






浏览器环境下js引擎的事件循环机制
当javascript代码执行的时候会将不同的变量存于内存中的不同位置:堆(heap)和栈(stack)中来加以区分。其中,堆里存放着一些对象。而栈中则存放着一些基础类型变量以及对象的指针。 但是我们这里说的执行栈和上面这个栈的意义却有些不同。
我们知道,当我们调用一个方法的时候,js会生成一个与这个方法对应的执行环境(context),又叫执行上下文。这个执行环境中存在着这个方法的私有作用域,上层作用域的指向,方法的参数,这个作用域中定义的变量以及这个作用域的this对象。 而当一系列方法被依次调用的时候,因为js是单线程的,同一时间只能执行一个方法,于是这些方法被排队在一个单独的地方。这个地方被称为执行栈。
同步代码的执行
当一个脚本第一次执行的时候,js引擎会解析这段代码,并将其中的同步代码按照执行顺序加入执行栈中,然后从头开始执行。如果当前执行的是一个方法,那么js会向执行栈中添加这个方法的执行环境,然后进入这个执行环境继续执行其中的代码。当这个执行环境中的代码 执行完毕并返回结果后,js会退出这个执行环境并把这个执行环境销毁,回到上一个方法的执行环境。。这个过程反复进行,直到执行栈中的代码全部执行完毕。
下面这个图片非常直观的展示了这个过程,其中的global就是初次运行脚本时向执行栈中加入的代码:
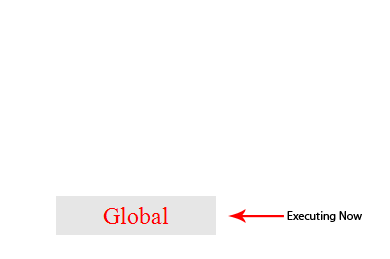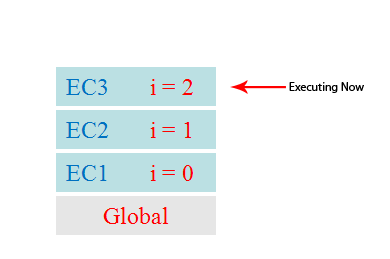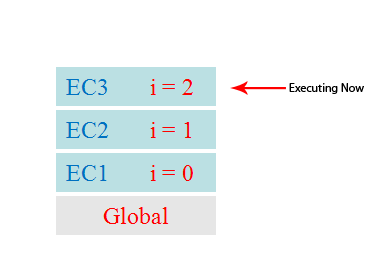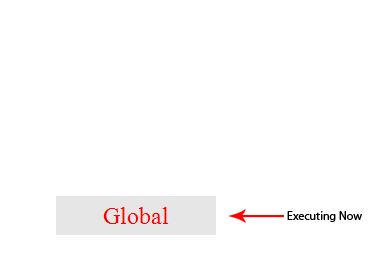
从图片可知,一个方法执行会向执行栈中加入这个方法的执行环境,在这个执行环境中还可以调用其他方法,甚至是自己,其结果不过是在执行栈中再添加一个执行环境。这个过程可以是无限进行下去的,除非发生了栈溢出,即超过了所能使用内存的最大值。
异步代码的执行
以上的过程说的都是同步代码的执行。那么当一个异步代码(如发送ajax请求数据)执行后会如何呢?前文提过,js的另一大特点是非阻塞,实现这一点的关键在于下面要说的这项机制——事件队列(Task Queue)。
js引擎遇到一个异步事件后并不会一直等待其返回结果,而是会将这个事件挂起,继续执行执行栈中的其他任务。当一个异步事件返回结果后,js会将这个事件加入与当前执行栈不同的另一个队列,我们称之为事件队列。被放入事件队列不会立刻执行其回调,而是等待当前执行栈中的所有任务都执行完毕, 主线程处于闲置状态时,主线程会去查找事件队列是否有任务。如果有,那么主线程会从中取出排在第一位的事件,并把这个事件对应的回调放入执行栈中,然后执行其中的同步代码…,如此反复,这样就形成了一个无限的循环。这就是这个过程被称为“事件循环(Event Loop)”的原因。
这里还有一张图来展示这个过程:
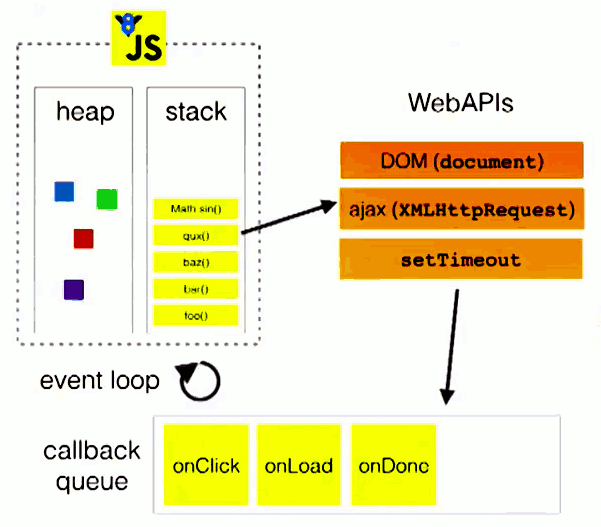
图中的stack表示我们所说的执行栈,web apis则是代表一些异步事件,而callback queue即事件队列。
2.macro task与micro task
以上的事件循环过程是一个宏观的表述,实际上因为异步任务之间并不相同,因此他们的执行优先级也有区别。不同的异步任务被分为两类:微任务(micro task)和宏任务(macro task)。
以下事件属于宏任务:
setInterval()setTimeout()
以下事件属于微任务
new Promise()new MutaionObserver()
前面我们介绍过,在一个事件循环中,异步事件返回结果后会被放到一个任务队列中。然而,根据这个异步事件的类型,这个事件实际上会被对应的宏任务队列或者微任务队列中去。并且在当前执行栈为空的时候,主线程会 查看微任务队列是否有事件存在。如果不存在,那么再去宏任务队列中取出一个事件并把对应的回到加入当前执行栈;如果存在,则会依次执行队列中事件对应的回调,直到微任务队列为空,然后去宏任务队列中取出最前面的一个事件,把对应的回调加入当前执行栈…如此反复,进入循环。
我们只需记住当当前执行栈执行完毕时会立刻先处理所有微任务队列中的事件,然后再去宏任务队列中取出一个事件。同一次事件循环中,微任务永远在宏任务之前执行。
这样就能解释下面这段代码的结果:
setTimeout(function () {
console.log(1);
});
new Promise(function(resolve,reject){
console.log(2)
resolve(3)
}).then(function(val){
console.log(val);
})
结果为:
2
3
1
unction(val){
console.log(val);
})
结果为:
```text
2
3
1















 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









