







commonJS相关:
(1)在commonJS规范中,require,exports,module,__filename,__dirname都是通过动态编译后添加到模块的头部的,这样就不存在全局变量污染的问题
但是他们传入的require,exports,module都是一个空对象。而且必须弄清楚一点:exports是一个对象,如果重新赋值,那么不会反映到外面,但是module.exports
不一样,其只会把exports收集到的属性,方法全部作为一个属性放在module.exports中,相当于为module.exports添加属性,而不是重新赋值,因此会反映到外面
(2)最终返回的是module.exports而不是我们的exports,Module.exports才是真正的接口,exports是一个辅助方法
(3)所有exports收集到的方法全部给了Module.exports,但是前提是后者没有任何属性和方法,否则忽略exports收集到的属性
(4)如果想要自己的模块为某一种实例,可以用module.exports,而不是给exports赋值,因为后者如果直接赋值为一个函数那么压根就不会反应到外面环境(除非设置为exports属性)
(5)nodejs中分为模块作用域和全局作用域,在node.js中:
module.exports=this=exports
//传入的exports对象,默认是{}
console.log(exports);
//往a模块里面和b模块里面都添加了module,exports,require,__dirname,__filename
//但是在a.js中被重新赋值了,所以这里的传入的exports={}现在还是空对象!
console.log(require('./a'));
console.log(require('./b'));websocket协议
(1)websocket客户端基于事件的编程模型与Node中自定义事件相差无几;websocket实现了客户端和服务端的长连接,而Node事件驱动的方式十分擅长于大量的客户端保持高并发连接。
(2)客户端和服务器端只会建立一个TCP连接,可以使用更少的连接。
(3)websockt可以推送数据到客户端,远远比HTTP请求响应模式更加灵活和高效
(4)有更加轻量级的协议头,减少数据传入量
在websocket之前,网页客户端于服务器端通信最高效的方式是使用Comet技术,实现Comet技术的细节是采用长轮询或者iframe流。长轮询的原理是客户端向服务器端发送请求,
服务器只在超时或者有数据响应时断开连接,客户端在收到数据后或者超时后重新发送请求。这个请求方式拖着长长的尾巴,所以称为Comet。在有了Websocket的方式后,网页客户端
只要一个TCP连接就可以完成双向通信,在客户端和服务器频繁通信的时候【无需频繁断开连接或者重新请求】,连接可以做到高效。
注意:相比于HTTP,websocket更加接近于传输层的协议,他没有在http的基础上模拟服务端的推送,而是在TCP上定义的独立的协议。让人困惑的地方在于握手阶段要通过http;websocket协议在
链接的时候会发送一个sec-websocket-key用于安全校验
{
connection:upgrade
upgrade:websocket
sec-websocket-key:ddasfa//随机生成的Base64编码的字符串,服务器收到后和一个新字符串'1588888'连接,然后进行sha1算法,再进行base64编码返回给客户端
sec-websocket-protocol:chat,superchat//子协议和版本号
sec-websocket-version:13
} {
http/1.1 101 switching protocals//更新应用层协议为websocket协议
upgrade:websocket
connection:upgrade
sec-websocket-accept://基于sec-websocket-key计算到的字符串,用于客户端进行验证
sec-websocket-protocol:chat//chat表示选中的协议
}总之:一个推送轻量级协议头
附加题:node中的多进程
(1)在master-worker模式中,要实现主进程管理和调度工作进程的功能,需要主进程和工作进程之间的通信。对于childe_procse方式,创建好子进程,然后和父进程通信是十分容易的。H5提供了我们的webworker的api,这个api允许创建工作线程并且在后台运行,使的一些阻塞严重的计算不影响主线程上的UI渲染。主进程和工作进程之间通过onmessage和postMessage来通信。[通过消息传递内容而不是共享或直接操作相关资源],这是较为轻量级和无依赖的做法。
(2)node中实现ipc通道的是管道,在node中管道是个抽象层面的称呼,具体细节由libuv提供,在window中通过命名管道来实现,*nix系统采用unix domain socket实现,表示在应用层上的进程通信只是简单的message事件和send方法。
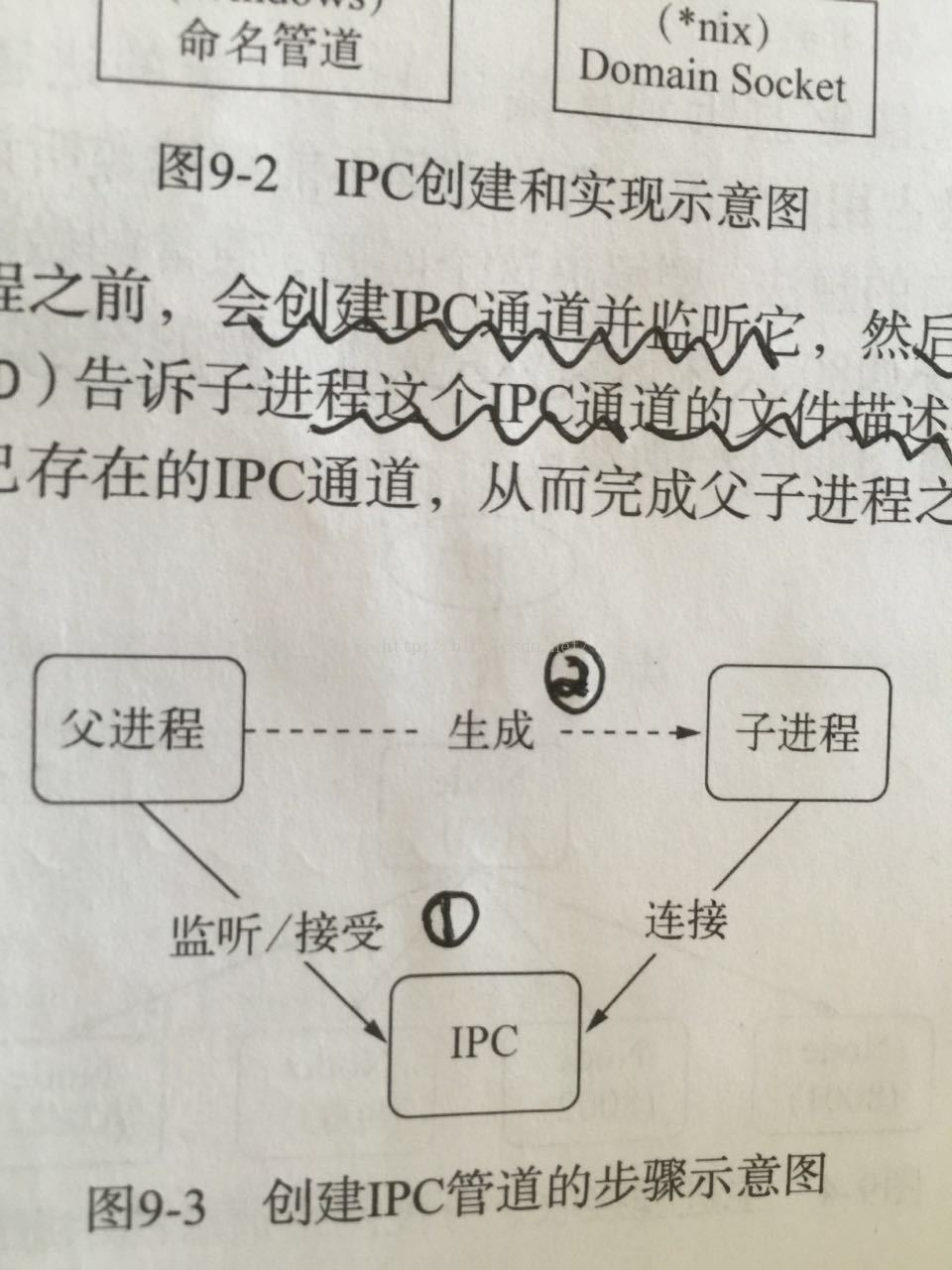
(3)父进程在实际创建子进程的之前,会创建ipc通道并监听它,然后才真正创建出子进程,并通过环境变量 node_channel_fd告诉子进程这个ipc通道的文件描述符。子进程在启动的过程中通过文件描述符去连接这个已经存在 的ipc通道,然后完成父子进程之间的连接
(4)ipc通道时通过命名管道或domain socket创建的,他们和网络socket行为比较类似,属于双向通信,不同的是他们在系统内核中就完成了进程间的通信,而不用实际的网络层,非常高效。在node中ipc通道被抽象为stream对象,在调用send时候发送数据,接受数据的时候通过message事件(类似于data)触发给应用层。
(5)句柄传递,每个进程只能监听一个端口号。但是可以让主进程监听主端口号,主进程对外监听所有的网络请求,再将这些请求分别代理到不同的端口的进程上。这种方式可以解决端口不能重复监听的问题,甚至可以在代理进程上作适当的负载均衡,使的每一个子进程能够较为均衡的执行任务。由于进程每接收到一个连接将会用掉一个文件描述符,因此代理方案中客户端连接到代理进程,代理进程连接到工作进程的过程会用掉两个文件描述符,操作系统的文件描述符的数量是有限的,代理方案会浪费掉一倍数量的文件描述符的做法影响了系统的扩展能力。
(6)上面的这种方式我们采用进程之间发送句柄的功能来解决。send方法除了能通过ipc发送数据外,还能发送句柄 send(message,[messageHander]),句柄是一种可以用来标识资源的引用,他的内部包含了指向对象的文件描述符。比如句柄可以用来标识一个服务器端的soccet对象,一个客户端的socket对象,一个udp套接字,一个管道。为了解决前面代理方案的不足,使的主进程接受到socket请求后,将这个socket直接发送给工作进程而不是重新和工作进程之间建立新的socket连接来传送数据。
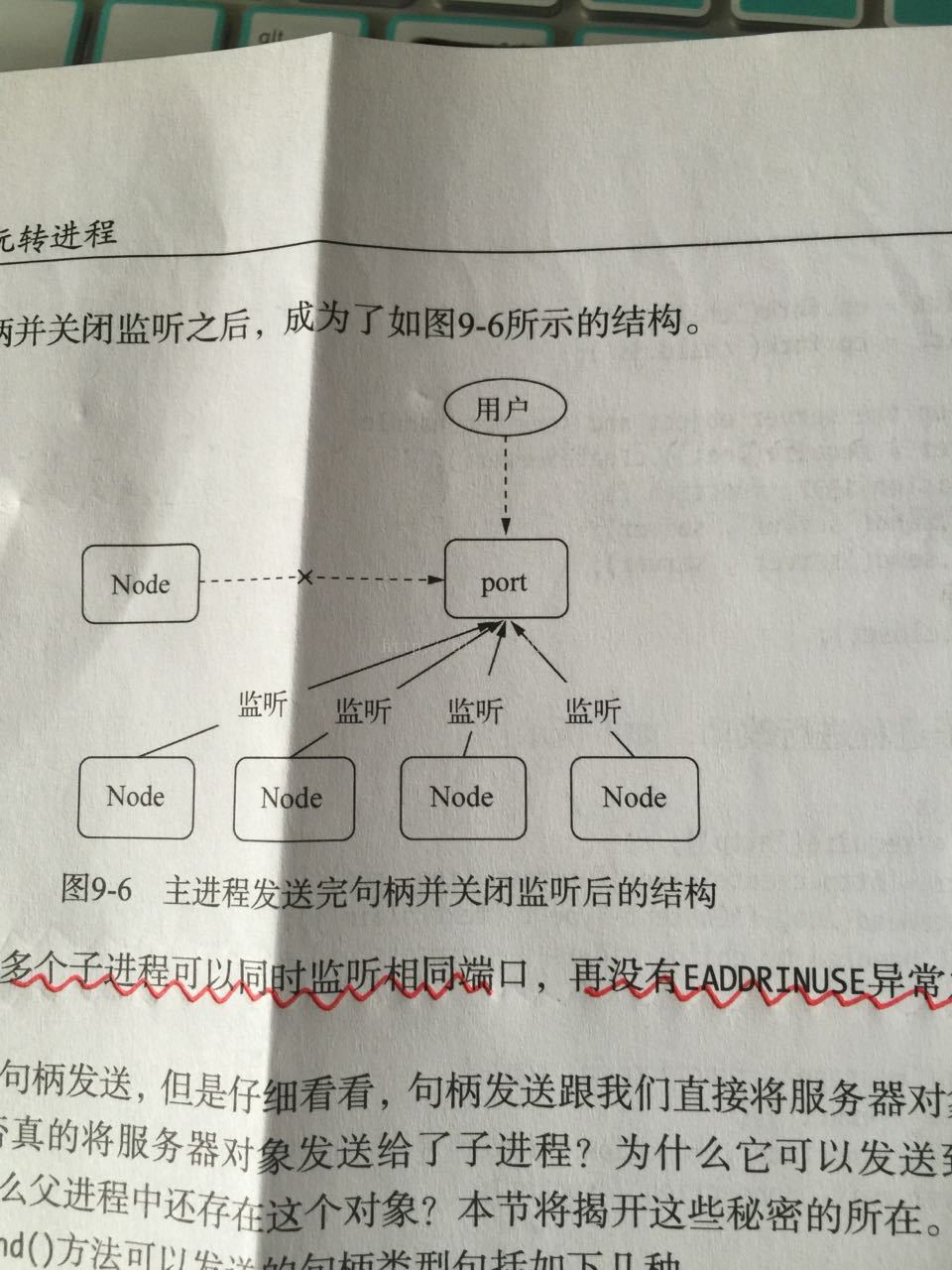
(7)主进程将服务器句柄传送给子进程之后就可以关掉服务器的监听了,多个子进程可以同时监听一个端口号,而不会出现重复监听的异常。
(8)send方法再将消息发送到ipc管道之前,将消息封装成两个对象,一个参数是handler,另一个是message,message参数如下:
<span style="font-family:Arial;"> {
cmd:'NODE_HANDLE',
type:'net.Server',
msg:message
}</span>
注意:我们启动独立的进程的时候,tcp服务器端的socket套接字的文件描述符并不相同(相当于启动了多个server),导致监听相同的端口号会抛出异常。Node底层对每一个端口监听都设置了SO_REUSEADDR选项,这个选项的含义是[不同进程可以就相同的网卡和端口进行监听],这个服务器套接字可以被不同的进程复用。由于独立的启动的进程互相之间并不知道文件描述符,所以监听相同端口号就会失败,但是对于send发送的句柄还原出来的服务而言,他们的文件描述符是相同的,所以监听相同的端口号不会引起异常。多个应用监听相同端口号时候,文件描述符同一时间只能被某个进程所用,换言之就是网络请求向服务端发送时候,只有一个幸运的进程能够抢到连接,也就是说只有它能为这个请求服务。
那么node单线程中是如何保证我们的健壮性的?
进程事件:
error,exit,close,disconnect等等这些进程事件
自动重启:
我们可以在主进程上加入一些子进程的管理机制,比如重新启动一个工作进程来继续服务。在实际业务中可能有隐藏的bug导致工作进程退出,这时候我们的工作进程应该停止接受新的连接,当所有连接都断开的时候退出进程,主进程在监听到exit事件后将会启动新的服务,以此保证集群中总是有进程为用户服务的!
自杀信号:
上面的方式必须等待所有的连接断开后进程才退出,在极端情况下,所有的工作进程都停止接受新的连接,全部等待退出状态。但在等到进程完全退出才重启的过程中,所有新来的请求都没法处理,这样会丢失大部分请求。因此,不能等到工作进程退出后才重启新的工作进程。当然也不能暴力退出进程,因为这样会导致已经连接的用户直接断开。于是我们在退出的流程中增加一个自杀信号然后才停止接受新的信号,工作进程在得知要退出的时候,向主进程发送一个自杀信号,然后再停止接受新的连接,当所有连接断开后才退出。主进程在接受到自杀信号后,立即建立新的工作进程服务
<span style="font-family:Arial;">process.on('uncaughtException',function(err){
process.send({act:'suicide'});
worker.close(function(){
process.exit(1);//所有连接断开后退出进程
});
})</span>工作进程不能无限制的重启,如果重启的过程中就发生了错误或者启动后接到连接就收到错误会导致工作进程被频繁重启,这种频繁重启不属于我们捕获未知异常的情况,因为这种短时间内频繁重启已经不符合预期的设置,很有可能是程序编写错误。因此,如果在指定的时间内触发了多次重启那么我们应该触发giveup事件,告知放弃重启工作进程这个事件。giveup表示没有任何工作进程可用,因此要添加重要日志
负载均衡:
node默认是操作系统抢占式策略,也就是一堆工作进程中,闲着的进程对到来的请求进程争抢,谁抢到谁服务。但是对于node来说,需要分清的他的繁忙度是由cpu,i/o两个部分来构成的,影响抢占的是cpu繁忙度。对于不同的业务,可能存在io繁忙,而cpu较为空闲,可能造成某些进程能抢到更多,形成负载不均衡。node后面采用了round-robin方式,让主进程接受连接,然后分发给工作进程。注意:node进程中不允许存放太多的数据,会导致垃圾回收的负担,进而影响性能。同时node也不允许在多个进程之间共享数据。但是在实际中可能需要共享数据,如配置数据,这时候可以通过第三方存储如数据库,然后轮训的方式;在node0.8后提出了cluseter模块,可以解决多核CPU的问题。同时也提供了叫完善的API
总之:‘事件重启自杀均衡’
附加题1:数组栈方法
shift:移除第一项,并把结果返回,length-1
unshift:在数组前端添加一个项目
push:队列后面添加一个元素
pop:从队列后面取出一个元素
队列方法:push+shift
栈方法:push+pop
反向队列:unshift+pop//也就是队列头部添加,然后在队列末尾移除
我们实现函数节流:
function timedProcessArray(items,process,callback){
//@items是要遍历的数组,@process每一个数组元素要执行的函数,@callback是执行后的回调
var todo=items.concat();
//获取一个副本
setTimeout(function(){
var start=+new Date();
do{
process(todo.shift());
}while(todo.length>0&&(+new Date()-start)<50);
//如果上面执行了50ms那么我们就会退出了
if(todo.length>0){
setTimeout(arguments.callee,25);
}else{
//回调了
callback(items);
}
},25)
}
function throttle(method,context){
clearTimeout(method.timeId);
method.timeId=setTimeout(function(){
method.call(context);
},100)
//如果在100ms内有多次resize那么是不会执行method的
}
function resizeDiv(){
var idv=document.getElementById('myDiv');
div.style.height=div.offsetHeight+'px';
}
window.οnresize=function(){
throttle(resizeDiv);
}附加题2:排版引擎和js引擎

附加题3:
IE推出了focusin/focusout而Opera退出了DOMFocusIn/DOMFocusout以解决focus/blur冒泡问题
mouseenter/mouseleave不冒泡,而且在移动到后代元素上面也不会触发;mouseout/mouseover和前者相反
总结:tagName只能用在元素节点上,而nodeName可以用在任何节点上,可以说nodeName涵盖了tagName,并且具有更多的功能,因此建议总是使用nodeName。
附加题4:webpack和gulp的区别是什么?
gulp的作用:1.构建工具;2.自动化;3.提高效率用。Gulp / Grunt 是一种工具,能够优化前端工作流程。比如自动刷新页面、combo、压缩css、js、编译less等等。简单来说,就是使用Gulp/Grunt,然后配置你需要的插件,就可以把以前需要手工做的事情让它帮你做了。
webpack的作用: 1.打包工具;2.模块化识别;3.编译模块代码方案用。说到 browserify / webpack ,那还要说到 seajs / requirejs 。这四个都是JS模块化的方案。其中seajs / require 是一种类型,browserify / webpack 是另一种类型。[当然,也有相似的功能,比如合并,区分,但各有各的优势]。总之:‘构自效,包识编(识编都是模块)’。
seajs / require : 是一种在线"编译" 模块的方案,相当于在页面上加载一个 CMD/AMD 解释器。这样浏览器就认识了 define、exports、module 这些东西。也就实现了模块化。
browserify / webpack : 是一个预编译模块的方案,相比于上面 ,这个方案更加智能。这里以webpack为例。首先,它是预编译的,不需要在浏览器中加载解释器。另外,你在本地直接写JS,不管是 AMD / CMD / ES6 风格的模块化,它都能认识,并且编译成浏览器认识的JS。这样就知道,Gulp是一个工具,而webpack等等是模块化方案。Gulp也可以配置seajs、requirejs甚至webpack的插件。 [置顶] Gulp和webpack的区别,是一种工具吗?为什么很多人喜欢gulp+webpack,而不直接使用webpack?
附加题5:gulp和grunt的区别?
(1)grunt更加基于配置(config,options,task),而gulp更多基于编码.
grunt.initConfig({
pkg: grunt.file.readJSON('package.json'),
clean: {
all: ['dest/*'],
unImg: ["dest/*", "!dest/images"]
},
// 复制文件
copy: {
main: {
files: [
{expand: true, src: ['index.html', 'favicon.ico'], dest: 'dest'}
]
}
},
useminPrepare:{
html: 'index.html',
options: {//options
root: 'threeKingdoms_xq',
dest: 'dest'
}
}
//Task
grunt.loadNpmTasks('grunt-usemin');
grunt.registerTask('g-copy', ['copy']);基于前面的task的中间文件来完成。
(3) Gulp的每个插件只完成一个功能,这也是Unix的设计原则之一,各个功能通过流进行整合并完成复杂的任务。
例如:Grunt的imagemin插件不仅压缩图片,同时还包括缓存功能。他表示,在Gulp中,缓存是另一个插件,
可以被别的插件使用,这样就促进了插件的可重用性
(4)易学 Gulp的核心API只有5个,掌握了5个API就学会了Gulp,之后便可以通过管道流组合自己想要的任务。
gulp有src,dest,pipe,target,watch
前端自动化:谈谈grunt和gulp的区别 gulp教程之gulp中文API 为什么很多人喜欢gulp+webpack,而不直接使用webpack? 前端轮子们: gulp 和 webpack 是不是有功能上的 overlap
gulp 和 webpack 的区别: 在 webpack 里,你只需要 require 就行了,依赖关系 webpack 帮你处理。而在 gulp 里,你还是需要把所有的 js 或者其他依赖文件用 gulp.src 弄起来。
一个例子,webpack没有雪碧图功能,可能还有其他,但是这是我遇到的,需要配合gulp完成的。
附加题5:em的计算是怎么样的?
相对的计算必然会一个参考物,那么这里相对所指的是相对于元素父元素的font-size。比如说:如果在一个<div>设置字体大小为“16px”,此时这个<div>的后代元素教程了是将继承他的字体大小,除非重新在其后代元素中进行过显示的设置。此时,如果你将其子元素的字体大小设置为“0.75em”,那么其字体大小计算出来后就相当于“0.75 X 16px = 12px”;
很多前辈在多年的实践中得出一个经验,他们建议我们在<body>中设置一个正文文本所需的字体大小,或者设置为“10px”,相当于(“0.625em或62.5%”),这样为了方便其子元素计算。这两种都是可取的。但是我们都知道,<body>的默认字体是“16px”,同时我们也很清楚了,我们改变了他的默认值,要让弹性布局不被打破,就需要重新进行计算,重新进行调整。所以完美的设置是:
body {font-size:1em;}
可是在那个没人爱的IE底下,“em”会有一个问题存在。调整字体大小的时候,同样会打破我们的弹性布局,不过还好,有一个方法可以解决:
html {font-size: 100%;}
总结如下:
1、浏览器的默认字体大小是16px
2、如果元素自身没有设置字体大小,那么元素自身上的所有属性值如“boder、width、height、padding、margin、line-height”等值,我们都可以按下面的公式来计算
1 ÷ 父元素的font-size × 需要转换的像素值 = em值
3、这一种千万要慢慢理解,不然很容易与第二点混了。如果元素设置了字体大小,那么字体大小的转换依旧按第二条公式计算,也就是下面的:
1 ÷ 父元素的font-size × 需要转换的像素值 = em值
那么元素设置了字体大小,此元素的其他属性,如“border、width、height、padding、margin、line-height”计算就需要按照下面的公式来计算:
1 ÷ 元素自身的font-size × 需要转换的像素值 = em值
附加题6:背景图和图片的自适应
.bsize1 {
width:400px;
height:200px;
background: url("http://images2015.cnblogs.com/blog/561794/201603/561794-20160310002800647-50077395.jpg") no-repeat;
border:1px solid red;
overflow: hidden;
}
.bsize5 {
background-size: 400px 200px;
}
(1) background-size: 100%;这种类型我们可以知道仅仅是宽度自适应了,但是高度可能还有一部分没有占满,但是图片本身没有压缩变形
(2)background-size:100% 100%;那么图片会在background-size:100%的情况下发生拉伸,也就是图片本身很显然就变形了。其实这时候的100% 100%
和background-size:400px 200px是一样的效果!也就是这里的100%是相对于元素本身的宽度和高度来说的!
(3)如果是contain那么表示把背景图包含进去,但是图片不会压缩变形,也就是图片本身的宽度和高度比是没有发生变化的。但是有可能不能占满整个空间;cover
那么表示背景图片会被拉伸,使得元素按照比例放大后最小的一边都能够把元素包裹起来!
