







3. Epoll发展
3.1 BIO+多线程
1、kernel:内核;
2、fd:file descriptors 文件描述符(Linux系统中一切皆文件,任何进程都有文件描述符fd,其中0代表标准输入,1代表标准输出,2代表错误输出);
3、BIO模型下,每次对fd的操作都需要重新启动一个线程。
- 程序调用kernel的read命令读取fd,在单线程的情况下会阻塞,所以就需要使用多线程来读取,这就是BIO;
- Socket是Blocking的;
- 线程,以及线程切换会消耗内存;
- 在JVM中,一个线程的成本默认1MB,线程多了调度成本CPU浪费,内存成本高。
3.2 同步非阻塞 NIO
随着内核kernel向前发展,文件描述符fd可以是非阻塞的。
- Socket设置为nonblock;
- 单线程–死循环,读取Socket文件描述符–在程序;
- 在程序中有个死循环,用于建立进程连接,并读取。所有连接都会读取(轮询发生在用户空间);
- 每次循环,调用read过多,会浪费CPU;
- 复杂度是O(n)。
3.3 多路复用 NIO(poll)
内核kernel向前发展,提供了select方法。
- 用户态与内核态的fd需要相互拷贝;
- 程序调用内核的select方法,遍历fds,程序对返回的fd进行读取和写入;
- 减少程序到内核调用,由内核进行遍历(粒度不够细)。
3.4 epoll NIO(同步非阻塞-多路复用)
内核kernel继续向前发展,出现了EPOLL技术。
- 解决内核正向遍历的复杂度;
- epoll_create:注册到共享空间;
- epoll_wait:程序调用;
- 共享空间mmap:
- 用户态和内核态拥有一个共享空间–内核mmap;
- 共享空间是进程空间的一部分,也是内核空间的一部分,有一个红黑树以及链表。
4. Sendfile 零拷贝
4.1 简单介绍
- 原来文件数据要先到内核中,进程read并且再write到内核中,有拷贝过程;
- 有了sendfile之后,就是指内核直接调用sendfile读取数据到缓冲区,然后发送出去,不再需要上述拷贝过程,叫0拷贝。
4.2 技术使用
- Kafka = mmap + 0拷贝。
5. Redis的使用
5.1 切换库
