







目录
Chapter 4. Structure of the Columbia Optimizer
4.2.1.2 搜索空间中的重复Multi-Expression检测
4.2.3.1 O_GROUP - Task to Optimize a Group
4.2.3.2 E_GROUP - Task to Expand the Group
4.2.3.3 O_EXPR - Task to Optimize a Multi-Expression
4.2.3.4 APPLY_RULE - Task to Apply a Rule to a Multi-Expression
4.2.3.5 O_INPUTS - Task to optimize inputs and derive cost of an expression
4.4 Usability in the Columbia Optimizer
4.4.2 Tracing of the optimizer
Chapter 5. Result and Performance
Chapter 2. Conclusions and Future works
ABSTRACT
查询优化是一个数据库系统能够获得重要性能收益的领域。现代数据库应用通常要求优化器具有高可扩展性和效率。
Columbia基于Cascades优化框架的自顶向下优化算法,通过对搜索空间结构和搜索算法的精心重构,简化了自顶向下优化器的设计。
Chapter 1. Introduction
可扩展优化器技术的第一次努力(我们称之为第一代)开始于大约十年前,意识到需要新的数据模型、查询类、语言和计算技术。这些项目包括Exodus和StarBurst。它们的目标是让优化器更现代化和易于扩展。它们使用的技术包括层次化的组件、基于rule的transformation等等。这些工作有一些缺陷,例如扩展的复杂性、搜索效率和面向record数据模型的偏好。
可扩展优化器的第二代,例如Volcano optimizer generator,增加了更复杂的搜索技术,更多地使用物理属性来指导搜索,并更好地控制搜索策略,以实现更好地搜索性能。尽管这些优化器具有一定的灵活性,但进行扩展仍然困难而复杂。
查询优化器框架的第三代,例如Cascade、OPT++、EROC和METU,采用面向对象的设计,简化了优化器的实现、扩展和修改任务,同时保持了效率,使搜索策略更加灵活。最新一代的优化器打到了满足现代商业数据库系统需求的复杂程度。
这三代的查询优化器可以分为两类搜索策略,Starburst风格的自下而上动态规划优化器和Cascades风格的自顶向下和绑定规则驱动的基于成本的优化器。自下而上的优化器通常在传统商业数据库系统中使用,因为它被认为是有效的。但是自下而上的优化器相比自顶向下优化器缺少了扩展性,因为它要求将原始问题分解为子问题。