终极法宝:不管如何上面的方式都是不太好的,所以要解决这个问题必须让在不同的屏幕上加载不同的图片,如适配retina屏幕就要加载@2X的图片。但是上下的background-size充其量就是自适应,而不是响应式布局
(4)使用padding-top为背景图占位
<div class="column">
<div class="figure"></div>
</div> .column{
max-width: 1024px;
}
.figure {
padding-top:30.85%; /* 316 / 1024 */
background: url("http://images2015.cnblogs.com/blog/561794/201603/561794-20160310002800647-50077395.jpg") no-repeat;
background-size:cover;//包含元素,元素宽度和高度比值不变
background-position:center;//兼容IE
}(1)width:100%而达到图片自适应的问题,这时候高度会自适应
<div class="bsize-padding">
<img src="http://images2015.cnblogs.com/blog/561794/201603/561794-20160310002800647-50077395.jpg" width="100%"/>
</div><div class="cover-paddingTop">
<img src="http://images2015.cnblogs.com/blog/561794/201603/561794-20160310002800647-50077395.jpg"/>
</div>.cover-paddingTop {
position: relative;
padding-top: 50%;
overflow: hidden;
}
.cover-paddingTop img{
width:100%;
position: absolute;
top:0;
}(3)img的终极方案就是我们所说的根据屏幕的分辨率加载不同的图片,通过JS来控制,防止图片取样模糊。
理解CSS3中的background-size(对响应性图片等比例缩放) 响应式设计怎么让图片自适应? 为克服HTML在构建应用上的不足而设计!
附加题7:懒惰匹配和贪婪匹配的区别
match和exec的区别:
(1)在非全局模式下,match和exec方法一样只是返回第一个匹配字符串和捕获组
(2)全局模式下,exec返回的数组只包含第一个匹配字符串和捕获组的数据,如果多次调用,那么会通过lastIndex不断返回新的结果
match返回所有的匹配的结果,不包含捕获组,捕获组通过$n访问
(3)我们replace却不一样,他虽然会把match数组中所有的结果替换掉,但是他同时会含有每一项的所有的信息,包括捕获组的所有相关信息, 这些信息全部会传入第二个替换函数中!同时,我们要注意,在全局作用下,exec要获取所有的匹配项,唯一的做法就是不断的调用exec函数,否则还是保存第一个匹配项和捕获组的信息!
注意:parseJSP
懒惰匹配和贪婪匹配
(1)?:表示不保存捕获组
(2)\s匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
(3)\S匹配任何可见字符。等价于[^ \f\n\r\t\v]。
(4)\w匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集。
(5)匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。
(6)[^xyz]去除字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”。
(7)[xyz]字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。
(8)(?=pattern)非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(9)(?!pattern)非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。
(10)\b匹配一个单词边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。
var regex1=/[\W\w]+?/;//这个是懒惰匹配,是通过?来控制的;
var regex=/[\W\w]+/;//是非懒惰匹配replace方法:
var s='script language="javascript" type=" text/javascript "';
var f=function($1)
{
return $1.substring(0,1).toUpperCase()+$1.substring(1);
}
//对每一个单词都作用单独处理\b表示单词边界,而且是全局的!
//传入第二个函数的参数顺序是:每次匹配的文本(这里是单词),然后顺次是捕获组的值,然后是匹配字符在下标中的位置
//最后一个参数表示字符串本身!
var a=s.replace(/(\b\w+\b)/g,f);
//打印Script Language="Javascript" Type=" Text/Javascript "
console.log(a); 附加题8:angularJS的一些内容
(1)隔离作用域scope的继承
(2)控制器,视图,数据模型,因为其是一个MVVM的开发框架,在这个框架中模型和视图是双向通信的(双向数据绑定)。
(3)$apply,$digest
当你写下表达式如{{ aModel}}时,AngularJS在幕后会为你在scope模型上设置一个watcher,它用来在数据发生变化的时候更新view。
这里的watcher和你会在AngularJS中设置的watcher是一样的:
$scope.$watch('aModel', function(newValue, oldValue) {
//update the DOM with newValue
}); (1)AngularJS并不直接调用$digest(),而是调用$scope.$apply(), 后者会调用$rootScope.$digest() 。因此, 一轮$digest循环在$rootScope开始,随后会访问到所有的children scope中的watchers 。
(2)现在,假设你将ng-click指令关联到了一个button上,并传入了一个function名到ng-click上。当该button被点击时,AngularJS会将此function包装到一个【wrapping function】中,然后传入到$scope.$apply()。因此,你的function会正常被执行,修改models(如果需要的话),此时一轮$digest循环也会被触发,用来确保view也会被更新。
(3)Note: $scope.$apply()会自动地调用$rootScope.$digest()。$apply()方法有两种形式。第一种会接受一个function作为参数,执行该function【并且触发】一轮$digest循环。第二种会不接受任何参数,只是触发一轮$digest循环。我们马上会看到为什么第一种形式更好。
(4)什么时候手动调用$apply()方法?
如果AngularJS总是将我们的代码wrap到一个function中并传入$apply(),以此来开始一轮$digest循环,那么什么时候才需要我们手动地调用$apply()方法呢?实际上,AngularJS对此有着非常明确的要求,就是它只负责对发生于AngularJS上下文环境中的变更会做出自动地响应(即,在$apply()方法中发生的对于models的更改)。AngularJS的built-in指令就是这样做的,所以任何的model变更都会被反映到view中。但是,如果你在AngularJS上下文之外的任何地方修改了model,那么你就需要通过手动调用$apply()来通知AngularJS。这就像告诉AngularJS,你修改了一些models,希望AngularJS帮你触发watchers来做出正确的响应。
(5)Note:顺便提一下,你应该使用$timeout service来代替setTimeout(),因为前者会帮你调用$apply(),让你不需要手动地调用它。以上的代码使用了$apply()的第二种形式,也就是没有参数的形式。需要记住的是你总是应该使用接受一个function作为参数的$apply()方法。 这是因为当你传入一个function到$apply()中的时候,这个function会被包装到一个try…catch块中,所以一旦有异常发生,该异常会被$exceptionHandler service处理 。
而且,注意在以上的代码中你也可以在修改了model之后手动调用没有参数的$apply()
(6)$digest循环会运行多少次?
当一个$digest循环运行时,watchers会被执行来检查scope中的models是否发生了变化。如果发生了变化,那么相应的listener函数就会被执行。这涉及到一个重要的问题。如果listener函数本身会修改一个scope model呢?AngularJS会怎么处理这种情况?
答案是$digest循环不会只运行一次。在当前的一次循环结束后,它会再执行一次循环用来检查是否有models发生了变化。这就是脏检查(Dirty Checking),它用来处理在listener函数被执行时可能引起的model变化。因此,$digest循环会持续运行直到model不再发生变化,或者$digest循环的次数达到了10次。因此,尽可能地不要在listener函数中修改model。
Note: $digest循环最少也会运行两次,即使在listener函数中并没有改变任何model。正如上面讨论的那样,它会多运行一次来确保models没有变化。

理解Angular中的$apply()以及$digest() 深入理解ng里的scope
附加题9:http1.0和http1.1的区别
(1)为了克服HTTP 1.0的这个缺陷,HTTP 1.1支持持久连接,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。一个包含有许多图像的网页文件的多个请求和应答可以在一个连接中传输,但每个单独的网页文件的请求和应答仍然需要使用各自的连接。
(2)HTTP 1.1还允许客户端不用等待上一次请求结果返回,就可以发出下一次请求,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容,这样也显著地减少了整个下载过程所需要的时间。 HTTP 1.1与HTTP 1.0的比较
附加题10:浏览器缓存的
(1)使用上很简单,但只有部分浏览器可以支持,而且所有缓存代理服务器都不支持,因为代理不解析HTML内容本身。
(2)Expires规定了缓存失效时间(Date为当前时间),而Cache-Control的max-age规定了缓存有效时间(2552s),理论上这两个值计算出的有效时间应该是相同的(上图好像不一致)。Expires是HTTP1.0的东西,而Cache-Control是HTTP1.1的,规定如果max-age和Expires同时存在,前者优先级高于后者
(3)或许你会发送该请求也有If-Modified-Since项,如果两者同时存在,If-None-Match优先,忽略If-Modified-Since。或许你会问为什么它优先?两者功能相似甚至相同,为什么要同时存在?HTTP1.1中ETag的出现主要是为了解决几个Last-Modified比较难解决的问题:
Last-Modified标注的最后修改只能精确到秒级,如果某些文件在1秒钟以内,被修改多次的话,它将不能准确标注文件的修改时间
如果某些文件会被定期生成,但有时内容并没有任何变化(仅仅改变了时间),但Last-Modified却改变了,导致文件没法使用缓存。
附加题11:不同的文档类型
<!--HTML4.01严格模式-->
<!doctype html public "-//w3c//DTD HTML 4.01//EN"
'http://www.w3.org/tr/html4/strict.dtd'>
<!--xhtml 1.0严格模式-->
<!doctype html public '-//w3c//dtd xhtml 1.0 strict//en'
'http://www.w3.org/tr/xhtml/en/html1-strict.dtd'>
<!--html5严格模式-->
<!doctype html>
<!--<u>准标准模式可以通过过渡型和框架集型文档类型来触发</u>,但是标准型和准标准型非常接近,差异几乎可以不计
因此,当人提到准标准模式的时候有可能指任何一种。准标准模式下很多浏览器特性都是符合标准的,但是不竟然
主要区别在于处理图片间隙的时候
-->附加题12:如果防止自己的页面被iframe掉
try{
top.location.hostname;
//这提示我们,只要查看top.location.hostname是否报错就可以了。如果报错了,表明存在跨域,
//就对top对象进行URL重导向;如果不报错,表明不存在跨域(或者未使用框架),就不采取操作。
if (top.location.hostname != window.location.hostname) {
//在chrome中,如果存在跨域那么top.location.hostname也是不报错的,所以用这句话来解决chrome问题
top.location.href =window.location.href;
}
}
catch(e){
top.location.href = window.location.href;
}附加题13:数组去重复的代码
Array.prototype.unique=function(){
var result=[];
var returnVal=[];
for(var j=0;j<this.length;j++){
result[this[j]]=this[j];
}
for(var i=0;i<result.length;i++)
{
if(result[i] in result){
returnVal.push(result[i]);
}
}
return returnVal;
}
//第二种方式去重
Array.prototype.unique1=function(){
this.sort();
var elem=0;
var i=0;
var j=0;
var duplicates=[];
while(elem=this[i++]){
if(elem==this[i]){
//两个相同,duplicates中存储的是当前元素重复的下标数
//而后面的push返回的是当前的duplicates数组中的元素个数
j=duplicates.push(i);
}
}
while(j--){
this.splice(duplicates[j],1);
}
//这里的this必须要返回
return this;
}
console.log([1,2,3,4,2,3,2].unique1());
console.log([1,2,3,4,2,3,2].unique());附加题14:如何解析出url中的参数
function getQueryString() {
var result = {},
queryString = location.search.substring(1),
//获取查询字符串
regex = /([^&=]+)=([^&=]*)/g, m;
//注意这里的正则表达式的书写方式,只是返回第一个匹配字符串和[捕获组],是所有的捕获组
while (m = regex.exec(queryString)) {
result[decodeURIComponent(m[1])]=decodeURIComponent(m[2]);
}
return result;
}
function clone(obj){
if(obj==null||typeof obj!=='object')
return;
if(obj instanceof Date){
var dateString=obj.getTime();
var date=new Date();
date.setTime(dateString);
return date;
}<pre name="code" class="javascript"> //数组类型
if(obj instanceof Array){
var arr=new Array();
for(var i=0;i<obj.length;i++){
if(typeof obj[i]=='object'){
arr[i]=argument.callee(obj[i]);
}else{
arr[i]=obj[i];
}
}
return arr;
}
//首先获取原型的一个副本,然后把实例属性全部封装到这个原型的副本上
function clone(obj){
var copy=Object.create(Object.getPrototypeOf(obj));
//首先获取原型的一个副本
var propNames=Object.getOwnPropertyNames(obj);
propNames.forEach(function(elem,index,arr){
var descriptor=Object.getOwnPropertyDescriptor(obj,elem);
//往这个副本上添加实例属性
Object.defineProperty(copy,elem,descriptor);
});
return copy;
}
function addListener(elem,type,handler){
if(elem.addEventListener){
elem.addEventListener(type,handler,false);
//不让支持捕获
}else if(elem.attachEvent){
elem.attachEvent('on'+type,handler);
}else{
//on方法来完成
elem['on'+type]=handler;
}
}
String.prototype.endWith=function(suffix){
var regex=new RegExp(suffix+'$','i');
//我们的RegExp对象的构造是可以含有变量的,同时是不需要//开头的
return regex.test(this);
}
console.log('qinliang.txt'.endWith('txt'));
function sort(arr){
//外层循环事arr.length-1
for(var i=0;i<arr.length-1;i++){
for(var j=0;j<arr.length-1-i;j++){
if(arr[j]>arr[j+1]){
//前面的元素比后面的元素要大,那么交换
var temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
return arr;
}
console.log(sort([1,2,3,2,1,5,6,32,11,1]));
//选择排序算法
function sort(arr){
var len=arr.length;
var _min=0;//最小元素
var k=0;//最小元素的下标
for(var i=0;i<len;i++){
_min=arr[i];
k=i;
for(var j=i+1;j<len;j++){
if(_min>arr[j]){
//如果后面的元素比前面的还小,那么更新下标和最小值
_min=arr[j];
k=j;
}
}
//这时候已经找出了我们的这一轮循环的最小下标和最小元素
arr[k]=arr[i];
//必须把后面的元素先填上!!!!
arr[i]=_min;
}
return arr;
}
console.log(sort([1,2,4,3,2,1]));附加题20-1:快速排序算法(下面的临界值是arr.length<=1,否则报错)
function quickSort(arr){
if(arr.length<=1)return arr;
var pivotIndex=Math.floor(arr.length/2);//中间下标
var pivot=arr.splice(pivotIndex,1)[0];
//中间数字,不能直接通过arr[pivotIndex],因为这样的话pivot并没有从数组中去掉,所以后面的return语句就存在问题
//同时注意:splice返回的是数组
var left=[],right=[];
for(var i=0;i<arr.length;i++){
if(arr[i]<pivot){
left.push(arr[i]);
}else{
right.push(arr[i]);
}
}
return quickSort(left).concat([pivot],quickSort(right));
}
console.log(quickSort([5,4,6,7,8,9]));附加题21:undefined只有和加号运算符在一起的的时候才会变成字符串,其他情况下如和数字,布尔值加减乘除都会变成NaN。if,while等循环条件中定义的函数不会发生声明提升的过程,所以在函数前面,函数中间,函数后面都无法访问,只是简单的作为条件来判断;给基本类型数据添加属性,不报错,但取值时是undefined
附加题22:单例设计模式
var singleton=(function(){
var instanced;
function init(){
return {
publicMethod:function(){
console.log('public');
},
publicProperty:true
}
}
return {
//如果已经被实例化了就不会实例化了
getInstance:function(){
if(!instanced){
instanced=init();
}
return instanced;
}
}
})();function doAdd(num1,num2){
arguments[1]=10;
console.log(arguments[0]+num2);
}
doAdd(5,1);
//(1)arguments的值永远和命名参数的值保持同步,但是不是说这两个字值保存相同的内存空间,他们的内存空间是独立的,但是值是同步的
//(2)但是,如果只是传入了一个参数那么arguments[1]的设置不会反映到命名参数中,这是因为arguments的长度是由传入的参数个数决定的不是由定义参数的个数决定的,这一点很重要。
//(3)没有传入的参数都是undefined。而且在严格模式下对arguments对象做了限制,重写arguments的值会导致语法错误arguments另外一个内容
var length = 10;
function fn() {
console.log(this.length);
}
var obj = {
length: 5,
method: function(fn) {
fn();
arguments[0]();//arguments={fn:fn,length:2}
//相当于arguments调用方法所以fn中的this就是arguments对象
}
};
obj.method(fn, 1);//打印10,2,因为arguments这时候的长度是2附加题24:闭包的绑定策略
window.οnlοad=function(){
var lists=document.querySelectorAll('li');
for(var i=0;i<lists.length;i++){
var elem=lists[i];
//使用一个自执行的函数来把我们的事件绑定的部分包裹起来
(function(index){
elem.οnclick=function(){
console.log(index);
}
})(i)
}
}
var pet=function(){
this.message='qinliang';
this.shout=function(){
console.log('shout');
}
this.waitAndShout=function(){
var that=this;//保存that,同时也要注意setTimeout中的this
setInterval(that.shout.bind(that),1000);
}
}
var pet=new pet();
pet.waitAndShout();附加题25-1:setInterval执行10次
var pet=function(){
this.counter=1;
this.timeId=0;
this.message='shout';
this.shout=function(){
if(this.counter<=10){
this.counter++;
console.log('shout');
}else{
clearInterval(this.timeId);
}
}
this.bindAndShout=function(){
var context=this;
this.timeId=setInterval(this.shout.bind(context),1000);
//bind返回的是函数
}
}
var pt=new pet();
pt.bindAndShout();附加题26:外部作用域变量优先级小于内部
var a=100;
function fn(a) {
//虽然这时候和外面的函数同名了,但是因为其是外部作用于,因此其优先级要
//远远低于内部的局部变量
console.log(a);
var a = 2;
function a() {}
//而var a=2相当于给a重新赋值了,所以打印2
console.log(a);
}
fn(a);
console.log(a);
//打印function 2 100 //这里的a被提升到window作用域最前面了,相当于window['a']这种方式用于定义变量访问
if('a' in window) {
var a = 10;
//这里也会发生变量类型声明提升
}
console.log(a);
function getTimes(s){
var arr=s.split('');
var obj={};
for(var i=0;i<arr.length;i++){
if(obj[arr[i]]){
obj[arr[i]]++;
}else{
obj[arr[i]]=1;
}
}
return obj;
}
var result=getTimes('aaabbcd');
//{a: 3, b: 2, c: 1, d: 1}
var props=Object.getOwnPropertyNames(result);
var maxValue=0;
props.forEach(function(elem,index,arr){
if(result[elem]>maxValue){
maxValue=result[elem];
}
});
console.log('次数最到='+maxValue);function obj(name){
//第一部分:这下面是填入的代码
if(name){
this.name=name;
return this;
}
}
//第二部分:这里是填入的代码
obj.prototype.name = "name2";
var a = obj("name1");//这里可以添加new和不添加new,如果没有new那么返回的就是window
var b = new obj;
//这里和new obj()是一样的,但是我们这里通过obj构造出来的对象的name却成为了undefined,这是我们不需要的结果!
console.log(a.name);
console.log(b.name);
//apply必须单个指定this,同时第二个参数必须是数组
//打印{name:'qinliang'},12
var a = Function.prototype.apply.call(function(a){
console.log(this);
return a;
}, {name:"qinliang"},[12]);
console.log(a);
//call必须一起指定,而且this和参数全部在一个数组中
//打印Number(0),4
var a = Function.prototype.call.apply(function(a){
console.log(this);
return a;
}, [0,4,3]);
console.log(a);
function compare(value1,value2){
if(value1<value2){
return -1;//因为value1-value2=-1那么表示升序
}else if(value1>value2){
return 1;
}else{
return 0;
}
}
console.log([1,2,3,2,1].sort(compare));
var arr=[1,4,3,2];
var sum=arr.reduce(function(pre,cur,index,arr){
return pre+cur;
},10)
//第二个参数表示累加的基准值,reduceRight的用法也是一样的
console.log(sum);
var a = {n: 1}
var b = a;
a.x = a = {n: 2}
//首先修改a.x得到a={n:1,x:a}=>a={n:1,x:{n:2}}(因为这时候a已经被修改了{a:2})
//然后a保持不变={n:2}
console.log(a);
console.log(b)
// Object {n: 2}
// Object {n: 1, x: {n:2}} 附加题25:如何编写jQuery插件
(function($){
$.fn.extend({
'sayHello':function(str){
console.log(str);
}
})
})(window.jQuery)
//其实也是可以通过jQuery.fn.sayName来编写的
jQuery.extend({
sayHello:function(str){
console.log(str);
}
});
jQuery.sayHello=function(str){
console.log(str);
}附加题26:那些排序算法是稳定的
冒泡;插入;归并;基数(贸然进入归基)。平均速度最快的排序算法是:‘快速排序’
附加题27:Promise对象相关
Promise对象的特点:
(1)对象的状态不受外界的影响。只有异步操作的状态可以决定当前处于哪一种状态,如pending,resolved,rejected
(2)一旦状态改变就不会再次改变,也就是会保持当前所处的状态。就算改变已经发生,你再对promise对象添加回调也会立即执行
缺点:
无法取消Promise,一旦建立就会立即执行,无法中途取消;如果不设置catch回调函数,Promise内部抛出的错误不会反应到外部。【‘影响改变取消catch’】
其他内容相关:
.then方法返回的是一个新的promise实例,注意不是原来的那个Promise实例,then方法是在prototype上面的方法
.catch方法是then(null,rejection)的别名,用于指定错误发生改变时的回调函数
.如果状态已经resolved,那么再次抛出错误是无效的,也就是说在resolve后面抛出的异常,并不会被捕获,等于没有抛出,也就是catch块抓不到这种异常.
如果指定了setTimeout这种形式,如果没有try..catch就会成为未捕获异常,因此此时Promise的函数体已经运行结束,所以这个错误是在Promise体外抛出
catch块抓不到
var promise3=new Promise(function(resolve,reject){
resolve('ok');
setTimeout(function(){
throw new Error('test');
},0);//体外抛出
})
promise3.then(function(val){
console.log(val);
});
promise3.catch(function(err){
console.log('catch');
console.log(err);
}).如果catch块在前面,那么后面的then方法抛出错误那么catch是抓不住的
.all,race(和数组中率先改变状态的promise对象有相同的状态),resolve(将现有对象转化为promise,如果参数不具有then方法,那么返回一个Pormise对象,状态为resolved),
reject(返回一个新的promise对象,状态为rejected)。而且这几个方法都是静态方法!!!!!
.Promise完成后,逐个执行回调,如果检测到返回的对象是新的promise对象,停止执行,然后把当前Defered对象的promise引用修改为新的Promise对象,并将余下的回调转交给他
var promise1=new Promise(function(resolve,reject){
setTimeout(function(){
reject(new Error('fail'));
},3000)
})
//promise2依赖于promise1,也就是说promise2等待着promsie1状态的改变,1s的时候promise1状态还没有改变
//所以promise2一直等待,3s后promise1状态改变,因此promise2状态也改变了,变成reject
var promise2=new Promise(function(resolve,reject){
setTimeout(resolve(promise1),1000);
});
promise2.then(function(result){
console.log(result);
})
promise2.catch(function(err){
console.log(err);
});附加题28:module加载ES6
(1)ES6在语言层面上实现了模块功能,而且实现的非常简单,完全可以用于取代现有的CommonJs,和AMD规范,成为浏览器和服务器通用的模块解决方案。ES6设计思想是尽量静态化,使得编译的时候就能确定模块的依赖关系,以及输入和输出变量。CommonJs和AMD模块都只能在运行的时候确定这些东西。比如,Commonjs模块就是对象,输入时候必须查找对象属性
let {stat,exitss,readFile}=require('fs');//这里的代码的实质就是整体加载fs模块(加载fs所有方法),
//然后在使用时用到3个方法。这种加载叫做“运行时加载” ES6模块不是对象,而是通过exports命令显示指定输出的代码,输入时候也采用静态命令的方式
import {stat,exits,readFile} from 'fs'//从fs模块加载3个方法,其他方法都不加载,这种加载称之为“编译时加载”,也就是说ES6在编译时就能够完成模块编译,
//效率要比commonJS更高(2)不在需要UMD模块格式,将来服务器和浏览器都会原生支持ES6模块格式,目前通过各种库已经做到这一点
(3)将来浏览器的新API可以用模块格式提供,不再需要做成全局变量或者navigator的对象的属性
(4)不再需要对象作为命名空间,未来这些功能都有模块提供
(5)ES6模块加载机制和commonJS模块完全不同,commonjs模块输出的是一个值的拷贝,而ES6输出的是值的引用。ES6在遇到import时候不会去执行模块,只会生成一个动态的【只读】引用,等到真正需要用到时,再到模块中取值。ES6的输入有点像unix系统的‘符号链接’,原始值变化了,输入值也就变化了,因此ES6模块是动态引用,而且不会【缓存】,模块里面的变量绑定其所在的模块
(6)如何避免循环加载问题:
commonJS:require命令第一次加载该脚本就会执行整个脚本,然后在内存中生成一个对象,这个脚本代码在require时候就会全部执行
{
id:'',
exports:{..},//以后需要用到整个模块就在exports属性上取值,即使再次执行require也不会再次执行这个模块,而是到缓存中取值
loaded:true
}ES6:ES6模块是动态引用,遇到模块加载命令import时候不会去执行模块,只是生成一个指向被加载模块的引用,需要开发者自己保证真正能够取到值
ES6加载的变量是动态引用其所在的模块,只要引用存在代码就会执行
严格模式:
。不能使用arguments.caller,arguments.callee,fn.caller,fn.callee,with等不能使用
。禁止this指向全局变量;不能对只读属性赋值,不能删除不可删除的属性等等
其他内容:
。exports必须位于模块顶层即可
。import命令具有提升效果,会提升到整个模块的头部首先执行
。除了指定加载某个输出值,还可以整体加载,也就是使用*指定一个对象,所有输出值都加载在这对象上
。module可以取代import语句,达到整体输入模块的功能
。export default对应的import不要大括号,如果不使用export default,那么import语句要使用大括号
。模块的继承,export * from 'circle'表示在circleplus中把circle暴露出去
。ES6输入的模块变量只是一个‘符号链接’,所以这个变量是只读的,对他进行赋值就会报错,但是可以为obj添加属性,只是不能重新赋值
附加题29: 从按下遥控器到页面做出响应发生了什么?