- 使用select命令可以切换库。
5.2 二进制安全
-
字节流/字符流:Redis只取字节流,其底层存储的是字节,是二进制安全的;
-
编码不影响数据存储;
-
数值会在Redis内部进行转换和计算;
-
Redis的Key中包含两个信息:
- type:value类型;
- OBJECT encoding:字符编码集,包含embstr、raw、int三种。
-
编码格式化命令:redis-cli --raw;
1、例如“中”,使用raw格式化后,对应客户端设置的字符编码集是UTF-8的话,就会正常显示汉字;
2、否则不用raw格式化,就会被识别为ASCII码,以16进制表示:“/xe4/xb8/xad”;
3、但上述两者长度是一样的。
-
多人一起使用Redis时,一定要沟通好用户端使用的编码和解码的字符编码集,因为Redis中是没有数据类型的概念的。
5.3 value正负索引
- 值value是存在正负索引的,如正向为0、1、2,则反向为-1、-2、0。
5.4 ASCII
常识:ASCII码,必须第一位是0,即0xxxxxxx,后面可能全1或0。自己编写一个程序,按字节读取,只要第一位是0,就可以按ASCII码显示。如果是1,如1110,UTF8,3个字节,就去对应它的编码。
Linux中,可以用帮助命令去查看:
man ascii
- 字符集;
- 其他一般叫扩展字符集,且不再对ASCII重编码。
5.5 NX/XX语义
- NX:只有key不存在时才去设置其value;
- 只能新建;
- 使用场景:分布式锁,多个线程一起设置,成功的可以拿到锁。
- XX:只有key存在时才能操作。
- 只能更新。
5.6 value(5种值类型)
5.6.1 string(byte)
Redis的值类型中的string包含3种情形:
1、字符串:常规下对字符串进行各种操作;

2、数值:可以面向string进行数值操作;

3、bitmap(位图):也可以进行二进制位操作。
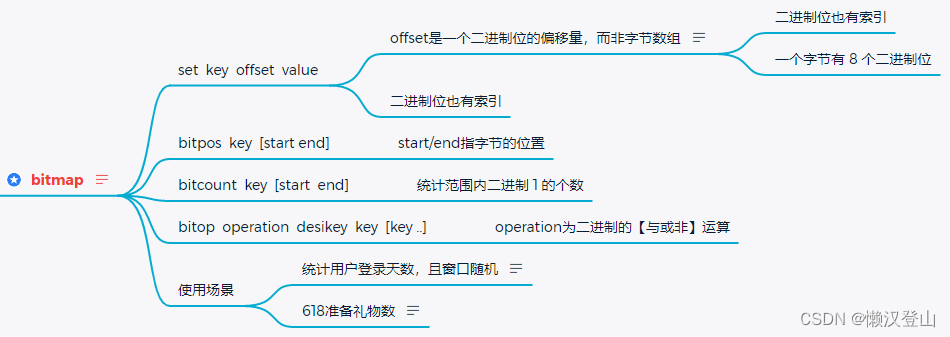
5.6.2 list
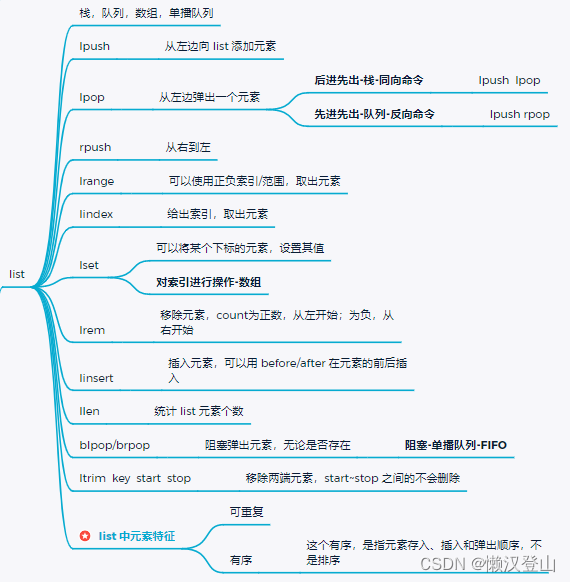
5.6.3 hash

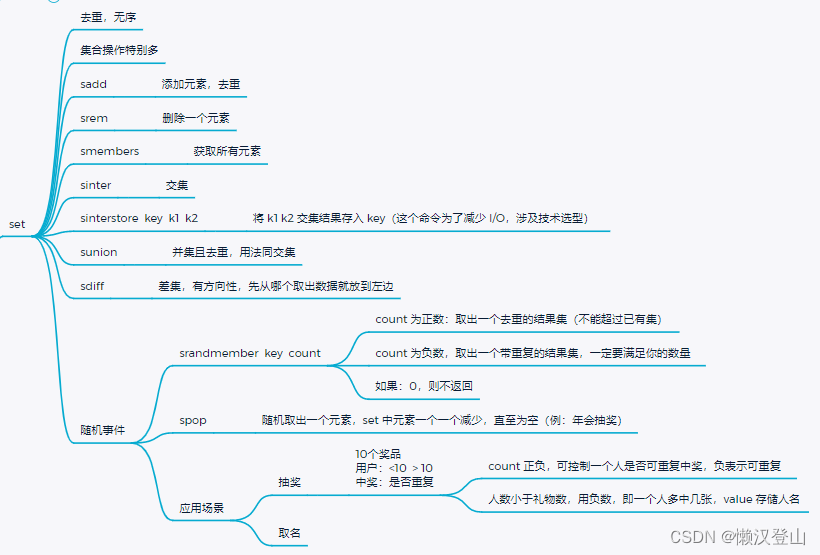
