







文章目录
13、单桶聚集
13.1、过滤聚集
过滤器聚集通过定义一个或多个过滤器来过滤分桶,满足过速器条件的文档将 落入这个过滤器形成的桶中。过滤器聚集分为单桶和多桶两种,对应的聚集类型 自然就是 filter 和 filters。
POST /kibana_sample_data_flights/_search?size=0&filter_path=aggregations
{
"aggs" : {
"origin_cn": {
# 过滤出发为CN的 航班 才落到桶中
"filter": {
"term": {
"OriginCountry":"CN"
}
},
# 然后再 统计它们的平均票价
"aggs": {
"cn_ticket_price": {
"avg": {
"field": "AvgTicketPrice"
}
}
}
},
# 统计了所有航班 平均票
"avg_price": {
"avg": {
"field": "AvgTicketPrice"
}
}
}
}
结果为:
{
"aggregations" : {
# 平均票价
"avg_price" : {
"value" : 628.2536888148849
},
"origin_cn" : {
#出现地为中国的 平均票价
"doc_count" : 743,
"cn_ticket_price" : {
"value" : 601.1180918245585
}
}
}
}
多桶过滤:
POST /kibana_sample_data_flights/_search?size=0&filter_path=aggregations
{
"aggs" :{
"origin_cn_us":{
"filters": {
"filters":[
{ "term": {"OriginCountry": "CN"} },
{"term": {"OriginCountry": "US " } }
]
},
"aggs":{
"avg_ price":{
"avg": {
"field": "AvgTicketPrice"
}
}
}
}
}
}
13.2、global聚集
忽略query的条件,统计所有
13.3、missing聚集
把缺失的字段 规到某个桶
14、聚集组合
有两种比较特殊的多桶型聚集,它们是 composite 聚集和 adjacency_matrix 聚集。
14.1、 composite 聚集
集可以将不同类型的聚集组合到一一起,它会从不同的聚集中 提取数据,并以笛卡尔乘积的形式组合它们,而每一个组合就会形成一个新桶。
查看平均票价与机场天气的对应关系:
POST /kibana_sample_data_flights/_search?filter_path=aggregations
{
"aggs" :{
"price_weather" : {
"composite" : {
#用sources,定义2个需要组合的聚集
"sources":[
{
"avg_price": {
##第一个聚集:针对 AvgTicketPrice 以 500 为间隔 分桶聚集
"histogram":{
"field": "AvgTicketPrice",
"interval":500,
#按avg_price排序
"order": "asc"
}
}
},
{
##第二聚集:个针对 OriginWeather 的 terms 聚集,按weather 排序
"weather":{
"terms": {"field": "OriginWeather","order":"asc"}
}
}
]
}
}
}
}
运行结果:
{
"aggregations" : {
"price_weather" : {
#它包含自前聚集结果中最后一个结果的 key。所以请求下一页聚集结果就可 以通过 after 和 size 参数值定
"after_key" : {
"avg_price" : 500.0,
"weather" : "Cloudy"
},
"buckets" : [
{
"key" : {
"avg_price" : 0.0,
"weather" : "Clear"
},
"doc_count" : 795
},
{
"key" : {
"avg_price" : 0.0,
"weather" : "Cloudy"
},
"doc_count" : 809
},
{
"key" : {
"avg_price" : 0.0,
"weather" : "Damaging Wind"
},
"doc_count" : 303
},
{
"key" : {
"avg_price" : 0.0,
"weather" : "Hail"
},
"doc_count" : 373
},
{
"key" : {
"avg_price" : 0.0,
"weather" : "Heavy Fog"
},
"doc_count" : 292
},
{
"key" : {
"avg_price" : 0.0,
"weather" : "Rain"
},
"doc_count" : 738
},
{
"key" : {
"avg_price" : 0.0,
"weather" : "Sunny"
},
"doc_count" : 744
},
{
"key" : {
"avg_price" : 0.0,
"weather" : "Thunder & Lightning"