(1)传感器获取到遥控器的信号
(2)把信号传递给我们的操作系统
(3)操作系统传递给我们的活动容器
(4)活动容器把信号传递给我们的blitz内核(blitz内核其实相当于浏览器的内核)
(5)blitz内核接受到信号,并把信号传递给我们的js代码(如keydown等信号),继而JS代码会执行
注意:我觉得中间还有一个重要的环节,那就是我们的安卓系统,其实通过adb等这种方式都是通过安卓系统来发送广播,然后接受广播的过程。而且遥控器的输入和传统
键盘的输入本质上相差不大,原因在于我们都是通过监听keydown来完成的。
问题1:从输入网址到页面显示经历了那些步骤?
第一步:查找域名的IP地址(浏览器缓存,系统缓存,路由器缓存,ISP的DNS缓存,递归搜索域名从顶级域名开始)
第二步:通过三次握手建立TCP/IP连接
第三步:发送HTTP请求(HTTP头等分析)
第四步:baidu.com到www.baidu.com的永久重定向相应(和搜索引擎重定向排名有关,搜索引擎知道301是什么意思,于是将两者归于同一个名下;用多个地址会导致缓存效果较差)
第五步:跟踪重定向地址发送请求
第六步:服务器处理响应(可能要设置http头);四次放手协议
第七步:浏览器获取到二进制的数据, 转换(Conversion): 浏览器从磁盘或者网络上读取HTML的原始字节,然后根据指定的编码规则转换成单独的字符(比如按UTF-8编码)。标记分解(Tokenizing):浏览器将字符串按照W3C HTML5标准转换成确定的标记,比如<html>、<body>以及其他带尖括号的字符。每个标记都有特定的意义以及一套规则。词法分析(Lexing):分解出来的标记被转换成能定义其属性和规则的对象。DOM 构造: 最终由于HTML标记定义了不同标签的关系(有些标签嵌套在其他标签里面),创建出来的对象被关联到一个树形数据结构。这颗树会反映在原先标签里定义的父子关系,比如HTML对象就是body对象的父对象,body对象又是paragraph对象的父对象等等。(参见谷歌 Web 开发最佳实践手册(4.1.1):创建对象模型)
第八步:发送请求获取在html中其它内容如img/javascript/css等,如果是javascript可能要按顺序逐个下载执行
第九步:浏览器从服务端获取网页后会根据文档的DOCTYPE定义显示网页,如果文档正确定义了DOCTYPE浏览器则会进入标准模式(Standards Mode),否则浏览器会进入怪异模式或混杂模式(Quirks mode)。
第十步:构建DOM树/CSSOM树构建渲染树(这时候对于head,或者display:none等不需要显示的元素不会在渲染树上),然后进行对象尺寸的计算,并且绘制到屏幕上!(DNS预处理,link prefetching,ajax请求等)
绑定事件,事件触发等
问题2:什么是Http协议三次握手过程协议?
第一次握手:主机A发送位码为syn=1,随机产生seq number=1234567的数据包到服务器,主机B由SYN=1知道,A要求建立联机;
第二次握手:主机B收到请求后要确认联机信息,向A发送ack number=(主机A的seq+1),syn=1,ack=1,随机产生seq=7654321的包
第三次握手:主机A收到后检查ack number是否正确,即第一次发送的seq number+1,以及位码ack是否为1,若正确,主机A会再发送ack number=(主机B的seq+1),ack=1,主机B收到后确认seq值与ack=1则连接建立成功。
完成三次握手,主机A与主机B开始传送数据。
为什么建立连接是三次握手,而关闭连接却是四次挥手呢?
这是因为服务端在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。而关闭连接时,当收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,己方也未必全部数据都发送给对方了,所以己方可以立即close,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,因此,己方ACK和FIN一般都会分开发送。
如果采用两次的话,会出现下面这种情况。
比如是A机要连到B机,结果发送的连接信息由于某种原因没有到达B机;于是,A机又发了一次,结果这次B收到了,于是就发信息回来,两机就连接。传完东西后,断开。结果这时候,原先没有到达的连接信息突然又传到了B机,于是B机发信息给A, 然后B机就以为和A连上了,这个时候B机就在等待A传东西过去。
2. 三次握手改成仅需要两次握手,死锁是可能发生
考虑计算机A和B之间的通信,假定B给A发送一个连接请求分组,A收到了这个分组,并发送了确认应答分组。按照两次握手的协定,A认为连接已经成功地建立了,可以开始发送数据分组。可是,B在A的应答分组在传输中被丢失的情况下,将不知道A是否已准备好,不知道A建议什么样的序列号,B甚至怀疑A是否收到自己的连接请求分组。 在这种情况下,B认为连接还未建立成功,将忽略A发来的任何数据分组,只等待连接确认应答分组。而A在发出的分组超时后,重复发送同样的分组。这样就形成了死锁
问题3:跨域有那些方式?
(1)window+name
代理文件和应用页面在同一域下,所以可以相互通信。通过在 iframe 中加载一个资源,该目标页面将设置 frame 的 name 属性。此 name 属性值可被获取到,以访问 Web 服务发送的信息。但 name 属性仅对相同域名的 frame 可访问。这意味着为了访问 name 属性,当远程 Web 服务页面被加载后,必须导航 frame 回到原始域。同源策略依旧防止其他 frame 访问 name 属性。一旦 name 属性获得,销毁 frame 。window.name 的美妙之处:name 值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值(2MB)。通过window.name+iframe实现跨域,在iframe的onload中必须把iframe的location设置为本域名的一个空的页面!(window.name需要代理页面;)
function proxy(url, func){
var isFirst = true,
ifr = document.createElement('iframe'),
//回调事件!
loadFunc = function(){
if(isFirst){
//如果是首次,那么加载iframe成功以后我们需要把iframe的url设置为本域名的一个页面!否则在本域名下获取另外域名的contentwindow是不允许的
ifr.contentWindow.location = 'http://static.cors.com:8080/CORS/cors3/null.html';
isFirst = false;
}else{
//如果已经加载过了a.html,因为上一次已经又把iframe设置了一个新的url,这时候onload后就直接回调了
func(ifr.contentWindow.name);
ifr.contentWindow.close();
document.body.removeChild(ifr);
ifr.src = '';
ifr = null;
}
};
//隐藏框架,并为框架绑定事件onload!
ifr.src = url;
ifr.style.display = 'none';
if(ifr.attachEvent) ifr.attachEvent('onload', loadFunc);
else ifr.onload = loadFunc;
document.body.appendChild(ifr);
}(2)location.hash
ie、chrome的安全机制无法修改parent.location.hash,所以要利用一个主页面域下的代理iframe!也就是说在chrome中和IE中添加一个iframe那么主页面的url后面的hash就会变化,只要添加iframe的域名和iframe指向的域名一致就可以了!(document.hash要代理页面)缺点:所有的数据都暴露在url上,父元素通过setInterval循环查询hash变化
//这个隐藏的iframe修改主页面的hash!
function callBack(){
try {
parent.location.hash = 'somedata';
} catch (e) {
// ie、chrome的安全机制无法修改parent.location.hash,
// 所以要利用一个主页面域下的代理iframe!也就是说在chrome中和IE中
//添加一个iframe那么主页面的url后面的hash就会变化,只要添加iframe的域名和
//iframe指向的域名一致就可以了!
var ifrproxy = document.createElement('iframe');
ifrproxy.style.display = 'none';
ifrproxy.src = 'http://static.cors.com:8080/CORS/cors2/proxy.html#somedata';
document.body.appendChild(ifrproxy);
}
}代理页面的处理逻辑:
//因为parent.parent和自身属于同一个域,所以可以改变其location.hash的值
parent.parent.location.hash = self.location.hash.substring(1);(3)document.domain+iframe
主域名相同才可以利用document.domain+iframe实现跨域。通过修改document的domain属性,我们可以在域和子域或者不同的子域之间通信。同域策略认为域和子域隶属于不同的域,比如www.a.com和sub.a.com是不同的域,这时,我们无法在www.a.com下的页面中调用sub.a.com中定义的JavaScript方法。但是当我们把它们document的domain属性都修改为a.com,浏览器就会认为它们处于同一个域下,那么我们就可以互相调用对方的method来通信了。
(4)postMessage
这就是HTML5提供的XDM,这种方式借助于window.postMessage来完成,通过iframe实现跨域内容的加载,然后向iframe中发送消息! window.postMessage是HTML5定义的一个很新的方法,这个方法可以很方便地跨window通信。由于它是一个很新的方法,所以在很旧和比较旧的浏览器中都无法使用。
postMessage(data,origin)方法接受两个参数
1.data:要传递的数据,html5规范中提到该参数可以是JavaScript的任意基本类型或可复制的对象,然而并不是所有浏览器都做到了这点儿,[部分浏览器只能处理字符串参数],所以我们在传递参数的时候需要使用JSON.stringify()方法对对象参数序列化,在低版本IE中引用json2.js可以实现类似效果。
2.origin:字符串参数,指明目标窗口的源,协议+主机+端口号[+URL],URL会被忽略,所以可以不写,这个参数是为了安全考虑,postMessage()方法只会将message传递给指定窗口,当然如果愿意也可以建参数设置为"*",这样可以传递给任意窗口,如果要指定和当前窗口同源的话设置为"/"。
//主页面发送消息
window.frames[0].postMessage('getcolor','http://lslib.com');//发送消息
//主页面接受消息
window.addEventListener('message',function(e){
var color=e.data;
document.getElementById('color').style.backgroundColor=color;
},false);
//iframe来接受消息
window.addEventListener('message',function(e){
if(e.source!=window.parent) return;
var color=container.style.backgroundColor;
window.parent.postMessage(color,'*');
//iframe发送消息。获取父元素的对象才能调用postMessage
},false);(5)CORS
原理是通过HTTP头和服务器之间进行消息传递! Firefox, Google Chrome等通过XMLHTTPRequest实现,IE8下通过XDomainRequest实现
Access-Control-Allow-Origion, Access-Control-Allow-Method, Access-Control-Allow-Headers, Access-Control-Max-Age。浏览器会发送Access-Control-Request-Method, Access-Control-Request-Headers, Origion等。这时候发送的就是Preflighted请求,用的是Options方法。这个方法首先会发送一个HTTP请求,用于判断当前请求是否合法,如果不合法那么ajax请求就失败了,如果通过了浏览器再发送一个请求读取服务器返回的数据。preflighted请求结束后,会把结果缓存起来,为此付出的代价就是第一个多出一次HTTP请求。如果需要在跨域的时候发送凭证那么就需要用withCredential为true,这时候如果服务器接受就会发送Access-Control-Allow-Credentials来回复。如果服务器没有返回这个头那么不会将返回值给js,于是responseText就是空,status为0,同时onerror调用。(凭证包括:cookie,http认证,客户端SSL等)
Chrome等浏览器:不能使用setRequestHeader设置自定义头部;不能发送和接受cookie;调用getAllResponseHeaders返回空字符串
IE浏览器:只能设置contentType; 不能发送cookie; 不能访问相应头;只支持GET/POST
(6)动态script
(7)websocket
web sockets是一种浏览器的API,它的目标是在一个单独的持久连接上提供全双工、双向通信。(同源策略对web sockets不适用)web sockets原理:在JS创建了web socket之后,会有一个HTTP请求发送到浏览器以发起连接。取得服务器响应后,建立的连接会使用HTTP升级从HTTP协议交换为web sockt协议。缺点:只有在支持web socket协议的服务器上才能正常工作。
(8)JSONP
JSONP包含两部分:回调函数和数据。回调函数是当响应到来时要放在当前页面被调用的函数。数据就是传入回调函数中的json数据,也就是回调函数的参数了。注意:JSONP请求回调的数据必须是json数据,这样客户端才能处理!安全问题(请求代码中可能存在安全隐患);要确定jsonp请求是否失败并不容易
问题4:ajax几种状态和动态script的几种状态?
ajax:unitialized,open,send,receiving,loaded;
动态的script标签:unitialized,loading,loaded,interative,compelete!
问题5:什么是ajax以及ajax的优缺点?
1.什么是AJAX?
AJAX全称为“Asynchronous JavaScript and XML”(异步JavaScript和XML),是一种创建交互式网页应用的网页开发技术。它使用:
使用XHTML+CSS来标准化呈现;
使用XML和XSLT进行数据交换及相关操作;
使用XMLHttpRequest对象与Web服务器进行异步数据通信;
使用Javascript操作Document Object Model进行动态显示及交互;
使用JavaScript绑定和处理所有数据。
2.与传统的web应用比较
传统的Web应用交互由用户触发一个HTTP请求到服务器,服务器对其进行处理后再返回一个新的HTML页到客户端, 每当服务器处理客户端提交的请求时,客户都只能空闲等待,并且哪怕只是一次很小的交互、只需从服务器端得到很简单的一个数据,都要返回一个完整的HTML页,而用户每次都要浪费时间和带宽去重新读取整个页面。这个做法浪费了许多带宽,由于每次应用的交互都需要向服务器发送请求,应用的响应时间就依赖于服务器的响应时间。这导致了用户界面的响应比本地应用慢得多。
与此不同,AJAX应用可以仅向服务器发送并取回必需的数据,它使用SOAP或其它一些基于XML的Web Service接口,并在客户端采用JavaScript处理来自服务器的响应。因为在服务器和浏览器之间交换的数据大量减少,结果我们就能看到响应更快的应用。同时很多的处理工作可以在发出请求的客户端机器上完成,所以Web服务器的处理时间也减少了。
3.AJAX的工作原理
Ajax的工作原理相当于在用户和服务器之间加了—个中间层(AJAX引擎),使用户操作与服务器响应异步化。并不是所有的用户请求都提交给服务器,像—些数据验证和数据处理等都交给Ajax引擎自己来做, 只有确定需要从服务器读取新数据时再由Ajax引擎代为向服务器提交请求。
Ajax其核心有JavaScript、XMLHTTPRequest、DOM对象组成,通过XmlHttpRequest对象来向服务器发异步请求,从服务器获得数据,然后用JavaScript来操作DOM而更新页面。这其中最关键的一步就是从服务器获得请求数据。让我们来了解这几个对象。
(1).XMLHTTPRequest对象
Ajax的一个最大的特点是无需刷新页面便可向服务器传输或读写数据(又称无刷新更新页面),这一特点主要得益于XMLHTTP组件XMLHTTPRequest对象。
XMLHttpRequest 对象方法描述
| 方 法 | 描 述 |
| abort() | 停止当前请求 |
| getAllResponseHeaders() | 把HTTP请求的所有响应首部作为键/值对返回 |
| getResponseHeader("header") | 返回指定首部的串值 |
| open("method","URL",[asyncFlag],["userName"],["password"]) | 建立对服务器的调用。method参数可以是GET、POST或PUT。url参数可以是相对URL或绝对URL。这个方法还包括3个可选的参数,是否异步,用户名,密码 |
| send(content) | 向服务器发送请求 |
| setRequestHeader("header", "value") | 把指定首部设置为所提供的值。在设置任何首部之前必须先调用open()。设置header并和请求一起发送 ('post'方法一定要 ) |
XMLHttpRequest 对象属性描述
| 属 性 | 描 述 |
| onreadystatechange | 状态改变的事件触发器,每个状态改变时都会触发这个事件处理器,通常会调用一个JavaScript函数 |
| readyState | 请求的状态。有5个可取值:0 = 未初始化,1 = 正在加载,2 = 已加载,3 = 交互中,4 = 完成 |
| responseText | 服务器的响应,返回数据的文本。 |
| responseXML | 服务器的响应,返回数据的兼容DOM的XML文档对象 ,这个对象可以解析为一个DOM对象。 |
| responseBody | 服务器返回的主题(非文本格式) |
| responseStream | 服务器返回的数据流 |
| status | 服务器的HTTP状态码(如:404 = "文件末找到" 、200 ="成功" ,等等) |
| statusText | 服务器返回的状态文本信息 ,HTTP状态码的相应文本(OK或Not Found(未找到)等等) |
(2).JavaScript
JavaScript是一在浏览器中大量使用的编程语言。
(3).DOM Document Object Model
DOM是给HTML和XML文件使用的一组API。它提供了文件的结构表述,让你可以改变其中的內容及可见物。其本质是建立网页与Script或程序语言沟通的桥梁。所有WEB开发人员可操作及建立文件的属性、方法及事件都以对象来展现(例如,document就代表“文件本身“这个对像,table对象则代表HTML的表格对象等等)。这些对象可以由当今大多数的浏览器以Script来取用。一个用HTML或XHTML构建的网页也可以看作是一组结构化的数据,这些数据被封在DOM(Document Object Model)中,DOM提供了网页中各个对象的读写的支持。
(4).XML
可扩展的标记语言(Extensible Markup Language)具有一种开放的、可扩展的、可自描述的语言结构,它已经成为网上数据和文档传输的标准,用于其他应用程序交换数据 。
(5).综合
Ajax引擎,实际上是一个比较复杂的JavaScript应用程序,用来处理用户请求,读写服务器和更改DOM内容。JavaScript的Ajax引擎读取信息,并且互动地重写DOM,这使网页能无缝化重构,也就是在页面已经下载完毕后改变页面内容,这是我们一直在通过JavaScript和DOM在广泛使用的方法,但要使网页真正动态起来,不仅要内部的互动,还需要从外部获取数据,在以前,我们是让用户来输入数据并通过DOM来改变网页内容的,但现在,XMLHTTPRequest,可以让我们在不重载页面的情况下读写服务器上的数据,使用户的输入达到最少。
Ajax使WEB中的界面与应用分离(也可以说是数据与呈现分离),而在以前两者是没有清晰的界限的,数据与呈现分离的分离,有利于分工合作、减少非技术人员对页面的修改造成的WEB应用程序错误、提高效率、也更加适用于现在的发布系统。也可以把以前的一些服务器负担的工作转嫁到客户端,利于客户端闲置的处理能力来处理。
4.AJAX的优缺点
(1).AJAX的优点
<1>.无刷新更新数据。
AJAX最大优点就是能在不刷新整个页面的前提下与服务器通信维护数据。这使得Web应用程序更为迅捷地响应用户交互,并避免了在网络上发送那些没有改变的信息,减少用户等待时间,带来非常好的用户体验。
<2>.异步与服务器通信。
AJAX使用异步方式与服务器通信,不需要打断用户的操作,具有更加迅速的响应能力。优化了Browser和Server之间的沟通,减少不必要的数据传输、时间及降低网络上数据流量。
<3>.前端和后端负载平衡。
AJAX可以把以前一些服务器负担的工作转嫁到客户端,利用客户端闲置的能力来处理,减轻服务器和带宽的负担,节约空间和宽带租用成本。并且减轻服务器的负担,AJAX的原则是“按需取数据”,可以最大程度的减少冗余请求和响应对服务器造成的负担,提升站点性能。
<4>.基于标准被广泛支持。
AJAX基于标准化的并被广泛支持的技术,不需要下载浏览器插件或者小程序,但需要客户允许JavaScript在浏览器上执行。随着Ajax的成熟,一些简化Ajax使用方法的程序库也相继问世。同样,也出现了另一种辅助程序设计的技术,为那些不支持JavaScript的用户提供替代功能。
<5>.界面与应用分离。
Ajax使WEB中的界面与应用分离(也可以说是数据与呈现分离),有利于分工合作、减少非技术人员对页面的修改造成的WEB应用程序错误、提高效率、也更加适用于现在的发布系统。
(2).AJAX的缺点
<1>.AJAX干掉了Back和History后退功能,即对浏览器机制的破坏。
在动态更新页面的情况下,用户无法回到前一个页面状态,因为浏览器仅能记忆历史记录中的静态页面。一个被完整读入的页面与一个已经被动态修改过的页面之间的差别非常微妙;用户通常会希望单击后退按钮能够取消他们的前一次操作,但是在Ajax应用程序中,这将无法实现。
后退按钮是一个标准的web站点的重要功能,但是它没法和js进行很好的合作。这是Ajax所带来的一个比较严重的问题,因为用户往往是希望能够通过后退来取消前一次操作的。那么对于这个问题有没有办法?答案是肯定的,用过Gmail的知道,Gmail下面采用的Ajax技术解决了这个问题,在Gmail下面是可以后退的,但是,它也并不能改变Ajax的机制,它只是采用的一个比较笨但是有效的办法,即用户单击后退按钮访问历史记录时,通过创建或使用一个隐藏的IFRAME来重现页面上的变更。(例如,当用户在Google Maps中单击后退时,它在一个隐藏的IFRAME中进行搜索,然后将搜索结果反映到Ajax元素上,以便将应用程序状态恢复到当时的状态。)
但是,虽然说这个问题是可以解决的,但是它所带来的开发成本是非常高的,并与Ajax框架所要求的快速开发是相背离的。这是Ajax所带来的一个非常严重的问题。
一个相关的观点认为,使用动态页面更新使得用户难于将某个特定的状态保存到收藏夹中。该问题的解决方案也已出现,大部分都使用URL片断标识符(通常被称为锚点,即URL中#后面的部分)来保持跟踪,允许用户回到指定的某个应用程序状态。(许多浏览器允许JavaScript动态更新锚点,这使得Ajax应用程序能够在更新显示内容的同时更新锚点。)这些解决方案也同时解决了许多关于不支持后退按钮的争论。
解决办法1:(通过隐藏的iframe的onload事件,见该图)
2 IE6/7/8/9/10/Firefox/Safari/Chrome/Opera
* (1)这种方式不是通过为当前页面设置hash来完成的,而是通过为一个辅助iframe对象设置hash来完成的,所以页面URL不会变化!
* (2)其中iframe在push时候或者页面后退时候都会触发onload,所以有一个字段pushing用于表示是否在保存数据,保存数据的时候什么也不做
* 也就是保存数据的时候我们不会恢复现场!
History = function() {
//这个函数是自执行的,所以刚引入js就会创建一个隐藏的iframe
var
iframe,
list = [],
index = 0,
pushing;
iframe = document.createElement('iframe');
iframe.style.display = 'none';
//创建一个隐藏的iframe添加到DOM中,那么每一次后退都会导致重新加载iframe,最后在onload中处理后退的逻辑就可以了!
iframe.onload = function() {
//后退的时候pushing是false,表示不是存放数据时候!
if(pushing) return;
//获取iframe的url!
var url= this.contentWindow.location.href;
//如果url有hash,那么获取hash值,同时根据这个hash值从list全局数组中来获取恢复现场所需要的数据和函数
if(url.indexOf('?')>-1) {
var idx = url.substr(url.indexOf('?')+1);
get(idx);
}
}
document.body.appendChild(iframe);
function push(data) {
if(typeof data !== 'object') return;
if(typeof data.param == undefined || typeof data.func !== 'function') return;
//把数据保存在一个数组中,数组下标是当前的hash!
list[index] = data;
//更新iframe,也就是把iframe的src设置为一个新的url,后面添加锚点hash!
updateIframe();
//正在保存数据为true!
pushing = true;
//hash值自增
index++;
//100ms后把pushing设置为false表示不存放数据了!
setTimeout(function(){
pushing = false;
}, 100);
}
function updateIframe() {
iframe.src = 'blank.html?' + index;
}
function get(idx) {
var item, param, func, scope;
if(idx != index) {
//从list中获取到恢复现场的数据!
item = list[idx];
if(item) {
//param为数据,func为函数,scope为上下文!
param = item.param;
func = item.func;
scope = item.scope;
//恢复现场!
func.call(scope, param);
}
}
}
return {
push : push
};
}();解决办法2:如果只要实现IE8以上的浏览器,那么可以用onhashChange事件
1.每次调用push保存状态时候也会触发onhashchange事件,后退的时候也会触发onhashchange事件!
