







题目链接:http://acm.hust.edu.cn/vjudge/problem/viewProblem.action?id=10500
题意:每头奶牛都只愿意在她们喜欢的那些牛栏中产奶,,农夫约翰刚刚收集到了每头奶牛喜欢在哪些牛栏产奶。一个牛栏只能容纳一头奶牛,一头奶牛只能在一个牛栏中产奶。
根据牛的喜好,计算产奶奶牛的最大数量。
思路:典型的二分最大匹配、匈牙利算法模版题
代码:
#include<stdio.h>
#include<string.h>
#include<algorithm>
#include<math.h>
#include<iostream>
#define maxn 10005
using namespace std;
bool flag,visit[maxn]; //记录V2中的某个点是否被搜索过
int match[maxn]; //记录与V2中的点匹配的点的编号
int cow, stall; //二分图中左边、右边集合中顶点的数目
int head[maxn];
int index;//指输入的每个对应的编号
struct edge
{
int to,next;
}e[3000];
void addedge(int u,int v)
{ //向图中加边的算法,注意加上的是有向边
//u为v的后续节点既是v---->u
e[index].to=v;
e[index].next=head[u];
head[u]=index;
index++;
}//e数组记录边,e.pre指的是与它有相同顶点的前一条边的编号,e.to指连接的顶点
// 匈牙利(邻接表)算法
bool dfs(int u)
{
int i,v;
for(i = head[u]; i != 0; i = e[i].next)
{
v = e[i].to;
if(!visit[v]) //如果节点v与u相邻并且未被查找过
{
visit[v] = true; //标记v为已查找过
if(match[v] == -1 || dfs(match[v])) //如果i未在前一个匹配M中,或者i在匹配M中,但是从与i相邻的节点出发可以有增广路径
{
match[v] = u; //记录查找成功记录,更新匹配M(即“取反”)
return true; //返回查找成功
}
}
}
return false;
}
int maxmatch()
{
int i,sum=0;
memset(match,-1,sizeof(match));
for(i = 1 ; i <= cow ; ++i)
{
memset(visit,false,sizeof(visit)); //清空上次搜索时的标记
if( dfs(i) ) //从节点i尝试扩展
{
sum++;
}
}
return sum;
}
int main()
{
int i,j,k,ans,m;
while (scanf("%d %d",&cow, &stall)!=EOF)
{
memset(head,0,sizeof(head)); //切记要初始化
index = 1;
for (i = 1; i <= cow; ++i)
{
scanf("%d",&k);
for (j = 0; j < k; ++j)
{
scanf("%d",&m);
addedge(i , m);
}
}
ans = maxmatch();
printf("%d\n",ans);
}
return 0;
}
于是乎=。=这两天总是碰到二分最大匹配的题,但是没有合适的模版可以理解,好吧,其实主要是图中添加有向边的代码不是很理解,先来看看二分最大匹配的精髓,具体代码具体研究
具体的二分匹配有很多博客讲的灰常的清楚~点击打开链接
关于本题中所用代码,先看那个addedge()函数,其实是这样理解的
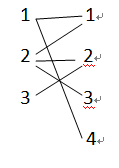

关于遍历dfs()函数,从head[i]开始,一直到e[head[i]].pre等于0,判断e[head[i]].to是不是被访问是不是被匹配。。。自己慢慢消化~















 806
806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