},
"doc_count" : 357
},
{
"key" : {
"avg_price" : 500.0,
"weather" : "Clear"
},
"doc_count" : 1377
},
{
"key" : {
"avg_price" : 500.0,
"weather" : "Cloudy"
},
"doc_count" : 1365
}
]
}
}
}
15、管道聚集
管道聚集不是直接从索引中读取文档,而是在其他聚集的基础上再进行聚集 运算。
管道聚集都会 包含一个名为 buckets_path 的参数,用于指定访问其他桶中指标值的路径。
buckets_ path 参数的值由三部分组成,即聚集名称、指标名称和分隔符。
15.1、基于兄弟聚集
POST /kibana_sample_data_flights/_search?filter_path=aggregations
{
"aggs": {
"carriers": {
#terms分桶, 按字段Carrier 分10个桶
"terms":{
"field": "Carrier",
"size": 10
},
"aggs": {
"carrier_stat": {
# 将上面10个桶,按stats聚集
"stats": {
"field": "AvgTicketPrice"
}
}
}
},
"all_stat": {
# 对兄弟聚集carriers,基础上再聚集,对carrier_stat.avg 作avg_bucket平均值聚集
"avg_bucket": {
"buckets_path": "carriers>carrier_stat.avg"
}
}
}
}
结果:
{
"aggregations" : {
"carriers" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Logstash Airways",
"doc_count" : 3331,
"carrier_stat" : {
"count" : 3331,
"min" : 100.37113189697266,
"max" : 1199.72900390625,
"avg" : 624.5819742276625,
"sum" : 2080482.5561523438
}
},
{
"key" : "JetBeats",
"doc_count" : 3274,
"carrier_stat" : {
"count" : 3274,
"min" : 101.0330810546875,
"max" : 1199.642822265625,
"avg" : 627.4573726292857,
"sum" : 2054295.4379882812
}
},
{
"key" : "Kibana Airlines",
"doc_count" : 3234,
"carrier_stat" : {
"count" : 3234,
"min" : 100.14596557617188,
"max" : 1199.109130859375,
"avg" : 630.8681507004435,
"sum" : 2040227.5993652344
}
},
{
"key" : "ES-Air",
"doc_count" : 3220,
"carrier_stat" : {
"count" : 3220,
"min" : 100.0205307006836,
"max" : 1199.5123291015625,
"avg" : 630.235816375069,
"sum" : 2029359.3287277222
}
}
]
},
"all_stat" : {
"value" : 628.2858284831152
}
}
}
15.2、基于父聚集
滑动窗口聚集
把父聚集的结果作为输入,然后再聚集
滑动窗口有2个: moving_avg:平均值, moving_fn:自定义计算
只能用于间隔聚集
POST /kibana_sample_data_flights/_search?filter_path=aggregations
{
"aggs": {
"day_price": {
#timestamp 字段按天将文档分桶。
"date_histogram": {
"field": "timestamp",
"interval": "day"
},
"aggs": {
"avg_price": {
#AvgTicketPrice 字段在 1 个桶内avg 聚集
"avg": {
"field": "AvgTicketPrice"
}
},
#使用滑动窗口做平均值平滑的管道聚集,按滑动窗口聚集
"smooth_price": {
#以对落在窗口内的父聚集结果做各种自定义的运算
"moving_fn": {
"buckets_path": "avg_price",
"window": 10,
# 无加权平均计算
"script":"MovingFunctions.unweightedAvg(values)"
}
}
}
}
}
}
单桶聚集
目前我们学习的管道聚集会对父聚集结果中落在窗口内的多个桶做聚集运 算,而 bucket_script、 bucket_selector 、bucket_sort 这三个管道聚集则会针对
父聚集结果中的每一个桶做单独的运算。
- bucket_script
