






K8s网络通信
1.引言
2.概念
2.1前提概念
2.1.1 docker 镜像:
# 指定基础镜像
FROM ubuntu:latest
# 设置工作目录
WORKDIR /app
# 复制当前目录中的所有文件到工作目录
COPY . .
# 安装依赖包(可根据需要进行修改)
RUN apt-get update && \
apt-get install -y python3
# 运行命令或程序
CMD ["python3", "main.py"]
2.1.2 docker 容器:
步骤 描述
步骤 1 创建一个Docker Compose Yaml文件
步骤 2 定义服务和容器
version: '3'
services:
web:
image: nginx:latest
db:
image: mysql:latest
步骤 3 配置容器的属性
version: '3'
services:
web:
image: nginx:latest
ports:
- "80:80"
volumes:
- ./html:/usr/share/nginx/html
db:
image: mysql:latest
environment:
- MYSQL_ROOT_PASSWORD=secret
volumes:
- ./data:/var/lib/mysql
步骤 4 定义网络连接
version: '3'
services:
web:
image: nginx:latest
networks:
- mynetwork
db:
image: mysql:latest
networks:
- mynetwork
networks:
mynetwork:
步骤 5 运行和管理容器
# 启动容器
docker-compose up
# 后台启动容器
docker-compose up -d
# 停止容器
docker-compose down
# 查看容器状态
docker-compose ps
# 查看容器日志
docker-compose logs
2.2本节概念
2.2.1 Deployment
Deployment yaml文件包含四个部分:
apiVersion: 表示版本。版本查看命令:kubectl api-versions
kind: 表示资源
metadata: 表示元信息
spec: 资源规范字段
apiVersion: apps/v1 # 指定api版本,此值必须在kubectl api-versions中。业务场景一般首选”apps/v1“
kind: Deployment # 指定创建资源的角色/类型
metadata: # 资源的元数据/属性
name: demo # 资源的名字,在同一个namespace中必须唯一
namespace: default # 部署在哪个namespace中。不指定时默认为default命名空间
labels: # 自定义资源的标签
app: demo
version: stable
annotations: # 自定义注释列表
name: string
spec: # 资源规范字段,定义deployment资源需要的参数属性,诸如是否在容器失败时重新启动容器的属性
replicas: 1 # 声明副本数目
revisionHistoryLimit: 3 # 保留历史版本
selector: # 标签选择器
matchLabels: # 匹配标签,需与上面的标签定义的app保持一致
app: demo
version: stable
strategy: # 策略
type: RollingUpdate # 滚动更新策略
rollingUpdate: # 滚动更新
maxSurge: 1 # 滚动升级时最大额外可以存在的副本数,可以为百分比,也可以为整数
maxUnavailable: 0 # 在更新过程中进入不可用状态的 Pod 的最大值,可以为百分比,也可以为整数
template: # 定义业务模板,如果有多个副本,所有副本的属性会按照模板的相关配置进行匹配
metadata: # 资源的元数据/属性
annotations: # 自定义注解列表
sidecar.istio.io/inject: "false" # 自定义注解名字
labels: # 自定义资源的标签
app: demo # 模板名称必填
version: stable
spec: # 资源规范字段
restartPolicy: Always # Pod的重启策略。[Always | OnFailure | Nerver]
