







目录
我记得10年前Windows上装Hadoop得借助cygwin,现在不用了。现在装起来更容易了,今天试了一下并记录一下过程免得忘了。当然win上玩Hadoop多半为了学习,和之前Windows上安装HBASE作一个呼应。
百度一下还是很多的,我参考的主要是两篇:
这两篇的过程居然还有一些不一样,经过尝试,发现各有一些没考虑到的,分享一下我的踩坑过程
0. 安装Java
这一步没什么好说的,我安装的是jdk1.8u202, 可以在华为这下载到。
安装完了配置一下环境变量的JAVA_HOME,并且把 %JAVA_HOME%\bin 添加到Path里。(注意JAVA_HOME不能有空格,否则会出现 Error: JAVA_HOME is incorrectly set. )解决方法:C:\Program Files\Java\jdk1.8.0_202 改为 C:\PROGRA~1\Java\jdk1.8.0_202JAVA_HOME is incorrectly set. Please update C:\hadoop\conf\hadoop-env.cmd解决方法_小菜鸟磊代码的博客-CSDN博客![]() https://blog.csdn.net/weixin_45631366/article/details/106089563
https://blog.csdn.net/weixin_45631366/article/details/106089563
1. 安装Hadoop
1.1 下载Hadoop
从官方渠道 https://archive.apache.org/dist/hadoop/common/ 下载,速度较慢可以先用百度网盘离线下载
然后配置一下这个目录到环境变量的 HADOOP_HOME 。并且把 %HADOOP_HOME%\bin 添加到Path里。
1.2 下载winutils
下载Windows专用的winutils.exe和hadoop.dll 两个文件放到 %HADOOP_HOME%\bin 目录下和 C:\Windows\System32 目录下(只放bin里,不放system32,哪怕配置过Path环境变量也不够,后面测试MapReduce就报错了)。这里需要对应winutils和Hadoop的版本。看winutils的github这里,GitHub - vhma/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windowswinutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows - GitHub - vhma/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows![]() https://github.com/vhma/winutils . 如果上不去,直接看这里:Hadoop 之 winutils_电光闪烁的博客-CSDN博客
https://github.com/vhma/winutils . 如果上不去,直接看这里:Hadoop 之 winutils_电光闪烁的博客-CSDN博客![]() https://blog.csdn.net/yang_shibiao/article/details/122620656。
https://blog.csdn.net/yang_shibiao/article/details/122620656。
这就是为啥我选的Hadoop版本是3.1.2。
2. 配置Hadoop
配置文件都在%HADOOP_HOME%\etc\hadoop路径下
2.1 hadoop-env.cmd
因为环境变量配了JAVA_HOME, 所以这个文件不用改
2.2 创建数据目录
在%HADOOP_HOME%下创建tmp和 data目录,在data下创建namenode和datanode目录。其实目录在哪无所谓,后面路径写对就行。
2.3 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>D:/bigdata/hadoop-3.1.2/tmp</value>
</property>
</configuration>
这里路径分隔符可以写“\”,建议还是用“/” ,因为下面的hdfs-site就不能用 “\”。
2.4 hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/bigdata/hadoop-3.1.2/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/bigdata/hadoop-3.1.2/data/datanode</value>
</property>
</configuration>
这里连盘符前都要加 “/”
3. 启动测试
到这里其实就可以用了。准备开始,建议用管理员权限打开CMD。
3.1 namenode格式化
hdfs namenode -format执行下去如果没问题,可能会遇到一个Y or N 的选择,y就行
3.2 启动Hadoop
执行start-all.cmd
%HADOOP_HOME%\sbin\start-all.cmd它会启动4个进程:

如果需要关闭,用stop-all.cmd就行,它会关掉4个打开的进程。
3.3 查看webui
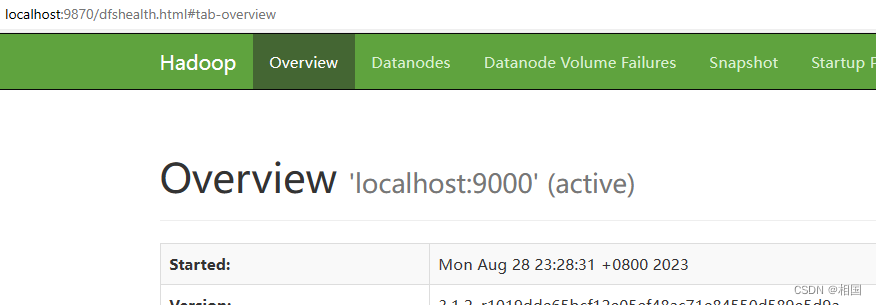
hdfs的地址是:http://localhost:9870/
yarn的地址是:http://localhost:8088/cluster

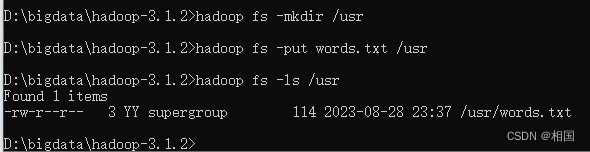
3.4 测试hdfs
3.5. 测试MapReduce
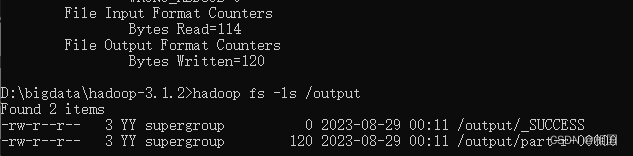
通过自带的example的运行wordcount,这里是在%HADOOP_HOME%目录下
hadoop jar share\hadoop\mapreduce\hadoop-mapreduce-examples-3.1.2.jar wordcount /usr/words.txt /output然后很快就会看到运行日志,包括结果也出来了
你以为这就OK了,其实没结束
4. 还没结束
4.1 YARN的webui没看到任务
运行了wordcount的MapReduce作业,怎么会看不到job历史,包括有些人也遇到过这个。找到一个解决方案(可能只配置这里还不够):Yarn UI 不显示任务 - 工克己 - 博客园 (cnblogs.com)
配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
估计是开启由YARN管理MapReduce计算程序,这样才能在YARN的任务队列里看到。
那么yarn-site.xml是不是也要配,顺便一起吧
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>
关了重启动Hadoop(重启Hadoop会遇到过各种各样的问题,其中一个hdfs不能操作了:Name node is in safe mode. 遇到这个就删了数据目录重新格式化....还包括4个进程可能不能正常stop掉等等。)
删掉/output目录,再次运行wordcount,报错了,长篇大论意思是yarn管理的container启动不起来,主要信息是 Exception message: CreateSymbolicLink error (1314): ???????????
里面两个方法,我也没搞清楚是哪个起作用,所以前面说的建议用管理员权限打开CMD。
最后解决的结果是wordcount花费大量时间在job的启动上, 然后webui能看到任务历史了。

最后,如果只是为了学习感觉应该不需要这么用YARN来跑作业。
4.2 hadoop-streaming的小坑
跑hadoop-streaming时候, -files这种通用参数必须放在其他参数的前面,否则会报"Streaming command failed"的错误

如下:
hadoop jar share/hadoop/tools/lib/hadoop-streaming-3.1.2.jar -files "map1.py,red1.py" -input /usr -output /output -mapper "python map1.py" -reducer "python red1.py"













 199
199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