会对每个桶执行一 段脚本, 运算结果会添加到父聚集的结果中 - bucket_selector
执行一 段脚本, 但它执行的结果一定是布尔类型, 并且决定当前桶是否出现在父聚集 的结果中; - bucket_sort
每个桶中的具体指标值决定桶的次序
POST /kibana_sample_data_flights/_search?filter_path=aggregations
{
"aggs": {
"date_price_diff": {
#时间间隔分桶,按天分桶
"date_histogram": {
"field": "timestamp", "fixed_interval": "1d"
},
"aggs": {
"stat_price_day": {
#按字段 AvgTicketPrice 指数聚集
"stats": {
"field": "AvgTicketPrice"}
},
#兄弟聚集
"diff":{
#管道聚集
"bucket_script": {
#将上一个聚集 结果 ,取出最大值和最小值
"buckets_path": {
"max_price":"stat_price_day.max",
"min_price":"stat_price_day.min"
},
#对最大值和最小值求相减
"script": "params.max_price - params.min_price"
}
},
"gt990": {
#selector聚集,同样取最大值和最小值,然后相减去,如果差值大于990的才能出现,否则不能出现
"bucket_selector": {
"buckets_path": {
"max_price":"stat_price_day.max",
"min_price":"stat_price_day.min"
},
"script": "params.max_price - params.min_price > 990"
}
},
"sort_by": {
#排序
"bucket_sort": {
"sort":[
{
#对diff结果排序--倒序
"diff":{
"order":"desc"
}
}
]
}
}
}
}
}
}
过滤出最大值和最小值差值大于 990的聚集,然后按差值 倒序排序。
16、父子关系
文档和文档间的关系。通过某个 标识 还标识 文档间的 父子关系。类似 mysql表中如下结构:
用parent_id字段来标识 父部门Id,通过父部门Id可以找到子部门id,可以通过子部门Id , 找到它的父部门。
部门表:
dept_id dept_name parent_id
1 研发一部 0
2 研发二部 1
3 研发三部 2
数据与数据间有父子关系,es间也有这种关系,就是父子关系。需要在索引中定义一个字段 ,来标识这 种关系
16.1、join类型
定义文档父子关系
PUT employees
{
"mappings": {
"properties": {
"management":{
"type": "join",
"relations":{
"manager": "member"
}
}
}
}
}
PUT /employees/_doc/1
{
"name" : "tom",
"management":{ "name" : "manager" }
}
PUT /employees/_doc/2?routing=1
{
"name" : "smith",
"management":{ "name" : "member", "parent": "1" }
}
PUT /employees/_doc/3?routing=1
{
"name" : "john",
"management":{ "name" : "member", "parent": "1" }
}
#如果再添加 文档1 的父文档好像添加不了
PUT /employees/_doc/4?routing=1
{
"name" : "tom_parent",
"management":{ "name":"manager","children":"1"}
}
16.2、has_child查询
#查询,who has child, 根据子文档名字 smith,查看谁有这个child,即:根据子文档查询父文档
POST /employees/_search
{
"query": {
"has_child":{
"type": "member",
"query":{
"match":{ "name": "smith" }
}
}
}
}
16.3、has_parent查询
#查询,who has parent, 根据父文档名字查看 子文档
POST /employees/_search
{
"query": {
"has_parent":{
"parent_type": "manager",
"query":{
"match":{ "name": "tom" }
}
}
}
}
16.4、parent_id查询
# 查看parent_id=1的子文档有哪些
POST /employees/_search
{
"query": {
"parent_id": { "type": "member", "id":1 }
}
}
16.5、children聚集
POST /employees/_search?filter_path=aggregations
{
"query":{