# Always :在任何情况下,只要容器不在运行状态,就自动重启容器。默认
# OnFailure :只在容器异常时才自动容器容器。
# 对于包含多个容器的pod,只有它里面所有的容器都进入异常状态后,pod才会进入Failed状态
# Nerver :从来不重启容器
nodeSelector: # 设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
caas_cluster: work-node
containers: # Pod中容器列表
- name: demo # 容器的名字
image: demo:v1 # 容器使用的镜像地址
imagePullPolicy: IfNotPresent # 每次Pod启动拉取镜像策略
# IfNotPresent :如果本地有就不检查,如果没有就拉取。默认
# Always : 每次都检查
# Never : 每次都不检查(不管本地是否有)
command: [string] # 容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] # 容器的启动命令参数列表
# 如果command和args均没有写,那么用Docker默认的配置
# 如果command写了,但args没有写,那么Docker默认的配置会被忽略而且仅仅执行.yaml文件的command(不带任何参数的)
# 如果command没写,但args写了,那么Docker默认配置的ENTRYPOINT的命令行会被执行,但是调用的参数是.yaml中的args
# 如果如果command和args都写了,那么Docker默认的配置被忽略,使用.yaml的配置
workingDir: string # 容器的工作目录
volumeMounts: # 挂载到容器内部的存储卷配置
- name: string # 引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string # 存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean # 是否为只读模式
- name: string
configMap: # 类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
ports: # 需要暴露的端口库号列表
- name: http # 端口号名称
containerPort: 8080 # 容器开放对外的端口
# hostPort: 8080 # 容器所在主机需要监听的端口号,默认与Container相同
protocol: TCP # 端口协议,支持TCP和UDP,默认TCP
env: # 容器运行前需设置的环境变量列表
- name: string # 环境变量名称
value: string # 环境变量的值
resources: # 资源管理。资源限制和请求的设置
limits: # 资源限制的设置,最大使用
cpu: "1" # CPU,"1"(1核心) = 1000m。将用于docker run --cpu-shares参数
memory: 500Mi # 内存,1G = 1024Mi。将用于docker run --memory参数
requests: # 资源请求的设置。容器运行时,最低资源需求,也就是说最少需要多少资源容器才能正常运行
cpu: 100m
memory: 100Mi
livenessProbe: # pod内部的容器的健康检查的设置。当探测无响应几次后将自动重启该容器
# 检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
httpGet: # 通过httpget检查健康,返回200-399之间,则认为容器正常
path: /healthCheck # URI地址。如果没有心跳检测接口就为/
port: 8089 # 端口
scheme: HTTP # 协议
# host: 127.0.0.1 # 主机地址
# 也可以用这两种方法进行pod内容器的健康检查
# exec: # 在容器内执行任意命令,并检查命令退出状态码,如果状态码为0,则探测成功,否则探测失败容器重启
# command:
# - cat
# - /tmp/health
# 也可以用这种方法
# tcpSocket: # 对Pod内容器健康检查方式设置为tcpSocket方式
# port: number
initialDelaySeconds: 30 # 容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 5 # 对容器健康检查等待响应的超时时间,单位秒,默认1秒