5.6.4 set
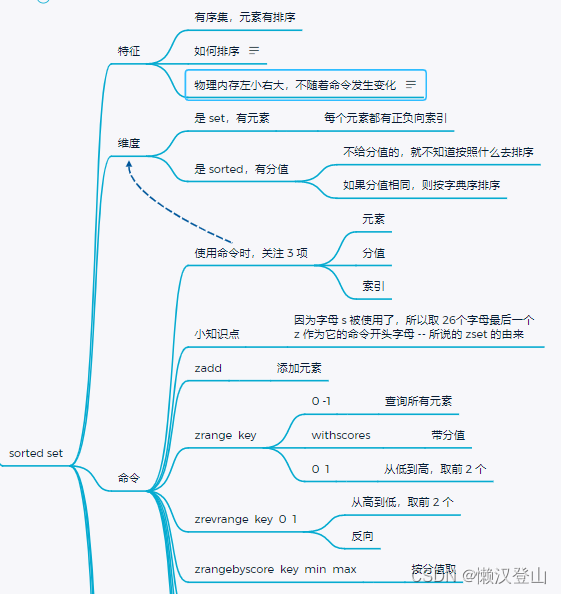
5.6.5 sorted set
5.7 管道
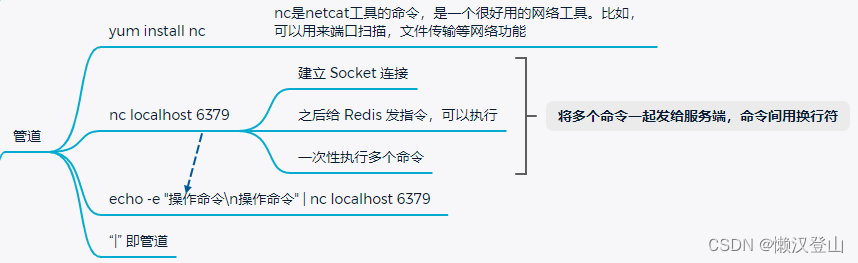
5.8 发布订阅(pub/sub)
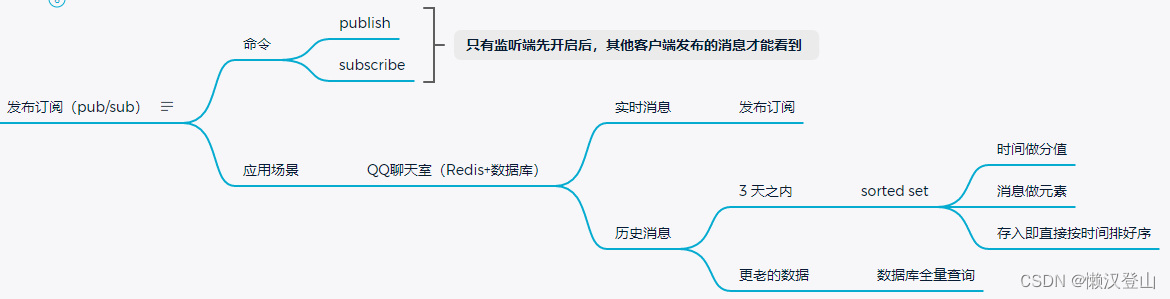
5.9 事务
5.10 布隆过滤器
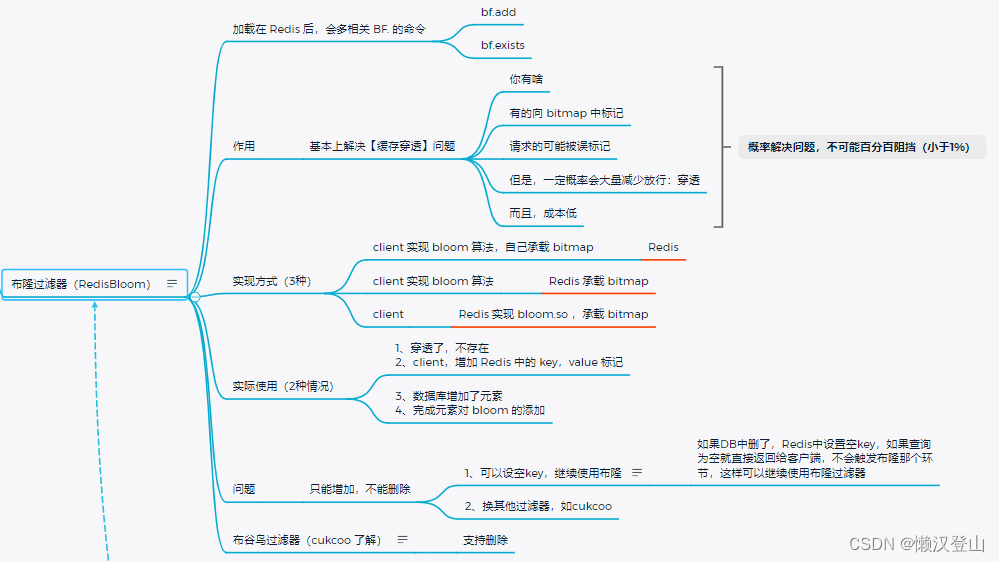
布隆过滤器的安装:
# 安装:
1、redis.io——》modules
2、访问redisBloom的github
3、linux中 wget *.zip
# 注:我这里用zip包无法make,用了这个
#【wget https://github.com/RedisBloom/RedisBloom/archive/v2.0.3.tar.gz】成功make和安装使用
4、yum install unzip
5、unzip *.zip
6、cd RedisBloom-master
7、make
8、cp redisbloom.so /opt/mxf/redis5/redisbloom.so
9、cd /opt/mxf/redis5/
8、redis-server --loadmodule /opt/mxf/redis5/redisbloom.so
--------成功--------
redis-cli
bf.add o abc
bf.exists o abc
bf.exists o def
# 注:--loadmodule /opt/mxf/redis5/redisbloom.so 这里必须是绝对路径,否则无法启动
6. Redis作为数据库和缓存的区别
6.1 缓存
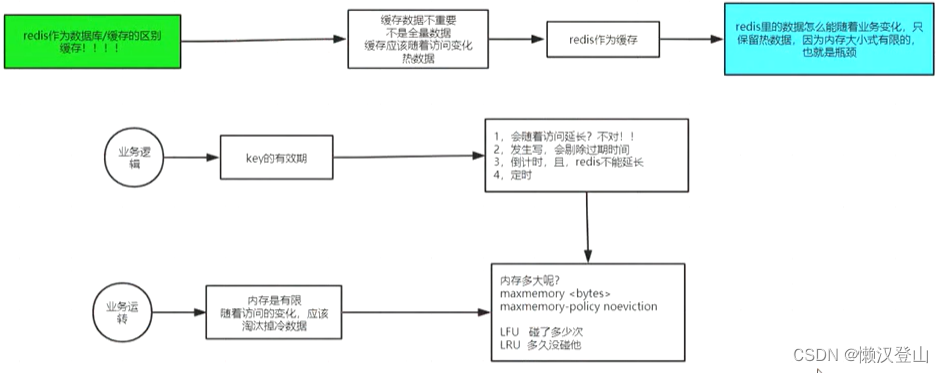
6.1.1 缓存和数据库的本质区别
- 缓存数据不重要,不是全量数据;
- 缓存应该随着访问变化,缓存热数据。
6.1.2 缓存数据清除
Redis作为缓存,里面的数据如何随着业务变化,只缓存热数据?因为内存容量有限,会成为瓶颈。
这就涉及到缓存数据清除策略:
