况和配置细节。
倒排索引
正排索引
说倒排索引之前,首先要说正排索引。。
举个例子:
我们有一批文档数据,和文档词汇,如下
| 文档ID | 文档内容 |
|---|---|
| 1 | 今天天气真好 |
| 2 | 北京天气晴 |
| 3 | 北京欢迎你 |
| 4 | 苹果公司 |
这样,我们就可以通过id来获取内容了,我们传统的数据库表,图书的分类信息和书名信息其实都是正排索引。
词汇文档矩阵
你可能以为上面已经可以很好的完成日常的检索需求了,直到有一天,你需要检索包含某个关键字的文档,你会发现,上面的索引毫无用处,你还是需要遍历所有的文档内容。这个时候,你发现,其实你检索的主题或者单位其实是一个个的单词,因此,我们可以构建一个词汇文档矩阵,记录词汇和文档之间的关系,横坐标为文档id,纵坐标为具体词汇如下:
| 1 | 2 | 3 | 4 | |
|---|---|---|---|---|
| 今天 | ✓ | |||
| 天气 | ✓ | ✓ | ||
| 真好 | ✓ | |||
| 北京 | ✓ | ✓ | ||
| 晴 | ✓ | |||
| 欢迎 | ✓ | |||
| 你 | ✓ | |||
| 苹果 | ✓ | |||
| 公司 | ✓ |
这样的话,当你需要检索天气这个关键字的时候,你很容易就可以得到文档1和文档2就是你需要的结果。
看上去是不是很像邻接矩阵?
ps:上述的分词是我随便分的,中文的分词是个很难搞的事情,比如『真好』就可以成『真』、『好』、『真好』,这样就会得到不同的结果,这也是我觉得中文的自然语言处理比英文麻烦的原因之一,毕竟,英文天生就是一个一个词汇组成。
这种实现方法十分简单,但是却具有一个巨大的缺陷。如果我们的词汇量有20万个,文档量有100万个,那么我们需要的存储空间大小就至少要20万*100万=2000亿个字节,也就是至少186GB的信息量,这还搞个锤子?
倒排索引
那么我们要如何优化这个结构呢?我们不难发现这个矩阵其实具有高度的稀疏性(大量的值为0)。毕竟不可能每本书都有20万个不同的词,如果考虑到大量的论文或者博客的话,可能平均一篇文献中能有1000个不一样的词都很不容易了。这就意味着这个矩阵中99%的元素都为0。
上面我们提到,词汇文档矩阵很像一个邻接矩阵,邻接矩阵还有个兄弟,叫做邻接表,非常的适合存储稀疏矩阵。
我们可以模仿邻接表来存储,因此,上面这个矩阵我们可以存成下面的格式:
| 单词 | 文档id |
|---|---|
| 今天 | 1 |
| 天气 | 1, 2 |
| 真好 | 1 |
| 北京 | 2, 3 |
| 晴 | 2 |
| 欢迎 | 3 |
| 你 | 3 |
| 苹果 | 4 |
| 公司 | 4 |
其实,上面这个表格就是所谓的倒排索引了。
所谓倒排索引,就在辅助表中存储了单词与单词自身在一个或多个文档中所在位置之间的映射,这通常利用关联数组实现,拥有两种表现形式:
inverted file index:{单词,单词所在文档的id}