periodSeconds: 30 # 对容器监控检查的定期探测间隔时间设置,单位秒,默认10秒一次
successThreshold: 1 # 成功门槛
failureThreshold: 5 # 失败门槛,连接失败5次,pod杀掉,重启一个新的pod
readinessProbe: # Pod准备服务健康检查设置
httpGet:
path: /healthCheck # 如果没有心跳检测接口就为/
port: 8089
scheme: HTTP
initialDelaySeconds: 30
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 5
lifecycle: # 生命周期管理
postStart: # 容器运行之前运行的任务
exec:
command:
- 'sh'
- 'yum upgrade -y'
preStop: # 容器关闭之前运行的任务
exec:
command: ['service httpd stop']
initContainers: # 初始化容器
- command:
- sh
- -c
- sleep 10; mkdir /wls/logs/nacos-0
env:
image: {{ .Values.busyboxImage }}
imagePullPolicy: IfNotPresent
name: init
volumeMounts:
- mountPath: /wls/logs/
name: logs
volumes:
- name: logs
hostPath:
path: {{ .Values.nfsPath }}/logs
volumes: # 在该pod上定义共享存储卷列表
- name: string # 共享存储卷名称 (volumes类型有很多种)
emptyDir: {} # 类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
- name: string
hostPath: # 类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string # Pod所在宿主机的目录,将被用于同期中mount的目录
- name: string
secret: # 类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
imagePullSecrets: # 镜像仓库拉取镜像时使用的密钥,以key:secretkey格式指定
- name: harbor-certification
hostNetwork: false # 是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
terminationGracePeriodSeconds: 30 # 优雅关闭时间,这个时间内优雅关闭未结束,k8s 强制 kill
dnsPolicy: ClusterFirst # 设置Pod的DNS的策略。默认ClusterFirst
# 支持的策略:[Default | ClusterFirst | ClusterFirstWithHostNet | None]
# Default : Pod继承所在宿主机的设置,也就是直接将宿主机的/etc/resolv.conf内容挂载到容器中
# ClusterFirst : 默认的配置,所有请求会优先在集群所在域查询,如果没有才会转发到上游DNS
# ClusterFirstWithHostNet : 和ClusterFirst一样,不过是Pod运行在hostNetwork:true的情况下强制指定的
# None : 1.9版本引入的一个新值,这个配置忽略所有配置,以Pod的dnsConfig字段为准
affinity: # 亲和性调试
nodeAffinity: # 节点亲和力
requiredDuringSchedulingIgnoredDuringExecution: # pod 必须部署到满足条件的节点上
nodeSelectorTerms: # 节点满足任何一个条件就可以
- matchExpressions: # 有多个选项时,则只有同时满足这些逻辑选项的节点才能运行 pod
- key: beta.kubernetes.io/arch
operator: In
values:
- amd64