尽管基于之前自顶向下优化的实现表明,它们很难像自底向上的优化器那样进行性能优化,但我们相信自顶向下的优化器在效率和扩展性方面具有优势。本文其他部分描述了我们开发的一种自顶向下的优化器Columbia的尝试,以证明采用自顶向下的方法可以实现高效率。
基于Cascades Optimizer Framework的自顶向下优化,Columbia广泛利用了c++的面向对象特性,并精心设计工程师,简化了自顶向下的优化,以实现效率,同时保持可扩展性。
为了最小化CPU和内存的使用,Columbia使用了多个工程技术。包括消除重复expression的快速hash函数,group中逻辑和物理表达式的分离,小而紧凑的数据结构,优化group和input的高效算,以及处理enforcer的高效方法。
另外一个Columbia使用的重要技术是group剪枝,它极大地减少了搜索空间,同时保留了规划质量。优化器会在生成lower-level plans之前先为high-level physical plan计算cost。这些早期的cost可以作为后续优化的上界。在许多情况下,我们可以使用这些上界来避免生成整个expression group,从而在搜索空间中修剪大量可能的查询计划。
除了group剪枝,Columbia还实现了另一种剪枝技术:全局剪枝。这种技术通过生成可接受的接近最优的解来显著地修剪搜索空间。当找到一个解足够接近最优解时,优化目标就完成了,因此不需要考虑大量的表达式。对这种剪枝技术进行了分析。结果表明了优化的有效性和误差。
Chapter 2. Terminology
2.1 查询优化器
查询处理器的目的是接受用数据库系统的数据操作语言(DML)表示的请求,并根据数据库的内容对其进行评估。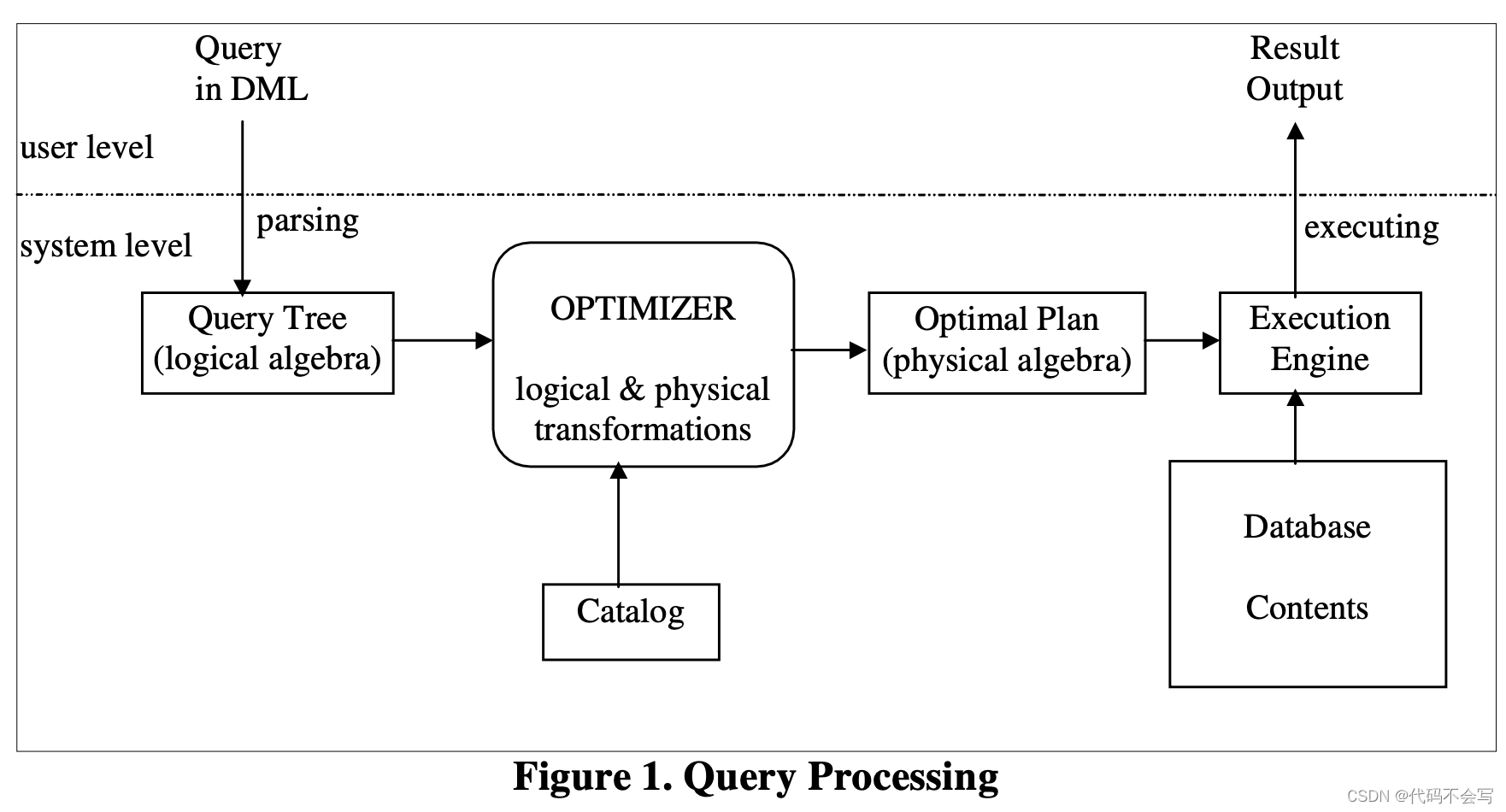
上图展示了查询处理过程中的步骤。DML语法中的原始查询被解析为逻辑代数构成的逻辑表达式树,其在后续阶段可以很容易被计算。查询的内部逻辑形式会被传递给查询优化器,它负责来将逻辑查询转换为物理查询计划,该计划会针对保存数据的物理数据结构进行执行。两种类型的transformation会被执行:
-
创建对查询等价的可选逻辑形式的logical transformation,例如交换树的左右子节点
-
和选择一种特定的物理算法来实现逻辑算子的physical transformation,例如针对join操作选择sort-merge join算法。
这个过程通常会产生大量的实现查询树的执行计划。找到最优的执行计划(相对于cost model来说,其包括了统计信息和其他catalog信息)是查询优化器的主要关注点。一旦一个最优(或是接近最优)的查询物理执行计划被选择,它就会被传递给查询执行引擎。查询执行引擎使用存储数据库作为输入来执行这个计划,并产生查询结果作为输出。