* 2 IE8/9/10/Firefox/Safari/Chrome/Opera,IE6/7不支持
History = function() {
var
list = [],
index = 0;
//保存数据会修改hash,但是自己的hashchange事件中调用get方法
function push(data) {
if(typeof data !== 'object') return;
if(typeof data.param == undefined || typeof data.func !== 'function') return;
list[index] = data;
//修改自己的hash!
updateHash();
index++;
}
//改变自己页面的hash值,但是自己注册了onhashchange事件,该事件!
function updateHash() {
location.hash = index;
}
function get(idx) {
var item, param, func, scope;
if(idx != index) {
item = list[idx];
if(item) {
param = item.param;
func = item.func;
scope = item.scope;
func.call(scope, param);
}
}
}
//为自己绑定onhashchange,
window.onhashchange = function() {
get(location.hash.replace(/#/, ''));
}
return {
push : push
};
}();pushState和popstate是HTML5为history对象新增的方法和事件。虽然可以改变地址栏,
* 但却不能复制地址栏的url直接进入该历史记录(没有真正的发送HTTP请求)。该系列API知道IE10预览版尚不支持,
* Firefox/Safari/Chrome/Opera的最新版本均支持。
开发中应根据需求组合以上形式以兼容所有浏览器,如新浪微博就组合使用了方案一,四,五(base.js)。
如果项目中使用了一些开源库如jQuery,mootools等时强烈推荐使用histroy.js 。古老的dhtmlHistory.js和RSH已经很久没更新了。
History = function() {
var
list = [],
index = 1,
func, scope;
//保存的必须是对象
function push(data) {
if(typeof data !== 'object') return;
//除了保存的是对象以外还必须保证有param表示数据,有func表示恢复现场的函数!
if(typeof data.param == undefined || typeof data.func !== 'function') return;
func = data.func;
scope = data.scope;
//我们通过这种方式来修改hash值!
history.pushState({param: data.param}, index, '#' + index);
index++;
}
//注册回到上一页的回调函数,在该函数中我们恢复现场!
window.onpopstate = function(e) {
//第一个页面的数据是null!
if(e.state) {
var state = e.state,
param = state.param;
//获取参数,并且通过该参数恢复现场!
if(param) {
func.call(scope, param);
}
}
else{
//第一个页面数据是null,所以要另外调用!
if(func){
func.call(scope, 0);
}
}
}
return {
push : push
};
}();AJAX技术给用户带来很好的用户体验的同时也对IT企业带来了新的安全威胁,Ajax技术就如同对企业数据建立了一个直接通道。这使得开发者在不经意间会暴露比以前更多的数据和服务器逻辑。Ajax的逻辑可以对 客户端的安全扫描技术隐藏起来,允许黑客从远端服务器上建立新的攻击。还有Ajax也难以避免一些已知的安全弱点,诸如跨站点脚步攻击、SQL注入攻击和基于Credentials的安全漏洞等等。
<3>.对搜索引擎支持较弱。
对搜索引擎的支持比较弱。如果使用不当,AJAX会增大网络数据的流量,从而降低整个系统的性能。
随着网站的日益增多,SEO(搜索引擎优化)这样一种互联网技术已经在竞争的大环境愈现优势,作为提升Web站点知名度的重任,它与 Ajax 技术应并驾齐驱。但是任何事物都有其两面性,强强联手难度系数也显而易见。基于 Ajax 技 术的 Web 站点,对于 SEO 的不友好性主要就表现在 Ajax 对 于 SEO 可见度的影响。
1)SEO
SEO(搜索引擎优化)的主要工作是通过了解各类搜索引擎如何抓取互联网页面、如何进行索引以及如何确定其对某一特定关键词的搜索结果排名等技术,来对网页内容进行 相关的优化,使其符合用户浏览习惯,在不损害用户体验的 情况下提高搜索引擎排名,从而提高网站访问量,最终提升 网站的销售能力或宣传能力的技术。 2)Ajax 技术给 SEO 带来的问题 通过上面的阐述,我们了解到 SEO 的主要功能是抓取页 面、关键字以达到网站页面收录的目的,从而提高网站知名 度,同时,搜索引擎在抓取页面的时候会屏蔽掉所有 javascript 代码,而基于 Ajax 技术的 Web 站点其中所用到的很重要的 一项技术就是 javascript 代码, 那么 Ajax 载入的内容对于搜 索引擎来说也就是是透明的,这样一来,对于百度、google 等收录页面是十分不利的。
4 解决方案
纵使问题再多,困难再大,但人类的潜能永远是无穷的, Ajax与SEO再怎么相处的不融洽,也有使其友好和睦的方法。 1)改良 Ajax 代码方案
------------- 传统的 Ajax 方案.htm -------------
<html>
<head>
<script>
function orz6() {
document.getElementById("orz6.com").innerHTML="大家 好,欢迎来到 http://www.orz6.net!(假设文章比较长,此处 省略掉 2000 个字)"; }
</script>
</head>
<a href="#" _fcksavedurl=""#"" onClick="orz6()">繁体字,火星 文</a>
<div id="orz6.com">
</div>
</html> ------------- 兼顾搜索引擎的方案.htm -------------
<html>
<head>
<script>
function orz6() {
document.getElementById("orz6.com").innerHTML="大家
好,欢迎来到 http://www.socut.com!(假设文章比较长,此处 省略掉 2000 个字)"; }
</script>
</head>
<a href="http://www.orz6.com/fantizi.aspx"
onClick="orz6();return false;">繁体字,火星文</a> <div id="orz6.com"></div>
</html> 后面引入了hijax的概念:
为了有效地实施标准,使网站更易于访问,你必须通过使用HTML、CSS和JavaScript,把内容、样式(或表现)和行为分离。这是前端开发的三个层次。这种分离也使渐进增强 (PE)更加可行,渐进增强使网站在旧浏览器和技术上优雅降级。
“Hijax”(Jeremy Keith)是渐进增强的一个很好的例子,即使JavaScript不可用时,使网页仍具有AJAX的功能。一个伟大的经验法则是:“从一开始就计划AJAX,但最后实施。”要了解更多Hijax,请阅读2006年keith的演讲:“Hijax:AJAX逐步增强 。“同时通过文章hijax是什么技术?有什么优缺点? 可以了解hijack的概念
至少从目前看来,像Ajax.dll,Ajaxpro.dll这些Ajax框架是会破坏程序的异常机制的。关于这个问题,曾在开发过程中遇到过,但是查了一下网上几乎没有相关的介绍。后来做了一次试验,分别采用Ajax和传统的form提交的模式来删除一条数据……给我们的调试带来了很大的困难。
<5>.违背URL和资源定位的初衷。
例如,我给你一个URL地址,如果采用了Ajax技术,也许你在该URL地址下面看到的和我在这个URL地址下看到的内容是不同的。这个和资源定位的初衷是相背离的。 (动态评论)
<6>.AJAX不能很好支持移动设备。
一些手持设备(如手机、PDA等)现在还不能很好的支持Ajax,比如说我们在手机的浏览器上打开采用Ajax技术的网站时,它目前是不支持的。
<7>.客户端过肥,太多客户端代码造成开发上的成本。
编写复杂、容易出错 ;冗余代码比较多(层层包含js文件是AJAX的通病,再加上以往的很多服务端代码现在放到了客户端);破坏了Web的原有标准。
5.AJAX注意点及适用和不适用场景
(1).注意点
Ajax开发时,网络延迟——即用户发出请求到服务器发出响应之间的间隔——需要慎重考虑。不给予用户明确的回应,没有恰当的预读数据,或者对XMLHttpRequest的不恰当处理,都会使用户感到延迟,这是用户不希望看到的,也是他们无法理解的。通常的解决方案是,使用一个可视化的组件来告诉用户系统正在进行后台操作并且正在读取数据和内容。
(2).Ajax适用场景
<1>.表单驱动的交互
<2>.深层次的树的导航
<3>.快速的用户与用户间的交流响应
<4>.类似投票、yes/no等无关痛痒的场景
<5>.对数据进行过滤和操纵相关数据的场景
<6>.普通的文本输入提示和自动完成的场景
(3).Ajax不适用场景
<1>.部分简单的表单
<2>.搜索
<3>.基本的导航
<4>.替换大量的文本
<5>.对呈现的操纵
优点:"泛离异刷载" 缺点:“移肥退异安擎”
问题6:常见的前端安全术语?(浏览器无法判断是否是用户主动发出的)
CSRF(Cross-site request forgery)(银行转账的例子):中文名称:跨站请求伪造,也被称为:one click attack/session riding,缩写为:CSRF/XSRF。见浅谈CSRF攻击方式(验证码;token;Referer等来保护)
XSS(欢迎xx来到本站):xss表示Cross Site Scripting(跨站脚本攻击),它与SQL注入攻击类似,SQL注入攻击中以SQL语句作为用户输入,从而达到查询/修改/删除数据的目的,而在xss攻击中,通过插入恶意脚本,实现对用户浏览器的控制。详见xss攻击入门 和XSS的原理分析与解剖
DdoS的攻击方式有很多种,最基本的DoS攻击就是利用合理的服务请求来占用过多的服务资源,从而使合法用户无法得到服务的响应。单一的DoS攻击一般是采用一对一方式的,当攻击目标CPU速度低、内存小或者网络带宽小等等各项指标不高的性能,它的效果是明显的。随着计算机与网络技术的发展,计算机的处理能力迅速增长,内存大大增加,同时也出现了千兆级别的网络,这使得DoS攻击的困难程度加大了-目标对恶意攻击包的"消化能力"加强了不少。这时候分布式的拒绝服务攻击手段(DDoS)就应运而生了。DDoS就是利用更多的傀儡机(肉鸡)来发起进攻,以比从前更大的规模来进攻受害者
IP Spoofing
IP欺骗攻击是一种黑客通过向服务端发送虚假的包以欺骗服务器的
做法。具体说,就是将包中的源IP地址设置为不存在或不合法的值。服务器一旦接受到该包便会返回接受请求包,但实际上这个包永远返回不到来源处的计算机。这种做法使服务器必需开启自己的监听端口不断等待,也就浪费了系统各方面的资源
LAND attack
这种攻击方式与SYN floods类似,不过在LAND attack攻击包中的源地址和目标地址都是攻击对象的IP。这种攻击会导致被攻击的机器死循环,最终耗尽资源而死机。
DDOS:详见分布式拒绝服务攻击
//服务器端代码
<?php
$name = $_GET['name'];
echo "Welcome $name<br>";
echo "<a href="http://www.cnblogs.com/bangerlee/">Click to Download</a>";
?>
//用户在文本框输入内容为
index.php?name=guest<script>alert('attacked')</script>
//最后的内容为
Welcome guest
<script>alert('attacked')</script>
<br>
<a href='http://www.cnblogs.com/bangerlee/'>Click to Download</a>问题7:什么是DOM以及DOM年份?
Document Object Model的历史可以追溯至1990年代后期微软与Netscape的“浏览器大战”,双方为了在JavaScript与JScript一决生死,于是大规模的赋予浏览器强大的功能。微软在网页技术上加入了不少专属事物,既有VBScript、ActiveX、以及微软自家的DHTML格式等,使不少网页使用非微软平台及浏览器无法正常显示。DOM即是当时蕴酿出来的杰作。
DOM(见该图)是Document Object Model文本对象模型的简称,是指页面文档,所有的页面元素都放置在这个文档中,它的好处是显示页面指定的元素,不足在于禁止多层嵌套DOM元素,否则会影响页面加载的性能,可以调用元素的disabled属性禁用某个或全部它包含的元素。
根据W3C DOM规范,DOM是针对XML,但是经过扩展用于HTML的应用编程接口(API),DOM将整个页面映射为一个多层次节点结构。HTML或者XML页面的每一个组成部分都是某种类型的节点,这些节点有包含着不同类型的数据。通过DOM创建的这个表示文档的树形图,开发人员得到了控制页面内容和结构的主动权,借助于DOM提供的API可以轻松自在的添加删除替换或者修改任何节点
为什么是DOM:在IE4和Netscape4分别支持不同形式的DHTML基础上,开发人员首次无需重新加载网页就可以修改其外观和内容了,然而DHTML在web技术带来巨大进步的同时也带来的巨大的问题,由于Netscape和微软在开发DHTML各抒己见。过去那个编写一个HTML页面就可以在任何浏览器中运行的时代结束了。为了摆脱这个局面,W3C开始着手规划DOM!
"0级"DOM
当阅读与DOM有关的材料时,可能会遇到参考0级DOM的情况。需要注意的是并没有标准被称为0级DOM,它仅是DOM历史上一个参考点(0级DOM被认为是在Internet Explorer 4.0 与Netscape Navigator4.0支持的最早的DHTML)。
1级DOM
1级DOM在1998年10月份成为W3C的提议,由DOM核心与DOM HTML两个模块组成。DOM核心能映射以XML为基础的文档结构,允许获取和操作文档的任意部分。DOM HTML通过添加HTML专用的对象与函数对DOM核心进行了扩展。(主要映射文档结构)
2级DOM
鉴于1级DOM仅以映射文档结构为目标,DOM 2级面向更为宽广。通过对原有DOM的扩展,2级DOM通过对象接口增加了对鼠标和用户界面事件(DHTML长期支持鼠标与用户界面事件)、范围、遍历(重复执行DOM文档)和层叠样式表(CSS)的支持。同时也对DOM 1的核心进行了扩展,从而可支持XML命名空间。
2级DOM引进了几个新DOM模块来处理新的接口类型:
DOM视图:描述跟踪一个文档的各种视图(使用CSS样式设计文档前后)的接口;
var parentWindow=document.defaultView||document.parentWindow;
//指向拥有指定文档的窗口,除此之外没有任何可用的信息,唯一一个新增的属性//增加了两个方法,用于指定和删除事件处理程序,addEventListener和removeEventListener等主要有三种,通过link引入,通过style引入和内联的样式(document.implementation.hasFeature)。通过如elem.style.xx;removeProperty,getPropertyValue,setProperty,item等方式可以移除默认样式;getComputedStyle和currentStyle获取计算样式;操作样式表如elem.styleSheet||elem.sheet,sheet.cssRules||sheet.rules等
DOM遍历与范围:描述遍历和操作文档树的接口;
var support=document.implementation.hasFeature('Traversal','2.0');
var nodeIterator=(typeof document.createNodeIterator=='function');
//借助与NodeFilter来完成遍历,两个主要方法是nextNode和previousNode方法
var treewalker=(typeof document.createTreeWalker=='function');
//treeWalker真正强大之处在于可以向任何方向移动,除了nextNode,previousNode外还有firstChild,lastChild, parentNode, nextSiblings,previousSiblings等等
//注意DOM的遍历是深度优先遍历,TreeWalker是NodeIterator一个更加高级的版本var support=document.implementation.hasFeature('Range','2.0');
var alseS=(typeof document.createRange=='function');
//同时提供了如startContainer,endContainer,commonAncestorContainer等,selectNode,selectNodeContent,setStart,setEnd,deleteContents, extractContents, cloneContents, surroundContents等各种方法,对于IE就用createTextRange等方法 3级DOM
3级DOM引入了以统一方式载入和保存文档的方法(在DOM加载和保存模块中定义)和文档验证方法(DOM验证模块定义)对DOM进行进一步扩展,DOM3包含一个名为“DOM载入与保存”的新模块,DOM核心扩展后可支持XML1.0的所有内容,包括XML Infoset、 XPath、和XML Base。
var support=document.implementation.hasFeature('XPath','3.0');
//提供了evaluate,createExpression,,createNSResolver等DOM= Document Object Model,文档对象模型,DOM可以以一种独立于平台和语言的方式访问和修改一个文档的内容和结构。换句话说,这是表示和处理一个HTML或XML文档的常用方法。有一点很重要,DOM的设计是以对象管理组织(OMG,OMG是一个国际化的、开放成员的、非盈利性的计算机行业标准协会,该协会成立于1989年。任何组织都可以加入OMG并且参与标准制定过程)的规约为基础的,因此可以用于任何编程语言。最初人们把它认为是一种让JavaScript在浏览器间可移植的方法,不过DOM的应用已经远远超出这个范围。Dom技术使得用户页面可以动态地变化,如可以动态地显示或隐藏一个元素,改变它们的属性,增加一个元素等,Dom技术使得页面的交互性大大地增强。更多内容,参见百度百科
DOM坏处:可能导致页面的重绘和回流,所以我们更多的依赖于HTML来显示数据,而不是用JS来操作数据。因为HTML是页面的结构,而JS只是行为
SVG:(scalable Vector Graphic可伸缩矢量图); MathML:(Mathematical Markup language)数学标记语言; SMIL(Synchronized Multimedia Integration Language)多媒体同步集成语言,这都是除了DOM核心和DOM HTML接口以外,另外集中语言发布的只针对自己的DOM标准。
注意:DOM2核心没有引入任何新类型,只是在DOM1级基础上通过增加新方法和新属性增强既有类型(getAttributeNS等通过命名空间来获取元素,为document.implementation增加了createDocumentType,createDocument,createHTMLDocument),而DOM3增强了既有类型的同时也引入了新类型!(isSameNode,isEqualNode等)
问题7:ECMAScipt===javascript?
虽然javascript和ECMAScript表示同样的含义(见该图),但是javascript的含义比ECMA-262规定的多得多。包括核心(ECMAScript),文档对象模型(DOM),浏览器对象模型(BOM)。ECMA-262定义的ECMASCipt和web浏览器之间没有依赖关系,ECMA-262定义的只是这门语言的基础,而再此基础之上可以构建更加完善的脚本语言,我们常见的web浏览器只是ECMASCipt事件可能的宿主环境之一,宿主环境不仅提供基本的ECMAScript实现,同时也提供该语言的拓展,以便语言和环境之间对接交互。其它宿主环境包括Node和Adobe Flash。javascript实现了ECMAScript,而Adobe ActionScript同样也实现了ECMAScipt! ECMAScript最近一版是第五版,出版2009年!
问题8:有没有考虑过CSS性能问题?
文件组织角度:
(1)不要使用import,而要使用link,如果你想样式表并行载入,以使页面更快,请使用LINK 替代@import。参见为了网站的性能 请不要使用@import (注意:如果使用@import的话,你必须时刻记得要将@import放到样式代码的最前面,否则它将会不起作用)。问题出现在当@import嵌套入其它样式中或者和LINK联合使用的时候,这时候可能会导致并行下载失效(去这里看看把);同时也会产生如FOUCx现象也就是花屏现象!
(2)把 Stylesheets放在HTML 页面头部:
浏览器在所有的 stylesheets 加载完成之后,才会开始渲染整个页面,在此之前,浏览器不会渲染页面里的任何内容,页面会一直呈现空白。这也是为什么要把 stylesheet 放在头部的原因。如果放在 HTML 页面底部,页面渲染就不仅仅是在等待 stylesheet 的加载,还要等待 html 内容加载完成,这样一来,用户看到页面的时间会更晚。对于 @import 和 <link> 两种加载外部 CSS 文件的方式:@import 就相当于是把 <link> 标签放在页面的底部,所以从优化性能的角度看,应该尽量避免使用 @import 命令
(3)避免使用 CSS Expressions:
清单 1. CSS Expression 案例
Background-color: expression( (new Date()).getHours()%2 ? "#B8D4FF" : "#F08A00" )
Expression 只有 IE 支持,而且他的执行比大多数人想象的要频繁的多。不仅页面渲染和改变大小 (resize) 时会执行,页面滚动 (scroll) 时也会执行,甚至连鼠标在页面上滑动时都会执行。在 expression 里面加上一个计数器就会知道,expression 的执行上相当频繁的。鼠标的滚动很容易就会使 expression 的执行次数超过 10000。
(4)避免使用 Filter:
IE 特有的 AlphaImageLoader filter 是为了解决 IE6 及以前版本不支持半透明的 PNG 图片而存在的。但是浏览器在下载 filter 里面的图片时会“冻结”浏览器,停止渲染页面。同时 filter 也会增大内存消耗。最不能忍受的是 filter 样式在每个页面元素(使用到该 filter 样式)渲染时都会被浏览器分析一次,而不是像一般的背景图片渲染模式:使用过该背景图片的所有元素都是被浏览器一次性渲染的。针对这种情况,最好的解决办法就是使用 PNG8。
其它内容参见提高 web 应用性能之 CSS 性能调优 高性能CSS 合并css/压缩css/简化css等等
问题9:js异步加载的方式有哪几种?
defer:仅仅支持IE(实现了延迟)
async:HTML5属性(实现了异步),document.write这种方式也是异步加载的
动态插入脚本(延迟了,通过async实现异步):所有浏览器支持(jQuey中通过ajax方法加载脚本就是通过创建script元素来完成的,getScript等方法默认的aync全部是true表示都是异步的。而且如果要缓存自己设置cache就可以了,因为在ajaxPrefilter中规定了如果cache没指定就是false,同时也指定了script.async=true表示异步加载。实用技巧:使用 jQuery 异步加载 JavaScript 脚本)
ajax:通过ajax获取内容,然后通过eval来执行脚本
其它延迟:seajs,requirejs等按需加载
问题9(附加):使用iframe导致的性能问题有那些(setTimeout加载;onload后加载,这两种方式下iframe都不会阻塞主页面的onload事件,但是会显示正在加载数据)?
第一:iframe会阻塞主页面的onload事件;第二:主页面和iframe共享同一个连接池(而浏览器对相同域的连接有限制,所以会影响页面的并行加载);iframe和主页面可以并行加载。阻塞主页面的onload是这两个问题中最影响性能的方面。一般都是想让onload时间越早触发越好,一方面是用户体验过更重要的是google给网站的加载速度的打分:用户可以用IE和FF中Google工具栏来计时。
(function(d) {
var iframe = d.body.appendChild(d.createElement('iframe')),
doc = iframe.contentWindow.document;
// style the iframe with some CSS
iframe.style.cssText ="position:absolute;width:200px;height:100px;left:0px;";
doc.open().write('<body οnlοad="'+
'var d = document;d.getElementsByTagName(\'head\')[0].'+
'appendChild(d.createElement(\'script\')).src'+'=\'\/path\/to\/file\'">');
doc.close(); //iframe onload event happens
})(document);神奇的地方就在<body οnlοad="">:这个iframe一开始没有内容,所以onload会立即触发。然后你创建一个script元素,用他来加载内容、广告、插件什么的,然后再把这个script添加到HEAD中去,这样iframe内容的加载就不会阻塞主页面的onload!你应该看看他在个浏览器中的表现:
iframe会在主页面onload之前开始加载;iframe的onload会立即触发,因为iframe的内容一开始为空;主页面的onload不会被阻塞;为什么这个iframe不会阻塞主页面的onload?因为<body οnlοad="">;如果你不在iframe使用onload监听,那么iframe的加载就会阻塞主页面的onload。;当iframe加载的时候,浏览器终于不显示忙碌状态了(非常好)参见iframe异步加载技术及性能。(iframe也没有语义)
在百度的搜索引擎优化技能中我们可以看到:“frame/frameset/iframe标签,会导致百度蜘蛛的抓取困难,建议不要使用”。所以说目前所有的搜索引擎都无法识别页面ifram框架中被调用的链接、文本、图片等等内容的,原因很简单因为该内容不属于该页面,只是在用户访问的时候被临时的调用。而且网站首页使用ifram被搜索引擎视为不友好表现,可能导致网站降权和关键词排名下降。这样就可以很明显的看出其存在的弊端了。详见iframe对网站优化的利与弊。
举一个例子,比如一些大型网站推广首页的备-案信息,荣誉zhengshu,认证等之类的网络营销链接,这些我们不需要给网络营销搜索引擎看,因为这样稀释了网站推广首页的权重,我们就可以搭配iframe来使用,而且只需要在首页被使用,其他页面可以不需要这些信息,还有一般在门户站投放的广告都是用iframe调用的,这是为了放广告,又不给那些广告链接输送权重。是不是很完美呢,这就是其利。(广告 vs 荣誉证书)
1、网站顶部(导航栏目以上就算是顶部)不要采用iframe框架结构,一般放在中间或尾部;
2、一个页面的iframe不要太多,真的有那么多广告放(有钱赚),那最多也只能放两个(个人经验),这的大家有兴趣可以测试下,反正我放两个是没有影响的
3、iframe框架内的内容尽量简单,一般就是一个图片或者简单的网页;简称"顶部太多反而简单"。
在 HTML 4.1 Strict DTD 和 XHTML 1.0 Strict DTD 中,不支持 iframe 元素。
问题9(附加):可不可以 js异步加载css文件(通过xhr获取然后插入到页面中)?
function loadCSS(url){
var cssLink = document.createElement("link");
cssLink.rel = "stylesheet";
cssLink.rev = "stylesheet";
cssLink.type = "text/css";
cssLink.media = "screen";
cssLink.href = url;
document.getElementsByTagName("head").appendChild(cssLink);
}问题10:浏览器缓存和应用缓存的区别?
manifest的特点:(一次更新下次生效)
(1)manifest文件有变化才会更新,或者清除缓存,或者程序干预applicationCache.update(强制检查应用缓存)+applicationCache.swapCache。同时applicationCache有一个status属性
(2)一次必须更新manifest中所有的文件。(如果要更新10个文件,但是这次只完成了9个那么更新是失败的)
(3)这次的更新下次打开浏览器才会生效,除非程序干预
(4)主要状态:checking为浏览器查找更新时候触发;error在检查更新或者下载资源期间发生错误时候触发;noupdate在检查描述文件发现文件没有变化时候触发;downloading在开始下载应用缓存资源的时候开始触发;progress在文件下载应用缓存的时候持续不断的触发;updateReady在页面新的应用缓存下载完毕并且可以通过swapCache使用时触发,swapCache表示启用新的应用缓存;cached在应用缓存完整可用时触发.
用程序缓存是 HTML5 的重要特性之一,提供了离线使用的功能,让应用程序可以获取本地的网站内容,例如 HTML、CSS、图片以及 JavaScript。这个特性可以提高网站性能,它的实现借助于 manifest 文件。应用缓存可以作用应程序使用而浏览器缓存无法做到(各个页面之间是否可以跳转);没有网络的情况下:当按住ctrl+F5的时候浏览器缓存无法加载完成,而应用程序缓存可以,因为他可以自己控制如果没有网络的情况下直接从本地加载(结合localstorage)。参见浏览器: F5 和 Ctrl+F5的区别
问题11:css布局和table布局的区别?
DIV+CSS的特点:
1、符合W3C标准。微软等公司均为W3C支持者。这一点是最重要的,因为这保证您的网站不会因为将来网络应用的升级而被淘汰。
2、搜索引擎更加友好。相对与传统的table, 采用DIV+CSS技术的网页,对于搜索引擎的收录更加友好。
3、样式的调整更加方便。内容和样式的分离,使页面和样式的调整变得更加方便。 现在YAHOO,MSN等国际门户网站,网易,新浪等国内门户网站,和主流的WEB2.0网站,均采用DIV+CSS的框架模式,更加印证了DIV+CSS是大势所趋。 现很多个人站长新建站点都采用了DIV+CSS来构建自己的网站页面,可见DIV+CSS替代table已经不是遥远梦想。
4、通过制作发行同样的页面使用TABLE做的页面与DIV+CSS制作的页面大小对比,DIV+CSS的XHTML页面大小至少小TABLE制作页面1/4。从而使的浏览DIV+CSS的页面更加快捷快速。(一句话"小离准擎"同名"小李赚钱"就为了用css替换table)
问题12:内联css>嵌入式>外部引用css?
一:嵌入式
用户可在HTML文档头部定义多个style元素,实现多个样式表。
二:外部引用式
①可以在多个文档间共享样式表,对于较大规模的网站,将CSS样式定义独立成一个一个的文档,可有效地提高效率,并有利于对网站风格的维护。
②可以改变样式表,而无需更改HTML文档,这也与HTML语言内容与形式分开的原则相一致。
③可以根据介质有选择的加载样式表。
三:内联式
使用该属性可以直接指定样式,当然,该样式仅能用于该元素的内容,对于另一个同名的元素则不起作用。
优先级:
内联式>内嵌式>外部引用式
问题13:IE内存泄漏的情况?
