







一 简介
散列表(Hash table哈希表),根据关键码值(Key value)而直接进行访问的数据结构。
通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
这个映射函数叫做散列函数,存放记录的数组叫做散列表。
打个非常不严谨的比方:
NBA2K是一个广受篮球爱好者追捧的游戏。里面有每个NBA球员的战斗值,越高越厉害。
现在假设2K战斗值从1到100放在电脑中(不是全部每个战斗值都有,如可能没有10的值)
以战斗值为关键字,我想查找2K值为1的人是谁?按照传统的方法:
如果2K值无序存放在电脑中,要找1只能一个个取出来与1作比较,相等然后才能找到1存放那的人;
如果2k值有序存放在电脑中,可以通过比如折半查找比较等找到存1的位置然后找到人。
有没有不怎么耗时间,无须多次比较查找却一问就知道2K值为1的人是谁的方法呢?
答案是哈希表存储,以战斗值为关键字,给定战斗值就知道了存放的位置!!
但是哈希有时候会有冲突,也就是即便关键字不一样,可能通过哈希函数算出来的地址一样,这时候就尴尬了。
解决冲突的办法有很多,如链地址法(拉链法),建立一个公共溢出区等,本文主要是用到以下:
开放定址法:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。
Hi=(H(key) + di) MOD m,i=1,2,…,k(k<=m-1),其中H(key)为散列函数,m为散列表长,di为增量序列,可有下列三种取法:
1. di=1,2,3,…,m-1,称线性探测再散列;
2. di=1^2,-1^2,2^2,-2^2,⑶^2,…,±(k)^2,(k<=m/2)称二次探测再散列;
3. di=伪随机数序列,称伪随机探测再散列。
再散列法:即在同义词产生地址冲突时计算另一个散列函数地址,直到冲突不再发生。
二 编程实现
准备测试文件:
有10条记录,第2行开始,每行两数,第一个数是2K值,第二个是关联的人。
比如第2行,对应着2K值6的人叫luxing富。
现在要做的事就是,知道了这些信息,然后用合适的位置存放在电脑中。
当下次一问2K值为6的人是谁时,电脑立即知道从哪儿个位置取相应的记录。

1.建立一个HashTable.h
#ifndef HASH.H
#define HASH.H
const int SUCCESS=1;//插入元素成功
const int UNSUCCESS=0;
const int EXIST=-1;//哈希表中有相同关键字元素,不再插入
const int MAX=3;
//hashsize数组存放哈希表需要重建时下一个容量大小
int hashsize[MAX]={11,19,37};
template <typename T>
class HashTable{
private:
T *elem;
int count,length;//数据个数,哈希表容量
int sizeindex;//hashsize[sizeindex]为当前容量
int *random_d;//增量随机数数组指针
int Hash(KeyType key){
return key%length;
}
int Hash2(KeyType key){
return key%(length-1);//双散列函数探测法第二个哈希函数
}
void Random(){//随机探测法中建立伪随机数组
bool *a=new bool[length];
random_d=new int[length];
int i;
for(i=1;i<length;i++)
a[i]=false;
srand(time(0));
for(i=1;i<length;i++){
do{
random_d[i]=rand()%(length-1)+1;//给rando[i]赋值为1到length-1
if(!a[random_d[i]])
a[random_d[i]]=true;
else
random_d[i]=0;
}while(random_d[i]==0);//赋值失败重新赋值
// cout<<"random_d["<<i<<"]="<<random_d[i]<<" ";
}
cout<<endl;
delete []a;
}
int d(int i,KeyType key){//增量序列函数,返回第i次冲突的增量
switch(d_type){
//线性探测法:1,2,3···
case 0:return i;
//二次探测法:1,-1,4,-4,9,-9···
case 1:return ((i+1)/2)*((i+1)/2)*(int)pow(-1,i-1);
//双散列探测法
case 2:return i*Hash2(key);
//随机探测法
case 3:return random_d[i];
//默认线性探测
default: return i;
}
}
void FindAnotherPos(KeyType key,int &p,int i){//开地址法求关键字key的第i次冲突地址p