tolerations: # 污点容忍度
- operator: "Equal" # 匹配类型。支持[Exists | Equal(默认值)]。Exists为容忍所有污点
key: "key1"
value: "value1"
effect: "NoSchedule" # 污点类型:[NoSchedule | PreferNoSchedule | NoExecute]
# NoSchedule :不会被调度
# PreferNoSchedule:尽量不调度
# NoExecute:驱逐节点
2.2.2 Service
Service是Kubernetes的核心概念,通过创建Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址,并将请求负载分发到后端各个容器应用上。解决Pod动态变化后Ip不确定问题(4层负载TCP:IP)。
apiVersion: v1 # 指定api版本,此值必须在kubectl api-versions中
kind: Service # 指定创建资源的角色/类型
metadata: # 资源的元数据/属性
name: demo # 资源的名字,在同一个namespace中必须唯一
namespace: default # 部署在哪个namespace中。不指定时默认为default命名空间
labels: # 设定资源的标签
- app: demo
annotations: # 自定义注解属性列表
- name: string
spec: # 资源规范字段
type: ClusterIP # service的类型,指定service的访问方式,默认ClusterIP。
# ClusterIP类型:虚拟的服务ip地址,用于k8s集群内部的pod访问,在Node上kube-porxy通过设置的iptables规则进行转发
# NodePort类型:使用宿主机端口,能够访问各个Node的外部客户端通过Node的IP和端口就能访问服务器
# LoadBalancer类型:使用外部负载均衡器完成到服务器的负载分发,需要在spec.status.loadBalancer字段指定外部负载均衡服务器的IP,并同时定义nodePort和clusterIP用于公有云环境。
clusterIP: string #虚拟服务IP地址,当type=ClusterIP时,如不指定,则系统会自动进行分配,也可以手动指定。当type=loadBalancer,需要指定
sessionAffinity: string #是否支持session,可选值为ClietIP,默认值为空。ClientIP表示将同一个客户端(根据客户端IP地址决定)的访问请求都转发到同一个后端Pod
ports:
- port: 8080 # 服务监听的端口号
targetPort: 8080 # 容器暴露的端口
nodePort: int # 当type=NodePort时,指定映射到物理机的端口号
protocol: TCP # 端口协议,支持TCP或UDP,默认TCP
name: http # 端口名称
selector: # 选择器。选择具有指定label标签的pod作为管理范围
app: demo
status: # 当type=LoadBalancer时,设置外部负载均衡的地址,用于公有云环境
loadBalancer: # 外部负载均衡器
ingress:
ip: string # 外部负载均衡器的IP地址
hostname: string # 外部负载均衡器的主机名
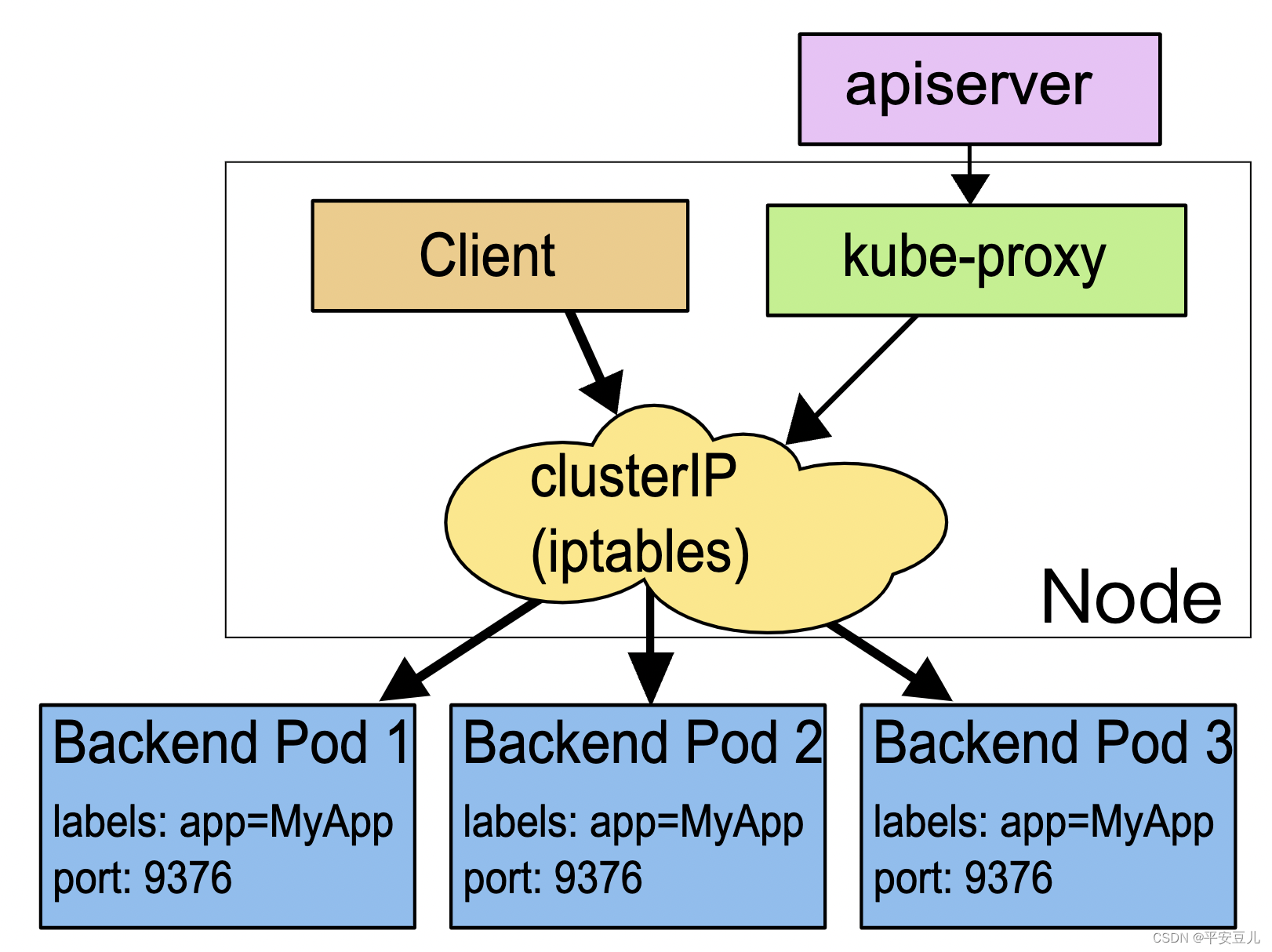
2.3.3 kuber-proxy
kube-proxy(Kubernetes Proxy)运行在每个 Kubernetes Node 节点上。kube-proxy是一个网络代理和负载均衡器,它负责处理集群内部服务的网络请求,并确保这些请求被正确地路由到相应的 Pod。
这里 Service 使用了 iptables 技术,每个节点上的 kube-proxy 组件自动维护 iptables 规则,客户不再关心 Pod 的具体地址,只要访问 Service 的固定 IP 地址,Service 就会根据 iptables 规则转发请求给它管理的多个 Pod,是典型的负载均衡架构。
不过 Service 并不是只能使用 iptables 来实现负载均衡,它还有另外两种实现技术:性能更差的 userspace 和性能更好的 ipvs,但这些都属于底层细节,我们不需要刻意关注。
问题:
k8s中service资源在node节点中,还是K8s容器中?