站在用户视角来看,查询处理过程是一个黑盒。用户通过high level的语言,例如SQL,Quel或是OQL,来提交查询请求到数据库系统,希望能够获得准确和快速的输出。准确性无意是一个查询处理器的绝对要求,同时性能是一个立项的特性,也是查询处理器的主要关注点。正如我们在查询处理过程的系统级别看到的一样,查询优化器一个对于高性能起作用的关键组件。对于一个查询来说,有大量的执行计划可以将它准确地执行,但是具有不同的执行性能。优化器的其中一个目标是找到具有最优执行性能的执行计划。优化器可以选择生成所有可能的执行计划并选择最优的一个。但是,探索所有可能的计划的成本非常高,因为即使是相对简单的查询,也有大量的替代计划。因此,优化器必须以某种方式缩小他们所考虑的备选方案的空间。
查询优化是一个复杂的搜索问题。研究表明,这个问题的简化版本是NP-hard。事实上,即使是最简单的关系Join,在使用动态规划时必须计算的join数量也是输入relation数量的指数关系。所以一个好的搜索策略对于优化器的成功是至关重要的。
2.2 逻辑算子和查询树
逻辑算子Logical Operator是指定了数据转换逻辑但不需要指定物理执行算法的high-level operators。在关系模型中,logical operators通常接收tables作为输入,并产生1个单独的table作为输出。每个logical operator都会接收指定数量的input(我们称之为operator的参数数量arity),并且可以会有一些能够区分operator变体的参数。
两种典型的logical operators是GET和EQJOIN。GET operator没有input,只有一个参数,即为存储relation的名称。GET从磁盘检索relation的元组并将这些元组输出给后续的operations。EQJOIN operator有2个input,即需要执行join的left和right table,以及一个参数,它是一组与左表和右表相关的连接谓词。
查询树query tree是一个代表了整个查询,并作为优化器输入的树形结构。通产来说一个query tree以一个logical operators的属性结构表示,其中每个节点是一个logical operator,有0个或多个logical operators作为它的输入。节点的子节点数量就是operator的参数数量arity。query tree用来执行operator的执行顺序。
2.3 物理算子和执行计划
物理算子Physical Operator代表着实现特定数据库操作的指定算法。一个或多个物理执行算法可以在一个数据库之上执行来实现一个给定的query logical operator。例如,EQJOIN operator可以使用nested-loop或是sort-merge或是其他算法来实现。这些特定的算法可以在不同的physical operator中实现。和logical operator一样,每一个physical operator也都有固定数量的input(即operator的参数数量arity),以及可能存在的参数。