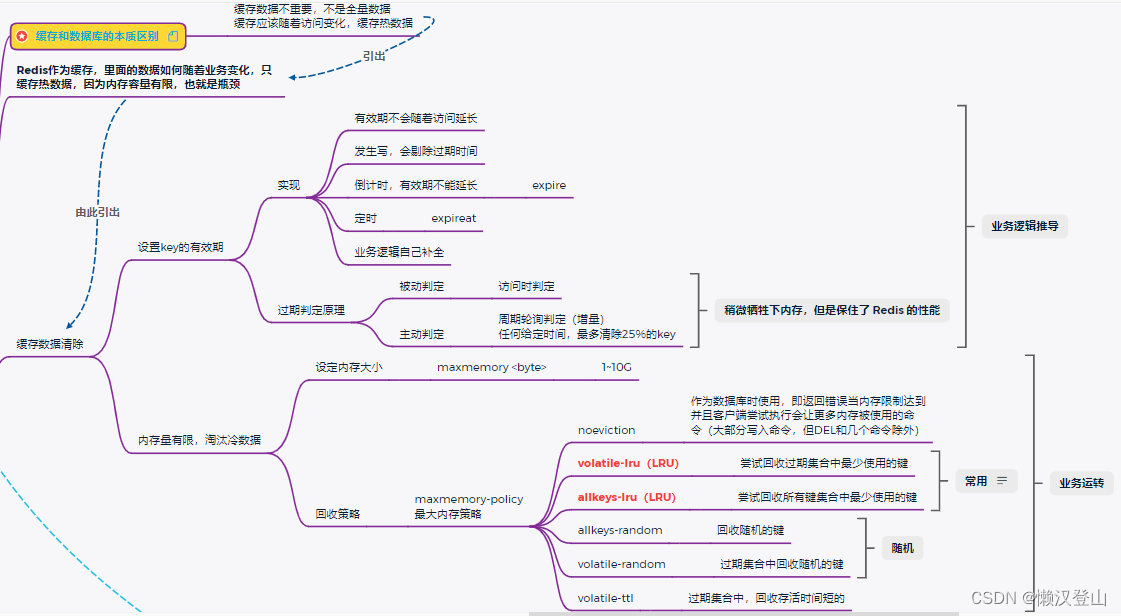
一、设置key的有效期(业务逻辑推导)
1、注意事项
- 有效期不会随着访问延长;
- 发生写,会剔除过期时间;
- 倒计时,有效期不能延长(expire命令);
- 定时(expireat命令);
- 业务逻辑自己补全。
2、过期判定原理
整体思想:稍微牺牲下内存,但是保住了Redis的性能。
(1)被动判定
访问时判定,即客户端访问时判定key是否过期,若过期则清除key。
(2)主动判定
周期性轮询判定(增量的方式),任何给定时间,最多清除25%的key。
二、内存量有限,淘汰冷数据(业务运转)
1、设定内存大小
通过配置文件,设置maxmemory最大内存的大小,一般为1~10G。
2、回收策略(缓存淘汰策略)
注意:Redis的淘汰策略是基于近似算法的,即并不是严格按照策略进行淘汰,而是根据一定的概率进行淘汰。Redis还提供了手动删除数据的命令,可以通过DEL命令主动删除指定的键值对。
Redis缓存淘汰策略包括LRU、LFU、Random、TTL和maxmemory-policy等,可以根据实际需求选择合适的策略,来进行缓存淘汰。
(1)LRU(Least Recently Used,最近最少使用):Redis会根据键的最近使用时间来淘汰数据,即最近最少使用的数据会被优先淘汰。这时Redis默认的淘汰策略。
(2)LFU(Least Frequently Used,最不经常使用):Redis会根据键的使用频率来淘汰数据,即使用频率最低的数据会被优先淘汰。
(3)Random(随机):Redis会随机选择一些数据进行淘汰。
(4)TTL(Time To Live,生存时间):Redis会根据键的过期时间来淘汰数据,即过期时间最早的数据会被优先淘汰。
(5)maxmemory-policy(最大内存策略):Redis会根据配置的最大内存限制来淘汰数据,具体的淘汰策略可以通过配置参数进行设置,常见的策略有:
- noeviction:作为数据库时使用,即返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分写入命令,但DEL和几个命令除外);
- volatile-lru(LRU):尝试回收过期集合中最近最少使用的键;
