







一、 如何实现非核心线程延迟死亡?
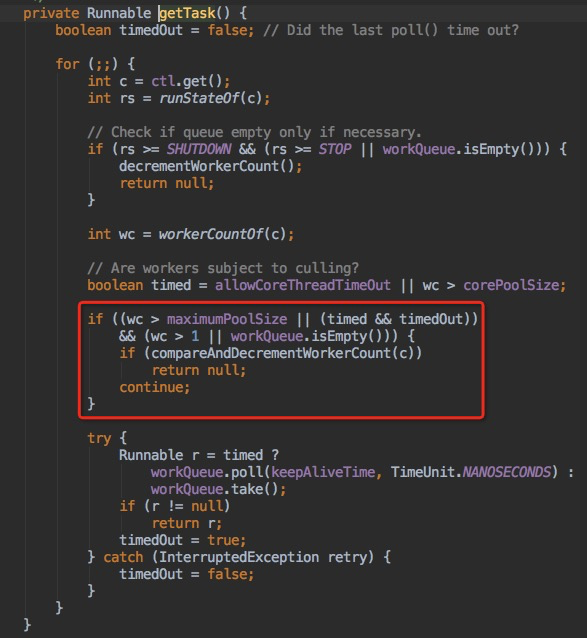
从runWorker方法可以看出,当getTask方法中获取不到执行任务的时候就会执行线程退出的操作

从下图可以看出返回null值的位置。
结论:非核心线程延迟死亡的条件为线程池处于运行状态&&当前线程数大于最大核心线程数&&获取任务时间超过keepAliveTime。
二、如何实现核心线程一直保活?
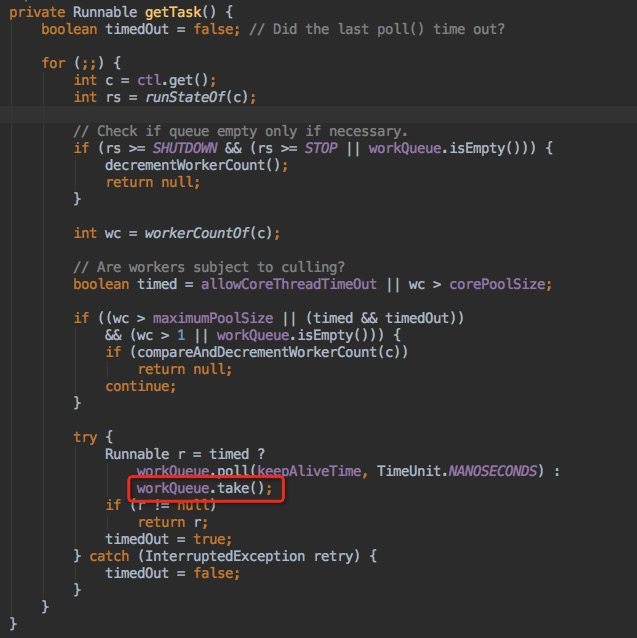
结论:通过阻塞队列take()方法让线程一直等待,使得Worker的run()方法一直阻塞,直到获取到执行任务,执行完任务后继续阻塞等待,使得线程生命周期一直在RUNNABLE和WAITING状态之间流转,保证核心线程一直存活。
三、 如何释放核心线程?
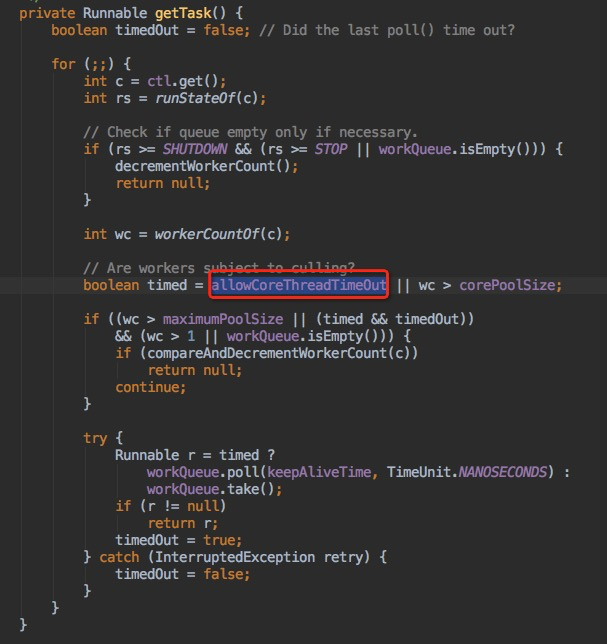
结论:allowCoreThreadTimeOut是ThreadPoolExecutor类的成员属性,将这个变量设置为true就可以跟非核心线程一样,在执行keepAliveTime还未获取到执行任务时就会移出线程池。
四、 非核心线程能成为核心线程吗?
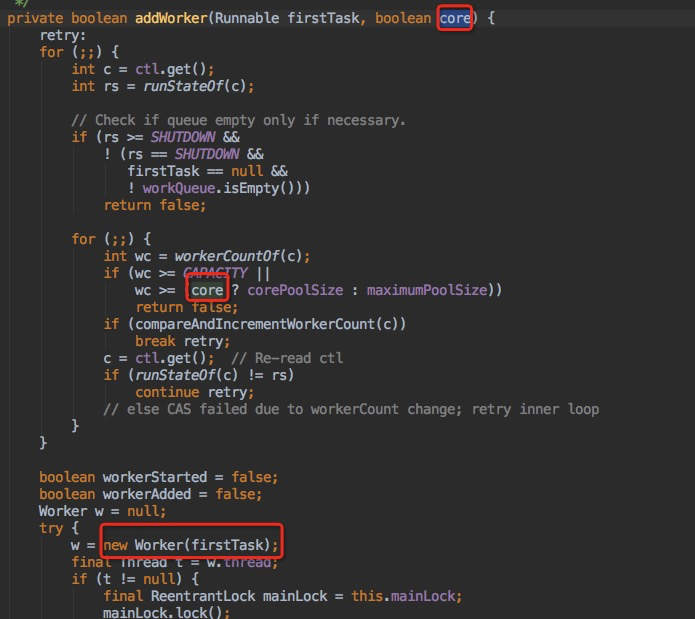
从下图线程池添加线程的代码中可以看出,core参数仅用于判断当前线程总数是与最大核心线程数比较还是与最大线程数比较。创建Worker线程类中并没有任何标识来表示一个是否是核心线程还是非核心线程。
五、 存放线程对象的容器为什么使用HashSet?