将query tree中的logical operator替换为能够实现它们的physical operator,将产生一棵physical operator tree,对于给定查询,这被称为执行计划Execution Plan或访问计划access plan。图3显示了与图2(b)中的查询树相对应的两种可能的执行计划。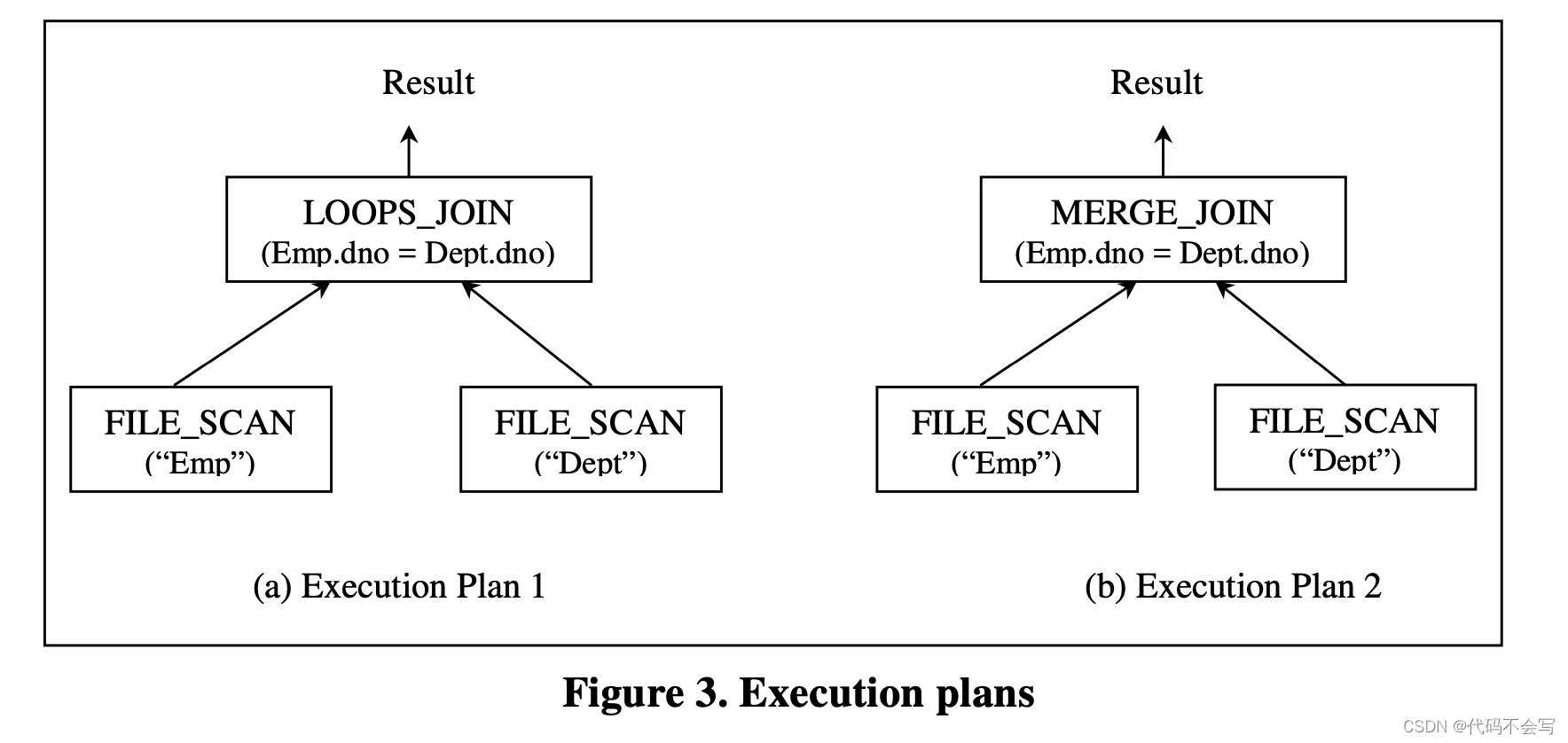
Execution plan指定了查询的评估方式。每一个执行计划都有一个与cost model和catalog信息对应的执行cost。通常来说,优化器会为一个给定查询生成一个好的执行计划,并作为查询执行引擎Query Execution Engine的输入,查询执行引擎会根据数据库系统的数据来执行整体的算法,易产生给定查询的输出结果。
2.4 Groups
一个给定的查询可以通过逻辑等价的一个或其他的query treee表达。如果两个query tree对于数据库的任意输出产生完全相同的结果,那我们就称它们是逻辑等价logicall equivalent的。对任意的query tree,通常来说都会有一个或多个实现该query tree并产生严格一致结果的execution plan。同样,这些执行计划execution plan也可以成为是逻辑等价的。下图展示了几个逻辑等价的query tree和execution plan。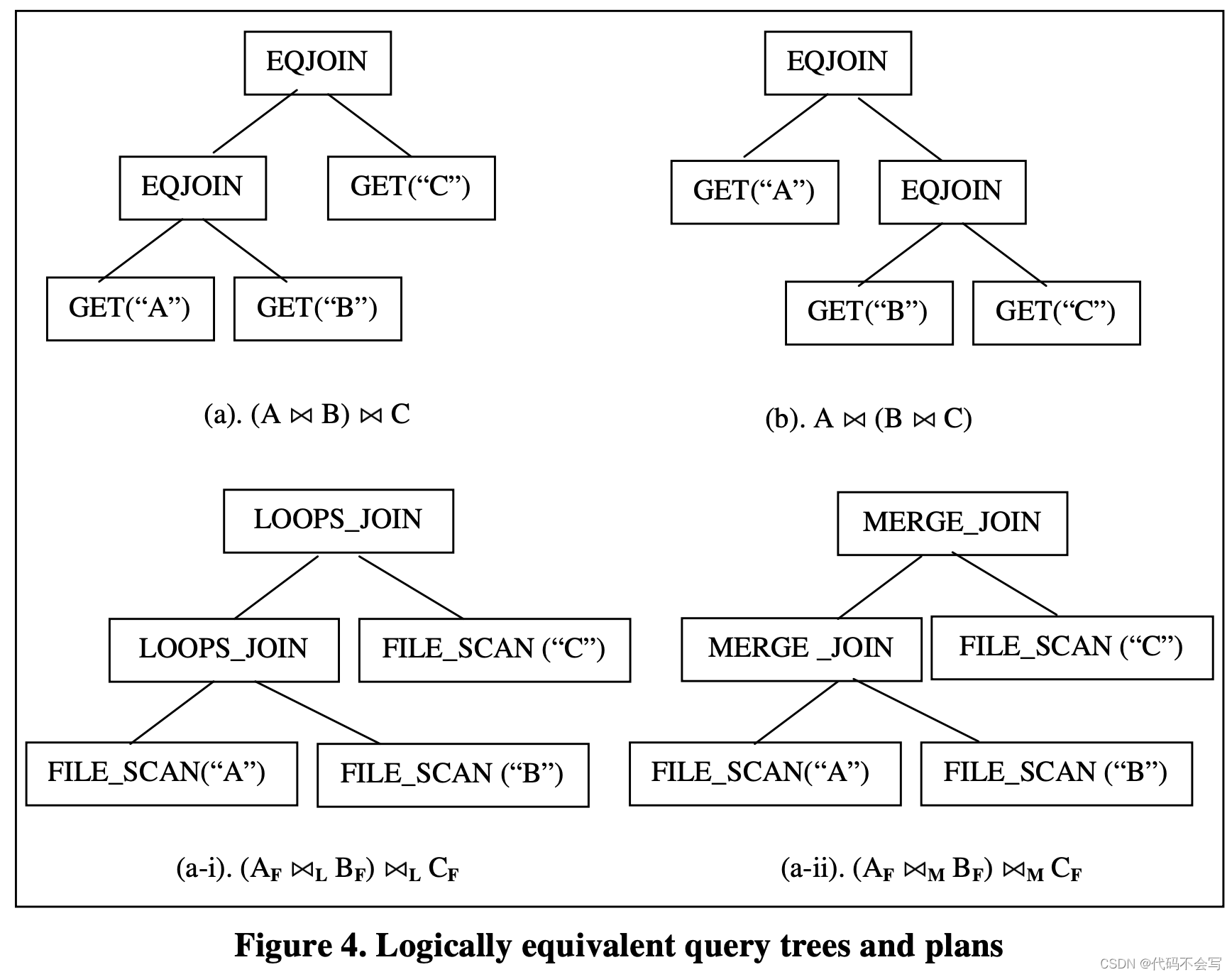
我们可以使用表达式expression来代表query tree和execution plans(或是sub trees和sub plans)。一个expression由一个operator和零个或一个input expression组成。根据operator的类型,我们将expression称为logical expression或physical expression。因此,query tree是logical plan,而execution plan是physical expression。
给定一个logical expression,它会有一系列的逻辑等价的logical和physical expressions。将它们收集到group中并定义公共的属性是非常有用的。一个Group就是一组逻辑等价的expression。通常来说,一个group会包含一个expression的所有等价的logical形式,以及这些logical形式对应的可选的physical expression。通常,一个group的每个logical expression都有不止一个physical expression。下图展示了一个包含Figure 4中的expression及其的等价expression。
