







基本的自编码器(Autoencoder)是一个含有输入、隐含、输出的三层神经网络,它的目的是尽可能复现输入输出的关系。
一. 神经元
神经网络的最小组成单元是神经元,神经元的结构如下:
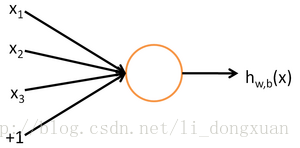
左边的 x1,x2,x3 是运算输入值, 1 代表截距(为什么要有截距:我们知道线性拟合的时候如果不含常数项即截距,那么无论怎么拟合数据都必将经过原点,这很有可能和实际数据不符,在神经网络里也是这个原因)。
接着每个由输入到中间的那个圆圈的各条箭头线都附有权值
中间的圆圈代表激活函数 f(⋅) ,通常有s激活函数(sigmoid,取值范围0~1)和双曲正切函数(tanh,取值范围-1~1)。
最后的 h(x) 代表输出:
二. 神经网络结构
最基本的神经网络由输入、隐含、输出三层结构组成,如下图:
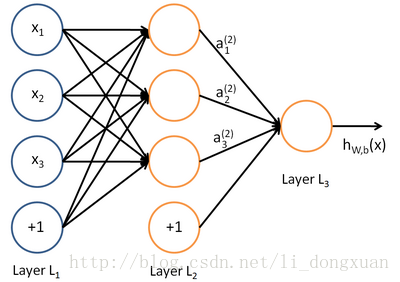
除了最后一层输出层,每一层的数据都包含额外的一项偏置结点,也就是之前说的截距。每一条带箭头的直线都代表一个权值( h(x) 后的那条除外)。黄色的圈都代表对他的所有直接输入数据的加权和的激活处理。
从第一层开始向后一步一步进行加权和激活运算,这个过程叫做前向传播。合理的神经网络会尽可能拟合现有数据的输入输出关系,而要想达到这一目的,我们需要找到每一层网络上的合适的权重 W ,这一求解过程的方法就是反向传播算法。
三. 反向传播算法(Backpropagation,BP)
首先我们要设定一个代价函数来评价神经网络求解结果的好坏,和线性拟合的代价函数类似,都是二次损失。整体的代价函数如下:
m
是数据里有
那么这里为什么要多一规则项(也称权重衰减项) λ2∑l∑i∑j(W(l)ji)2 呢:
因为我们为了稳定性要限制
W
的大小(一个稳定性解释的例子),必须添加一个关于的
λ 是权重衰减参数,用于控制公式中两项的相对重要性。
我们的目标是针对参数
W
和
需要再次强调的是,要将参数进行随机初始化,而不是全部置为0。如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数。
梯度下降法的本质其实就是迭代求编导数:
其中 α 是学习速率。其中关键步骤是计算偏导数。反向传播算法是计算偏导数的一种有效方法,反向传播算法具体步骤如下:
(1)进行前馈传导计算,利用前向传导公式,得到 L2,L3,… 直到输出层 Lnl 的激活值
(2)对于第 nl 层(输出层)的每个输出单元 i ,我们根据以下公式计算残差:
(3)对
l=nl−1,nl−2,nl−3,…,2
的各个层,第
l
层的第
以上逐次从后向前求导的过程即为“反向传导”的本意所在
(4)计算我们需要的偏导数,计算方法如下:
反向传播是批量梯度下降中的重要一步,上述公式的具体推导可以看这里 。
现在给出批量梯度下降中的一次完整迭代:
(1)对于所有
l
,令
(2)对于 i=1 到 m ,
①使用反向传播算法计算
②计算 ΔW(l):=ΔW(l)+∇W(l)J(W,b;x,y)
③计算 Δb(l):=Δb(l)+∇b(l)J(W,b;x,y)
(3)更新权重参数:
现在,我们可以重复梯度下降法的迭代步骤来减小代价函数 J(W,b) 的值,进而求解我们的神经网络。求解结束以后就可以用来预测数据了。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