- allkeys-lru(LRU):尝试回收所有键集合中最近最少使用的键;
- allkeys-random:回收随机的键;
- volatile-random:过期集合中回收随机的键;
- volatile-ttl:过期集合中,回收存活时间短的键。
其中,最常用的是volatile-lru和allkeys-lru这2个粗略。选型时如何选择,关键看占比:
- 如果缓存里大量key做了过期配置,优先使用volatile-lru;
- 如果没怎么做过期配置,依靠Redis自己腾空间去淘汰缓存,就用allkeys-lru。
6.1.3 Redis作为缓存的常见问题
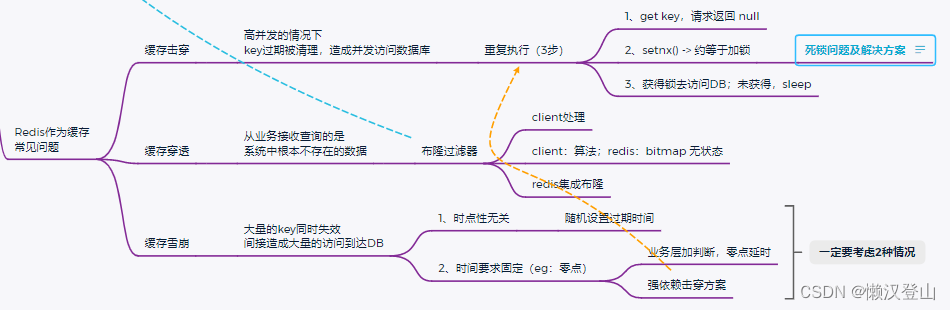
一、缓存击穿
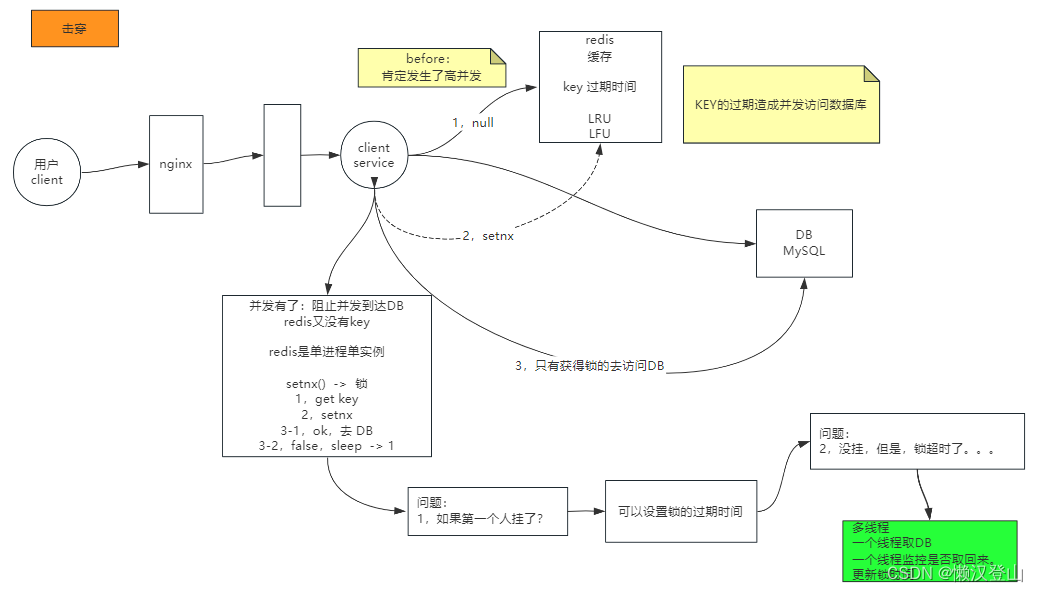
1、击穿描述:高并发的情况下,key过期被清理,造成并发访问数据库。
2、解决方案:
重复执行如下3步:
(1)get key,请求返回null;
(2)setnx(),约等于加锁;
死锁问题及解决方案
使用setnx()出现的问题及解决方案:
问题1:第一个去DB的挂了,这时锁未释放,导致后面的一直拿不到锁,出现死锁;
问题2:为了解决(问题1)死锁问题,可以设置锁的过期时间。这时又引出另一个问题,如果第一个去DB的没挂,但锁超时了,导致出现拥塞;
解决方案:可以使用多线程,A线程去DB取数据,B线程监控锁是否超时,并更新锁时间。
(3)获的锁去访问数据库DB;未获得,sleep。
二、缓存穿透
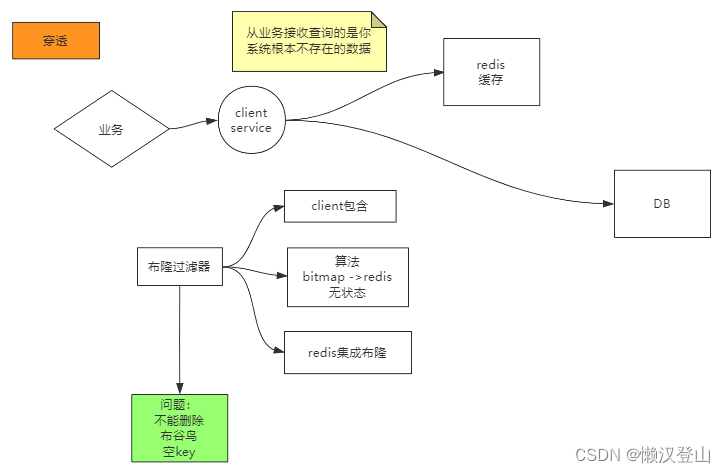
1、穿透描述:从业务接收查询的是系统中根本不存在的数据。
2、解决方案:
使用布隆过滤器,有三种方式:
(1)client实现算法 + bitmap;
(2)client实现算法,Redis中放bitmap(无状态);
(3)Redis集成布隆过滤器。
三、缓存雪崩
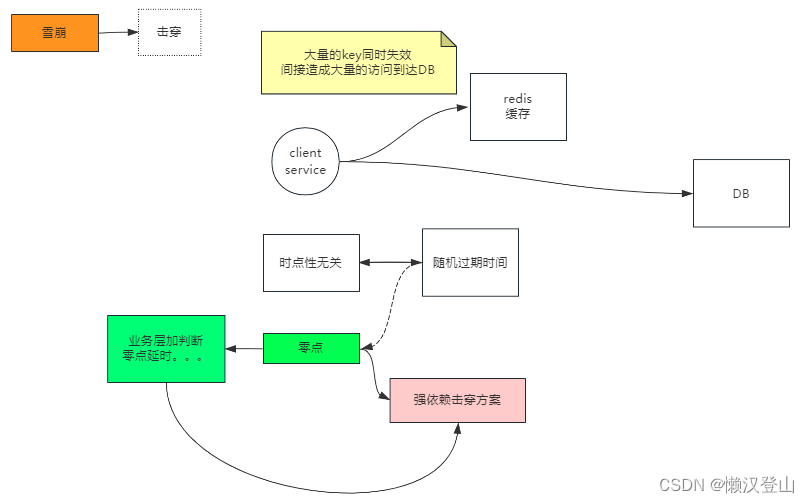
1、雪崩描述:大量的key同时失效,间接造成大量的访问达到DB。
2、解决方案:
一定要考虑到如下两种情形,采用不同方案:
(1)时点性无关:随机设置过期时间;