为了减少一个group中的expression数量,Multi-expressions被引入了。一个Multi-expression由一个logical或是physical operator组成,并接收group作为input。Multi-expression和expression是一样的,除了它的input是group,而expression的input是其他expression。Multi-expression的优势在于,它极大地节省了空间,因为一个group中的等价multi-expression会更少。下图为group[ABC]对应的等价multi-expression。和Figure 5相比,group中的multi-expression少了。事实上,一个multi-expression通过获取group作为input可以代表多种不同的expression。
在典型的查询处理中,在产生最终结果钱会产生许多中间结果(元组的组合)。一个中间结果是通过计算一个group中的execution plan(或physical plan)产生的。在这个意义上,group对应于中间结果(这些group被称为intermediate group)。只会有一个最终结果,对应的group被称为final group。
一个group中的Logical properties被定义为结果的逻辑属性,而不管这个结果是如何物理计算和组织的。这些属性包括cardinality(元组的数量)、schema和其他属性。Logical properties作用于一个group中的所有expression
2.3 搜索空间
搜索空间search space代表对于一个给定初始化查询的logical query tree和physical plans。为了节省空间,search space使用一组group来表示,每个group接收一些group作为input。有一个top group会被执行为final group,对应于初始查询的最终评估结果。下图展示了给定查询的initial search space。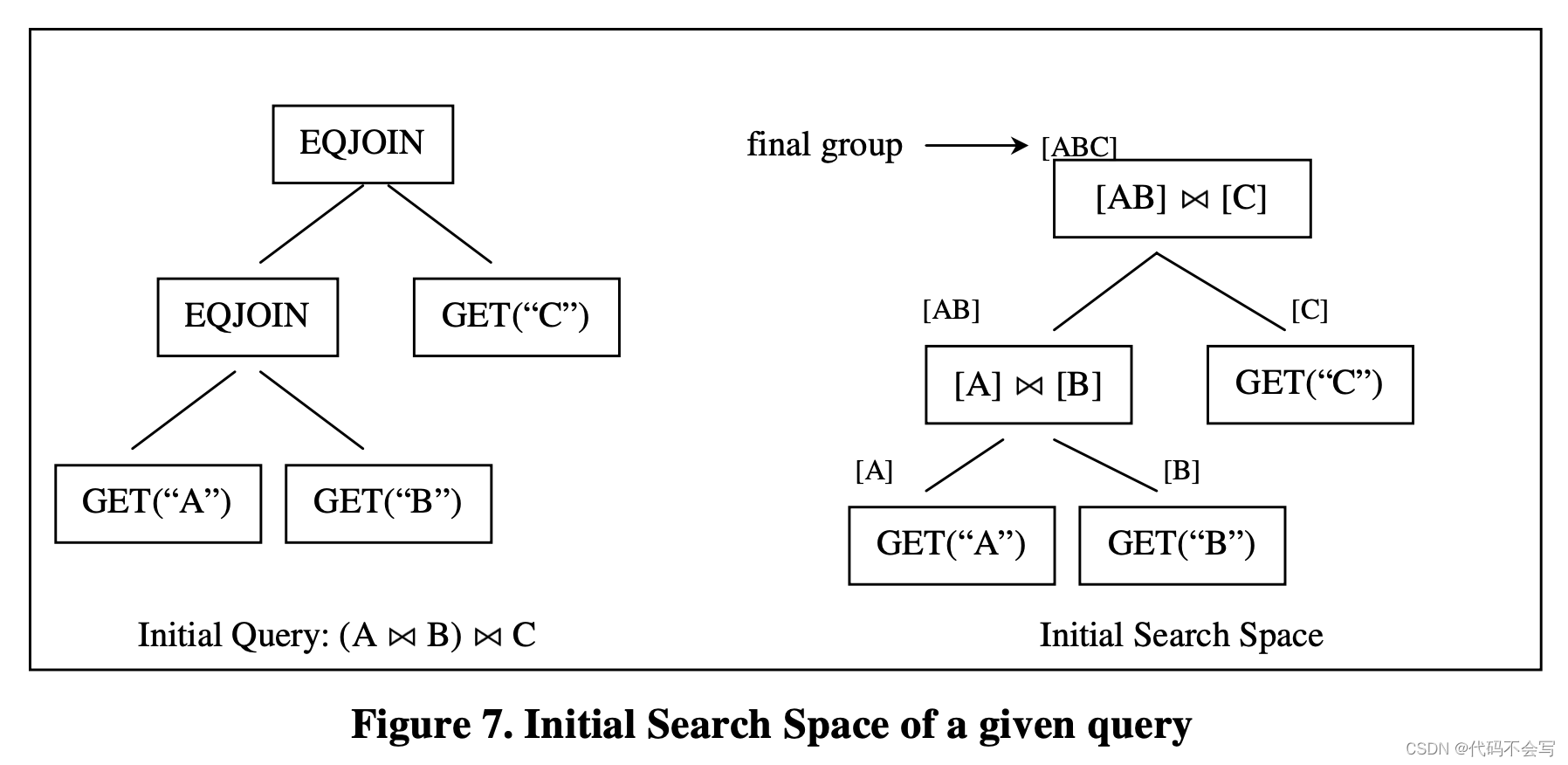
在initial search space中,每个group只包含一个logical expression,来源于初始的query tree。在上图中,group[ABC],就是查询的final group。它对应于3个relation join的最终结果。我们可以从initial search space中导出initial query tree。Query tree中的每一个节点对应着search space中每个group中的一个multi-expression。