full inverted index:{单词,(单词所在文档的id,再具体文档中的位置)}
对于 inverted file index 的关联数组
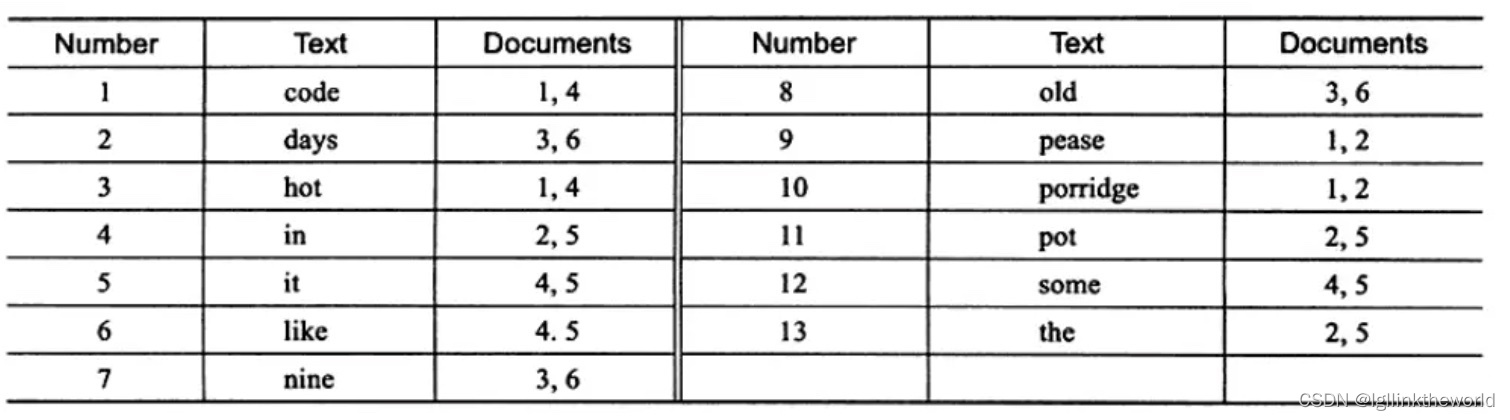
上图为 inverted file index 关联数组,可以看到其中单词"code"存在于文档1,4中,这样存储再进行全文查询就简单了,可以直接根据 Documents 得到包含查询关键字的文档;而 full inverted index 存储的是对,即(DocumentId,Position),因此其存储的倒排索引如下图,如关键字"code"存在于文档1的第6个单词和文档4的第8个单词。相比之下,full inverted index 占用了更多的空间,但是能更好的定位数据,并扩充一些其他搜索特性。
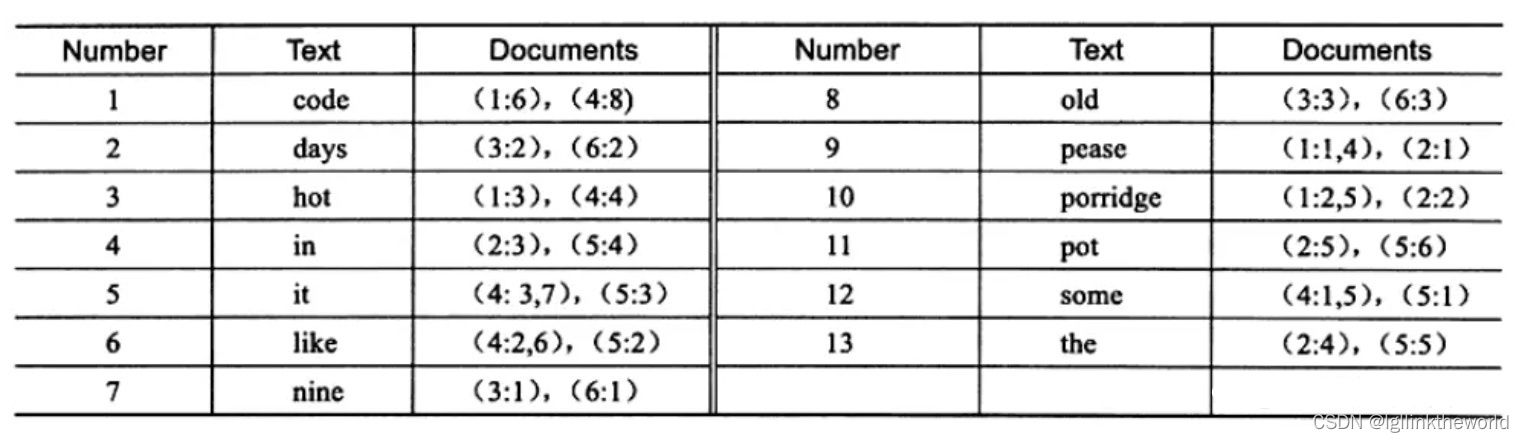
以上就是倒排索引的一些基本概念。其实倒排索引是一个很早就被人发明出的索引模型,在1958年IBM就在一次会议上展示了一台“自动索引机器”。虽然这种索引方式诞生的很早,但是至今依旧是全文索引的重要的基础之一。
倒排索引广泛应用于各种全文搜索中,注明的elasticsearch就使用了倒排索引,有兴趣可以阅读一下elasticsearch 倒排索引原理。
全文索引
全文索引(Full-Text Search)是将存储于数据库中的整本书或整篇文章中的任意信息查找出来的技术。它可以根据需要获得全文中有关章、节、段、句、词等信息,也可以进行各种统计和分析。
版本支持
MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引,InnoDB存储引擎并不支持全文索引技术,大多数的用户转向MyISAM存储引擎,虽然可以通过表的拆分,将进行全文索引的数据存储为MyIsam表,这样方式解决逻辑业务的需求,但是却丧失了INNODB存储引擎的事务性;
MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引;
只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
使用全文索引
约束条件
- 全文索引仅支持对一列进行设置,如需对多个列创建全文索引,可通过在多个列上单独创建全文索引实现。
- 全文索引只支持varchar类型的列,包括varchar,char,text。
首先创建表,插入测试数据
create table test (
id int(11) unsigned not null auto_increment,
content text not null,
primary key(id),
fulltext key content_index(content)
) engine=Innodb default charset=utf8;