(2)时间要求固定(比如:零点):业务层加判断,零点延时,以及强依赖击穿方案。
6.2 数据库

6.2.1 概述
- 数据库存储的是全量数据,绝对不能丢失,追求速度+持久性;
- 缓存数据可以丢,追求极速。内存数据,掉电易失;
- 存储层的持久化方式一般为快照/副本+日志,如Redis的RDB和AOF。
6.2.2 持久化(RDB和AOF)
一、RDB
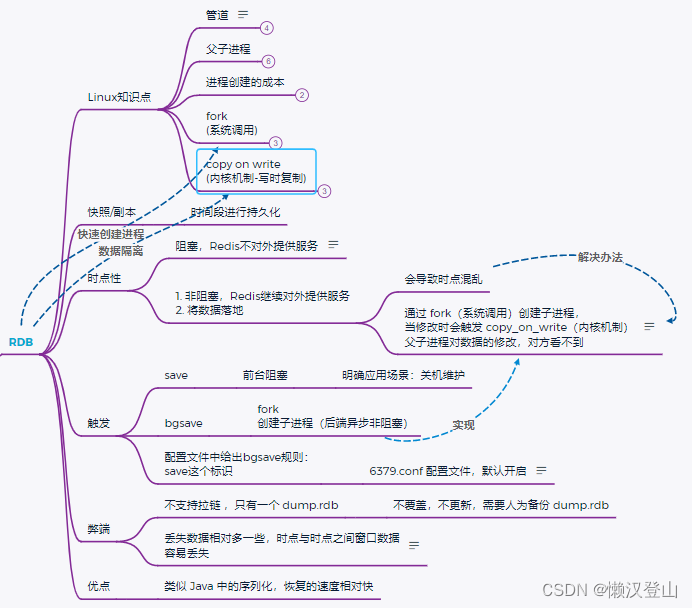
1、Linux知识点
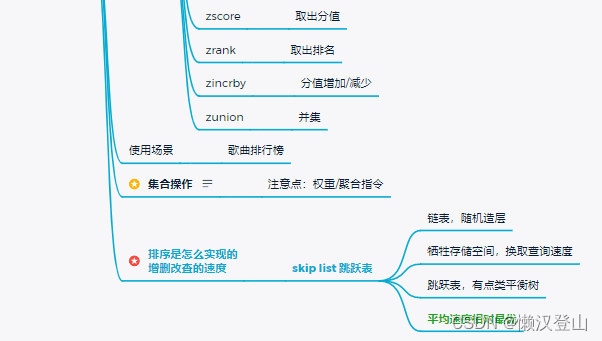
(1)管道
-
符号是“|”,作用是衔接:前一个命令的输出是后一个命令的输入;
-
管道会触发创建【子进程】;
-
echo $$ | more echo $BASHPID | more # echo $$ 和 echo $BASHPID 都可以取当前进程ID号 $$ 优先级高于 | $BASHPID 优先级低于 | # 举例: echo $$ | more => 114017 # 先执行$$,即进程号 = echo $$ 显示父进程ID echo $BASHPID | more => 114107 # 先执行管道,创建子进程,再替换显示其子进程ID号
(2)父子进程
- 常规思想:进程是数据隔离的;
- 进阶思想:父进程可以让子进程看到数据,通过export环境变量;
- export的环境变量:子进程的修改不会破坏父进程,父进程的修改也不会破坏子进程。
(3)进程创建的成本
- 速度;
- 内存空间。
(4)fork(系统调用)
- 创建进程
- 速度快;
- 空间小。
(5)copy on write(写时复制-内核机制)
-
创建进程时并不发生复制;
-
提高创建子进程的速度;
根据经验,不可能父子进程把所有数据都修改一遍。
-
操作的是指针(地址映射)。
RDB就是依赖fork和copy on write在创建快照/副本时,快速创建进程和数据隔离的。
2、快照/副本
时间段进行持久化。
3、时点性
创建快照/副本时,两种方式:
-
阻塞,Redis不对外提供服务:
例如:8:00-8:30期间数据落地,db.file是8:00时点的数据。
-
非阻塞,Redis继续对外提供服务,同时将数据落地:
-