1、给DOM对象添加的属性是一个对象的引用。(事实上包括 element.onclick = funcRef 这种写法也算在其中,因为这也是一个对对象的引用。)
2、DOM对象与JS对象相互引用(IE早期版本的BOM和DOM是用COM类型实现的,而COM又是用引用技术完成的)
3、给DOM对象用attachEvent绑定事件。(调用detachEvent也无法释放内存,因为在attachEvent的时候就已经造成内存“LEAK”了)。在jQuery中在detachEvent之前如果该event不存在,那么就设置为null后再调用detachEvent!
4、从外到内执行appendChild。这时即使调用removeChild也无法释放。
5、反复重写同一个属性会造成内存大量占用(但关闭IE后内存会被释放)。
6、删除元素后,事件和数据还在也会导致内存泄漏
7、隐式类型转换,如"xx".length会首先转为new String('xx')
循环引用(Circular References);内部函数引用(Closures);页面交叉泄漏(Cross-Page Leaks);貌似泄漏(Pseudo-Leaks)。详见Js内存泄漏及解决方案
问题14:问题:你知道那些前端大牛?
steve souder:《高性能网站设计》设计作者,但是我只是看过他关于import和link同时引入css的一篇翻译过来的博客;iframe异步加载技术及性能 也是他写的;seajs作者余波;张鑫旭等
问题15:什么叫资源预加载,你知道那些预加载的知识?
页面资源预加载(Link prefetch)是浏览器提供的一个技巧,目的是让浏览器在空闲时间下载或预读取一些文档资源,用户在将来将会访问这些资源。一个Web页面可以对浏览器设置一系列的预加载指示,当浏览器加载完当前页面后,它会在后台静悄悄的加载指定的文档,并把它们存储在缓存里。当用户访问到这些预加载的文档后,浏览器能快速的从缓存里提取给用户。
图片预加载的知识,重点要知道图片预加载时候要通过compete检测是否已经在浏览器缓存中
function loadImage(url, callback) {
var img = new Image();
//创建一个Image对象,实现图片的预下载
img.src = url;
if (img.complete) {
// 如果图片已经存在于浏览器缓存,直接调用回调函数
callback.call(img);
return;
// 直接返回,不用再处理onload事件
}
img.onload = function () {
//图片下载完毕时异步调用callback函数。
callback.call(img);
//将回调函数的this替换为Image对象
};
};
loadImage('1.jpg',function(){console.log(this.width);});也可以用new Image来预加载css文件
解答:这种方式FF不支持
可以用new Image来加载js文件
IE下 image 预加载js在httpwatch下查看content,资源的加载并不是完整的。我这里测试也是如此。貌似有字节限制,测试中2返回的是完整的,5有一部分内容丢失了。所以用new Image加载JS一点都不可取。
这里总结下:预加载图片用new Image()兼容性没问题。但是css/js只有OP/CM可以,IE/FF基本是无效(这点IE/FF到挺有默契)。
window.onload来延迟加载也是可以的。
seajs-preload:用这种方式可以实现特定的模块执行之前依赖的模块已经加载完成,这也是一种预加载!
HTML5页面资源预加载(Link prefetch)写法:prefetch表示当subresources都加载完成以后才加载;subresource表示当前页面必须加载的资源;chrome浏览器和FF浏览器甚至支持prerender,不过ff用的是next表示预先渲染!<!-- 预加载整个页面 -->
<link rel="prefetch" href="http://www.webhek.com/misc/3d-album/" />
<!-- 预加载一个图片 -->
<link rel="prefetch" href=" http://www.webhek.com/wordpress/wp-content/uploads/2014/04/b-334x193.jpg " />dns-pretch就是预先解析DNS:
<link rel="dns-prefetch" href="//fonts.googleapis.com"> 有了浏览器缓存为什么还要用预加载
用户可能是第一次访问网站,此时还无缓存;用户可能清空了缓存;缓存可能已经过期,资源将重新加载;用户访问的缓存文件可能不是最新的,需要重新加载(详见HTML5 prefetch)。注意:即使在不支持的浏览器,用了这个特性其实是不会出错的,只不过浏览器解析不到而已,所以,如果你感觉能有办法预先预测到用户期望点的页面(比如用户看最新的受欢迎的热图,他可能看了第一页后,会继续看下一页,这个时候就可以用预先加载这个特性了)。参见探讨HTML5的预加载功能prefetch
function preload(arr) {
var i = arr.length,
o,
d = document,
b = document.body,
isIE = /*@cc_on!@*/0;
while (i--) {
if (isIE) {
new Image().src = arr[i];
continue;
}
o = d.createElement('object');
o.data = arr[i];
o.width = o.height = 0;
b.appendChild(o);
}
}
window.onload = function () {
preload([
'http://localhost/load.js',
'http://localhost/load.css',
'http://localhost/load.jpg'
]);
}问题16:什么是web标准?
WEB标准不是某一个标准,而是一系列标准的集合。网页主要由三部分组成:结构(Structure)、表现(Presentation)和行为(Behavior)。对应的标准也分三方面:结构化标准语言主要包括XHTML和XML,表现标准语言主要包括CSS,行为标准主要包括对象模型(如W3C DOM)、ECMAScript等。这些标准大部分由W3C起草和发布,也有一些是其他标准组织制订的标准,比如ECMA(European Computer Manufacturers Association)的ECMAScript标准。见该图
XML
XML是The Extensible Markup Language(可扩展标识语言)的简写。目前推荐遵循的是W3C于2000年10月6日发布的XML1.0,参考(www.w3.org/TR/2000/REC-XML-20001006)。和HTML一样,XML同样来源于SGML(standard generalized markup language),但XML是一种能定义其他语言的语。XML最初设计的目的是弥补HTML的不足,以强大的扩展性满足网络信息发布的需要,后来逐渐用于网络数据的转换和描述。
XHTML是The Extensible HyperText Markup Language可扩展超文本标识语言的缩写。目前推荐遵循的是W3C于2000年1月26日推荐XML1.0(参考http://www.w3.org/TR/xhtml1)。XML虽然数据转换能力强大,完全可以替代HTML,但面对成千上万已有的站点,直接采用XML还为时过早。因此,我们在HTML4.0的基础上,用XML的规则对其进行扩展,得到了XHTML。简单的说,建立XHTML的目的就是实现HTML向XML的过渡
ECMAScript是ECMA(European Computer Manufacturers Association)制定的标准脚本语言(JAVAScript)。目前推荐遵循的是ECMAScript 262
采用Web标准的好处 对于访问者:
1. 文件下载与页面显示速度更快。 2. 内容能被更多的用户所访问(包括失明、视弱、色盲等残障人士)。 3. 内容能被更广泛的设备所访问(包括屏幕阅读机、手持设备、搜索机器人、打印机、电冰箱等等)。 4. 用户能够通过样式选择定制自己的表现界面。 5. 所有页面都能提供适于打印的版本。
对于网站所有者: 1. 更少的代码和组件,容易维护。 2. 带宽要求降低(代码更简洁),成本降低。举个例子:当 ESPN.com 使用 CSS改版后,每天节约超过两兆字节(terabytes)的带宽。 3. 更容易被搜寻引擎搜索到。 4. 改版方便,不需要变动页面内容。 5. 提供打印版本而不需要复制内容。 6. 提高网站易用性。在美国,有严格的法律条款(Section 508)来约束政府网站必须达到一定的易用性,其他国家也有类似的要求。
1. 不是为了通过校验才标准化
web标准的本意是实现内容(结构)和表现分离,就是将样式剥离出来放在单独的css文件中。这样做的好处是可以分别处理内容和表现,也方便搜索和内容的再利用。 W3C校验仅仅是帮助你检查XHTML代码的书写是否规范,css的属性是否都在CCS2的规范内。代码的标准化仅仅是第一步,不是说通过的校验,我的网页就标准化了。我们不是为了虚名,或者向别人炫耀:“看我的页面通过了校验”而去标准化,我们的目的是为了使自己的网页设计工作更有效率,为了缩小网页尺寸,为了能够在任何浏览器和网络设备中正常浏览 (HTML发展历史 HTML用规范检验规范 html5是什么 WHATWG是什么)
问题17:那些技术可以实现无刷新更新数据?
xhr,iframe(利用XDR实现数据传送),applet,flash
iframe方式:利用了主页面可以通过contentDocument等控制从页面,当然后面HTML5也提供了XDM的方式
document.getElementById('child').contentDocument.location.reload(true)问题18:ajax的过程是怎么样的?
经过总结使用Ajax可以分为四步,分别如下:
1:创建引擎(xmlHttpRequest对象)
不同的浏览器创建 XMLHttpRequest 对象的方法是有差异的,针对IE使用ActiveXObject,针对其他浏览器用xmlHttpRequest,但是如果针对不同版本的的浏览器可以使用“try and catch”语句来进行创建
2:事件处理函数,处理服务器的响应结果。
onreadystatechange事件:该事件处理函数由服务器触发,而不是用户,相当于监听,监听服务器每个动作
readyState 属性表示Ajax请求的当前状态。它的值用数字代表。分别是:
0 代表未初始化。 还没有调用 open 方法
1 代表正在加载。 open 方法已被调用,但 send 方法还没有被调用
2 代表已加载完毕。send 已被调用。请求已经开始
3 代表交互中。服务器正在发送响应
4 代表完成。响应发送完毕
status 属性表示状态码,也是用数字表示,分别是:
404 没找到页面(not found)
403 禁止访问(forbidden)
500 内部服务器出错(internal service error)
200 一切正常(ok)
304 没有被修改(not modified)(服务器返回304状态,表示源文件没有被修改 )
responseText属性包含了从服务器发送的数据
每次 readyState 值的改变,都会触发 readystatechange 事件
3:打开一个连接open(method, url, asynch)
允许客户端用一个Ajax调用向服务器发送请求。
三个参数的含义如下:
method:请求类型,类似 “GET”或”POST”的字符串
url:请求路径字符串,指向所请求的服务器上的那个文件(servlet,jsp,action)
asynch:表示请求是否要异步传输,默认值为true(异步)
4:发送数据send(data)
data:向服务器发的数据,如果是get方式data为null就行,即使传了参数,服务器也收不到。如果为post方式在send(data)之前还要设置requestHeader("Content-Type","application/x-www-form-urlencoded")。
问题19:如何实现把div下面所有的节点反转?
function convertToArray(nodes)
{
var arr=null;
try
{
arr=Array.prototype.slice.call(nodes);
}catch(e)
{
//IE9以前把Nodelist通过COM来实现,而我们不能像使用JScript那样使用该对象!
arr=new Array();
for(var i=0,len=nodes.length;i<len;i++)
{
arr.push(nodes[i]);
}
}
return arr;
}
window.οnlοad=function()
{
var reverse=document.getElementById('reverse');
var children=reverse.children;
//只是获取到元素节点!
var arr=convertToArray(children);
arr.reverse();
//用documentFragment减少回流!
var fragment=document.createDocumentFragment();
for(var i=0,len=arr.length;i<len;i++)
{
fragment.appendChild(arr[i]);
}
reverse.appendChild(fragment);
}问题20:css中的各种居中实现?
问题21:CSShack了解多少?
由于不同的浏览器和浏览器各版本对CSS的支持及解析结果不一样,以及CSS优先级对浏览器展现效果的影响,我们可以据此针对不同的浏览器情景来应用不同的CSS。
区别IE和非IE
background-color:red;
background-color:green\9;区分IE6/7和FF:
#tip{
background:blue;/*Firefox背景变蓝色*/
*background:green!important;/*IE7背景变绿色,!important是IE7/8*/
*background:orange;/*IE6背景变橘色*/
} 千万不要出现下面这种情况,否则所有浏览器都会渲染为绿色
background-color:red;
background-color:green!important;也可以用那种注释的方式来完成
只在IE下生效
<!--[if IE]>
这段文字只在IE浏览器显示
<![endif]-->
只在IE6下生效
<!--[if IE 6]>
这段文字只在IE6浏览器显示
<![endif]-->
只在IE6以上版本生效
<!--[if gte IE 6]>
这段文字只在IE6以上(包括)版本IE浏览器显示
<![endif]-->
只在IE8上不生效
<!--[if ! IE 8]>
这段文字在非IE8浏览器显示
<![endif]-->
非IE浏览器生效
<!--[if !IE]>
这段文字只在非IE浏览器显示
<![endif]-->一般情况下,我们尽量避免使用CSS hack,但是有些情况为了顾及用户体验实现向下兼容,不得已才使用hack。比如由于IE8及以下版本不支持CSS3,而我们的项目页面使用了大量CSS3新属性在IE9/Firefox/Chrome下正常渲染,这种情况下如果不使用css3pie或htc或条件注释等方法时,可能就得让IE8-的专属hack出马了。使用hack虽然对页面表现的一致性有好处,但过多的滥用会造成html文档混乱不堪,增加管理和维护的负担。相信只要大家一起努力,少用、慎用hack,未来一定会促使浏览器厂商的标准越来越趋于统一,顺利过渡到标准浏览器的主流时代。抛弃那些陈旧的IE hack,必将减轻我们编码的复杂度,少做无用功。不得不收藏的——IE中CSS-filter滤镜小知识大全 Sep 07 2012 前端路上遇到的IE6 bug汇总(持续更新) IE滤镜处理PNG图片有严重的BUG!
问题22:一个页面有多个h1标签的作用是什么?
一个页面用多个h1标签会被认为是作弊吗?
搜索引擎判断一个网站是否有作弊,最基本的原则是该网站是不是有违背用户体验,而一个网站加多个h1标签并不违背用户体验,比如说一个页面当中,有2大内容,而用h1标签来分别做这2大内容的标题修饰,这点并没有什么不可以的。笔者也观察过不少网站,有些网站首页甚至有5~6个h1标签,也没有被惩罚的迹象。
虽然一个页面用多个h1标签不会被认为是作弊,但是并不建议一个页面用多个h1标签,原因是会分散权重。h1标签是用来修饰页面的最重要的主题的,如果一个页面用了多个h1标签,会让百度不知道你这个页面的主要内容,很可能会淡化标题关键词的排名。
h1标签用在logo当中的效果如何?
现在有相当大的一批人,开始尝试在给网站的logo加上h1标签,因为h1标签能够引起蜘蛛的注意,所以通过给logo加上这个标签,可以让蜘蛛更多的注意到首页,从而大大的增加首页的权重。有些网站确实因为这样的做法让首页的排名有所上涨的。
但是在logo上面加h1标签也带来了一些负面的影响。首先是影响了内页的权重。很明显,内页的主题和首页是不一样的,给内页的logo也加了h1标签,这让内页的的主题变得不明确了,对百度来说是非常不有好的,权重自然就会受到影响。其次,是可能会引起百度的反感,被认为是作弊。特别是在给全站的logo都加上这个标签的时候,是非常危险的,因为这是一种过度优化的行为。
总体来说h1标签用在logo当中会有一定的效果,但是要谨慎使用。
h1标签怎么用最有助于页面的关键词排名?
无疑在一个页面当中用h1标签修饰核心关键词是最有助于提高关键词排名的做法,但是在实际布置的时候要刻记住一点:h1标签是给用户看的,因此在对网站不同的页面做h1标签处理的时候,首先要考虑的都是用户,然后再考虑到搜索引擎。
比如说网站的首页,h1标签的添加最好是在logo上面,因为一个网站的首页最重要的内容就是展示你的网站,而logo就是最能代表你网站的那个地方;对于列表页,h1标签就可以完全用来修饰该页面的主关键词,因为那个关键词完全可以表达出这个页面的核心内容;对于产品页或者文章页,h1标签用来修饰产品名称、文章标题就最恰当。这样运用h1标签是会对关键词排名有所帮助的,而且不会引起百度的反感。
问题23:CSRF可以用什么方式来防御?(根本原因不知道是否是用户授权的请求)
CSRF漏洞防御主要可以从三个层面进行,即服务端的防御、用户端的防御和安全设备的防御。
4 CSRF漏洞防御
CSRF漏洞防御主要可以从三个层面进行,即服务端的防御、用户端的防御和安全设备的防御。
4.1 服务端的防御
目前业界服务器端防御CSRF攻击主要有三种策略:验证HTTP Referer字段,在请求地址中添加token并验证,在HTTP头中自定义属性并验证。下面分别对这三种策略进行简要介绍。
4.1.1 验证HTTP Referer字段
根据HTTP协议,在HTTP头中有一个字段叫Referer,它记录了该HTTP请求的来源地址。在通常情况下,访问一个安全受限页面的请求必须来自于同一个网站。比如某银行的转账是通过用户访问http://bank.test/test?page=10&userID=101&money=10000页面完成,用户必须先登录bank. test,然后通过点击页面上的按钮来触发转账事件。当用户提交请求时,该转账请求的Referer值就会是转账按钮所在页面的URL(本例中,通常是以bank. test域名开头的地址)。而如果攻击者要对银行网站实施CSRF攻击,他只能在自己的网站构造请求,当用户通过攻击者的网站发送请求到银行时,该请求的Referer是指向攻击者的网站。因此,要防御CSRF攻击,银行网站只需要对于每一个转账请求验证其Referer值,如果是以bank. test开头的域名,则说明该请求是来自银行网站自己的请求,是合法的。如果Referer是其他网站的话,就有可能是CSRF攻击,则拒绝该请求。
4.1.2 在请求地址中添加token并验证
CSRF攻击之所以能够成功,是因为攻击者可以伪造用户的请求,该请求中所有的用户验证信息都存在于Cookie中,因此攻击者可以在不知道这些验证信息的情况下直接利用用户自己的Cookie来通过安全验证。由此可知,抵御CSRF攻击的关键在于:在请求中放入攻击者所不能伪造的信息,并且该信息不存在于Cookie之中。鉴于此,系统开发者可以在HTTP请求中以参数的形式加入一个随机产生的token,并在服务器端建立一个拦截器来验证这个token,如果请求中没有token或者token内容不正确,则认为可能是CSRF攻击而拒绝该请求。
4.1.3 在HTTP头中自定义属性并验证
自定义属性的方法也是使用token并进行验证,和前一种方法不同的是,这里并不是把token以参数的形式置于HTTP请求之中,而是把它放到HTTP头中自定义的属性里。通过XMLHttpRequest这个类,可以一次性给所有该类请求加上csrftoken这个HTTP头属性,并把token值放入其中。这样解决了前一种方法在请求中加入token的不便,同时,通过这个类请求的地址不会被记录到浏览器的地址栏,也不用担心token会通过Referer泄露到其他网站。
4.2 用户端的防御
对于普通用户来说,都学习并具备网络安全知识以防御网络攻击是不现实的。但若用户养成良好的上网习惯,则能够很大程度上减少CSRF攻击的危害。例如,用户上网时,不要轻易点击网络论坛、聊天室、即时通讯工具或电子邮件中出现的链接或者图片;及时退出长时间不使用的已登录账户,尤其是系统管理员,应尽量在登出系统的情况下点击未知链接和图片。除此之外,用户还需要在连接互联网的计算机上安装合适的安全防护软件,并及时更新软件厂商发布的特征库,以保持安全软件对最新攻击的实时跟踪。
4.3 安全设备的防御
由于从漏洞的发现到补丁的发布需要一定的时间,而且相当比例的厂商对漏洞反应不积极,再加之部分系统管理员对系统补丁的不够重视,这些都给了攻击者可乘之机。鉴于上述各种情况,用户可以借助第三方的专业安全设备加强对CSRF漏洞的防御。
CSRF攻击的本质是攻击者伪造了合法的身份,对系统进行访问。如果能够识别出访问者的伪造身份,也就能识别CSRF攻击。研究发现,有些厂商的安全产品能基于硬件层面对HTTP头部的Referer字段内容进行检查来快速准确的识别CSRF攻击。图3展示了这种防御方式的简图。目前pC公司的IPS产品采用了特殊技术,支持对部分常用系统的CSRF漏洞攻击进行检测和阻断。
3 CSRF 漏洞检测
检测CSRF漏洞是一项比较繁琐的工作,最简单的方法就是抓取一个正常请求的数据包,去掉Referer字段后再重新提交,如果该提交还有效,那么基本上可以确定存在CSRF漏洞。
随着对CSRF漏洞研究的不断深入,不断涌现出一些专门针对CSRF漏洞进行检测的工具,如CSRFTester,CSRF Request Builder等。
以CSRFTester工具为例,CSRF漏洞检测工具的测试原理如下:使用CSRFTester进行测试时,首先需要抓取我们在浏览器中访问过的所有链接以及所有的表单等信息,然后通过在CSRFTester中修改相应的表单等信息,重新提交,这相当于一次伪造客户端请求。如果修改后的测试请求成功被网站服务器接受,则说明存在CSRF漏洞,当然此款工具也可以被用来进行CSRF攻击。
问题24:XSS攻击的防御?
攻击者可以利用XSS漏洞向用户发送攻击脚本,而用户的浏览器因为没有办法知道这段脚本是不可信的,所以依然会执行它。对于浏览器而言,它认为这段脚本是来自可以信任的服务器的,所以脚本可以光明正大地访问Cookie,或者保存在浏览器里被当前网站所用的敏感信息,甚至可以知道用户电脑安装了哪些软件。这些脚本还可以改写HTML页面,进行钓鱼攻击。
虽然产生XSS漏洞的原因各种各样,对于漏洞的利用也是花样百出,但是如果我们遵循本文提到防御原则,我们依然可以做到防止XSS攻击的发生。
有人可能会问,防御XSS的核心不就是在输出不可信数据的时候进行编码,而现如今流行的Web框架(比如Rails)大多都在默认情况下就对不可信数据进行了HTML编码,帮我们做了防御,还用得着我们自己再花时间研究如何防御XSS吗?答案是肯定的,对于将要放置到HTML页面body里的不可信数据,进行HTML编码已经足够防御XSS攻击了,甚至将HTML编码后的数据放到HTML标签(TAG)的属性(attribute)里也不会产生XSS漏洞(但前提是这些属性都正确使用了引号),但是,如果你将HTML编码后的数据放到了<SCRIPT>标签里的任何地方,甚至是HTML标签的事件处理属性里(如onmouseover),又或者是放到了CSS、URL里,XSS攻击依然会发生,在这种情况下,HTML编码不起作用了。所以就算你到处使用了HTML编码,XSS漏洞依然可能存在。下面这几条规则就将告诉你,如何在正确的地方使用正确的编码来消除XSS漏洞。
详细内容参见防御 XSS 攻击的七条原则以及各种HTTP头 X-XSS-Protection,Content-Security-Policy,X-Frame-Options,HttpOnly,Strict-Transport-Security,X-Content-Type-Options等。图1 图2
X-XSS-Protection:
1://打开防护,此时攻击时候script就插入了空的标签
1;mode=block://打开防护,通知浏览器阻止而不是过滤用户脚本,不会插入script标签
1;report='http://www.baidu.com'://把错误发送到指定URL,webkit/opera都支持
0://表示关闭浏览器对XSS防护!
Content-Security-Policy:
以前是x-webkit-csp,;x-content-security-policy
<meta http-equiv="content-security-policy" content="script-src 'self' http://localhost:8080">font-src;frame-src;img-src;media-src;object-src;style-src;default-src;report-uri此时若不指定font-src那么也限制在default-src中,多个directive要用分好隔开。
X-Frame-Options(deny/sameOrgion/url):
现在正在使用,但以后可能被CSP的frame-ancestor代替,但是目前比frame-ancestor好,deny不允许被iframe, sameOrigion同源,uri特定url加载
Strict-transport-security:
如果在响应头中包含标记,从客户端到服务端都会加密。strict-transport-security:max-age=3600;includeSubDomains其中includeSubDomain表示是否对子域加密。
X-Content-Type-Options:
X-Content-Type-Options头允许你更有效的告知浏览器你知道你在做什么,当它的值为“nosniff”是才表明Content-Type是正确的。
iframe沙箱模式:
allow-script:仅仅允许执行脚本
allow-form:仅运行提交表单
allow-same-origion:同源
"":表示没有限制
问题25:AMD规范和CMD规范的区别?
(1)除了解决命名冲突和依赖管理,使用 Sea.js 进行模块化开发还可以带来很多好处:
模块的版本管理。通过别名等配置,配合构建工具,可以比较轻松地实现模块的版本管理。
(2)提高可维护性。模块化可以让每个文件的职责单一,非常有利于代码的维护。Sea.js 还提供了 nocache、debug 等插件,拥有在线调试等功能,能比较明显地提升效率。
(3)前端性能优化。Sea.js 通过异步加载模块,这对页面性能非常有益。Sea.js 还提供了 combo、flush 等插件,配合服务端,可以很好地对页面性能进行调优。
(4)跨环境共享模块。CMD 模块定义规范与 Node.js 的模块规范非常相近。通过 Sea.js 的 Node.js 版本,可以很方便实现模块的跨服务器和浏览器共享。简称”维跨优化冲依版“
AMD 是 RequireJS 在推广过程中对模块定义的规范化产出。
CMD 是 SeaJS 在推广过程中对模块定义的规范化产出。
类似的还有 CommonJS Modules/2.0 规范,是 BravoJS 在推广过程中对模块定义的规范化产出。
这些规范的目的都是为了 JavaScript 的模块化开发,特别是在浏览器端的。目前这些规范的实现都能达成浏览器端模块化开发的目的。
区别:
1. 对于依赖的模块,AMD 是提前执行,CMD 是延迟执行。
不过 RequireJS 从 2.0 开始,也改成可以延迟执行(根据写法不同,处理方式不同)。CMD 推崇 as lazy as possible.
2. CMD 推崇依赖就近,AMD 推崇依赖前置。看代码:
// CMD
define(function(require, exports, module) {
var a = require('./a')
a.doSomething()
// 此处略去 100 行
var b = require('./b') // 依赖可以就近书写
b.doSomething()
// ...