在优化过程中,每个group中的逻辑等价logical和physical expressions会被生成,极大地扩展了搜索空间。每个group会有大量的logical和physical expressions。在优化生产physical expression的同时,physical expression的执行cost会被计算出来。从某种意义上来说,生成所有的physical expressions是优化目标,因为我们想要找到最优的执行计划,而且我们知道cost只和physical expression相关。但是为了生成所有的physical expression,就必须生成所有的logical expression,因为physical expression是logical expression的物理实现。
在完成优化过程,即为每一个group生成了所有的等价physical expressions,并且所有可能的execution plan的cost都被计算完成后,最优的execution plan可以在search space中被定为并作为优化器的输出。一个完全扩展的search space被称为final search space。通常,一个final search space代表了给定查询的所有逻辑等价的expressions(包括loigcal和physical的)。在final search space中我们可以通过递归的方法提取出所有可能的query tree。
但潜在query tree的数量是会随着执行计划节点的增长指数增长的,下表展示了一个具有n个relation的join的完全逻辑search space的复杂度,还只是考虑logical expressions的复杂度。假设在search space中有N个loigcal expressions,并且该数据库系统中M个join 算法,那么最终搜索空间会有M*N个physical expressions.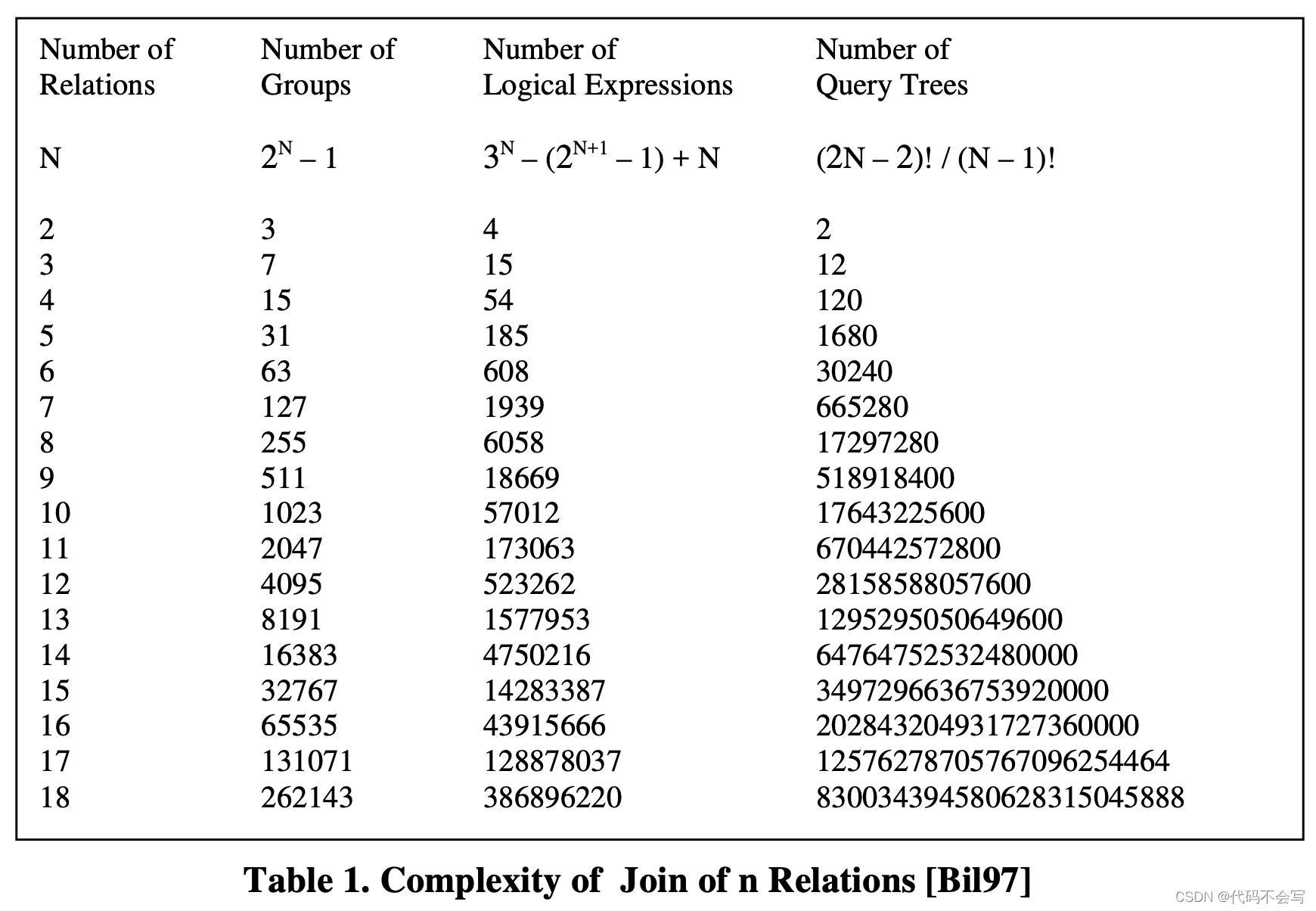
2.6 规则
许多优化器使用规则rules来生成一个给定初始查询的逻辑等价expression。一个Rule描述了如何从一个expression转换为一个逻辑等价expression。当一个Rule作用于一个给定的expression时就会产生一个新的expression。优化器会使用这些rule来扩展initial search space并基于给定的初始化查询来生成所有的逻辑等价expression。
每个rule会定义一对pattern和substitute。Pattern定义了可以应用这个rule作用的logical expression的结构。Substitute定义了在应用这个rule之后产生结果的结构。在扩展search space时,优化器会查看每一个logical expression,(注意rule不仅仅只作用于logical expression),并检查这个expression是否和rule set中的rules的任一Pattern匹配。如果一个rule的Pattern匹配上了,这个rule就会被处罚,根据rule的Substitute来生成新的逻辑等价expression。