"term":{ "name":"tom" }
},
"aggs":{
"members":{
#children聚集:查看集合中 parent=tom的子文档个数
"children":{
"type": "member"
},
# 再次聚集,分别统计tom子文档
"aggs": {
"member_name":{
"terms":{ "field": "name.keyword", "size": 10 }
}
}
}
}
}
查询结果:
{
"aggregations" : {
#members 聚集结果:doc_cout=2,统计了name=tom的子文档个数
"members" : {
"doc_count" : 2,
#member_name聚集结果: 分别统计了name=tom的子文档个数
"member_name" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
#子文档john 的个数
"key" : "john",
"doc_count" : 1
},
{
#子文档smith 的个数
"key" : "smith",
"doc_count" : 1
}
]
}
}
}
}
16.6、parent聚集
POST /employees/_search?filter_path=aggregations
{
# 查询name = smith的文档
"query": {
"match":{ "name": "smith" }
},
"aggs": {
#parent聚集:根据子文档名字smith 找到父文档,统计它的个数
"who_is_manager":{
"parent":{
"type": "member"
},
#再次聚集,根据smith 找到父文档,根据父文档名字 分别统计 父文档个数
"aggs":{
"manager_name":{
"terms":{ "field" :"name.keyword" , "size": 10 }
}
}
}
}
}
查询结果:
{
"aggregations" : {
"who_is_manager" : {
"doc_count" : 1,
"manager_name" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "tom",
"doc_count" : 1
}
]
}
}
}
}
17、嵌套类型
添加一个数组文档如下;
PUT colleges/_doc/2
{
"address":[
{ "country": "CN", "city":"BJ" },
{ "country" : "US", "city": "NY" }
],
"age":10
}
colleges 文档在实际存储时,会被拆解为“ address. country": [“CN.US”]” 和 address. city":[“BJ” ,“NY”]” 两个数组字段。这样一来,单个对象 内部,country 字段和 city 字段之间的匹配关系就丢失了。换句话说,使用 CN 与 NY 作为共同条件检索的文档时,上述文档也会被检索出来,这在逻辑上就出现 了错误:
POST colleges/_search
{
"query": {
"bool": {
"must":[
{"match": { "address.country": "CN"}},
{"match": {"address.city": "NY"}}
]
}
}
}
在示例中使用了 bool 组合查询,要求 country 字段为 CN 而 city 字段为 NY。 这样的文档显然并不存在,但由于数组中的对象被平铺为两个独立的数组字段, 文档仍然会被检索出来。
所以定义文档时,address字段需要定义为嵌套类型。
17.1、嵌套类型
PUT colleges
{
"mappings": {
"properties": {
"address":{ "type": "nested" },
"age":{ "type":"integer" }
}
}
}
如果还是用上面那个查询语句查询,实际上还是有问题,条件正确不会被查询出来:
POST colleges/_search
{
"query": {
"bool": {
"must":[
{"match": { "address.country": "CN"}},
{"match": {"address.city": "BJ"}}
]
}
}
}
上面改成正确的条件也查不出来数据,
这是因为对 nested 类型字段的检索实际 上是对隐式文档的检索,在检索时必须要将检索路由到隐式文档上,所以必须使 用专门的检索方法。
17.2、nested查询
POST /colleges/_search
{
"query":{
"nested":{
"path": "address",
"query": {
"bool":{
"must":[
{"match": {"address.country": "CN"}},
{"match": {"address.city": "BJ"}}
]
}
}
}
}
}
17.3、nested 聚集
nested 聚集是一个单桶聚集,也是通过 path 参数指定 nested 字段的路径, 包含在 path 指定路径中的隐式文档都将落入桶中。所以 nested 字段保存数组的 长度就是单个文档落入桶中的文档数量,而整个文档落入桶中的数量就是所有文 档 nested 字段数组长度的总和。有了 nested 聚集,就可以针对 nested 数组中的 对象做各种聚集运算,例如:
POST /colleges/_search?filter_path=aggregations
{
"aggs": {
"nested_address":{
"nested":{ "path": "address" },
"aggs":{
"city_names": {
"terms":{ "field": "address.city.keyword", "size": 10 }
}
}
}
}
}
在示例中,nested_address 是一个 nested 聚集的名称,它会将 address 字段 的隐式文档归入一个桶中。而嵌套在 nested_address 聚集中的 city_names 聚集 则会在这个桶中再做 terms 聚集运算,这样就将对象中 city 字段所有的词项枚举 出来了。
17.4、reverse_nested 聚集
reverse_nested 聚集用于在隐式文档中对父文档做聚集,所以这种聚集必须 作为 nested 聚集的嵌套聚集使用。
POST /colleges/_search?filter_path=aggregations
{
"aggs": {
"nested address": {
"nested":{ "path": "address" },
"aggs":{
"city names":{
"terms":{ "field": "address.city.keyword", "size": 10 },
"aggs": {
"avg_age_in_city":{
"reverse_nested": {},
"aggs": {
"avg_age": {
"avg": {"field": "age"}
}
}
}
}
}
}
}
}
}
18、sql语言
Elasticsearch 在 Basic 授权中支持以 SQL 语句的形式检索文档,SQL 语句在 执行时会被翻译为 DSL 执行。从语法的角度来看,Elastisearch 中的 SQL 语句与 RDBMS 中的 SQL 语句基本一致
19、与spring集成
目前常见的 Elasticsearch Java API 有四类 client 连接方式:
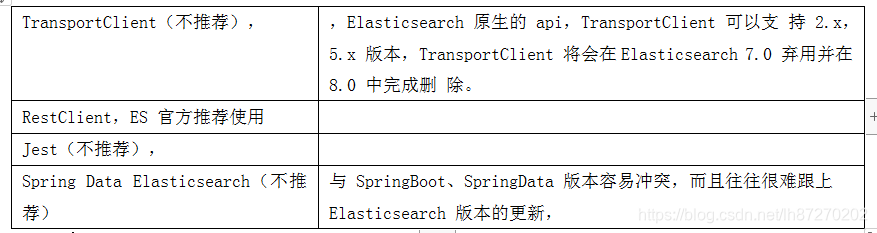
一般4种, 用简单的查询可以用spring data elasticsearch,但如果复杂就不用了,那么最终推荐使用 RestClient, 那么ResttClient又2种。
Java REST Client 有 Low Level 和 High Level 两种:
- Java Low Level REST Client:
使用该客户端需要将 HTTP 请求的 body 手动拼 成 JSON 格式,HTTP 响应也必须将返回的 JSON 数据手动封装成对象,使用上 更为原始。 - Java High Level REST Client:
该客户端基于 Low Level 客户端实现,提供 API 解决 Low Level 客户端需要手动转换数据格式的问题。
官方使用手册:
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/index.ht ml
因为 Low Level更基于原始,所以一般我们用 High Level 。
19.1、使用
maven依赖的版本最好和es的版本一致。
java low level 的maven依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.7.0</version>
</dependency>
java high level的maven的依赖
<dependency>
<groupId>com.strapdata.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.7.0</version>
</dependency>
20、索引模式-index Patterns
索引模式是一种对 Elasticsearch 中索引的模式匹配,以定义哪些索引将被包 含到这个模式中。它以索引名称为基础,可以匹配单个索引也可以使用星号“*” 匹配多个索引。例如在导入飞行记录样例数据时,Kibana 会创建一个名为 kibana_sample_data_flights 的索引模式。索引模式的管理功能位于 Management 菜单中。
21、文档可视化
kibana可视化功能以图表形式展示Elasticsearch中的文档数据,能让用以最直观的形式了解数据变化。
21.1、二维坐标图
二维坐林海雪原图基于维直角坐标系的X/Y轴绘制数据,
包括折线图、面积图和柱状图。
X轴是自变量,Y轴是因变量,二维坐标图体现的就是:Y随X变化的图形。
二维坐标图的 Y 轴一般是一个或多个指标聚集,比如平均值、 总数、极值等。而 X 轴则是桶型聚集,比如词项聚集、范围聚集等。所以指标 聚集、桶型聚集的知识是学习可视化功能的基础。
21.1.1、面积图
飞行距离与机票价格 关系的面积图:
Y轴:机票平均价格,即取 AvgTicketPrice 字段的平均值
X 轴:设置为飞行距离,按 DistanceKilometers 字段的值分桶。