})
// AMD 默认推荐的是
define(['./a', './b'], function(a, b) { // 依赖必须一开始就写好
a.doSomething()
// 此处略去 100 行
b.doSomething()
...
}) 3. AMD 的 API 默认是一个当多个用,CMD 的 API 严格区分,推崇职责单一。比如 AMD 里,require 分全局 require 和局部 require,都叫 require。CMD 里,没有全局 require,而是根据模块系统的完备性,提供 seajs.use 来实现模块系统的加载启动。CMD 里,每个 API 都简单纯粹。 commonJS。CommonJS 是javascript模块化编程的一种规范,主要是在服务器端模块化的规范,一 个单独的文件就是一个模块。每一个模块都是一个单独的作用域,也就是说,在该模块内部定义的变量,无法被其他模块读取, 除非定义为global对象的属性。CommonJS加载模块是 同步的,只有加载完成,才能执行后面的操作,主要是由于服务端的编程模块文件都存在于本地硬盘,所以加载较快。
4.CMD规范与CommonJs和Node.js的模块规范保持很大的兼容性,通过CMD的规范书写的模块可以很容易的在Nodejs中运行,而且CMD有调试接口!
注意:CommonJS是一种规范,NodeJS是这种规范的实现。commonJS规范的提出是为了弥补当前js没有标准的缺陷,以达到像python,java,ruby等具备开发大型应用的基础能力,而不是停留在小脚本的阶段。他们期望用commonJS写出的应用可以具备跨域宿主环境执行的能力,这样不仅可以利用js开发富客户端应用,而且还可以编写一下应用:
服务器端js应用程序;命令行工具;桌面图形桌面应用程序。node借助于commonjs的模块规范实现了一套非常易用的模块系统。

commonjs是用在服务器端的,同步的,如nodejs ;amd, cmd是用在浏览器端的,异步的,如requirejs和seajs ;其中,amd先提出,cmd是根据commonjs和amd基础上提出的。commonjs规范推荐每一个文件就是一个模块,而且有独立的作用域,除非明确指定为global对象的属性。
问题26:ECMA6你了解多少?
(1)let关键字可以产生块级作用域,不像var那么产生变量覆盖,因为var的作用域是整个函数(详见本文),同时let不存在变量类型声明提升,同时let能避免循环变量不成为全部变量!
var a = [];
for (let i = 0; i < 10; i++) {
a[i] = function () {
console.log(i);
};
}
a[1]();
a[2]();
a[3]();
输出 1, 2,3let不会导致声明提升的作用,详见http://www.cnblogs.com/cnblogsfans/p/5157810.html
console.log(x);
console.log(y);
var x = 1;
let y = 2;
# 输出
undefined
ReferenceError: y is not defined(2)可以设置默认参数
function test(x=0,y=0)
{
console.log("x="+x+"y="+y);
}
test();(3)不严格的解析 如let[x,y]=[3,4,5]//x=3,y=4
(4)多行语句用范引号设置var x=`xhtml`
(5)可用内嵌模块var x=12,var msg=`your age is $(x)`;
问题27:能不能实现一个IOS开关?
window.οnlοad=function(){
var div2=document.getElementById("div2");
var div1=document.getElementById("div1");
div2.οnclick=function(){
div1.className=(div1.className=="close1")?"open1":"close1";
div2.className=(div2.className=="close2")?"open2":"close2";
}
}
#div1{
width: 170px;
height: 100px;
border-radius: 50px;
position: relative;
}
#div2{
width: 96px;
height: 96px;
border-radius: 48px;
position: absolute;
background: white;
box-shadow: 0px 2px 4px rgba(0,0,0,0.4);
}
/*大的div*/
.open1{
background: rgba(0,184,0,0.8);
}
/*小的div*/
.open2{
top: 2px;
right: 1px;
}
.close1{
background: rgba(255,255,255,0.4);
border:3px solid rgba(0,0,0,0.15);
border-left: transparent;
}
.close2{
left: 0px;
top: 0px;
border:2px solid rgba(0,0,0,0.1);
} <div id="div1" class="open1">
<div id="div2" class="open2"></div>
</div>问题28:contains和compareDocumentPosition区别和使用
前者只能判断两个节点是否包含关系,而后者可以判断两者是否无关,居前,居后等关系;同时后者在IE9+浏览器才会支持,但是前者对IE所有的版本都是支持的!对于两种都不支持的浏览器只能用遍历parentNode的方法来确定
var dom=document.documentElement;
var body=document.body;
console.log(!!(dom.compareDocumentPosition(body)&16));问题29:什么是文档流?
将窗体自上而下分成一行行, 并在每行中按从左至右的顺序排放元素,即为文档流.
问题30:float类型的数据精度丢失?
问题31:数组和链表的区别?
(1) 从逻辑结构角度来看
a, 数组必须事先定义固定的长度(元素个数),不能适应数据动态地增减的情况。当数据增加时,可能超出原先定义的元素个数;当数据减少时,造成内存浪费。
b,链表动态地进行存储分配,可以适应数据动态地增减的情况,且可以方便地插入、删除数据项。(数组中插入、删除数据项时,需要移动其它数据项)
(2)从内存存储角度来看
a,(静态)数组从栈中分配空间, 对于程序员方便快速,但自由度小。
b, 链表从堆中分配空间, 自由度大但申请管理比较麻烦.
问题32:HTTP状态码有那些?
这要从搜索引擎如何处理302转向说起。从定义来说,从网址A做一个302重定向到网址B时,主机服务器的隐含意思是网址A随时有可能改主意,重新显示本身的内容或转向其他的地方。大部分的搜索引擎在大部分情况下,当收到302重定向时,一般只要去抓取目标网址就可以了,也就是说网址B。实际上如果搜索引擎在遇到302转向时,百分之百的都抓取目标网址B的话,就不用担心网址URL劫持了。问题就在于,有的时候搜索引擎,尤其是Google,并不能总是抓取目标网址。为什么呢?比如说,有的时候A网址很短,但是它做了一个302重定向到B网址,而B网址是一个很长的乱七八糟的URL网址,甚至还有可能包含一些问号之类的参数。很自然的,A网址更加用户友好,而B网址既难看,又不用户友好。这时Google很有可能会仍然显示网址A。网址劫持(URL hijacking)
状态码 含义
100 客户端应当继续发送请求。这个临时响应是用来通知客户端它的部分请求已经被服务器接收,且仍未被拒绝。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。服务器必须在请求完成后向客户端发送一个最终响应。
101 服务器已经理解了客户端的请求,并将通过Upgrade 消息头通知客户端采用不同的协议来完成这个请求。在发送完这个响应最后的空行后,服务器将会切换到在Upgrade 消息头中定义的那些协议。 只有在切换新的协议更有好处的时候才应该采取类似措施。例如,切换到新的HTTP 版本比旧版本更有优势,或者切换到一个实时且同步的协议以传送利用此类特性的资源。
102 由WebDAV(RFC 2518)扩展的状态码,代表处理将被继续执行。
200 请求已成功,请求所希望的响应头或数据体将随此响应返回。
201 请求已经被实现,而且有一个新的资源已经依据请求的需要而建立,且其 URI 已经随Location 头信息返回。假如需要的资源无法及时建立的话,应当返回 '202 Accepted'。
202 服务器已接受请求,但尚未处理。正如它可能被拒绝一样,最终该请求可能会也可能不会被执行。在异步操作的场合下,没有比发送这个状态码更方便的做法了。 返回202状态码的响应的目的是允许服务器接受其他过程的请求(例如某个每天只执行一次的基于批处理的操作),而不必让客户端一直保持与服务器的连接直到批处理操作全部完成。在接受请求处理并返回202状态码的响应应当在返回的实体中包含一些指示处理当前状态的信息,以及指向处理状态监视器或状态预测的指针,以便用户能够估计操作是否已经完成。
203 服务器已成功处理了请求,但返回的实体头部元信息不是在原始服务器上有效的确定集合,而是来自本地或者第三方的拷贝。当前的信息可能是原始版本的子集或者超集。例如,包含资源的元数据可能导致原始服务器知道元信息的超级。使用此状态码不是必须的,而且只有在响应不使用此状态码便会返回200 OK的情况下才是合适的。
204 服务器成功处理了请求,但不需要返回任何实体内容,并且希望返回更新了的元信息。响应可能通过实体头部的形式,返回新的或更新后的元信息。如果存在这些头部信息,则应当与所请求的变量相呼应。 如果客户端是浏览器的话,那么用户浏览器应保留发送了该请求的页面,而不产生任何文档视图上的变化,即使按照规范新的或更新后的元信息应当被应用到用户浏览器活动视图中的文档。 由于204响应被禁止包含任何消息体,因此它始终以消息头后的第一个空行结尾。
205 服务器成功处理了请求,且没有返回任何内容。但是与204响应不同,返回此状态码的响应要求请求者重置文档视图。该响应主要是被用于接受用户输入后,立即重置表单,以便用户能够轻松地开始另一次输入。 与204响应一样,该响应也被禁止包含任何消息体,且以消息头后的第一个空行结束。
206 服务器已经成功处理了部分 GET 请求。类似于 FlashGet 或者迅雷这类的 HTTP 下载工具都是使用此类响应实现断点续传或者将一个大文档分解为多个下载段同时下载。 该请求必须包含 Range 头信息来指示客户端希望得到的内容范围,并且可能包含 If-Range 来作为请求条件。 响应必须包含如下的头部域: Content-Range 用以指示本次响应中返回的内容的范围;如果是 Content-Type 为 multipart/byteranges 的多段下载,则每一 multipart 段中都应包含 Content-Range 域用以指示本段的内容范围。假如响应中包含 Content-Length,那么它的数值必须匹配它返回的内容范围的真实字节数。 Date ETag 和/或 Content-Location,假如同样的请求本应该返回200响应。 Expires, Cache-Control,和/或 Vary,假如其值可能与之前相同变量的其他响应对应的值不同的话。 假如本响应请求使用了 If-Range 强缓存验证,那么本次响应不应该包含其他实体头;假如本响应的请求使用了 If-Range 弱缓存验证,那么本次响应禁止包含其他实体头;这避免了缓存的实体内容和更新了的实体头信息之间的不一致。否则,本响应就应当包含所有本应该返回200响应中应当返回的所有实体头部域。 假如 ETag 或 Last-Modified 头部不能精确匹配的话,则客户端缓存应禁止将206响应返回的内容与之前任何缓存过的内容组合在一起。 任何不支持 Range 以及 Content-Range 头的缓存都禁止缓存206响应返回的内容。
207 由WebDAV(RFC 2518)扩展的状态码,代表之后的消息体将是一个XML消息,并且可能依照之前子请求数量的不同,包含一系列独立的响应代码。
300 被请求的资源有一系列可供选择的回馈信息,每个都有自己特定的地址和浏览器驱动的商议信息。用户或浏览器能够自行选择一个首选的地址进行重定向。 除非这是一个 HEAD 请求,否则该响应应当包括一个资源特性及地址的列表的实体,以便用户或浏览器从中选择最合适的重定向地址。这个实体的格式由 Content-Type 定义的格式所决定。浏览器可能根据响应的格式以及浏览器自身能力,自动作出最合适的选择。当然,RFC 2616规范并没有规定这样的自动选择该如何进行。 如果服务器本身已经有了首选的回馈选择,那么在 Location 中应当指明这个回馈的 URI;浏览器可能会将这个 Location 值作为自动重定向的地址。此外,除非额外指定,否则这个响应也是可缓存的。
301 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个 URI 之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。 新的永久性的 URI 应当在响应的 Location 域中返回。除非这是一个 HEAD 请求,否则响应的实体中应当包含指向新的 URI 的超链接及简短说明。 如果这不是一个 GET 或者 HEAD 请求,因此浏览器禁止自动进行重定向,除非得到用户的确认,因为请求的条件可能因此发生变化。 注意:对于某些使用 HTTP/1.0 协议的浏览器,当它们发送的 POST 请求得到了一个301响应的话,接下来的重定向请求将会变成 GET 方式。
302 请求的资源现在临时从不同的 URI 响应请求。由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。只有在Cache-Control或Expires中进行了指定的情况下,这个响应才是可缓存的。 新的临时性的 URI 应当在响应的 Location 域中返回。除非这是一个 HEAD 请求,否则响应的实体中应当包含指向新的 URI 的超链接及简短说明。 如果这不是一个 GET 或者 HEAD 请求,那么浏览器禁止自动进行重定向,除非得到用户的确认,因为请求的条件可能因此发生变化。 注意:虽然RFC 1945和RFC 2068规范不允许客户端在重定向时改变请求的方法,但是很多现存的浏览器将302响应视作为303响应,并且使用 GET 方式访问在 Location 中规定的 URI,而无视原先请求的方法。状态码303和307被添加了进来,用以明确服务器期待客户端进行何种反应。
303 对应当前请求的响应可以在另一个 URI 上被找到,而且客户端应当采用 GET 的方式访问那个资源。这个方法的存在主要是为了允许由脚本激活的POST请求输出重定向到一个新的资源。这个新的 URI 不是原始资源的替代引用。同时,303响应禁止被缓存。当然,第二个请求(重定向)可能被缓存。 新的 URI 应当在响应的 Location 域中返回。除非这是一个 HEAD 请求,否则响应的实体中应当包含指向新的 URI 的超链接及简短说明。 注意:许多 HTTP/1.1 版以前的 浏览器不能正确理解303状态。如果需要考虑与这些浏览器之间的互动,302状态码应该可以胜任,因为大多数的浏览器处理302响应时的方式恰恰就是上述规范要求客户端处理303响应时应当做的。
304 如果客户端发送了一个带条件的 GET 请求且该请求已被允许,而文档的内容(自上次访问以来或者根据请求的条件)并没有改变,则服务器应当返回这个状态码。304响应禁止包含消息体,因此始终以消息头后的第一个空行结尾。 该响应必须包含以下的头信息: Date,除非这个服务器没有时钟。假如没有时钟的服务器也遵守这些规则,那么代理服务器以及客户端可以自行将 Date 字段添加到接收到的响应头中去(正如RFC 2068中规定的一样),缓存机制将会正常工作。 ETag 和/或 Content-Location,假如同样的请求本应返回200响应。 Expires, Cache-Control,和/或Vary,假如其值可能与之前相同变量的其他响应对应的值不同的话。 假如本响应请求使用了强缓存验证,那么本次响应不应该包含其他实体头;否则(例如,某个带条件的 GET 请求使用了弱缓存验证),本次响应禁止包含其他实体头;这避免了缓存了的实体内容和更新了的实体头信息之间的不一致。 假如某个304响应指明了当前某个实体没有缓存,那么缓存系统必须忽视这个响应,并且重复发送不包含限制条件的请求。 假如接收到一个要求更新某个缓存条目的304响应,那么缓存系统必须更新整个条目以反映所有在响应中被更新的字段的值。
305 被请求的资源必须通过指定的代理才能被访问。Location 域中将给出指定的代理所在的 URI 信息,接收者需要重复发送一个单独的请求,通过这个代理才能访问相应资源。只有原始服务器才能建立305响应。 注意:RFC 2068中没有明确305响应是为了重定向一个单独的请求,而且只能被原始服务器建立。忽视这些限制可能导致严重的安全后果。
306 在最新版的规范中,306状态码已经不再被使用。
307 请求的资源现在临时从不同的URI 响应请求。由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。只有在Cache-Control或Expires中进行了指定的情况下,这个响应才是可缓存的。 新的临时性的URI 应当在响应的 Location 域中返回。除非这是一个HEAD 请求,否则响应的实体中应当包含指向新的URI 的超链接及简短说明。因为部分浏览器不能识别307响应,因此需要添加上述必要信息以便用户能够理解并向新的 URI 发出访问请求。 如果这不是一个GET 或者 HEAD 请求,那么浏览器禁止自动进行重定向,除非得到用户的确认,因为请求的条件可能因此发生变化。
400 1、语义有误,当前请求无法被服务器理解。除非进行修改,否则客户端不应该重复提交这个请求。 2、请求参数有误。
401 当前请求需要用户验证。该响应必须包含一个适用于被请求资源的 WWW-Authenticate 信息头用以询问用户信息。客户端可以重复提交一个包含恰当的 Authorization 头信息的请求。如果当前请求已经包含了 Authorization 证书,那么401响应代表着服务器验证已经拒绝了那些证书。如果401响应包含了与前一个响应相同的身份验证询问,且浏览器已经至少尝试了一次验证,那么浏览器应当向用户展示响应中包含的实体信息,因为这个实体信息中可能包含了相关诊断信息。参见RFC 2617。
402 该状态码是为了将来可能的需求而预留的。
403 服务器已经理解请求,但是拒绝执行它。与401响应不同的是,身份验证并不能提供任何帮助,而且这个请求也不应该被重复提交。如果这不是一个 HEAD 请求,而且服务器希望能够讲清楚为何请求不能被执行,那么就应该在实体内描述拒绝的原因。当然服务器也可以返回一个404响应,假如它不希望让客户端获得任何信息。
404 请求失败,请求所希望得到的资源未被在服务器上发现。没有信息能够告诉用户这个状况到底是暂时的还是永久的。假如服务器知道情况的话,应当使用410状态码来告知旧资源因为某些内部的配置机制问题,已经永久的不可用,而且没有任何可以跳转的地址。404这个状态码被广泛应用于当服务器不想揭示到底为何请求被拒绝或者没有其他适合的响应可用的情况下。
405 请求行中指定的请求方法不能被用于请求相应的资源。该响应必须返回一个Allow 头信息用以表示出当前资源能够接受的请求方法的列表。 鉴于 PUT,DELETE 方法会对服务器上的资源进行写操作,因而绝大部分的网页服务器都不支持或者在默认配置下不允许上述请求方法,对于此类请求均会返回405错误。
406 请求的资源的内容特性无法满足请求头中的条件,因而无法生成响应实体。 除非这是一个 HEAD 请求,否则该响应就应当返回一个包含可以让用户或者浏览器从中选择最合适的实体特性以及地址列表的实体。实体的格式由 Content-Type 头中定义的媒体类型决定。浏览器可以根据格式及自身能力自行作出最佳选择。但是,规范中并没有定义任何作出此类自动选择的标准。
407 与401响应类似,只不过客户端必须在代理服务器上进行身份验证。代理服务器必须返回一个 Proxy-Authenticate 用以进行身份询问。客户端可以返回一个 Proxy-Authorization 信息头用以验证。参见RFC 2617。
408 请求超时。客户端没有在服务器预备等待的时间内完成一个请求的发送。客户端可以随时再次提交这一请求而无需进行任何更改。
409 由于和被请求的资源的当前状态之间存在冲突,请求无法完成。这个代码只允许用在这样的情况下才能被使用:用户被认为能够解决冲突,并且会重新提交新的请求。该响应应当包含足够的信息以便用户发现冲突的源头。 冲突通常发生于对 PUT 请求的处理中。例如,在采用版本检查的环境下,某次 PUT 提交的对特定资源的修改请求所附带的版本信息与之前的某个(第三方)请求向冲突,那么此时服务器就应该返回一个409错误,告知用户请求无法完成。此时,响应实体中很可能会包含两个冲突版本之间的差异比较,以便用户重新提交归并以后的新版本。
410 被请求的资源在服务器上已经不再可用,而且没有任何已知的转发地址。这样的状况应当被认为是永久性的。如果可能,拥有链接编辑功能的客户端应当在获得用户许可后删除所有指向这个地址的引用。如果服务器不知道或者无法确定这个状况是否是永久的,那么就应该使用404状态码。除非额外说明,否则这个响应是可缓存的。 410响应的目的主要是帮助网站管理员维护网站,通知用户该资源已经不再可用,并且服务器拥有者希望所有指向这个资源的远端连接也被删除。这类事件在限时、增值服务中很普遍。同样,410响应也被用于通知客户端在当前服务器站点上,原本属于某个个人的资源已经不再可用。当然,是否需要把所有永久不可用的资源标记为'410 Gone',以及是否需要保持此标记多长时间,完全取决于服务器拥有者。
411 服务器拒绝在没有定义 Content-Length 头的情况下接受请求。在添加了表明请求消息体长度的有效 Content-Length 头之后,客户端可以再次提交该请求。
412 服务器在验证在请求的头字段中给出先决条件时,没能满足其中的一个或多个。这个状态码允许客户端在获取资源时在请求的元信息(请求头字段数据)中设置先决条件,以此避免该请求方法被应用到其希望的内容以外的资源上。
413 服务器拒绝处理当前请求,因为该请求提交的实体数据大小超过了服务器愿意或者能够处理的范围。此种情况下,服务器可以关闭连接以免客户端继续发送此请求。 如果这个状况是临时的,服务器应当返回一个 Retry-After 的响应头,以告知客户端可以在多少时间以后重新尝试。
414 请求的URI 长度超过了服务器能够解释的长度,因此服务器拒绝对该请求提供服务。这比较少见,通常的情况包括: 本应使用POST方法的表单提交变成了GET方法,导致查询字符串(Query String)过长。 重定向URI “黑洞”,例如每次重定向把旧的 URI 作为新的 URI 的一部分,导致在若干次重定向后 URI 超长。 客户端正在尝试利用某些服务器中存在的安全漏洞攻击服务器。这类服务器使用固定长度的缓冲读取或操作请求的 URI,当 GET 后的参数超过某个数值后,可能会产生缓冲区溢出,导致任意代码被执行[1]。没有此类漏洞的服务器,应当返回414状态码。
415 对于当前请求的方法和所请求的资源,请求中提交的实体并不是服务器中所支持的格式,因此请求被拒绝。
416 如果请求中包含了 Range 请求头,并且 Range 中指定的任何数据范围都与当前资源的可用范围不重合,同时请求中又没有定义 If-Range 请求头,那么服务器就应当返回416状态码。 假如 Range 使用的是字节范围,那么这种情况就是指请求指定的所有数据范围的首字节位置都超过了当前资源的长度。服务器也应当在返回416状态码的同时,包含一个 Content-Range 实体头,用以指明当前资源的长度。这个响应也被禁止使用 multipart/byteranges 作为其 Content-Type。
417 在请求头 Expect 中指定的预期内容无法被服务器满足,或者这个服务器是一个代理服务器,它有明显的证据证明在当前路由的下一个节点上,Expect 的内容无法被满足。
421 从当前客户端所在的IP地址到服务器的连接数超过了服务器许可的最大范围。通常,这里的IP地址指的是从服务器上看到的客户端地址(比如用户的网关或者代理服务器地址)。在这种情况下,连接数的计算可能涉及到不止一个终端用户。
422 从当前客户端所在的IP地址到服务器的连接数超过了服务器许可的最大范围。通常,这里的IP地址指的是从服务器上看到的客户端地址(比如用户的网关或者代理服务器地址)。在这种情况下,连接数的计算可能涉及到不止一个终端用户。
422 请求格式正确,但是由于含有语义错误,无法响应。(RFC 4918 WebDAV)423 Locked 当前资源被锁定。(RFC 4918 WebDAV)
424 由于之前的某个请求发生的错误,导致当前请求失败,例如 PROPPATCH。(RFC 4918 WebDAV)
425 在WebDav Advanced Collections 草案中定义,但是未出现在《WebDAV 顺序集协议》(RFC 3658)中。
426 客户端应当切换到TLS/1.0。(RFC 2817)
449 由微软扩展,代表请求应当在执行完适当的操作后进行重试。
500 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器的程序码出错时出现。
501 服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。
502 作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
503 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是临时的,并且将在一段时间以后恢复。如果能够预计延迟时间,那么响应中可以包含一个 Retry-After 头用以标明这个延迟时间。如果没有给出这个 Retry-After 信息,那么客户端应当以处理500响应的方式处理它。 注意:503状态码的存在并不意味着服务器在过载的时候必须使用它。某些服务器只不过是希望拒绝客户端的连接。
504 作为网关或者代理工作的服务器尝试执行请求时,未能及时从上游服务器(URI标识出的服务器,例如HTTP、FTP、LDAP)或者辅助服务器(例如DNS)收到响应。 注意:某些代理服务器在DNS查询超时时会返回400或者500错误
505 服务器不支持,或者拒绝支持在请求中使用的 HTTP 版本。这暗示着服务器不能或不愿使用与客户端相同的版本。响应中应当包含一个描述了为何版本不被支持以及服务器支持哪些协议的实体。
506 由《透明内容协商协议》(RFC 2295)扩展,代表服务器存在内部配置错误:被请求的协商变元资源被配置为在透明内容协商中使用自己,因此在一个协商处理中不是一个合适的重点。
507 服务器无法存储完成请求所必须的内容。这个状况被认为是临时的。WebDAV (RFC 4918)
509 服务器达到带宽限制。这不是一个官方的状态码,但是仍被广泛使用。
510 获取资源所需要的策略并没有没满足。(RFC 2774)
问题33:JSON和XML的区别?