Cascades使用expression来表示Pattern和Substitute。Pattern始终都是logical expression,但Substitute可以是logical expression或是physical expression。Transformation rules和Implementation rule是两种常见的rule类型。如果一个Rule的Substitute是logical expression,那么它被称作transformation rule。如果一个Rule的Substitute是physical expression,那么它被称为Implementation rule。这两种rule的示例如下图: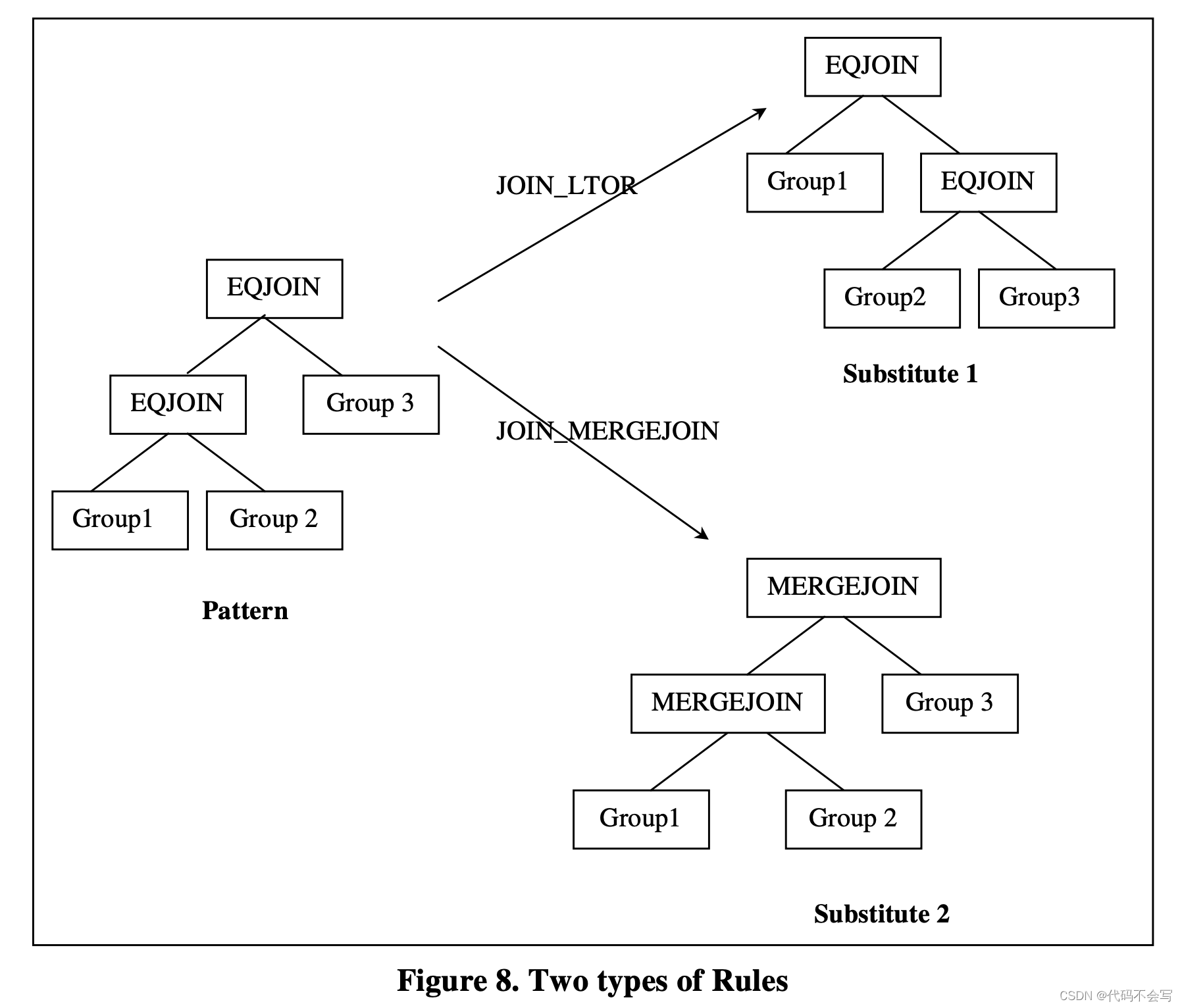
Chapter 3. Related Work
查询优化的开创性工作可以追溯到二十年前。IBM的System R优化器[SAC+79]取得了成功,并且工作得非常好,它已经成为当前许多商业优化器的基础。
数据库系统和应用程序不断发展,需要新一代的优化器来处理数据库系统的新扩展。关系数据模型扩展了更多的特性,比如支持新的数据类型和新的操作。引入面向对象的数据模型是为了处理更复杂的数据。由于早期的优化器被设计为与相对简单的关系数据模型一起使用,因此开发了新一代的可扩展优化器来满足不断发展的数据库系统的需求。新一代的优化器关注可扩展性以及所有优化器的困难目标:效率。本章将介绍一些对查询优化文献有重大贡献的著名优化器。
3.1 System R和Starburst优化器
System R优化器的一个重要的贡献是cost-based optimization。优化器使用存储在系统catalog中的relation和index的统计信息来确定一个查询评估计划的cost。cost估算分为两部分:一是对operator cost的估算。另一个是估计查询块结果的大小,以及是否对其排序。
对operator cost的估算要求获取input relation的多种参数,例如cardinality(relation的size),page的数量和可用的index。这些统计信息保留在DBMS system catalog中。size估算在cost估算中拌验证重要的角色,因为一个operator的output可以是另一个operator的input,并且operator的cost依赖于input的size。System R定义了一系列的size评估公式,这些公式在现在的查询优化器中仍然使用着,尽管近年来已经提出了基于更详细的统计数据的更复杂的技术(例如,系统值的直方图)。