p=(Hash(key)+d(i,key))%length;
if(p<0)//求余是负,在二次探测可能出现
p=p+length;
}
void RecreateHashTable(){
int i,len=length;//哈希表原容量
T *p=elem;
sizeindex++;//取存储容量为hashsize[]中下一个序列数
if(sizeindex<MAX){
length=hashsize[sizeindex];
elem=new T[length];
assert(elem!=NULL);
for(i=0;i<length;i++)
elem[i].key=EMPTY;//未填有数据
for(i=0;i<len;i++)//将p所指原elem中的数据插入到重建的哈希表中
if(p[i].key!=EMPTY&&p[i].key!=REMOVE)//原哈希表【i】有数据
InsertHash(p[i]);
delete []p;
if(d_type==3)
Random();//重建伪随机增量
}
}
public:
int d_type;//探测法类型
HashTable(){
count=0;
sizeindex=0;
length=hashsize[sizeindex];
elem= new T[length];
assert(elem!=NULL);
for(int i=0;i<length;i++)
elem[i].key=EMPTY;//还没填充元素
cout<<" 依下面提示序号选择冲突时探测法:"<<endl;
cout<<"(0:线性;1:二次;2:再散列;3:随机):"<<endl;
cin>>d_type;
switch(d_type){
case 0:cout<<"产生冲突时你选择使用线性探测法解决!"<<endl;break;
case 1:cout<<"产生冲突时你选择使用二次探测法解决!"<<endl;break;
case 2:cout<<"产生冲突时你选择用再散列探测法解决!"<<endl;
if(d_type==3)
Random();
else random_d=NULL;
break;
case 3:cout<<"产生冲突时你选择使用随机探测法解决!"<<endl;break;
default:cout<<endl;
}
}
~HashTable(){
if(elem!=NULL)
delete []elem;
if(d_type==3)
delete []random_d;
}
bool SearchHash(KeyType key,int &p,int &c){
/* 查找关键字为key的元素,若查找成功
p代表待查数据在表中位置,返回success;
否则,p代表插入位置,返回unsuccess;
c冲突次数,初值0,在建表插入时用
*/
int c1,remove=-1;//存放第一个删除地址
p=Hash(key);//求得哈希地址
//该位置被删除或者该位置有数据但不相同
while(elem[p].key==REMOVE||(elem[p].key!=EMPTY)&&(key!=elem[p].key))
{
//该位置数据被删除且是第一个
if(elem[p].key==REMOVE&&remove==-1){
remove=p;//该位置存放在remove中
c1=c;//冲突次数存放在c1中
}
//冲突数加1
c++;
//在哈希表中可能找到插入位置
if(c<=hashsize[sizeindex]/2)
FindAnotherPos(key,p,c);
else
break;
}
if(key==elem[p].key)
return true;
else{
if(remove!=-1){//在查找过程中碰到曾删除位置
p=remove;//设为插入位置
c=c1;//找到此位置时的冲突次数
}
return false;//p指示的是插入位置
}
}
int InsertHash(T e){
int p,c=0;
//先查找,有不插入且p指向查到的位置;没有则P指向该插入的位置
if(SearchHash(e.key,p,c))
return EXIST;
else{
if(c<hashsize[sizeindex]/2){
elem[p]=e;
++count;
return SUCCESS;
}
else{
cout<<"插着插着可能不够,暂停!!"<<endl;
cout<<"哈希地址顺序遍历此时哈希表,准备重建:"<<endl;
TraverseHash(Visit);
cout<<"重建哈希表如下:"<<endl;
RecreateHashTable();
cout<<endl;
return UNSUCCESS;
}
}
}
bool DeleteHash(KeyType key,T &e){
int p,c;
if(SearchHash(key,p,c)){
e=elem[p];
elem[p].key=REMOVE;//设置删除标志!