insert into test (content) values ('a'),('b'),('c');
insert into test (content) values ('aa'),('bb'),('cc');
insert into test (content) values ('aaa'),('bbb'),('ccc');
insert into test (content) values ('aaaa'),('bbbb'),('cccc');
按照全文索引的使用语法执行下面查询:
select * from test where match(content) against('a');
select * from test where match(content) against('aa');
select * from test where match(content) against('aaa');
结果发现只有最后那条SQL有一条记录,为什么呢?
这个问题有很多原因,其中最常见的就是 最小搜索长度 导致的。另外插一句,使用全文索引时,测试表里至少要有 4 条以上的记录,否则,会出现意想不到的结果。
MySQL 中的全文索引,有两个变量,最小搜索长度和最大搜索长度,对于长度小于最小搜索长度和大于最大搜索长度的词语,都不会被索引。通俗点就是说,想对一个词语使用全文索引搜索,那么这个词语的长度必须在以上两个变量的区间内。
这两个的默认值可以使用以下命令查看
show variables like '%ft%';
可以看到这两个变量在 MyISAM 和 InnoDB 两种存储引擎下的变量名和默认值
// MyISAM
ft_min_word_len = 4;
ft_max_word_len = 84;
// InnoDB
innodb_ft_min_token_size = 3;
innodb_ft_max_token_size = 84;1234567
可以看到最小搜索长度 MyISAM 引擎下默认是 4,InnoDB 引擎下是 3,也即,MySQL 的全文索引只会对长度大于等于 4 或者 3 的词语建立索引,而刚刚搜索的只有 rabbit 的长度大于等于 3。
配置最小搜索长度
全文索引的相关参数都无法进行动态修改,必须通过修改 MySQL 的配置文件来完成。修改最小搜索长度的值为 1,首先打开 MySQL 的配置文件 /etc/my.cnf,在 [mysqld] 的下面追加以下内容
[mysqld]
innodb_ft_min_token_size = 1
然后重启 MySQL 服务器,并修复全文索引。注意,修改完参数以后,一定要修复下索引,不然参数不会生效。
两种修复方式,可以使用下面的命令修复
repair table productnotes quick;
或者直接删掉重新建立索引,再次执行上面的查询,就都可以查出来了。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









