






一、爬虫代码:
from bs4 import BeautifulSoup #导入相关库函数
import requests
import time
for page in range(14,33): #按照鬼吹灯文章网址来构建,从而爬取1到15章文章题目
url=f'http://www.biquge5200.cc/61_61284/1417187{page}.html' #方式一构建url
#进入网页观察,构建headers
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.125 Safari/537.36',
'Host': 'www.222biquge.com',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Cookie': 'ckAC=1; Hm_lvt_e1880e6cb1c4b425fe63ef614765e9ec=1694943134,1695103196; width=85%25; Hm_lpvt_e1880e6cb1c4b425fe63ef614765e9ec=1695104708; __gads=ID=fdfbb2c2fc6d8266-222da8e5e3e3009f:T=1695104707:RT=1695104707:S=ALNI_MbBKmyOiE0rr-z9yI5R0SE_YUe2pQ; __gpi=UID=00000c4b8769dfe5:T=1695104707:RT=1695104707:S=ALNI_Makuto0k-PH61jsK4RcY1DN83cXng',
}
#进行数据抓取操作
try:
response=requests.get(url=url,headers=headers)
#print(response.text) #观察提取的响应体数据
soup=BeautifulSoup(response.text,'lxml')
titles=soup.select('.bookname>h1') #获取到文章题目标签对象
tuijians=soup.select('.bookname>.lm>a') #获取到其他小说推荐对象
for title,tuijian in zip(titles,tuijians): #构建字典,键值对形式
data={
'title':title.get_text().strip(), #获取到文章题目
'tuijian':tuijian.get_text().strip() #获取到其他小说推荐
}
# print(title.get_text().strip(),tuijian.get_text().strip())
print(data)
except all:
print('跳过此页')
#样例注释:
"""
'title':title.get_text().strip(),
'tuijian':tuijian.get_text().strip()
得到
{'title': '第一章?旧土', 'tuijian': '我有一剑'}
"""代码结果:

二、网页分析+代码构建思路
网页链接:http://www.biquge5200.cc


根据上图所示分别进入每一章的url,并观察urls:
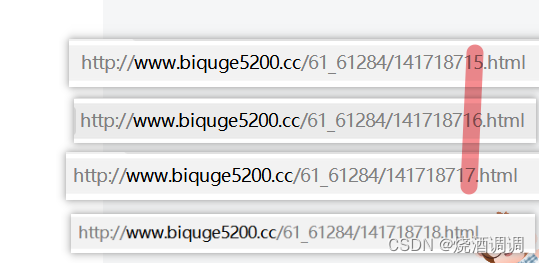
我们发现只有这里数字决定着不同的章节,所以准备构建循环来,提取每一章节的标题。
三、知识点
(一)构建urls
#方式一:
for page in range(14, 33): # 按照鬼吹灯文章网址来构建,从而爬取1到15章文章题目
url = f'http://www.biquge5200.cc/61_61284/1417187{page}.html'
#然后根据url进行访问
#response=requests.get(url=url)
#print(response.text)
#方式二:这种写法后面比较常用
urls = ['http://www.biquge5200.cc/61_61284/1417187{}.html'.format(str(page))for page in range(14,33)]
for url in urls:
print(url)(二)try和except处理异常
#处理了整数除以0所报出的异常
try:
for i in range(0,30):
result=5//i
except ZeroDivisionError:
pass(三)zip函数
Python 的 zip() 函数创建了一个迭代器,它将聚合来自两个或多个可迭代对象的元素
list1=[1,2,3,4]
list2=['a','b','c','d']
for a,b in zip(list1,list2): #创建迭代器,a取值于list1,b取值于list2
print(a,b)(四)CSS相关语法
titles=soup.select('.bookname>h1')
#根据class标签为bookname提取,接着提取所有后代标签h1
tuijians=soup.select('.bookname>.lm>a')
#根据class标签为bookname提取,接着提取class标签为lm标签,再提取所有后代标签a
CSS语法虽然简单,但对于复杂的html标签,就显得比较乏力,建议掌握Xpath语法,html标签就迎刃而解了。
















 1035
1035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











