







其它容器
1、ConcurrentSkipListMap
TreeMap,TreeSet 有序容器,的并发版ConcurrentSkipListMap
SkipList,以空间换时间,在原链表的基础上形成多层索引,但是某个节点在插入时,是否成为索引,随机决定,所以跳表又称为概率数据结构。
如果redis sortedmap和luence就是通过跳表实现的
1、跳跃表结构如下:
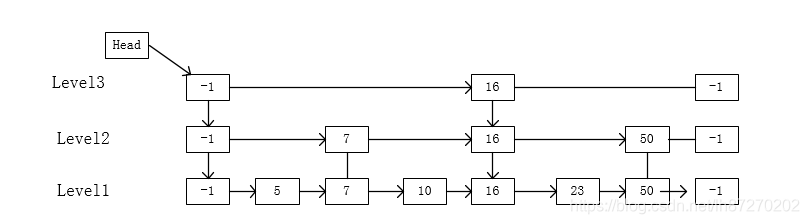
1)跳表每层都是一个有序列表
2)跳表最低层包含所有元素
3) 每个节点有2个指针,一个指向侧节点(没有为空),一个指向下层节点(没有为空)
4)必须有一个头节点指向最高层的第一个节点,通过它可以遍历整张表
2、在跳表中查找一个节点
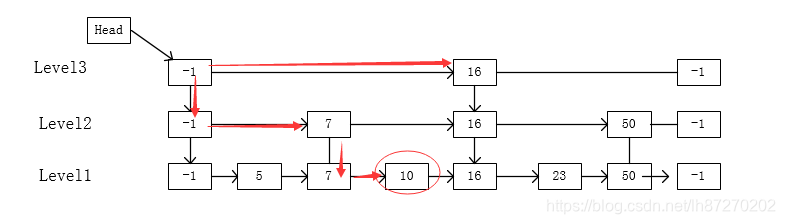
1)先找右侧节点如果大于这个节点值,那么继续找右侧节点,如果小于这个节点那么找下层节点,如果相等就返回
2)重复1)的操作,直到遍历完整个表
3、在跳表中插入一个节点
1)在最底层链表合适位置插入节点
2)往上的层次是否需要增加节点则完全是随机的,SkipList 通过概率保证整张表的节点分布均匀,它不像红黑树是通过人为的 rebalance 操作来保证二叉树的平衡性。(数学对于计算机还是很重要的)。
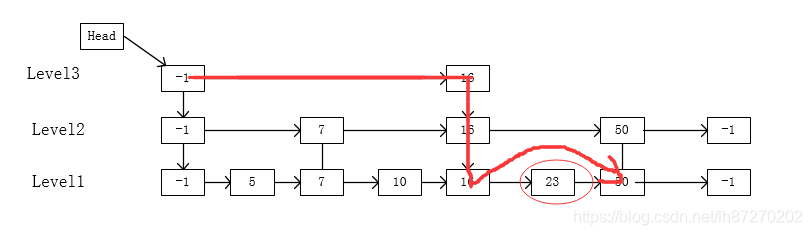
3)通过概率算法得到插入节点的一个level值,如果小于当前level,建立从低层到level层的节点,例如:

如图,首先 90节点会被添加到最底层链表的合适位置,然后通过概率算法得到 level 为 2,于是 1—level 层中的每一层都添加了 90节点。
如果概率算法得到的 level 大于当前表的最大 level 值的话,那么将会新增一个 level,并且将新节点添加到该 level 上。

3、在跳表中删除一个节点
跳表的删除操作就是一个查找加删除节点的操作
2、写时复制容器
1、写时复制容器
添加元素时不直接向里面添中元素,而是根根原容易复制出一个新容器,然后向新容器中添加原元素,添加完元素后,再将原容器的引用指向新容器。这样做是好处是或以并发读,而不需要加锁,因为当前容器不会添加任何元素。写时复制容器是一种读写分离的的思想,读和写是不同的容器。读的时候,有多线程写数据,读取的还是旧的数据,只能保证最终一致性。
3、阻塞队列
生产者消费者模式
1>当队列满时,插入元素被阻塞,直到队列不满
2》当队列空时,获取元素被阻塞,直到队列不空
阻塞队列可以当成一个缓冲器,缓冲了生产者消费者能力不匹配的问题
常用方法
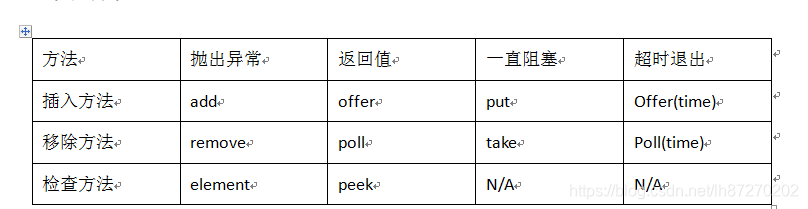
常用阻塞队列:
ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
按照先进先出原则,要求设定初始大小
LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
按照先进先出原则,可以不设定初始大小,Integer.Max_Value
ArrayBlockingQueue和LinkedBlockingQueue不同:
锁上面:ArrayBlockingQueue只有一个锁,LinkedBlockingQueue用了两个锁,
实现上:ArrayBlockingQueue直接插入元素,LinkedBlockingQueue需要转换。
PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
默认情况下,按照自然顺序,要么实现compareTo()方法,指定构造参数Comparator
DelayQueue:一个使用优先级队列实现的无界阻塞队列。
支持延时获取的元素的阻塞队列,元素必须要实现Delayed接口。
场景:实现缓存系统,订单到期,限时支付等等。
SynchronousQueue:一个不存储元素的阻塞队列。每一个put操作都要等待一个take操作
阻塞队列的实现原理
比如,ArrayBlockingQueue就是基于Lock和Condition实现的。














 924
924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