答:
Kubernetes 中的 Service 资源并不在 Node 节点中,也不在具体的容器中。Service 是一个抽象层,用于提供对一组 Pod 的网络访问的稳定方式。它定义了一组 Pod 的逻辑集合,并提供了一个固定的虚拟 IP 地址,称为 ClusterIP。
当你创建一个 Service 时,它将为这组 Pod 分配一个 ClusterIP,其他服务或应用程序可以通过该 ClusterIP 来访问这组 Pod。这样,Service 提供了一个抽象,使得 Pod 的变化不会影响到使用该服务的其他组件。
Service 的具体实现方式取决于其类型。以下是一些常见的 Service 类型:
1. **ClusterIP(默认类型):** 分配一个 ClusterIP,这个 IP 只在 Kubernetes 集群内部可访问,对外不可见。
2. **NodePort:** 在每个节点上都会监听相同的端口,并将流量转发到 Service 中的 Pod。这样,你可以通过节点的 IP 地址和 NodePort 来访问服务。
3. **LoadBalancer:** 通过云服务提供商(例如 AWS、Azure、GCP)的负载均衡器服务,将流量引导到 Service。
4. **ExternalName:** 提供了将 Service 映射到集群外部 DNS 名称的方法,而不是通过 ClusterIP。
无论 Service 的类型如何,它们本身并不直接运行在节点上,而是由 Kubernetes 控制平面进行管理,并通过代理、负载均衡器等机制将请求转发到底层的 Pod。
问题 service与kube-proxy与pod的关系?
2.2.4 ignress
它本身是K8s中的配置资源举个例子:让我尝试用一个更简单的比喻来解释。
想象你有一个大型建筑物,里面有很多不同的房间,每个房间都是一个应用程序或服务。现在,你想要让外部的人能够访问这些房间,但你不希望他们直接进入每个房间,而是通过一个前台接待室进行引导。
在这个比方中:
1. **大楼:** 就是你的Kubernetes集群,里面有很多不同的服务(房间)。
2. **每个房间:** 就是一个应用程序或服务,它们在集群中运行。
3. **前台接待室:** 这就是Ingress。它充当了大楼的入口点,外部的人(流量)都首先来到这里。
4. **Ingress规则:** 你在接待室设置的规则,告诉接待室的工作人员(Ingress控制器)如何引导外部人员到达每个房间。规则可能是“如果有人说要去咖啡店(域名是coffee.yourbuilding.com),就引导他们到咖啡厅房间;如果有人说要去办公室(域名是office.yourbuilding.com),就引导他们到办公室房间”。
所以,Ingress就像是大楼的前台接待室,通过定义规则,它能够把外部流量引导到正确的服务或应用程序。而Ingress Controller就像是接待室的工作人员,负责根据规则引导流量。希望这个比喻能帮助你理解Ingress的作用。
问题:K8s中Ingress 和Service 和 kube-proxy 和Pod 的关系?
让我们继续使用餐馆的例子来说明这些概念的关系:
1. **Pod(小厨师):** 假设你的餐馆有两个小厨师,分别负责烹饪意大利菜和日本料理。每个小厨师都是一个 Pod,运行在餐馆的厨房里。
2. **Service(服务员):** 你雇佣了一名服务员,这位服务员负责接受客户的点菜,并将订单传递给对应的小厨师。这个服务员就是 Service,它为客户提供了一个抽象的点餐接口。
- 当顾客说:“我想要意大利面”,服务员就知道把订单传递给烹饪意大利菜的小厨师(Pod)。
- 当顾客说:“我想要寿司”,服务员就知道把订单传递给烹饪日本料理的小厨师(Pod)。
3. **kube-proxy(传菜员):** 假设你有一位传菜员,负责将小厨师烹饪好的菜送到客户的桌上。这位传菜员就是 kube-proxy,它确保从小厨师(Pod)到客户之间的菜单正确送达。
4. **Ingress(大门):** 你在餐馆大门设置了一块告示板,上面写有不同餐区的信息。这块告示板就是 Ingress,它为顾客提供了进入餐馆的指引。
- 当顾客从前门进来时,Ingress 告示板指引他们进入正餐区(Main Service)。