--count;
return true;
}
else return false;
}
T GetElem(int i)const{
return elem[i];
}
void TraverseHash(void(*visit)(int ,T *))const{
//按照哈希地址顺序遍历表
int i;
cout<<"哈希地址0~"<<length-1<<endl;
for(i=0;i<length;i++)
if(elem[i].key!=EMPTY&&elem[i].key!=REMOVE)
visit(i,&elem[i]);
cout<<endl;
}
};
#endif
2.建立头文件func.cpp
struct DATA{
KeyType key;//关键字必有
string star;
};
void Visit(int i,DATA *c){
cout<<"["<<i<<"]: "<<'('<<c->key<<", "<<c->star<<")"<<endl;
}
void Visit(DATA c){
cout<<'('<<c.key<<","<<c.star<<")";
}
void InputFromFile(ifstream &f,DATA &c){
f>>c.key>>c.star;
}
void InputKey(int &k){
cin>>k;
}
3.测试程序
#include <iostream>
#include <fstream>
#include <cmath>
#include <string>
#include <ctime>
#include <assert.h>
using namespace std;
const int EMPTY=0;//尚未填充数据标志
const int REMOVE=-1;//数据删除标志
typedef int KeyType;//关键字类型
#include "func.cpp"
#include "HashTable.h"
int main()
{
HashTable<DATA> h;
int i, j, n, p=0;
bool m;
DATA e;
KeyType k;
ifstream fin("test.txt");
fin>>n;
for(i=0; i<n; i++)
{
InputFromFile(fin, e);
j=h.InsertHash(e);
if(j==EXIST)
{
cout<<"有人抢着要(已经有主)的关键字(2K战斗力):"<<e.key<<",妄图再插入成为: ";
Visit(e);
cout<<endl;
}
if(j==UNSUCCESS)
j=h.InsertHash(e);
}
fin.close();
cout<<endl;
cout<<"按哈希地址的顺序遍历哈希表:"<<endl;
h.TraverseHash(Visit);
if(h.d_type==1)
{
cout<<"请输入待删除球星的关键字(2K战斗力):";
InputKey(k);
m=h.DeleteHash(k, e);
if(m)
{
cout<<"成功删除该元素";
Visit(e);
cout<<endl;
}
}
cout<<"请输入待查找球星的关键字(2K战斗力):";
InputKey(k);
n=0;
j=h.SearchHash(k, p, n);
if(j==SUCCESS)
{
Visit(h.GetElem(p));
cout<<endl;
}
else
cout<<"未找到"<<endl;
if(h.d_type==1)
{
cout<<"插入球星,请输入待插入球星的关键字(2K战斗力):";
InputKey(e.key);
cout<<"请输入待插入球星的名字:";
cin>>e.star;
j=h.InsertHash(e);
cout<<j<<endl;
cout<<endl;
cout<<"按哈希地址的顺序遍历哈希表:"<<endl;
h.TraverseHash(Visit);
}
return 0;
}
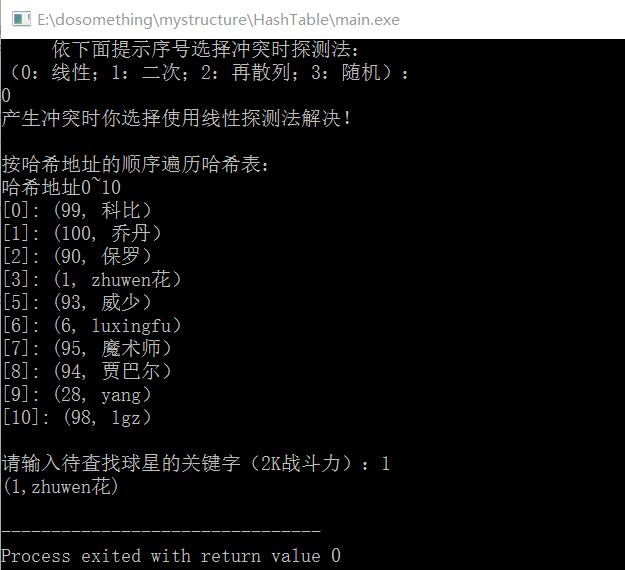
4.部分测试结果















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