问题:单进程处理,数据落地同时进行数据写,会导致时点混乱;
-
解决方案:通过fork(系统调用)创建子进程,当修改时会触发copy_on_write(内核机制),父子进程对数据的修改,对方看不到。
1、fork系统调用,保证进程创建速度快(此时父子进程共同看到同一数据)。
2、cow内核机制,保证父子进程数据隔离。
即:fork + cow 结合保证RDB的时点正确,程序员只需要调用fork方法,cow是内核机制,不需要人为参与。
-
4、触发时机
-
save命令:前台阻塞,明确应用场景是–关机维护;
-
bgsave命令:fork创建子进程(后端异步非阻塞);
-
配置文件中给出bgsave规则:
save这个标识,6379.conf配置文件,默认开启:
save 900 1 save 300 10 save 60 10000 dbfilename dump.rdb dir /var/lib/redis/6379 Redis默认开启RDB,可以注释,或设置 save="",或者删除save来关闭RDB。
5、弊端
-
不支持拉链,只有一个dump.rdb,不覆盖,不更新,需要人为备份dump.rdb;
-
丢失数据相对多一些,时点与时点之间的窗口数据容易丢失。
如:8点得到一个rdb,9点刚要落一个rdb,挂机了。
6、优点
类似Java中的序列化,恢复的速度相对快。
二、AOF
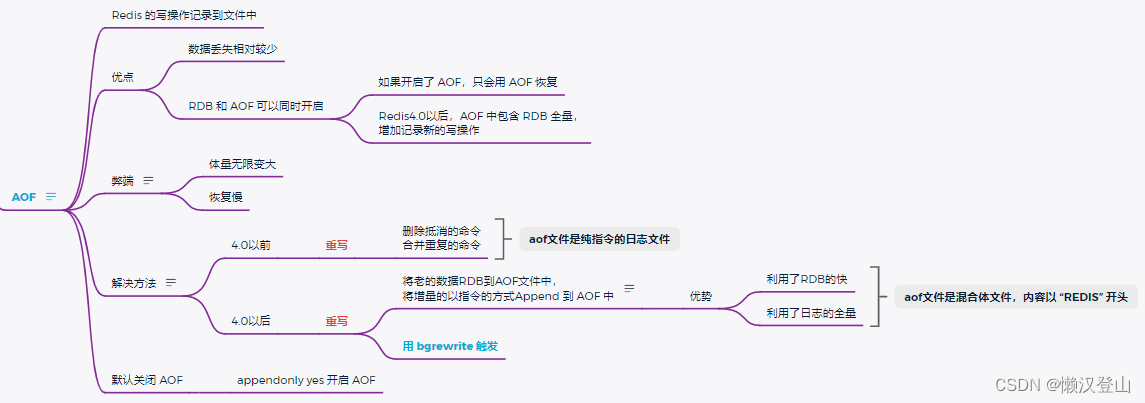
1、AOF(Append Only File,日志)即Redis的写操作记录到文件中。
2、优点
- 数据丢失相对较少;
- RDB和AOF可以同时开启。
- 如果开启了AOF,只会用AOF恢复;
- Redis4.0以后,AOF中包含了RDB全量,增加记录新的写操作。
3、弊端
- 体量无限变大;
- 恢复慢。
例如:Redis运行了10年,开启了AOF。
10年头,Redis挂了:
1、AOF多大:很大,可能10T;
那么恢复数据时,内存会不会溢出呢?不会。
2、恢复要多久:很久,可能要5年。
4、解决方法
(1)Redis4.0以前:
重写,删除抵消的命令,合并重复的命令(这时的AOF文件是纯指令的日志文件)。
(2)Redis4.0以后:
重写,将老的数据RDB到AOF文件中,将增量的数据一指令的方式Append到AOF中。
# 配置文件中,设置
aof-use-rdb-preamble yes # 开启混合
# rdb:二进制的,恢复快
这种方式的优势是:
- 利用了RDB的快;
- 利用了日志的全量。
- 这时的AOF文件是混合体文件,内容以“REDIS”开头。
注:以上两种解决方法,都必须用bgrewrite触发。
5、开启配置
Redis中AOF默认是关闭的,可以通过配置文件设置开启:
appendonly yes # 开启AOF
三、Redis的三种写IO级别

Redis是内存数据库,写操作会触发I/O。
Redis中有三种写的IO级别:
1、no:appendfsync no
内存满了就调一次flush,丢失数据最多,为一个buffer。
2、always:appendfsync always
每笔都调一次flush,丢失少,顶多1条数据。
3、everysec:appendfsync everysec(默认)
每秒调一次flush,丢失差1秒钟buffer数据满。
# 以下为Redis配置文件相关设置
appendonly yes
appendfilename "appendonly.aof"
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb =># 文件到达64M后,触发自动重写,历史数据就会被抵消掉
# 注:这里开始盯着64M,达到就会触发重写;记住这个64,下一次达到100%,即64+64,重写,第三次就是64*3 100% ...以此类推。
appendfsync always : # 只要写了,就立刻写入磁盘(丢失少,顶多1条)
appendfsync everysec : # 每秒将写入数据,写入磁盘(丢失差1秒钟buffer数据满,中间的,丢失相对少)
appendfsync no :# Redis不去flush,什么时候buffer满了,什么时候kernel将buffer数据flush到磁盘(丢失数据最多,为1个buffer)
四、实操















 154
154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