- 当顾客从侧门进来时,Ingress 告示板指引他们进入咖啡区(Coffee Service)。
综合起来,Pod 是负责烹饪的小厨师,Service 是服务员,kube-proxy 是传菜员,而 Ingress 则是餐馆的大门。通过这个组合,你可以在餐馆中提供不同种类的菜单,并确保它们在客户之间正确地传递和呈现。这类比有助于理解 Kubernetes 中这些概念的关系。
2.2.5 prot
- prot: port 是 k8s 集群内部访问service的端口,即通过 clusterIP: port 可以从 Pod 所在的 Node 上访问到 service。
- nodeProt: nodePort 是外部访问 k8s 集群中 service 的端口,通过 nodeIP: nodePort 可以从外部访问到某个 service。
- targetPort: targetPort 是 Pod 的端口,从 port 或 nodePort 来的流量经过 kube-proxy 反向代理负载均衡转发到后端 Pod 的 targetPort 上,最后进入容器。
- containerPort: 是 Pod 内部容器的端口,targetPort 映射到 containerPort。
- Service
在 Kubernetes 中,Service 是一种抽象,用于定义一组具有相同功能的 Pod 并提供对它们的网络访问。Service 的主要目标是创建一个稳定的网络端点,使得其他应用程序可以通过该端点与 Pod 进行通信,而不需要知道具体的 Pod IP 地址。
以下是 Service 的一些关键特性和详细说明:
1. **稳定的 ClusterIP:** Service 会被分配一个 ClusterIP,它是一个虚拟的稳定 IP 地址。其他的应用程序或服务可以通过这个 ClusterIP 来访问 Service,而无需关心背后的具体 Pod 地址。
2. **Service 类型:** Kubernetes 支持多种 Service 类型,每种类型都适用于不同的使用场景。
- **ClusterIP(默认类型):** 创建一个在集群内部可访问的虚拟 IP 地址。这是最常见的类型,用于在集群内部进行服务发现。
- **NodePort:** 在每个节点上公开一个端口,使得外部流量可以通过节点的 IP 地址和 NodePort 访问 Service。
- **LoadBalancer:** 使用云服务提供商的负载均衡器,将流量引导到 Service。适用于在云平台上暴露服务给外部访问。
- **ExternalName:** 将 Service 映射到集群外部的 DNS 名称。适用于需要将服务与集群外部的服务进行连接的情况。
3. **选择器(Selectors):** Service 使用标签选择器来确定它所代表的 Pod 集合。只有具有匹配标签的 Pod 才会被 Service 代理。
4. **端口匹配:** Service 通过端口匹配将流量引导到 Pod。例如,Service 可以监听 80 端口并将流量转发到 Pod 的 8080 端口。
5. **负载均衡:** 对于 ClusterIP、NodePort 和 LoadBalancer 类型的 Service,Kubernetes 提供了负载均衡功能。这意味着流量将平均分布到 Service 包含的各个 Pod 上,以确保均衡负载。
示例 Service 的 YAML 配置:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: ClusterIP
在这个例子中,Service 使用标签选择器 `app: my-app` 来选择具有该标签的 Pod。它监听 80 端口,并将流量转发到 Pod 的 8080 端口。这是一个 ClusterIP 类型的 Service。
3.1Type类型
3.1.1ClusterIp
3.1.2NodePort
- Ingress
- Servcie Mesh(概念API)
5.1概念关系
istio(具体实现)Istio和Linkerd是两个常见的用于实现Service Mesh的工具。
Istio的工作原理主要基于两个核心组件:数据平面(Data Plane)和控制平面(Control Plane)。
lstio工作原理?
