







http://pandas.pydata.org/pandas-docs/stable/index.html
pandas官方文档
>>> df = pd.DataFrame(np.arange(12).reshape(3,4),
columns=['A', 'B', 'C', 'D'])
>>> df
A B C D
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11Drop columns
>>> df.drop(['B', 'C'], axis=1)
A D
0 0 3
1 4 7
2 8 11>>> df.drop(columns=['B', 'C'])
A D
0 0 3
1 4 7
2 8 11Drop a row by index
>>> df.drop([0, 1])
A B C D
2 8 9 10 11>>> df = pd.DataFrame({
... 'col1' : ['A', 'A', 'B', np.nan, 'D', 'C'],
... 'col2' : [2, 1, 9, 8, 7, 4],
... 'col3': [0, 1, 9, 4, 2, 3],
... })
>>> df
col1 col2 col3
0 A 2 0
1 A 1 1
2 B 9 9
3 NaN 8 4
4 D 7 2
5 C 4 3Sort by col1
>>> df.sort_values(by=['col1'])
col1 col2 col3
0 A 2 0
1 A 1 1
2 B 9 9
5 C 4 3
4 D 7 2
3 NaN 8 4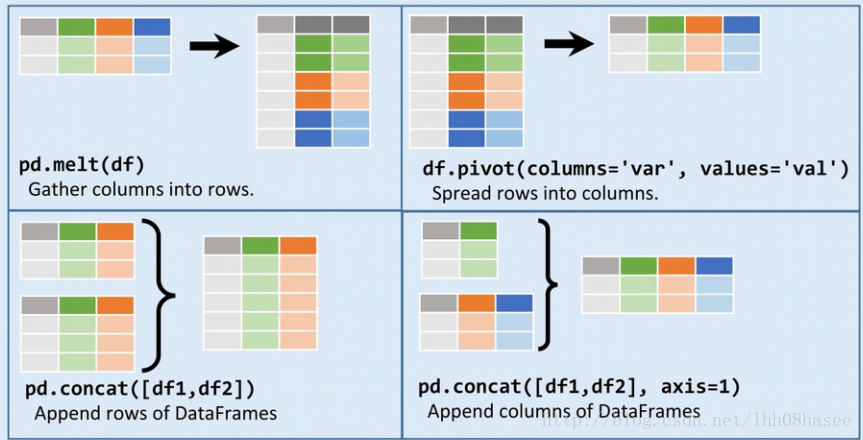
DataFrame.drop_duplicates(subset=None, keep=’first’, inplace=False)
subset : column label or sequence of labels, optional
用来指定特定的列,默认所有列
keep : {‘first’, ‘last’, False}, default ‘first’
删除重复项并保留第一次出现的项
inplace :默认为 False ,保留一个副本
True 是在原来数据上修改
df = pd.DataFrame({'a': [4,4,5,6],
'b': [7,7,8,9],
'c': [10,10,11,12]},index=['a','b','c','d'])
df.drop_duplicates(inplace=True) #在原数据上修改df = pd.DataFrame({'A': [4,4,5,6], 'B': [7,7,8,9], 'C': [10,10,11,12]},index=['a','b','c','d'])
A B C
a 4 7 10
b 4 7 10
c 5 8 11
d 6 9 12
df1 = pd.melt(df) #把列的数据移到行上
variable value
0 A 4
1 A 4
2 A 5
3 A 6
4 B 7
5 B 7
6 B 8
7 B 9
8 C 10
9 C 10
10 C 11
11 C 12
df2 = df.reset_index() #把行索引,复制当成一列
index A B C
0 a 4 7 10
1 b 4 7 10
2 c 5 8 11
3 d 6 9 12
a = df.sort_values(by='C', ascending=False) #对C那一列,排序由高到低,True为由低到高
b = df.drop('a') #删除行索引'a'的那行
A B C
d 6 9 12
c 5 8 11
a 4 7 10
b 4 7 10df数据:
A B C
a 4 7 10
b 4 7 10
c 5 8 11
d 6 9 12
df.loc['a'] #通过行标签索引行数据
A 4
B 7
C 10
df.iloc[2] #通过行号索引行数据
A 5
B 8
C 11
df.ix['a'] #通过行标签或者行号索引行数据(基于loc和iloc 的混合)
A 4
B 7
C 10
df.ix[:,'A'] #索引A 那一列
a 4
b 4
c 5
d 6















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









