






最近也是遨游在《流畅的python》这本书中,也是遇到了比较新奇点的知识:
序列拆包:
1.普通的拆包
2.使用*进行拆包
3.函数中使用拆包方法
4.嵌套拆包
序列模式匹配:
实例(1----4)
总之,小编吸收知识效率比较慢,总结了学习一小时的小知识点,供各位uu饭后消化。
PS:以下代码建议使用jupyter notebook或者是ipython下运行
序列拆包
1、普通序列拆包
#普通的拆包
#通过该函数获取商和余数
divmod(20,8)2、使用*进行拆包
#拆包时添加*,利用的是拆包
t=(20,8)
divmod(*t)
quotient,remainder=divmod(*t)
print(quotient,remainder)#使用*获取余下的项
a,b,*rest=range(10)
print(a)
print(b)
print(rest)
"""
0
1
[2, 3, 4, 5, 6, 7, 8, 9]
"""#实例
a,*body,c,d=range(5)
a,body,c,d
3、在函数中调用拆包方法
这个函数拆包方法,值得细品
#可以看见*[1,2]进行拆包,*range(4,7)也进行拆包
def fun(a,b,c,d,*rest):
return a,b,c,d,rest
fun(*[1,2],3,*range(4,7))
"""
(1, 2, 3, 4, (5, 6))
"""4、补充点拆包样例

5、嵌套拆包
知识点: 虚拟变量 字符串格式化
格式:使用main()方法和if __name__=='__main__':的使用让主函数更简洁
介绍:这里创建列表元组,表示地区名,国家,xx,(经度,纬度)
使用普通嵌套拆包方法
"""
里面使用了虚拟变量_
使用了字符串格式化
"""
metro_areas=[
('Tokyo','JP',36.933,(35.689722,139.691667)),
('Delhi NCR','IN',21.935,(28.613889,77.208809)),
('Mexico City','MX',20.142,(19.433333,-99.133333)),
('New York-Newark','US',20.104,(40.808611,-74.020386)),
('Sao Paulo','BR',19.649,(-23.547778,-46.635833))
]
#开始了高端写法
def main():
#保持空格15格,
print(f'{"":15} | {"latitude":>9} | {"longitude":>9}')
#虚拟变量
for name,_,_,(lat,lon) in metro_areas:
#{">9"}是格式化字符串的一部分,它告诉Python在输出时右对齐,并且占据至少9个字符的宽度。
print(f'{name:15} | {lat:9.4f} | {lon:9.4f}')
if __name__=='__main__':
main()
序列匹配:
上面使用普通的嵌套拆包方法,已经可以解决一些常见的需求,但是这本书的作者他要展示自己python高端的代码能力,在python3.10版本后,引入了新的概念,序列匹配,match 和 case的使用。让原本要实现if else elif等等复杂语句,变得简单。
"""以下代码极度高能"""
"""
简单点说,就是构建了一个处理命令集类,你输入的message,拿第一条来说,
如果你的解包了的参数,符合第一个参数是字符串'BEEPER',且剩下的解包参数能匹配到frequecy和times中,就执行第一条指令,以此类推
"""
def handle_command(self,message):
match message:
case ['BEEPER',frequency,times]:
self.beep(times,frequency)
case ['NECK',angle]:
self.rotate_neck(angle)
case ['LED',ident,intensity]:
self.leds[ident].set_brightness(ident,intensity)
case ['LED',ident,red,green,blue]:
self.leds[ident].set_color(ident,red,green,blue)
case _:
raise InvalidCommand(message)
#chatGPT给出的解释
"""
这段代码是一个函数 handle_command,它接收一个 message 参数,并根据消息的内容执行相应的操作。让我们一步步解释:
match message:: 这是 Python 3.10 中的新特性,使用模式匹配来匹配消息的内容。
case ['BEEPER', frequency, times]:: 如果消息是以 ['BEEPER', frequency, times] 开头的列表,则执行 self.beep(times, frequency),这里似乎是用于发出蜂鸣声的命令。
case ['NECK', angle]:: 如果消息是以 ['NECK', angle] 开头的列表,则执行 self.rotate_neck(angle),这似乎是用于控制一个设备的颈部旋转。
case ['LED', ident, intensity]:: 如果消息是以 ['LED', ident, intensity] 开头的列表,则执行 self.leds[ident].set_brightness(ident, intensity),这是用于设置LED亮度的命令。
case ['LED', ident, red, green, blue]:: 如果消息是以 ['LED', ident, red, green, blue] 开头的列表,则执行 self.leds[ident].set_color(ident, red, green, blue),这是用于设置LED颜色的命令。
case _:: 如果消息不匹配以上任何情况,则抛出 InvalidCommand(message) 异常,表示命令无效。
这段代码看起来是用于处理从某个设备接收到的命令,根据命令的不同调用不同的方法来执行相应的操作,例如发出蜂鸣声、旋转颈部或者控制LED。
"""1、实例1(普通)
#python 3.10以上的版本