1. 数据平面(Data Plane):数据平面由一组智能代理组成,这些代理(通常称为Envoy)被插入到服务之间的网络通信路径中。Envoy代理负责实际的网络通信,它们拦截服务之间的所有流量,并执行负载均衡、流量路由、故障恢复等功能。Envoy代理通过与控制平面交互,动态地更新其配置以反映集群中服务的当前状态。
2. 控制平面(Control Plane):控制平面负责管理整个服务网格的配置和策略。它由多个组件组成,包括Pilot、Citadel、Galley等。Pilot负责服务发现、负载均衡和流量路由,它向Envoy代理提供配置信息。Citadel负责安全性,包括服务间的身份验证和加密通信。Galley负责验证、转换和分发配置。
综合来看,Istio的工作原理是通过Envoy代理拦截和管理服务之间的所有流量,同时由控制平面管理和配置整个服务网格,从而实现流量控制、安全性、可观察性等功能。
SOFO 生态:
在 SOFAMesh 中,数据面我们采用 Golang 语言编写了名为 MOSN(Modular Open Smart Network)的模块来替代 Envoy 与 Istio 集成以实现 Sidecar 的功能,同时 MOSN 完全兼容 Envoy 的 API。
SOFA Pilot
SOFAMesh 中大幅扩展和增强 Istio 中的 Pilot 模块:
SOFA Pilot 架构图
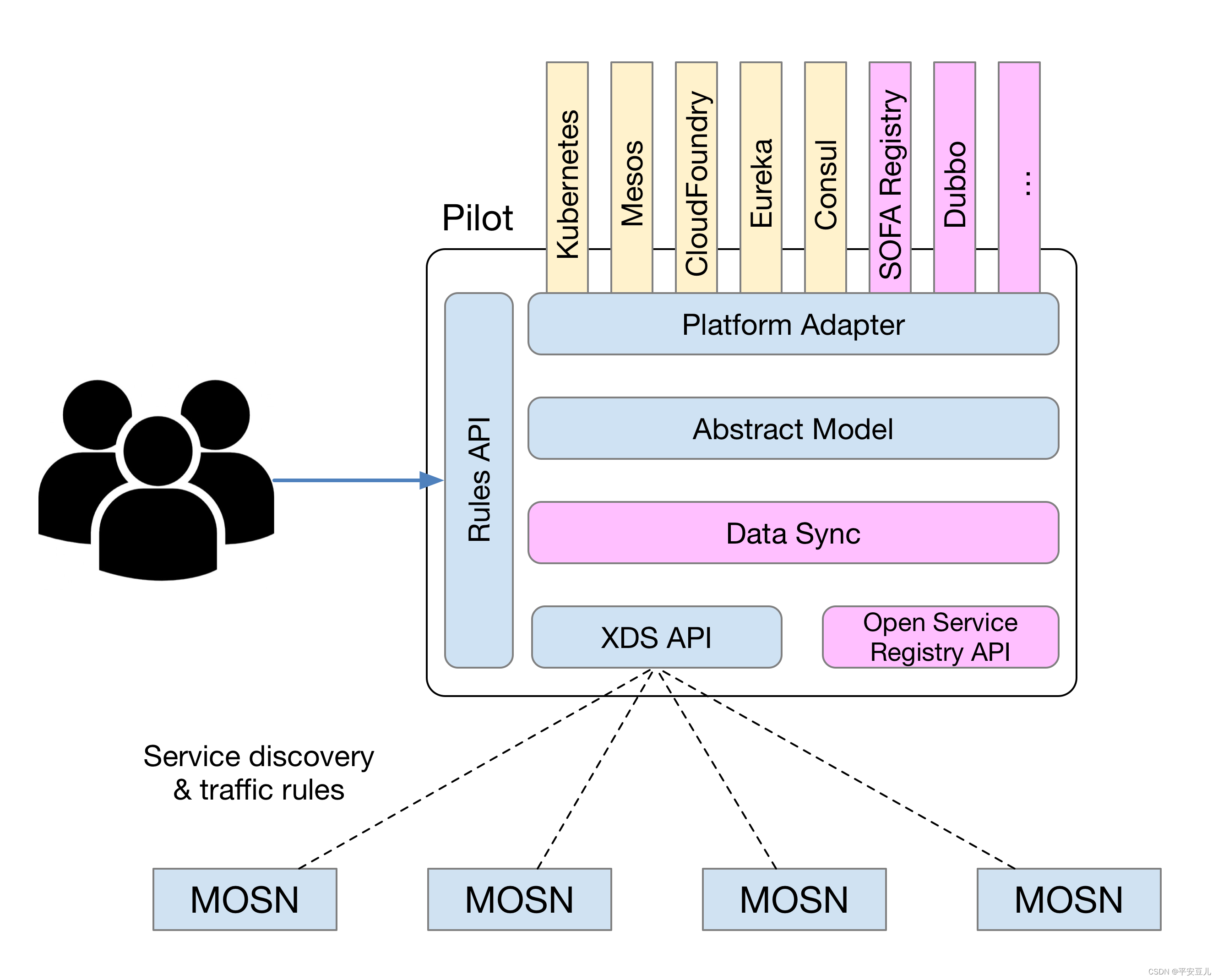
增加 SOFA Registry 的 Adapter,提供超大规模服务注册和发现的解决方案
增加数据同步模块,以实现多个服务注册中心之间的数据交换
增加 Open Service Registry API,提供标准化的服务注册功能
MOSN 和 Pilot 配合,将可以提供让传统侵入式框架(如 Spring Cloud、Dubbo、SOFARPC 等)和 Service Mesh 产品可以相互通讯的功能,以便可以平滑的向 Service Mesh 产品演进和过渡。
网格化后,微服务怎么注册的呢?