设置Y轴:

设置X轴:

完成显示:

21.1.2、折线图和柱状图
折线图、柱状图与面积图对数据的需求完全一样,所以它们之间可以很 容易做切换。在配置栏上点击 Metrics&Axis 链接,可以对指标和坐标做配置。 如图所示。
chart type: 表格类型,可以切换成折线图 或 柱状图


21.1.3、指标叠加
多个指标其实可以画在一张二维坐标图中,比如:
在飞行距离与机票价格 的基础上,再添加一个指标:不同飞行距离的航班数量


21.2、圆形与弧形图
圆形与弧形图:体现部分与整体之间的关系
圆形与弧形图包括:是饼图(Pie)、目 标(Goal) 和仪表(Gauge) 3种。
21.2.1、饼图
饼图:使用圆或圆环表示整个数据空间,并以扇面代表数据空间的某一部分, 所以饼图在展示部分与整体的关系时非常直观。
目标和仪表:是两个不同的可视化 对象,它们会将某一 指标值的范围绘制在一个 表盘中,并以指针或进度条的形式显示该指标在仪表中的实际值。一般用于监控某系统的运行状态, 体现该系统在某一项指标上的健康状态
饼图有两项变量需要定义 :
1、饼图要区分多少个扇面
2、每个扇 面有多大
两个变量在 Kibana 中由桶型聚集和指标聚集来决定。
饼图也同样包含 Metrics 和 Buckets 两个配置项,
Metries 只能定 义一个指标聚集, 决定扇面大小;
Buckets 定义多个,决定扇面有多 少个。
创建一个pie类型的visual:根据Carrier字段分桶,然后count聚集。查看每个Carrier 个数的占比。
Metries:选择count聚集

Buckets选择Split slices

选择 Buckets 下面的 Split Slices,并选择聚集为 Carrier 字段的 Terms 桶型聚集


默认是环形的饼图,可以在Options 界面中修改 Donut 开关更改。勾选 Donut 选项时绘制的图形为圆环

21.2.2、饼图叠加
在添加桶型聚集时有两个选项,一 个是 Split Slices, 而另-一个则是 Split Chart。与折线图类似,Split Chart 会以分割 X 轴或 Y 轴的形式添加子桶型,但 只能添加一次且必须要先于 Split Slices 添加。
所以需要再创建一个饼图:
Buckets先添加Split chart::
添加split chart的carrier的terms聚集:

再添加Split slices:


完成:
饼图先按不同的航空公司(Carrier) 分割坐标,所以每一个饼图就 代表一个航空公司。在每一个饼图中, 每个扇面代表的是航班的目的地国家占 比。

饼图的 Split Chart 也有 Rows 和 Columns 两个按钮,选择 Rows 时按行分 割 Y 轴,而选择 Columns 则按列分割 X 轴。
上面默认选的:ROWS,改成Columns如下:

21.2.3、目标图
目标图体现:指标值 距离 设定目标值 之间的差距。
实际值越高越 接近目标值说明系统运行越好。
比如:
设置 Kibana Airlines 航空公司每月航班数量的目标为 3000 次,来 生成一个目标可视化对象。由于这次要生成的可视化对象要过滤航空公司。
先添加一个过滤器:Carrier is Kibana Airlines


21.2.4、仪表图
生成一个航班延误时间的仪表:
添加Gauge类型vis:将指标 聚集设置为 FlightDelayMin 的 Average 聚集。

Kibana 默认将整个取值范围设置为 100,并且设置了0~50、50~75 和 75-~ 100 三个区间,它们对应的颜色分别为绿色、黄色和红色。可以到 Options 配 置页面,将延误取值范围修改为 1 个小时,并设置0~20、20~40 和 40 ~60 三 个区间:

21.3、热力图
热力图:代表某种资源的使用频度,资源使用得越多,它的热度也就越高。
比如:在地图的不同区域以不同颜色标识交通流量、 人口分布等情况,交通流量越大、人口密度越高它们所在区域的热度也就越高, 区域对应的颜色也就越深
。。。。。略
21.4、表格
表格由行和列组成,用来 展现关系型数据的形式。
行:由桶型聚集决 定。
列:则由指标聚集决定。
创建一一个表格:以航空公司为行 ,分别统计它们的航班数量、平均 票价、平均飞行距离等。
先添加三个指标聚集,分别为 Count 聚集、AvgTicketPrice 字段的 Average 聚集和 DistanceKilometers 字段的 Average 聚集,

再添加split rows:

添加一个terms聚集,根据航空公司名字 分桶:

完成,如下:

在添加 Buckets 时,有“Split Rows”和“Split Table”两个选择。“Split Rows” 在添加子桶型时会将父桶型按行分割,后者则会直接将表格分割成多个。为上述 表格再添加一个 DestCountry 的 Terms 聚集,在使用“Split Rows"形成的表格 如图所示:

21.5、Dashboard-仪表盘
仪表盘(Dashboard)是 Kibana 提供的综合展示数据的功能,在 Kibara 中保 存的可视化对象可以在仪表盘中组合起来共同展示。














 1149
1149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









