






 文章介绍了如何通过编程方式解析今日头条视频的真实地址,以便于在微信中安全分享。通过使用requests获取HTML源码,BeautifulSoup解析JSON数据,找到视频的MP4链接,然后提取出可直接播放的视频地址。
文章介绍了如何通过编程方式解析今日头条视频的真实地址,以便于在微信中安全分享。通过使用requests获取HTML源码,BeautifulSoup解析JSON数据,找到视频的MP4链接,然后提取出可直接播放的视频地址。
今天在今日头条上看到一个很好看的视频,但是想分享到微信的时候,别人不敢点开看,因为没有封面,就是一个作者的名字.现在很多人都非常谨慎,不会打开莫名其妙的链接.
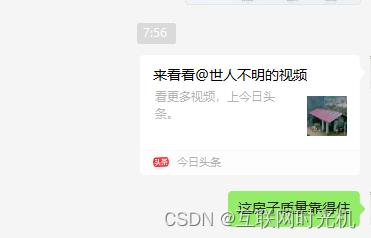
如图,分享到微信之后,就是这样显示的了.
平常我们的视频可以在微信里面直接打开.但是这样带链接的视频,一般别人是不敢点开的.
所以二话不说,立即使用代码来解决问题.按道理这样的代码AI都能够写出来,但是为了使写代码的手不生疏,还是亲自动手吧.
解析视频地址的思路是:
首先要确定视频是不是有真实的地址,所以自己先要用浏览器F12仔细找一下,看看有没有原始地址,如果有的话,肯定是可行的,如果找到的地址是m3u8这样的地址,那就基本行不通了.
所以思路就是这样的:
1,利用requests.get请求头条视频的原始地址,得到html源代码.
2, 分析html源代码中含有mp4的信息.得到有一段json包含了mp4信息.(人工分析出来的)
3,使用BeautifulSoup分析html.得到json信息.
4,使用json解析出视频地址
主要使用到的包有
import json
import urllib
import requests
from bs4 import BeautifulSoup视频链接如何获取

得到的地址一般是:
https://www.toutiao.com/video/7245981569750565408/
如果看到浏览器里面的地址就是这样的,那就不需要再分享,复制了.
接下来就可以写代码了.
源代码如下:
# -*- coding: utf-8 -*
# 头条视频解析
import json
import urllib
import requests
from bs4 import BeautifulSoup
# 模拟浏览器访问
# cookie 必须要,但是不用登录的cookie..先进入头条的页面,按f12查看cookie就可以了,全部复制也可以,只复制ttwid也可以
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Cookie":"ttwid=1%7CarG_9zGHRnvha3xXVrDKUesY-60w8j0Wn7FI6t6ZvFM%7C1687310450%7Cd2ec6a6525f124a59045e2e1314be8c6cdddaae26f8ae8cf06696d235fe1721b; "
}
# 分析html,里面有一段代码就是需要python 解析 html中<script id="RENDER_DATA" type="application/json">中间的字符串
def analyze_toutiao_url(url):
res = requests.get(url,headers=headers,timeout=10)
html_content = res.text
#print(html_content)
# 将 HTML 内容解析为 BeautifulSoup 对象
soup = BeautifulSoup(html_content, 'html.parser')
# print(soup)
# 查找包含 "id="RENDER_DATA"" 的 script 标签
tag = soup.find('script', id='RENDER_DATA')
# 提取 JSON 字符串
json_data = tag.string
print(json_data)
json_data2 = urllib.parse.unquote(json_data)
print(json_data2)
# 将 JSON 字符串解析为 Python 对象
data = json.loads(json_data2)
analyze_json(data)
print("*"*8)
# 分析json数据
def analyze_json(jsonData):
# 视频的格式不一样,json格式也不一样.例如有video_list和dynamic_video
videoPlayInfo = jsonData['data']['initialVideo']['videoPlayInfo'] # 该下面的属性不一样,需要判断
last_video_list = None;
if videoPlayInfo.get("video_list") :
last_video_list = videoPlayInfo['video_list'][-1] # 取最后一个,是最清晰的视频链接
elif videoPlayInfo.get('dynamic_video') :
last_video_list = videoPlayInfo['dynamic_video']['dynamic_video_list'][-1] # 取最后一个,是最清晰的视频链接
backup_url = last_video_list['backup_url'] # 最终的视频链接
print(backup_url)
if __name__ == "__main__":
# 复制头条的视频地址,解析出来的url就是可以下载的地址了
url = 'https://www.toutiao.com/video/7244425734473764154/'
analyze_toutiao_url(url)
这样基本上就得到了原始视频地址
类似这样的
解析出来的地址复制到浏览器打开即可


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