metro_areas=[
('Tokyo','JP',36.933,(35.689722,139.691667)),
('Delhi NCR','IN',21.935,(28.613889,77.208809)),
('Mexico City','MX',20.142,(19.433333,-99.133333)),
('New York-Newark','US',20.104,(40.808611,-74.020386)),
('Sao Paulo','BR',19.649,(-23.547778,-46.635833))
]
def main():
print(f'{"":15} | {"latitude":>9} | {"longitude":>9}')
for record in metro_areas:
match record:
#第一部分是匹配模式,第二部分是if指定的判断语句
#一般模式使用列表,嵌套的使用元组
case [name,_,_,(lat,lon)] if lon<=0:
print(f'{name:15} | {lat:9.4f} | {lon:9.4f}')
if __name__=='__main__':
main()2、实例2(使用as命名)
#模式中任何一部分都可以使用as方法命名
metro_areas=[
('Tokyo','JP',36.933,(35.689722,139.691667)),
('Delhi NCR','IN',21.935,(28.613889,77.208809)),
('Mexico City','MX',20.142,(19.433333,-99.133333)),
('New York-Newark','US',20.104,(40.808611,-74.020386)),
('Sao Paulo','BR',19.649,(-23.547778,-46.635833))
]
def main():
print(f'{"":15} | {"latitude":>9} | {"longitude":>9}')
for record in metro_areas:
match record:
#模式中任何一部分都可以使用as方法命名
case [name,_,_,(lat,lon) as local] if local[1]<=0:
print(f'{name:15} | {local[0]:9.4f} | {local[1]:9.4f}')
if __name__=='__main__':
main()3、实例3(添加类型信息)
#添加类型的信息可以让模式更加具体
#case[str(name),_,_,(float(lat),float(lon))]
"""看起来像是类型转化,实际上是case运行时对于这种数据的相关检测"""
#而且如果不匹配,它不会报错,反而直接忽略本次判断逻辑
metro_areas=[
('Tokyo','JP',36.933,(35.689722,139.691667)),
('Delhi NCR','IN',21.935,(28.613889,77.208809)),
('Mexico City','MX',20.142,(19.433333,-99.133333)),
('New York-Newark','US',20.104,(40.808611,-74.020386)),
('Sao Paulo','BR',19.649,(-23.547778,-46.635833))
]
def main():
print(f'{"":15} | {"latitude":>9} | {"longitude":>9}')
for record in metro_areas:
match record:
case [str(name),_,_,(float(lat),float(lon)) as local] if lon<=0:
print(f'{name:15} | {lat:9.4f} | {lon:9.4f}')
if __name__=='__main__':
main()
4、实例4(使用*优化你的拆包)
metro_areas=[
('Tokyo','JP',36.933,(35.689722,139.691667)),
('Delhi NCR','IN',21.935,(28.613889,77.208809)),
('Mexico City','MX',20.142,(19.433333,-99.133333)),
('New York-Newark','US',20.104,(40.808611,-74.020386)),
('Sao Paulo','BR',19.649,(-23.547778,-46.635833))
]
def main():
print(f'{"":15} | {"latitude":>9} | {"longitude":>9}')
for record in metro_areas:
match record:
#使用*优化你的代码
case [str(name),*_,(float(lat),float(lon)) as local] if lon<=0:
print(f'{name:15} | {lat:9.4f} | {lon:9.4f}')
if __name__=='__main__':
main()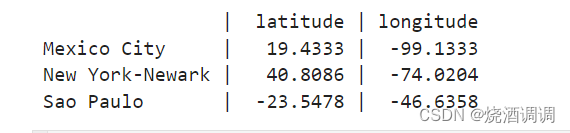
5、注意事项
"""使用match和case匹配时,不能使用str,bytes,bytearray对象,"""
#同数字一样876,不能被拆分为数字列表,str,bytes,bytearray都被认为是原子值
"""
解决方法:
match tuple(phone):
case ['1',*rest] #北美洲地区
case ['2',*rest] #非洲地区
case ['3' | '4',*rest] #欧洲地区"""
#ilst,tuple,range,memoryview, array,array,collection.deque可以与序列模式兼容
创作到这里,小编只想说今天下班下班,关于序列匹配书中还有个案例:使用序列匹配写出一个解释器,这个嘛,后续分享。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