在网格化的环境中,微服务通常通过网格的注册机制来注册自己。这种注册过程与传统的服务注册类似,但是它是在服务网格中完成的,而不是在单独的服务发现组件中。
具体而言,微服务在网格化后的注册过程如下:
1. **服务启动**:微服务启动时,它会与服务网格中的代理(如Envoy)建立连接。
2. **注册信息**:微服务将自己的位置和可用性信息发送给服务网格中的注册中心。这些信息通常包括服务的名称、地址、端口、健康状态等。
3. **定期更新**:微服务会定期向服务网格中的注册中心发送心跳或更新消息,以确保注册中心始终了解到该服务的最新状态。
4. **服务发现**:其他服务或客户端可以通过服务网格中的代理来发现特定服务。代理会向注册中心查询服务的位置信息,并将其返回给调用者。
5. **负载均衡和流量控制**:代理会根据负载均衡策略和流量控制规则,将流量路由到已注册的服务实例中。
在服务网格中,注册和发现是由代理负责管理的,而不是依赖于外部的服务发现组件。这使得微服务之间的通信更加简单和可靠,并且可以集成更多的功能,如流量控制、安全性、监控等。
问:混合云部署通信方式。
理解了,你想知道在一个混合部署环境中,即有部分服务部署在本地,另一部分服务部署在云上时,如何进行调用。在这种情况下,通常有几种方法可以实现跨部署环境的服务调用:
1. **直接调用**:
- 如果本地服务需要调用云上的服务,或者反之,可以直接使用服务的网络地址(IP地址或域名)进行调用。这就要求服务能够通过网络互相访问。在调用时,可以使用常规的通信协议,如HTTP、gRPC等。
2. **VPN(虚拟专用网络)**:
- 如果你有一个VPN连接,可以将本地网络和云上网络连接在一起,使得它们处于同一逻辑网络中。这样,本地服务就可以直接使用云上服务的内部地址进行调用,就像在同一网络中一样。
3. **Service Mesh**:
- 如果在云上部署了Service Mesh(如Istio),可以在本地服务和云上服务之间建立透明的通信管道。通过Service Mesh,本地服务可以通过服务名称来访问云上服务,而不需要关心具体的网络地址。
4. **API Gateway**:
- 可以在云上部署一个API Gateway,将云上的服务暴露出统一的API接口。本地服务可以通过调用API Gateway来访问云上的服务,而不需要知道具体的服务地址。
5. **消息队列/事件总线**:
- 可以使用消息队列或者事件总线来实现异步通信。本地服务将消息发送到云上的队列或者事件总线中,云上服务再进行处理。这种方式可以实现解耦和异步通信。
选择哪种方式取决于你的具体需求和环境限制。例如,如果你需要实时通信并且网络延迟较低,直接调用或者Service Mesh可能是更好的选择;如果需要跨网络进行安全通信,VPN可能更合适;如果需要统一管理API接口,API Gateway可能更适合等等。
【K8S】外部访问请求原理流程(service、kube-proxy、pod的关系)_k8s请求到pod的过程-CSDN博客
k8s里面的service和宿主机到底啥关系?这个service跑在哪里?外访问pod时做负载均衡? - 知乎
https://www.cnblogs.com/chenmaoling/articles/17341774.html
Kubernetes中的yaml文件_把deply转存yaml-CSDN博客
K8S之yaml 文件详解(pod、deployment、service)_k8s service yaml-CSDN博客














 5009
5009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