System R优化器的另外一个重要的贡献是bottom-up动态规划搜索策略。动态规划的思想是在query tree中找到底层query block中的最优计划(query block概念对应于Cascade/Columnbia中的group),并只保留这些最优方案给上层的query block。它是一种自底向上的样式,因为它总是首先优化较低级的expression。为了计算上层expression的成本,必须计算其下层输入(也包括expression)的所有成本(以及结果的大小)。动态规划的技巧是:在我们优化了一个query block后(eg. 我们找到一个最优计划),我们会将这个query block的所有等价表达式都丢弃,只保留这个query block的最后计划。动态规划需要考虑O(3^N)个expressions(plan),其计算复杂度是一个指数增长的方式。当N比较大时,优化器需要考虑的expression的数量是不可接受的。因此System R优化器同时也使用了启发式heuristics的方法,例如将笛卡尔积相关的优化延迟到最终处理,或者是在优化大型查询时只考虑左深树(排除了大量的query tree,例如bushy tree)。但是,排除笛卡尔积或是只考虑左深树可能会被迫选择一个糟糕的方案,因此不能保证最优。
IBM的Starburst优化器[HCL90]使用可扩展的、更有效的方法扩展了System R优化器。Starburst由两个基于rule的子系统组成:查询重写或是查询图模型(Query Graph Model, QGM)优化器和plan优化器。QGM是查询的内部语义表示。QGM使用一组生产规则来以启发式的方式将QGM转换为一个语法等价的“更优”的QGM。这个阶段的目的是简化和改进消除冗余,并推导出更容易让计划优化器以基于成本的方式进行优化的表达式。plan优化器是一个select-project-join优化器,它由一个join枚举器和一个plan生成器组成。join枚举器使用两种连接可行性标准(强制和启发式)来限制连接的数量。join枚举器算法不是基于规则的,是用C语言编写的,并且它的模块设置允许它被其他可选的枚举算法替代。plan生成器使用类似于语法的生产规则来为join构造访问计划。这些参数化的生产规则被称为战略替代规则(Strategic Alternative Rules, STARs)。STARs可以决定那个table是inner,哪个是outer,要考虑哪些join方法等等。
在Starburst中,查询优化是一个两阶段处理。在第一个阶段,一个用QGM表达的初始化查询被传递给QGM优化器并被重写为一个“更优”的QGM。新的QGM被传递给plan优化器。在第二个阶段,plan优化器和QGM优化器通信并产生访问路径,并使用类似于System
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 472
472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