JSON与XML的区别比较
1.定义介绍
(1).XML定义
扩展标记语言 (Extensible Markup Language, XML) ,用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。 XML使用DTD(document type definition)文档类型定义来组织数据;格式统一,跨平台和语言,早已成为业界公认的标准。
XML是标准通用标记语言 (SGML) 的子集,非常适合 Web 传输。XML 提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。
(2).JSON定义
JSON(JavaScript Object Notation)一种轻量级的数据交换格式,具有良好的可读和便于快速编写的特性。可在不同平台之间进行数据交换。JSON采用兼容性很高的、完全独立于语言文本格式,同时也具备类似于C语言的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等)体系的行为。这些特性使JSON成为理想的数据交换语言。
JSON基于JavaScript Programming Language , Standard ECMA-262 3rd Edition - December 1999 的一个子集。
2.XML和JSON优缺点
(1).XML的优缺点
<1>.XML的优点
A.格式统一,符合标准;
B.容易与其他系统进行远程交互,数据共享比较方便。
<2>.XML的缺点
A.XML文件庞大,文件格式复杂,传输占带宽;
B.服务器端和客户端都需要花费大量代码来解析XML,导致服务器端和客户端代码变得异常复杂且不易维护;
C.客户端不同浏览器之间解析XML的方式不一致,需要重复编写很多代码;
D.服务器端和客户端解析XML花费较多的资源和时间。
(2).JSON的优缺点
<1>.JSON的优点:
A.数据格式比较简单,易于读写,格式都是压缩的,占用带宽小;
B.易于解析,客户端JavaScript可以简单的通过eval()进行JSON数据的读取;
C.支持多种语言,包括ActionScript, C, C#, ColdFusion, Java, JavaScript, Perl, PHP, Python, Ruby等服务器端语言,便于服务器端的解析;
D.在PHP世界,已经有PHP-JSON和JSON-PHP出现了,偏于PHP序列化后的程序直接调用,PHP服务器端的对象、数组等能直接生成JSON格式,便于客户端的访问提取;
E.因为JSON格式能直接为服务器端代码使用,大大简化了服务器端和客户端的代码开发量,且完成任务不变,并且易于维护。
<2>.JSON的缺点
A.没有XML格式这么推广的深入人心和喜用广泛,没有XML那么通用性;
B.JSON格式目前在Web Service中推广还属于初级阶段。
3.XML和JSON的优缺点对比
(1).可读性方面。
JSON和XML的数据可读性基本相同,JSON和XML的可读性可谓不相上下,一边是建议的语法,一边是规范的标签形式,XML可读性较好些。
(2).可扩展性方面。
XML天生有很好的扩展性,JSON当然也有,没有什么是XML能扩展,JSON不能的。
(3).编码难度方面。
XML有丰富的编码工具,比如Dom4j、JDom等,JSON也有json.org提供的工具,但是JSON的编码明显比XML容易许多,即使不借助工具也能写出JSON的代码,可是要写好XML就不太容易了。
(4).解码难度方面。
XML的解析得考虑子节点父节点,让人头昏眼花,而JSON的解析难度几乎为0。这一点XML输的真是没话说。
(5).流行度方面。
XML已经被业界广泛的使用,而JSON才刚刚开始,但是在Ajax这个特定的领域,未来的发展一定是XML让位于JSON。到时Ajax应该变成Ajaj(Asynchronous Javascript and JSON)了。
(6).解析手段方面。
JSON和XML同样拥有丰富的解析手段。
(7).数据体积方面。
JSON相对于XML来讲,数据的体积小,传递的速度更快些。
(8).数据交互方面。
JSON与JavaScript的交互更加方便,更容易解析处理,更好的数据交互。
(9).数据描述方面。
JSON对数据的描述性比XML较差。
(10).传输速度方面。
JSON的速度要远远快于XML。
手写JSON,那么不能有var,不能有分号,必须有双引号!
问题34:前端优化规则?
详见前端性能优化----yahoo前端性能团队总结的35条黄金定律 HTTP次数;DNS次数(域名2-4个);CDN;服务器(GZIP,cache-control, ETag, Cookie)。服务器回应的HTTP头:content-type, content-encoding, content-length等
问题35:手写一个自定义事件?
window.οnlοad=function()
{
// 创建事件
var evt = document.createEvent('Event');
// 定义事件类型,Type,Bubble,cancellable
evt.initEvent('customEvent', true, true);
// 在元素上监听事件
var obj = document.getElementById('testBox');
event.view=document.defaultView;
//只能使用通用事件,因为UI事件不能为event添加属性,SF除外
//其它浏览器还可以用createElement时候传入MouseEvents,keyboardEvents等
obj.addEventListener('customEvent', function(){
console.log('customEvent 事件触发了');
}, false);
obj.dispatchEvent(evt)
}最后一个问题:你觉得自己的缺点是什么?
问题36:什么是coffeScript?
coffeescript 是一门新语言,是javascript 预编译器。由它生成的javascript 代码能兼容所有浏览器环境,可读性更强、更优雅。也许 JavaScript 就是下一个 JVM, 上面会有最适用于各种场景的各种语言. 很多人盼望 JavaScript 成为为未来的唯一语言, 看起来这是不切实际的幻想了.CoffeeScript 只使用了 JavaScript 的 ”Good Parts(精粹)”, 抛弃了原来 JavaScript 晦涩的,容易出问题的那部分东西. 比如,全局变量声明, with 等.CoffeeScript 还提供了一个机会, 让你现在就可以使用 ECMAScript 里面的特性. 将来有个更多新特性, CoffeeScript 也有机会在浏览器支持之前实现它们. 程序员面对的是 CoffeeScript 的优雅接口, 它是程序员和JavaScript 之间的中间层, 脏活累活它都干了.
问题37:jpg,png,gif等差别
(1)有损压缩jpg和无损压缩png
有损压缩:照我的理解有损压缩就是在存储图像的时候并不完全真实的记录图像上每个像素点的数据信息,它会根据人眼观察现实世界的特性(人眼对光线的敏感度比对颜色的敏感度要高,生物实验证明当颜色缺失时人脑会利用与附近最接近的颜色来自动填补缺失的颜色)对图像数据进行处理,去掉那些图像上会被人眼忽略的细节,然后使用附近的颜色通过渐变或其他形式进行填充。这样既能大大降低图像信息的数据量,又不会影响图像的还原效果。
无损压缩:PNG是我们最常见的一种采用无损压缩的图片格式。无损压缩在存储图像前会先判断图像上哪些地方是相同的哪些地方是不同的,为此需要对图像上所有出现的颜色进行索引(如上图),我们把称这些颜色称为索引色。索引色就好比绘制这幅图像的“调色版”,PNG在显示图像的时候则会用“调色版”上的这些颜色去填充相应的位置。PNG采用的是无损压缩为什么我们保存的PNG格式图片还会有失真呢?这是因为无损压缩只是说它的压缩方式会尽可能真实的还原图像,但从它的压缩原理我们可以知道它是通过索引图像上相同区域的颜色进行压缩和还原的,这就意味着只有在图像上出现的颜色数量小于我们可以保存的颜色数量时,我们才能真实的记录和还原图像,否则就会丢失一些图像信息(PNG8最多只能索引256种颜色,所以对于颜色较多的图像不能真实还原;PNG24则可以保存1600多万种颜色,基本能够真实还原我们人类肉眼所可以分别的所有颜色;PNG格式最多可以保存48位颜色通道)。而对于有损压缩来说,不管图像上的颜色多少,都会损失图像信息。
另外这里我们也不对GIF进行讨论,是因为PNG就是为取代GIF而生的,而且PNG的压缩算法也要优于GIF,所以只要不是需要动画效果的地方强烈建议都采用PNG格式图片。
JPG的特性(不支持透明)
1、支持摄影图像或写实图像的高级压缩,并且可利用压缩比例控制图像文件大小。
2、有损压缩会使图像数据质量下降,并且在编辑和重新保存JPG格式图像时,这种下降损失会累积。
3、JPG不适用于所含颜色很少、具有大块颜色相近的区域或亮度差异十分明显的较简单的图片。
PNG的特性
1、能在保证最不失真的情况下尽可能压缩图像文件的大小。
2、PNG用来存储灰度图像时,灰度图像的深度可多到16位,存储彩色图像时,彩色图像的深度可多到48位,并且还可存储多到16位的α通道数据。
3、对于需要高保真的较复杂的图像,PNG虽然能无损压缩,但图片文件较大,不适合应用在Web页面上。
JPEG的文件格式一般有两种文件扩展名:.jpg和.jpeg,这两种扩展名的实质是相同的,我们可以把*.jpg的文件改名为*.jpeg,而对文件本身不会有任何影响。就像.html和.htm一样。WebP格式,谷歌(google)开发的一种旨在加快图片加载速度的图片格式。图片压缩体积大约只有JPEG的2/3,并能节省大量的服务器带宽资源和数据空间。Facebook Ebay等知名网站已经开始测试并使用WebP格式。但WebP是一种有损压缩。相较编码JPEG文件,编码同样质量的WebP文件需要占用更多的计算资源。(WebP格式图像的编码时间“比JPEG格式图像长8倍”。)
问题38:canvas和svg的差别
更多内容参见svg官方网站
- SVG 指可伸缩矢量图形 (Scalable Vector Graphics)
- SVG 用来定义用于网络的基于矢量的图形
- SVG 使用 XML 格式定义图形
- SVG 图像在放大或改变尺寸的情况下其图形质量不会有所损失
- SVG 是万维网联盟的标准
- SVG 与诸如 DOM 和 XSL 之类的 W3C 标准是一个整体
与其他图像格式相比,使用 SVG 的优势在于:
- SVG 可被非常多的工具读取和修改(比如记事本)
- SVG 与 JPEG 和 GIF 图像比起来,尺寸更小,且可压缩性更强。
- SVG 是可伸缩的
- SVG 图像可在任何的分辨率下被高质量地打印
- SVG 可在图像质量不下降的情况下被放大
- SVG 图像中的文本是可选的,同时也是可搜索的(很适合制作地图)
- SVG 可以与 Java 技术一起运行
- SVG 是开放的标准
- SVG 文件是纯粹的 XML
SVG
SVG 是一种使用 XML 描述 2D 图形的语言。SVG 基于 XML,这意味着 SVG DOM 中的每个元素都是可用的。您可以为某个元素附加 JavaScript 事件处理器。
在 SVG 中,每个被绘制的图形均被视为对象。如果 SVG 对象的属性发生变化,那么浏览器能够自动重现图形。
Canvas
Canvas 通过 JavaScript 来绘制 2D 图形。Canvas 是逐像素进行渲染的。在 canvas 中,一旦图形被绘制完成,它就不会继续得到浏览器的关注。如果其位置发生变化,那么整个场景也需要重新绘制,包括任何或许已被图形覆盖的对象。
Canvas 与 SVG 的比较
下表列出了 canvas 与 SVG 之间的一些不同之处。
Canvas
依赖分辨率
不支持事件处理器
弱的文本渲染能力
能够以 .png 或 .jpg 格式保存结果图像
最适合图像密集型的游戏,其中的许多对象会被频繁重绘
SVG
不依赖分辨率
支持事件处理器
最适合带有大型渲染区域的应用程序(比如谷歌地图,管理评论的稿件处理流程)
复杂度高会减慢渲染速度(任何过度使用 DOM 的应用都不快)
不适合游戏应用。总之:“处理器分辨率变化”
(1)svg可以用img,embed,object,iframe等显示
<img src='sun.svg'/>//现在只有chrome,safari,opera支持
<embed src='sun.svg' width='300' height='100' type='image/svg+xml' pluginspage='http://www.adobe.com/svg/viewer/install'/>
//其中pluginspage是Adobe公司为不原生支持svg浏览器开发的插件
<object data='sun.svg' type='image/svg+xml' codebase="http://www.adobe.com/svg/viewer/install'"/>
//这里用的是data而不是src,用的codebase而不是pluginpage!
<iframe src='sun.svg'/>(3)svg是一个xml文件,用于XML编程的DOM和Sax同样适用于他。为HTML5中svg可以在HTML直接定义就像HTML元素一样。svg中的g标签用于分组,使得内容更加清晰,而且同一组内的对象可以集体操作
(4) html5中不需要在html/svg中指定命名空间,标签会被自动识别。IE6/7/8对svg没有原生支持,要通过专门的插件,IE9支持原生的
(5)svg作为通用的数据格式,属于XML语言的一个分支,主要负责矢量图的数据结构关系!
问题39:获取元素的第n级别的节点?
<div id="n">
<div id="n1">
<div id="n11">
<div id="n111">
<div id="n1111"></div>
<div id="n1112"></div>
</div>
<div id="n112"></div>
<div id="n113"></div>
</div>
<div id="n12"></div>
</div>
<div id="n2"></div>
<div id="n3"></div>
</div>//遍历所有的子元素集合,然后把子元素的所有下级元素返回!
function getNodes(nodes)
{
var newNodes=[];
for(var i=0,len=nodes.length;i<len;i++)
{
newNodes=newNodes.concat(Array.prototype.slice.call(nodes[i].children));
}
return newNodes;
}
function getChildren(node,n)
{
var times=n;
var children=node.children;
//获取所有元素
var result=[];
//保存结果
result[n]=children;
//保存第一次
n--;
result[n]=getNodes(children);
//遍历所有的子元素
while(n>0)
{
result[n-1]=getNodes.call(null,result[n]);
n--;
}
return result[result.length-times];
}(1)了解了需要那么做能提高性能,但是有些知识还是掌握的不牢靠,如chrome控制台如何看瀑布流自己还是没有琢磨透,所以每次还是要打开火狐浏览器。详见语言表达、仪表 好好复习把 web前端实习总结 我是如何同时拿到阿里和腾讯offer的
问题40:常见的css兼容问题(双边据bug; zIndex; max-width; PNG图片的布尔透明; IE6/7之前li圆点样式不显示;position为fixed; IE6下form的submit,overflow,padding-top+padding-bottom)?
3像素bug:ie下两个相邻的div之间会出现3个像素的bug,这个bug是在当对其中一个div使用了float,而另外一个没有使用时会出现。 解决方法:a.对另一个元素同时使用float; b.为已经浮动的div添加一条语句:margin-right:-3px; ;c:zoom设置也是可以的!
双边据bug:双边距的产生是由于float元素的浮动方向跟margin的方向一致导致的。也就是说float是left的时候,只有添加了margin-left才会产生双边距bug,要是添加了margin-right也不会产生这个bug。当有多个同行元素都浮动了,而且都有同方向的margin,则只有最靠近浮动方向的元素有双边距bug。
解决方法:
1、该元素加上 _display:inline。
2、_margin:一半的边距。
不支持max-width/height、min-width/heght:
有时候为了不让内部img图片过大撑开外层而影响布局,我们需要设置外层的overflow:hidden,但这样,里面的内容就被裁掉一块了。而设置滚动条的话又太难看,所以我们就要用到限定最大/小的高度和宽度。如你所想,IE6不识别这个。
不支持max-width/height的解决方法:
1、限宽的元素css中加上 _width: expression(this.offsetWidth > 500 ? "500px" : this.offsetWidth + "px") 。两个500修改为需要限定的值,限定高度同理:_height: expression(this.offsetHeight > 500 ? "500px" : this.offsetHeight + "px") 。该法css中使用了表达式,会导致很高的cpu占用率,不过高就高嘛,谁让你用ie6,卡死你!
2、js解决:
function resizeImg(img){
var image=new Image();
image.src = img.src;
if(image.width > 500 || image.width <= 0)
img.style.width = 500 + "px";
else
img.style.width = image.width + "px";
}
不支持min-width/height的解决方法:
1、利用IE6的特性,直接_width:500px或_height:500px即可,IE6中外层元素会自动被内容撑开而不管其设置的width/height。
2、同上max-width/height的解决方法。
png图片的alpha透明:
其它内容参见http://www.jackyrao.com/archives/94?ckattempt=1
z-index初探:
首先讲讲第一种z-index无论设置多高都不起作用情况。这种情况发生的条件有三个:1、父标签position属性为relative;2、问题标签无position属性(不包括static);3、问题标签含有浮动(float)属性。
可能不少人知道,这IE6下,层级的高低不仅要看自己,还要看自己的老爸这个后台是否够硬。用术语具体描述为
父标签position属性为relative或absolute时,子标签的absolute属性是相对于父标签而言的。而在IE6下,层级的表现有时候不是看子标签的z-index多高,而要看它们的父标签的z-index谁高谁低。有一定经验的人可能都知道上面的事实。但是,相信这里面很多人不知道IE6下,决定层级高低的不是当前的父标签,而是整个DOM tree(节点树)的第一个relative属性的父标签。有时平时我们多处理一个父标签,z-index层级多而复杂的情况不多见,所以难免会有认识上的小小偏差。
问题41:你安装了那些chrome插件?
cssViewer, colorZilla, web前端助手, windowResizer,javaScript Errors Notifier,CSRF Discovery,CSSGaga等
问题42:那些网站给你留下了深刻的印象?
FTP中文网;美团外卖的dns预解析;淘宝网主页的GZIP压缩;google的安全机制(x-xss-protection:1;block而x-frame-options:sameOrigion; x-content-type-options:nosniff)
问题43:为什么开始学习前端?
问题44:jquery源码读过之后有什么提升?
1.工具函数的理解:工具函数是jQuery一个重要的部分,通过对他的了解可以提升我们对于js的理解。如proxy函数就用到了闭包和函数柯里化等相关知识,也能让我们更好的理解bind函数;例如jQuery的type方法就是对js原生typeof方法的一种扩展,我们知道jQuery的typeof只能识别基本类型,而jQuery的方法却可以识别如Function,RegExp,Date等类型,通过该方法我们可以很好的理解typeof方法,如果我们有一天需要这么一个函数也可以知道怎么写;parseJSON方法,通过这个方法使得我研究了jQuery中的正则表达式部分,特别是带有或符号的正则表达式,了解了懒惰匹配和贪婪匹配等概念;通过each,map,grep等方法深入理解了call/apply的区别,同时也了解了buildFragment,parseHTML等jQuery没有向外暴露的方法。虽然这部分的源码不难理解,但是对于学习js基础知识是很好的。
function $proxy(func,context){
var outerArgs=Array.prototype.slice.call(arguments,2);
return function(){
var innerArgs=Array.prototype.slice.call(arguments);
var finalArgs=outerArgs.concat(innerArgs);
func.apply(context,finalArgs);
//这里不能是call,否则需要单个传递参数,而不是数组
}
}
function test(name,sex){
console.log('this',this);
console.log('name='+name+',sex='+sex);
}
var proxy=$proxy(test,{name:'qinliang'});
proxy('fkl','female');2.代码的性能上来说,如了解到了jQuery是如何防止内存泄漏的,如防止循环引用的,包括解除引用和循环引用,循环引用包括在script插入到DOM中onload事件触发以后移除onload和onreadyStatechange事件和解除引用;同时如detach,remove,empty等方法在移除元素之前都移除了其保存的内部数据,就是为了防止内存泄漏的,这在js中虽然有所提及,但是在这里真正理解到了。同时jQuery还用到了detachEvent来移除事件,但是在移除事件之前如果该事件不存在那么那么要把其设置为null,然后调用detachEvent.
if ( typeof elem[ name ] === strundefined ) {
//如果恒等于undefined,那么设置为null,移除引用
elem[ name ] = null;
}
elem.detachEvent( name, handle ); 每一个方法调用的上下文是什么,每一个方法的调用时机是什么?
如ajax方法提供了很多方法回调来最终完成ajax请求,那么每一个方法调用时机是什么呢,这部分内容都很少提及。
beforeSend最先调用,上下文为最终的callbackContext对象,第一个参数也是jqXHR,第二个参数是最终options对象
(1)调用ajaxStart方法
(2)ajaxSend方法调用,参数为jqXHR和最终options
(3)调用open/send方法,完成ajax发送
(4)调用ajaxSuccess/ajaxError方法,参数为jqXHR对象,最终options对象,如果成功那么第三个参数是response.data,如果失败那么第三个参数是response.error!
(5)调用ajaxComplete方法
(6)调用ajaxStop方法 (多个ajax全部调用完了,才会触发ajaxStop,ajaxComplete()会对所有ajax请求都触发,而ajaxStop则只对最后一次的ajax请求进行触发。)
对于jQuery.data保存数据和获取数据严格遵守下面的次序:
第一步:获取expando以备用他来获取钥匙。expando=jQuery.expando;
第二步:通过expando获取到钥匙。JS对象:key=expando; DOM对象key=elem[expando]
第三步:获取仓库。JS对象walhouse=elem;DOM对象walhouse=jQuery.cache
第四步:用钥匙打开仓库。JS对象data=elem[expando],DOM对象data=walhouse[key]
第五步:获取数据,如果是用户数据要在data的data域下面,如果是内部数据不用到data域下面!
jQuery是如何组织事件的?
了解了观察者模式,如jQuery的Deferred对象就是对Callbacks对象的封装,每一类事件都可以有一个数组作为事件处理程序,当触发某一类事件的时候所有的事件回调函数都会触发。
问题45:js创建对象的几种方式?
工厂模式;构造函数模式;原型模式;动态原型模式(如果this上面没有该属性就添加到prototype上);寄生构造函数模式(除了使用new操作符并把包装的函数叫做构造函数以外没有任何差别);稳妥构造函数(没有this,通过闭包完成)。参见 JS中各种构造模式对比 (动原妥寄 同名“动员拖拉机来构造”)
动态原型模式:
function Person(name,age){
this.name=name;
this.age=age;
if(typeof this.sayName!='function'){
Person.prototype.sayName=function(){
console.log('sayName');
}
}
}原型式构造函数:
function Person(name,age){
}
Person.prototype.sayName=function(){
console.log('sayName');
}
//通过原型添加方法function Person(name){
var o=new Object();
//稳妥表示没有this,全部用闭包的方式来访问。
//而且返回的是一个object类型
o.sayName=function(){
console.log(name);
}
return o;
}
var friend=Person('qinliang');
//构造函数也么有new操作符号
friend.sayName();function Person(name){
var o=new Object();
o.name=name;
o.sayName=function(){
console.log(this.name);
//因为构造函数用了new,所以这里可以用new操作符
}
return o;
}
var friend=new Person('sex');
//这里也用了new操作符号,除了使用new操作符,并把使用的包装函数叫做构造函数以外和工厂模式没有任何区别function Person(name){
var o=new Object();
o.name=name;
o.sayName=function(){
console.log(this.name);
//因为构造函数用了new,所以这里可以用new操作符
}
return o;
}
var friend= Person('sex');
//构造函数没有使用new,但是里面的sayName函数还是使用了this
friend.sayName();问题46:js继承的几种方式?(学会绘制内存图分析。引用类型有没有问题;同名变量有没有问题)
原型链;借用构造函数;组合继承;原型式继承;寄生式继承;寄生组合式继承。同名“原原借组寄寄” 组合起来就是“原原借组寄寄动原妥寄”
原型链方式:
Child.prototype=new Parent();//问题1:引用类型的原型;问题2:无法向父类传递参数 function Father(name){
this.name=name;
}
function Child(name){
this.name=name;
}
Child.prototype=new Father('father');
var child=new Child('child');
console.log(child.name);
delete child.name;
console.log(child.name);
//得出结论:子元素会屏蔽父元素的属性;同时为子类添加元素必须在修改prototype之后 function object(o){
function F(){}
F.prototype=o;
return new F();
}
var obj={name:'qinliang'};
var clone=object(obj);
//这时候的clone的原型不是F.prototype了,而是我们的o元素,o元素最后又指向了object.prototype
//object.prototype(学会绘制内存图)
console.log(clone);es5已经规范了这种方式继承,第一个参数为原型,第二个参数定义了额外属性的对象
var obj={name:'qinliang'};
var anotherObj=Object.create(obj,{
name:{
value:'klfang'
}
});
console.log(anotherObj);
//h5规范了原型继承借用构造函数方式:
function SuperType(){
this.colors=['name','sex']
}
function SubType(){
SuperType.call(this);
}
//这时候每一个this都是一个全新的对象,因此每一个对象都有个引用类型的副本
var instance1=new SubType();
instance1.colors.push('location');
console.log(instance1.colors);
var instance2=new SubType();
instance2.colors.push('dut');
console.log(instance2.colors);组合式继承:
function SuperType(name){
this.name=name;
this.color=['red'];
}
SuperType.prototype.sayName=function(){
console.log(this.name);
}
function SubType(name,age){
SuperType.call(this,name);
//这时候每一个subType实例都有一个自己的name和color属性,而这两个属性不是共享的
this.age=age;
}
SubType.prototype=new SuperType();
SubType.prototype.constructor=SubType();
//如果不修正,那么constructor已经是SuperType了
SubType.prototype.sayAge=function(){
console.log(this.age);
}寄身式继承:
var person={
name:'qinliang',
friends:['sex','male']
}
function object(o){
function F(){}
F.prototype=o;
return new F();
}
function parasite(original){
var clone=object(original);
//产生以original作为原型的一个对象的副本,original.prototype=object
clone.sayHi=function(){
console.log('hi');
}
return clone;
}
console.log(parasite(person));
寄身式组合继承:

var person={
name:'qinliang',
friends:['sex','male']
}
function object(o){
function F(){}
F.prototype=o;
return new F();
}
function SuperType(name){
this.name=name;
this.color=['red'];
}
SuperType.prototype.sayName=function(){
console.log(this.name);
}
function SubType(name,age){
SuperType.call(this,name);
//这时候每一个subType实例都有一个自己的name和color属性,而这两个属性不是共享的
this.age=age;
}
var prototype=object(SuperType.prototype);
//获取SuperType.prototype的一个副本,并作为F函数的prototype属性,
//同时返回这个副本(见下面的内存图)。然后把这个副本作为Subtype.prototype
//最后修改这个副本的constructor为SubType,否则这时候指向了SuperType
SubType.prototype.sayAge=function(){
console.log(this.age);
}
注意:这种通过create方式获取到SuperType.prototype的一个副本(create函数作用就在于返回一个类型的副本),然后把这个副本作为SubType的原型,但是同时要修正constructor。
问题47:html5特性有那些?