根据前面的一些知识我们已经知道了在ThreadPoolExecutor源码中的工作线程类是Worker(实现了Runnable接口),它是对线程池中工作线程的抽象。那为什么存放工作线程的集合要使用HashSet呢?我们翻看源码就知道ThreadPoolExecutor中对worker集合(HashSet)只有add和remove操作。我们知道Java中HashSet基于HashMap来实现的,只要hash函数和负载因子factor设计的足够好(最大化减少hash碰撞的概率),这些操作对于HashSet来说时间复杂度均为O(1),而且线程数中对线程进入集合的顺序和优先级都没有要求,跟其他集合类相比,在空间复杂度一致的情况下,当然是时间复杂度最好的集合类优先考虑。
六、线程数设置多少合理?
创建多少线程合适,要看多线程具体的应用场景。我们的程序一般都是 CPU 计算和 I/O 操作交叉执行的,由于 I/O 设备的速度相对于 CPU 来说都很慢,所以大部分情况下,I/O 操作执行的时间相对于 CPU 计算来说都非常长,这种场景我们一般都称为 I/O 密集型计算;和 I/O 密集型计算相对的就是 CPU 密集型计算了,CPU 密集型计算大部分场景下都是纯 CPU 计算。I/O 密集型程序和 CPU 密集型程序,计算最佳线程数的方法是不同的。
对于 CPU 密集型计算:多线程本质上是提升多核 CPU 的利用率,所以对于一个 4 核的 CPU,每个核一个线程,理论上创建 4 个线程就可以了,再多创建线程也只是增加线程切换的成本。所以,对于 CPU 密集型的计算场景,理论上“线程的数量 =CPU 核数”就是最合适的。不过在工程上,线程的数量一般会设置为“CPU 核数 +1”,这样的话,当线程因为偶尔的内存页失效或其他原因导致阻塞时,这个额外的线程可以顶上,从而保证 CPU 的利用率。
对于 I/O 密集型的计算场景:如果 CPU 计算和 I/O 操作的耗时是1:1,那么 2 个线程是最合适的。如果 CPU 计算和 I/O 操作的耗时是 1:2,那多少个线程合适呢?是 3 个线程,如下图所示:CPU 在 A、B、C 三个线程之间切换,对于线程 A,当 CPU 从B、C 切换回来时,线程 A 正好执行完 I/O 操作。这样 CPU 和 I/O 设备的利用率都达到了100%。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









