




 本文详细介绍了如何从零开始使用Python实现KNN算法,并通过sklearn库进行分类。首先解释了KNN算法的基本原理,接着通过六步实现了自定义KNN算法并绘制了分类图像,最后展示了如何使用sklearn简化这一过程。
本文详细介绍了如何从零开始使用Python实现KNN算法,并通过sklearn库进行分类。首先解释了KNN算法的基本原理,接着通过六步实现了自定义KNN算法并绘制了分类图像,最后展示了如何使用sklearn简化这一过程。
利用 python 实现 KNN 算法(自己实现 和 sklearn)
创作背景
昨天有个朋友请我帮他做一个 python 的作业,作业要求如下图(翻译过)

也就是:
给定了数据集,使用 KNN 算法完成下列目标
- 编写
自己的代码实现KNN并且用绘制图像 - 使用
sklearn绘制图像(使用KNeighborsClassifier进行分类)
绘制的图像效果如下

- 偷偷说一句:如果对我的答案和解析满意的话可不可以给我
点个赞,点个收藏之类的 Let's do it !!!
思路讲解
先开始我很懵,毕竟我也没怎么学过 KNN ,只是大概了解这个算法,想必来看文章的你也是有点不知所云,所以我们就先了解一下这个算法。
了解算法
KNN ,全称是 K-NearestNeighbors ,直译过来就是 K 个距离最近的邻居 ,专业术语是 K 最近邻分类算法 。
俗话说的好,物以类聚,人以群分 ,这个算法也是体现了这个思想,说的是每个样本的类别都可以用 离它最接近的 K 个邻近值的类别 来代表。
拿最常用的一个例子来说,看下边这一张图
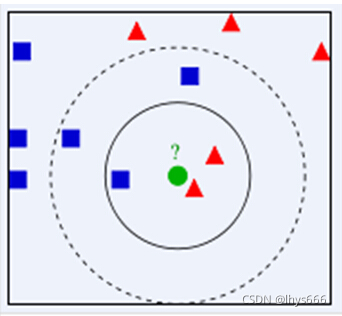
我们要判断 绿色的圆形 也就是未知的数据属于哪个类别,我们就可以根据离它最近的几个点的类别来判断。
- 如果
k = 3,也就是我们要看离这个点最近的3个点(如实心⚪圈住的点),其中2 个是 红色三角形 ,1 个是 蓝色正方形 ,那我们就可以判断这个未知的点属于 红色三角形 ,因为离它最近的三个点中红色三角形的点数量多。 - 如果
k = 5,也就是我们要看离这个点最近的5个点(如虚线⚪圈住的点),其中3 个是 蓝色正方形 ,红色三角形 的数量还是2 个,这时候形势逆转,那现在我们就认为未知点属于 蓝色正方形 。
上边的例子应该很好理解,其他数据也是类似。
作业思路(自己实现)
知道了 KNN 是怎么回事了以后我们就可以来做作业了。
第一步
Of course,导库 ,这次我们用到的库有 numpy,矩阵操作;pandas ,读取数据;collections ,统计数量;matplotlib,绘图 。
import numpy as np
import pandas as pd
from collections import Counter
import matplotlib.pyplot as plt
第二步
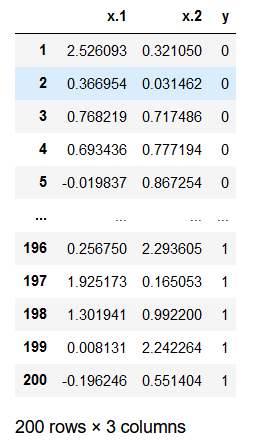
我们要 查看 一下作业 数据 ,并且进行 数据预处理 ,数据如下图所示(部分)
- 读取完毕后的数据,其中,
x.1和x.2分别是每个点的 横纵坐标 ,y是该点对应的 类别 ,取值为0和1。
- 数据预处理,即将点的坐标转换为
二维数组。np.concatenate进行矩阵合并,axis=1指定 横向合并 。代码如下(为了方便讲解代码逻辑,所以把一段长代码分为不同的行,文章后边也一样):
spots = np.concatenate(
[
np.array(df['x.1']).reshape(-1, 1),
np.array(df['x.2']).reshape(-1, 1)
],
axis=1
)
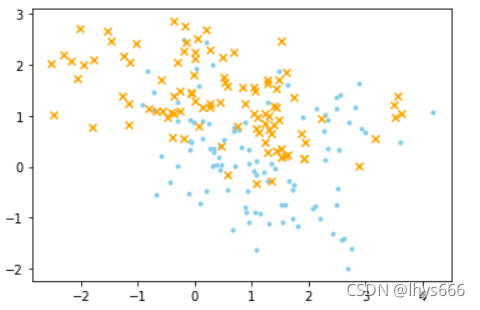
- 画一下
散点图,看一下数据分布,代码如下
for i, fig in enumerate([('#87CEEB', '.'), ('orange', 'x')]):
# 找到对应分类的点
data = df.where(df['y'] == i).dropna()
# 绘制散点图
plt.scatter(data['x.1'], data['x.2'], marker=fig[1], color=fig[0])
plt.show()
第三步
读取完数据后就到了第三步,利用 python 实现 knn 。
- 这里我们计算点之间的
欧式距离,并以此作为评判标准。 - 为了提高代码的
复用性,我将算法封装成函数,参数为要预测的点的坐标和k值,代码如下:
def take_nearest(grid, k):
'''
对传入的点进行 knn 分类
:param grid: 点的坐标
:type grid : tuple
:param k: 邻居个数
:type k : int
:return : 点的分类
'''
# 计算所有已知点距离未知点的距离,即实现 欧氏距离 的计算
distance = np.sqrt(
np.sum((spots - grid) ** 2, axis=1)
)
# 类别判断
# 具体细节见下述
cate = Counter(
np.take(
df['y'],
distance.argsort()[:k]
)
).most_common(1)[0][0]
return cate
- 其中:
distance.argsort()得到 排序后的列表 的 对应数据索引,[:k]取 前
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