结构标签(section,aritcle,aside,header,footer,hgroup,nav,figure,figcaption,dialog)+表单标签(email,url,number,range,date,seach,datetime,month,week,pattern)+媒体标签(video,audio,embed,canvas)+其它标签(mark,progress,ruby,keygen,menu,meter,detail,datalist)+属性(autofocus+链接的media和download,base+css的scoped属性作用于包含元素的以及子元素+iframe的seamless(frameborder去除边框,allowtransparency, scrolling滚动),srcdoc(框架中页面内容),sandbox+ol的reversed+menu的toolbar+manifest,charset)等
doctype;link和script不需要type;yu在HTML5中,有许多新引入的元素,hgroup就是其中之一。假设我的网站名下面紧跟着一个子标题,我可以用<h1>和<h2>标签来分别定义。然而,这种定义没有说明这两者之间的关系。而且,h2标签的使用会带来更多问题,比如该页面上还有其他标题的时候。在HTML5中,我们可以用hgroup元素来将它们分组,这样就不会影响文件的大纲。标记元素 (Mark Element);HTML5引入了<figure>元素。当和<figcaption>结合起来后,我们可以语义化地将注释和相应的图片联系起来;参见HTML5十五大新特性。本地存储,安全,postMessage,DNS Prefetching,Link prefetching等
sandbox沙箱:
"" 应用以下所有的限制。
allow-same-origin 允许 iframe 内容被视为与包含文档有相同的来源。
allow-top-navigation 允许 iframe 内容从包含文档导航(加载)内容。
allow-forms 允许表单提交。
allow-scripts 允许脚本执行。
问题48:html5有那些优势?
易用性(语义明确);视频和音频;doctype;本地存储;游戏开发等。详见浅析HTML5的10大优势
问题49:css3有那些变化?(还包括类选择器,标签选择器,id选择器)
关系选择器:E F表示所有的子孙元素;E>F所有的子元素选择器;E+F相邻选择器;HTML5新的选择器是E~F所有的兄弟元素,如p~p表示p所有的兄弟节点,不包括自身而且只是后面的兄弟
伪类选择器:link,visited,hover,active,focus,lang; HTML5添加了p:first-child,last-child,nth-child(n)选择步骤第一步找p元素,第二步找p元素的父元素,第三步看父元素的第一个,最后一个,或者第n个是否p元素。nth-child(even/odd/3n+1)也是可以的,nth-last-child表示从尾部开始计算。
li:nth-last-child(4)
{
border:1px solid red;
}/*这里获取倒数第四个li*/html:root{}这是root的唯一用法,如div:root{}选中的时候是html,但是不是div的集合中,所以不会变色
:empty{}表示选中的元素中没有任何内容
:disabled,:enabled,:checked等选择器
属性选择器:E[attr],E[attr='val'],E[attr~='val']空格属性,E[attr|“val”]其中p[class~='yellow']表示class为yellow或者yellow前后有空格都是可以的;p[class|='b']表示以b开头而且中间用横杠链接。HTML5提供了E[attr^='值']表示以什么开头;E[attr$='值']表示以什么结尾,如a[href$='rar']:after{content:url{images/1.jpg}};E[attr*='值']表示包含指定的值
伪对象:E:first-letter,E:first-line,E:before,E:after都是CSS1&CSS2提供的。HTML5提供了p::first-line,first-letter,before,after,selection是选中时候变颜色
问题50:jQuery有那些选择器?
问题51:css中如何水平居中,如何垂直居中?
什么是line-height?
行高由于其继承性,影响无处不在,即使是单行文本也不例外。
line-height:normal(默认值,跟着浏览器走,和字体相关)
line-height:<Number>是根据font-size计算的,line-height:1.5,如果font-size:20px,那么行高就是20*1.5=30px
line-height:<length>,如em/rem/px/pt那么简单继承,不用重新计算
line-height:<percent>,根据font-size计算
line-height:<inherit>
line-height:1.5/150%/1.5em的区别?
1.5所有可继承的元素根据font-size重新计算行高,如果父元素为1.5,子元素font-size:60px,那么行高就是1.5*60
150%/1.5em:当前元素根据font-size计算行高,继承给下面的元素,下面的元素不重新计算,如父元素font-size:24px,line-height:150%,则为36px,把其作为所有元素的行高!
如果让元素垂直居中(absolute/display:table和table-cell/transform:translate)?
方法1:首先让要居中的元素inline-block化,而且vertical-align:middle,让后伪元素{content:"";display:inline-block;height:100%;vertical-align:middle}<p id="pb" style="background-color:#ccc;height:500px;">
<img src="images/1.png" style="width:250px;height:250px;display:inline-block ;vertical-align:middle"/>
<img src="images/1.png" style="width:250px;height:250px; display:inline-block;vertical-align:middle"/>
<img src="images/1.png" style="width:250px;height:250px; display:inline-block;vertical-align:middle"/>
<img src="images/1.png" style="width:250px;height:250px; display:inline-block;vertical-align:middle"/>
</p>p:after
{
content:"";
vertical-align:middle;
height:100%;
display:inline-block;
/*不要设置width:0了,因为inline-block元素的包裹性没有内容,宽度就是0!*/
}
注意:上面的height都是设置为父元素上面的,所以所有子元素的height都会继承,而且设置为子元素上面是无效的。缺点:必须设置子元素的高度,否则无效!!!!
上面虽然是用于image元素,但是这种思想是可以运用于任何div等其它元素的,如下面的这种方式也可以实现div的垂直居中的:
<div id="pb" style="background-color:#ccc;font-size:0;height:500px;">
<div style="width:100px;height:100px;vertical-align:middle;border:1px solid red;display:inline-block;"></div>
<div style="width:100px;height:100px;vertical-align:middle;border:1px solid red;display:inline-block;"></div>
<div style="width:100px;height:100px;vertical-align:middle;border:1px solid red;display:inline-block;"></div>
<div style="width:100px;height:100px;vertical-align:middle;border:1px solid red;display:inline-block;"></div>
</div>单行文本垂直居中可以简单的用lin-height来完成,利用文字的垂直居中特性
<!--单行文本的垂直居中,不需要给父元素设置line-height和height相同,因为父元素设置了line-height那么子元素会继承line-height,所以
因此最高的line-box就是该文字,而且文字有垂直居中特效,所以实现了近似垂直居中!-->
<div style="border:1px solid red;line-height:100px;">
<span style="border:1px solid blue;">I love you</span>
</div><!--可以用table,table-cell实现垂直居中,但是IE8一下不支持-->
<div id="wrapper" style="display:table;border:1px solid red;height:100px;">
<div id="cell" style="display:table-cell;vertical-align:middle;border:1px solid blue;">
<div class="content">
goes here</div>
</div>
</div><div class="content" style="height:100px;width:100px;position:absolute;left:50%;top:50%;margin-left:-50px;margin-top:-50px;border:1px solid red;">Content goes here</div>也可以使用CSS3来说的:
p{
display: flex;
align-items: center;
}如何实现浮动元素的垂直居中
如何实现绝对定位元素的垂直居中
.element {
width: 600px; height: 400px;
position: absolute; left: 50%; top: 50%;
transform: translate(-50%, -50%); /* 50%为自身尺寸的一半,CSS3*/
}如何水平居中元素? (天使拉伸或者absolute和margin配合)
方法1:用position:absolute+margin-left负值
<!--用margin宽度一般的方法实现水平居中,但是前提必须知道宽度-->
<div style="width:800px;height:100px;background-color:#ccc;margin:0 auto;;">
<div style="height:50px;width:400px;background-color:red;position:absolute;left:50%;margin-left:-200px;"></div>
</div>方法2:用天使拉伸的方式
.horizontal-center3-father
{
position:relative;
}
/*如果要在可视区域内居中,只要把下面的absolute改成fixed就可以了,同时把z-index设置为一个很大的值!同时如果要可是区域左边设置left:0;right:auto右边则right:0;left:auto*/
.horizontal-center3-child
{
position:absolute;
left:0;/*left/right/top/bottom形成的盒子会填满body或者relative形成的包裹空间*/
right:0;
top:0;
bottom:0;
width:50%;/*当尺寸限制和天使拉伸同时存在的时候width>天使拉伸。也就是说设定了宽度以后浏览器会阻止元素填满整个空间,而会根据margin:auto重新计算包裹一层新的盒子*/
height:50%;/*必须指定height,我们可以通过height:10px;width:10px来重新设定元素本来应该的大小.因为内联样式大于外链样式*/
margin:auto;
overflow:auto;/*防止有问题,所以让问题显示出来*/
}
如何居中float元素(这里是用left而不是margin-left)
<div class="box" style="float:left;left:50%;position:relative;border:1px solid red;">
<p style="float:left;position:relative;border:1px solid blue;left:-50%;">我是浮动的sasaaaaaaaadadfffffffffffff</p>
</div>
问题52:em/px/%的区别? (相对单位 vs 绝对单位)
em vs px:任 意浏览器的默认字体高都是16px。所有未经调整的浏览器都符合: 1em=16px。那么12px=0.75em,10px=0.625em。为了简化font-size的换算,需要在css中的body选择器中声明 Font-size=62.5%,这就使em值变为 16px*62.5%=10px, 这样12px=1.2em, 10px=1em, 也就是说只需要将你的原来的px数值除以10,然后换上em作为单位就行了。详见em和px区别
rem: rem是CSS3新增的一个相对单位(root em,根em),这个单位引起了广泛关注。这个单位与em有什么区别呢?区别在于使用rem为元素设定字体大小时,仍然是相对大小,但相对的只是HTML根元素。这个单位可谓集相对大小和绝对大小的优点于一身,通过它既可以做到只修改根元素就成比例地调整所有字体大小,又可以避免字体大小逐层复合的连锁反应。目前,除了IE8及更早版本外,所有浏览器均已支持rem。对于不支持它的浏览器,应对方法也很简单,就是多写一个绝对单位的声明。这些浏览器会忽略用rem设定的字体大小。可以参见转换器 ,rem仅仅是IE6-8不支持 响应式布局要用em/rem/%
em vs 百分比:当客户端的浏览器文本大小设置为“medium”, ems和百分比之间没有区别。然而,当设置改变,差别是相当大的。“Smallest”设置,ems比百分比小得多,而当设置为“Largest”,这时恰恰相反,ems比百分比显示地更大。有些可能会说,当真css3-mediaqueries-js正去扩展时em单位在扩展,在实际的应用程序中,em文本尺度变化太大, 在一些客户端机器上最小的文本变得不是很清晰 详见CSS字体大小: em与px、pt、百分比之间的对比
问题53:什么是响应式布局?
自适应的不足:响应式的概念应该覆盖了自适应,而且涵盖的内容更多。自适应还是暴露出一个问题,如果屏幕太小,即使网页能够根据屏幕大小进行适配,但是会感觉在小屏幕上查看,内容过于拥挤,响应式正是为了解决这个问题而衍生出来的概念。它可以自动识别屏幕宽度、并做出相应调整的网页设计,布局和展示的内容可能会有所变动。
1.允许网页宽度自动调整
"自适应网页设计"到底是怎么做到的?其实并不难。
首先,在网页代码的头部,加入一行viewport元标签。
<meta name="viewport" content="width=device-width, initial-scale=1" />
viewport是网页默认的宽度和高度,上面这行代码的意思是,网页宽度默认等于屏幕宽度(width=device-width),原始缩放比例(initial-scale=1)为1.0,即网页初始大小占屏幕面积的100%。所有主流浏览器都支持这个设置,包括IE9。对于那些老式浏览器(主要是IE6、7、8),需要使用css3-mediaqueries-js。
<!--[if lt IE 9]>
<script src="http://css3-mediaqueries-js.googlecode.com/svn/trunk/css3-mediaqueries.js"></script>
<![endif]-->
响应式布局被大家熟知的一个重要原因就是 twitter 开源了 bootstrap。Google 第一次完成了从先驱到烈士。
2.尽量不要使用绝对宽度,必要时候可以用cal来计算
3.字体也不能使用绝对大小(px),而只能使用相对大小(em)或者高清方案(rem),rem不局限于字体大小,前面的宽度width也可以使用,代替百分比。
4.流体布局,float的好处是,如果宽度太小,放不下两个元素,后面的元素会自动滚动到前面元素的下方,不会在水平方向overflow(溢出),避免了水平滚动条的出现。
5.选择加载css。自适应网页设计"的核心,就是CSS3引入的Media Query模块。除了用html标签加载CSS文件,还可以在现有CSS文件中加载。
@import url("tinyScreen.css") screen and (max-device-width: 400px);
6.图片自适应。除了布局和文本,"自适应网页设计"还必须实现图片的自动缩放。这只要一行CSS代码:
img { max-width: 100%;}。让图片自适应可以用cssExpression或者用js来控制,详见让图片自适应大小的方法
更多内容参见响应式和自适应的区别
问题54:弹性布局的实现原理?
参见深入理解 CSS3 弹性盒布局模型 CSS 3中flex-basis属性用法详解
flex-basis:当flex container无法容纳所有元素的flex basis的时候就会对元素的大小进行比例的分配,这就是flex-basis的概念!
.example-first(宽度) = 400 * (400 / (400 + 200)) = 266.666666667
.example-last(宽度) = 400 * (200 / (400 + 200)) = 133.333333333弹性布局:
(1)弹性布局的主要思想是让容器有能力来改变项目的宽度和高度,以填满可用空间(主要是为了容纳所有类型的显示设备和屏幕尺寸)的能力。
(2)最重要的是弹性盒子布局与方向无关,相对于常规的布局(块是垂直和内联水平为基础),很显然,这些工作以及网页设计缺乏灵活性,无法支持大型和复杂的应用程序(特别当它涉及到改变方向,缩放、拉伸和收缩等)。
(3)Flexbox布局是最合适的一个应用程序的组件,以及小规模的布局,而网格布局是用于较大规模的布局。
(4)css 列(CSS columns)在弹性盒子中不起作用。float, clear and vertical-align 在flex项目中不起作用
(5)flex-direction: row | row-reverse | column | column-reverse
flex-wrap: nowrap | wrap | wrap-reverse
flex-flow: <‘flex-direction’> || <‘flex-wrap’>
justify-content: flex-start | flex-end | center | space-between | space-around(水平方向上对齐)
align-items: flex-start | flex-end | center | baseline | stretch(垂直方向上对齐)
align-content: flex-start | flex-end | center | space-between | space-around | stretch(弹性盒堆叠伸缩行的对齐方式)
order: <integer> 用整数值来定义排列顺序,数值小的排在前面。可以为负值。适用于元素
flex-grow: <number> (default 0)拥有分配剩余空间权利的
flex-shrink: <number> (default 1)设置或检索弹性盒的收缩比率(根据弹性盒子元素所设置的收缩因子作为比率来收缩空间。)
flex-basis: <length> | auto (default auto)设置或检索弹性盒伸缩基准值。
flex:none | [ flex-grow ] || [ flex-shrink ] || [ flex-basis ]复合属性。设置或检索伸缩盒对象的子元素如何分配空间。
align-self: auto | flex-start | flex-end | center | baseline | stretch设置或检索弹性盒子元素自身在侧轴(纵轴)方向上的对齐方式。
css3 flex属性flex-grow、flex-shrink、flex-basis学习笔记 Flex Basis与Width的区别
<div class="flex-parent">
<div class="flex-son"></div>
<div class="flex-son"></div>
<div class="flex-son"></div>
</div>
<style type="text/css">
.flex-parent {
width: 800px;
}
</style>.flex-son:nth-child(1){
flex: 3 1 200px;
}
.flex-son:nth-child(2){
flex: 2 2 300px;
}
.flex-son:nth-child(3){
flex: 1 3 500px;
}加权值 = son1 + son2 + …. + sonN;
那么压缩后的计算公式就是
压缩后宽度 w = (子元素flex-basis值 * (flex-shrink)/加权值) * 溢出值
所以最后的加权值是
1*200 + 2*300 + 3*500 = 2300px
son1的扩展量:(200 * 1/ 2300) * 200,即约等于17px;
son2的扩展量:(300 * 2/ 2300) * 200,即约等于52px;
son3的扩展量:(500 * 3/ 2300) * 200,即约等于130px;
最后son1、son2、son3,的实际宽度为:
200 – 16 = 184px;
300 – 52 = 248px;
500 – 230 = 370px;
我们把父元素的宽度变成1200,然后看看flex-grow的用法:
剩余后宽度 w = (子元素flex-grow值 /所有子元素flex-grow的总和) * 剩余值
总分数为 total = 1 + 2 + 3;
son1的扩展量:(3/total) * 200,即约等于100px;
son2的扩展量:(2/total) * 200,即约等于67px;
son3的扩展量:(1/total) * 200,即约等于33px;
最后son1、son2、son3,的实际宽度为:
200 + 100 = 300px;
300 + 67 = 367px;
500 + 33 = 533px;
但是很多时候我们的父级是不固定的,那么怎么办,其实很简单了,对照上面的公式,前提是已经设置了flex-basis值得元素,如果宽度的随机值小于flex-basis的时候就按第一种计算,反之第二种;明白了吧。也就是说浏览器会自动选择了。
但是在实际中,我们有些子元素不想进行比例分配,永远是固定的,那么flex就必须设置为none;
否则设置的宽度(width)将无效;
flex: 1, 则其计算值为 flex: 1 1 0%;
flex: auto, 则其计算值为 flex: 1 1 auto;
flex: none, 则其计算值为 flex: 0 0 auto;
根据上面的公式
flex:1的时候第一种方式其实是无效的(第一种方式container太小,所以以flex-basis和flex-shrink加权,而其权重为0,所以无效,也就是不会对其进行shrink),因为加权值是0,所以只能是第二种方式计算;
flex:none的时候,两种都失效,自己元素不参与父级剩余还是溢出的分配,flex:none的应用场景还是很多的;
上面的分写方式为:Flex-grow、Flex-shrink、Flex-basis 是Flex属性的分写模式
问题55:渐进增强和优雅降级?
渐进增强 progressive enhancement:针对低版本浏览器进行构建页面, 保证最基本的功能,然后再针对高级浏览器进行 效果、交互等改进和追加功能达到更好的用户体验。
优雅降级 graceful degradation:一开始就构建完整的功能,然后再针对低版本浏览器进行兼容。
区别:优雅降级是从复杂的现状开始,并试图减少用户体验的供给,而渐进增强则是从一个非常基础的,能够起作用的版本开始,并不断扩充,以适应未来环境的需要。降级(功能衰减)意味着往回看;而渐进增强则意味着朝前看,同时保证其根基处于安全地带。
“优雅降级”观点
“优雅降级”观点认为应该针对那些最高级、最完善的浏览器来设计网站。而将那些被认为“过时”或有功能缺失的浏览器下的测试工作安排在开发周期的最后阶段,并把测试对象限定为主流浏览器(如 IE、Mozilla 等)的前一个版本。
在这种设计范例下,旧版的浏览器被认为仅能提供“简陋却无妨 (poor, but passable)” 的浏览体验。你可以做一些小的调整来适应某个特定的浏览器。但由于它们并非我们所关注的焦点,因此除了修复较大的错误之外,其它的差异将被直接忽略。
“渐进增强”观点
“渐进增强”观点则认为应关注于内容本身。内容是我们建立网站的诱因。有的网站展示它,有的则收集它,有的寻求,有的操作,还有的网站甚至会包含以上的种种,但相同点是它们全都涉及到内容。这使得“渐进增强”成为一种更为合理的设计范例。这也是它立即被 Yahoo! 所采纳并用以构建其“分级式浏览器支持 (Graded Browser Support)”策略的原因所在。
问题56:前端技术栈有那些?
浏览器:IE/FireFox/Chrome/Safari/Opera/Edge等等
HTTP/1.1:URI,Session,Request.Response,Status Code,Request Method, Authentication
HTTP/2:Compression,Encryption,Minification, Server push
Three Pillar:上一层:HTML/CSS/Javascript
Standard: W3C/Ecmascript/HTML5/CSS3
问题57:Promise编程?
该方法允许异步函数,从而不打断现在代码的执行。promise对象仅仅暴露了Deferred的一些方法用于添加额外事件或者判断状态,如then, done, fail, always, pipe, progress, state and promise没有提供改变状态的方法如:(resolve, reject, notify, resolveWith, rejectWith, and notifyWith)。如果提供了参数,那么就会把这些方法封装到参数上面,并且返回,这可以把promise的行为添加到一些已经存在的对象上面.
我们可以简单总结一下规范。每个promise都有三个状态:pending(默认)、fulfilled(完成)、rejected(失败);默认状态可以转变为完成态或失败态,完成态与失败态之间无法相互转换,转变的过程是不可逆的,转变一旦完成promise对象就不能被修改。通过promise提供的then函数注册onFulfill(成功回调)、onReject(失败回调)、onProgres(进度回调)来与promise交互。Then函数返回一个promise对象(称为promise2,前者成为promise1),promise2受promise1状态的影响,具体请查看A+规范。
上两个规范中并没有说明promise的状态如何改变,大部分前端框架中使用Deferred来改变promise的状态(resolve()、reject())。详见JavaScript异步编程的Promise模式 ,注意Promise编程是异步的,这也是他的最重要的特点。每个promise有三个callback,分别是done, fail, progress有resolve,reject,nofify改变状态
问题58:页面重绘和重排导致的性能问题?
重绘和重排(repaints and reflows)
每个页面至少在初始化的时候会有一次重排操作。任何对渲染树的修改都有可能会导致下面两种操作:
1,重排
就是渲染树的一部分必须要更新 并且节点的尺寸发生了变化。这就会触发重排操作。
2,重绘
部分节点需要更新,但是没有改变他的集合形状,比如改变了背景颜色,这就会触发重绘。
重拍版发生的几种情况:添加或删除可见的DOM;元素位置变化;元素尺寸变化;内容改变;最初的页面渲染;浏览器窗口改变尺寸
记住:大多数浏览器都通过队列化修改和批量显示来优化重拍版过程。然而,可能经常不由自主的强迫队列进行刷新应要求立刻应用所有的计划改变的部分,如下面:
offsetTop, offsetLeft, offsetWidth, offsetHeight
scrollTop/Left/Width/Height
clientTop/Left/Width/Height
getComputedStyle(), or currentStyle in IE
减少重绘和重排版的几种方法:
class修改;cssText方法;隐藏元素然后修改最后显示;用文档碎片的方法创建一个子树,然后添加到DOM中;将元素复制到一个脱离文档的节点中,修改副本,然后覆盖原始的元素。
问题59:alt和title的区别?
问题60:Nodejs是什么?
JavaScript是一种运行在浏览器的脚本,它简单,轻巧,易于编辑,这种脚本通常用于浏览器的前端编程,但是一位开发者Ryan有一天发现这种前端式的脚本语言可以运行在服务器上的时候,一场席卷全球的风暴就开始了。 Node.js是一个基于Chrome JavaScript运行时建立的平台, 用于方便地搭建响应速度快、易于扩展的网络应用。Node.js 使用事件驱动, 非阻塞I/O 模型而得以轻量和高效,非常适合在分布式设备上运行的数据密集型的实时应用。Node是一个Javascript运行环境(runtime)。实际上它是对Google V8引擎进行了封装。V8引 擎执行Javascript的速度非常快,性能非常好。Node对一些特殊用例进行了优化,提供了替代的API,使得V8在非浏览器环境下运行得更好。
Node.js的优点
nodejs作为一个新兴的后台语言,有很多吸引人的地方:
RESTful API;单线程;Node.js可以在不新增额外线程的情况下,依然可以对任务进行并行处理 —— Node.js是单线程的。它通过事件轮询(event loop)来实现并行操作,对此,我们应该要充分利用这一点 —— 尽可能的避免阻塞操作,取而代之,多使用非阻塞操作;非阻塞IO;V8虚拟机;事件驱动

注意:node没有浏览器的html,webkit,显卡部分,其他都是具有的。而且node中可以任意访问本地资源,并且像webworker(child-process模块)玩转多线程。
Node是单线程的:
单线程不用考虑状态同步问题,没有死锁的发生;也没有线程切换的开销。但是单线程也有缺点:无法利用多核cpu,错误可能引起整个应用退出,大量计算占用cpu导致无法继续调用异步API。
Node是单线程的深度含义:
我们平时所说的node是单线程的仅仅是说javascript运行在单线程中,在node中无论在window还是linux平台上内部完成I/O任务的另有线程池。
Node中的异步IO:事件循环+观察者+请求对象:
事件循环:在进程启动的时候node开启了一个while(true)循环,每执行一次循环体的过程称为一个tick,每次tick的过程就是查看是否还有事件待处理,如果有就取出相应的事件和回调函数,并执行。然后进入下一个循环,如果不再有事件处理就退出进程。事件循环是一个典型的生产者/消费者模式,异步io是事件的生产者,源源不断的为node提供不同类型的事件,这些事件被传递到对应的观察者哪里,事件循环从关闸着那里取出事件并处理。
观察者:每个事件循环都有一个或者多个观察者,而判断是否有事件处理的过程就是像这些观察者询问是否有事件处理。事件可以来自用户的点击活着加载某些文件时候产生,这时候就会有对应的观察者。在node中,事件主要来源于网络请求和文件i/o等。这些事件对应于文件i/o观察者,网络i/o观察者。
请求对象:在node中异步io调用而言,回调函数不是由开发者调用的。那么从我们发出调用后到回调函数被执行,中间发生了什么了。事实上,从js发起调用的时候到内核执行玩io操作的过度阶段存在一种中间产物,叫做请求对象。组装好请求对象后,送入io线程池等待执行,实际上完成了异步io第一步,回调通知是第二步。
事件循环,观察者,请求对象,io线程池共同构成了node异步io的基本要素。window下,通过iocp来向系统内核发送io调用和从内核获取已经完成的io操作,配以事件循环,以此完成异步io的过程,在linux下通过epoll来完成。不同的是线程池在window下通过内核iocp直接提供,*nix下通过libuv自行完成。
注意:在js中因为是单线程的,所以按照常识他无法利用多核cpu,事实上在node中除了js是单线程的外,node自身其实是多线程的,只是io线程使用的cpu较少。另一个观点是除了用户代码没发并行外,所有的i/o(网络io,磁盘io)都是可以并行起来的。
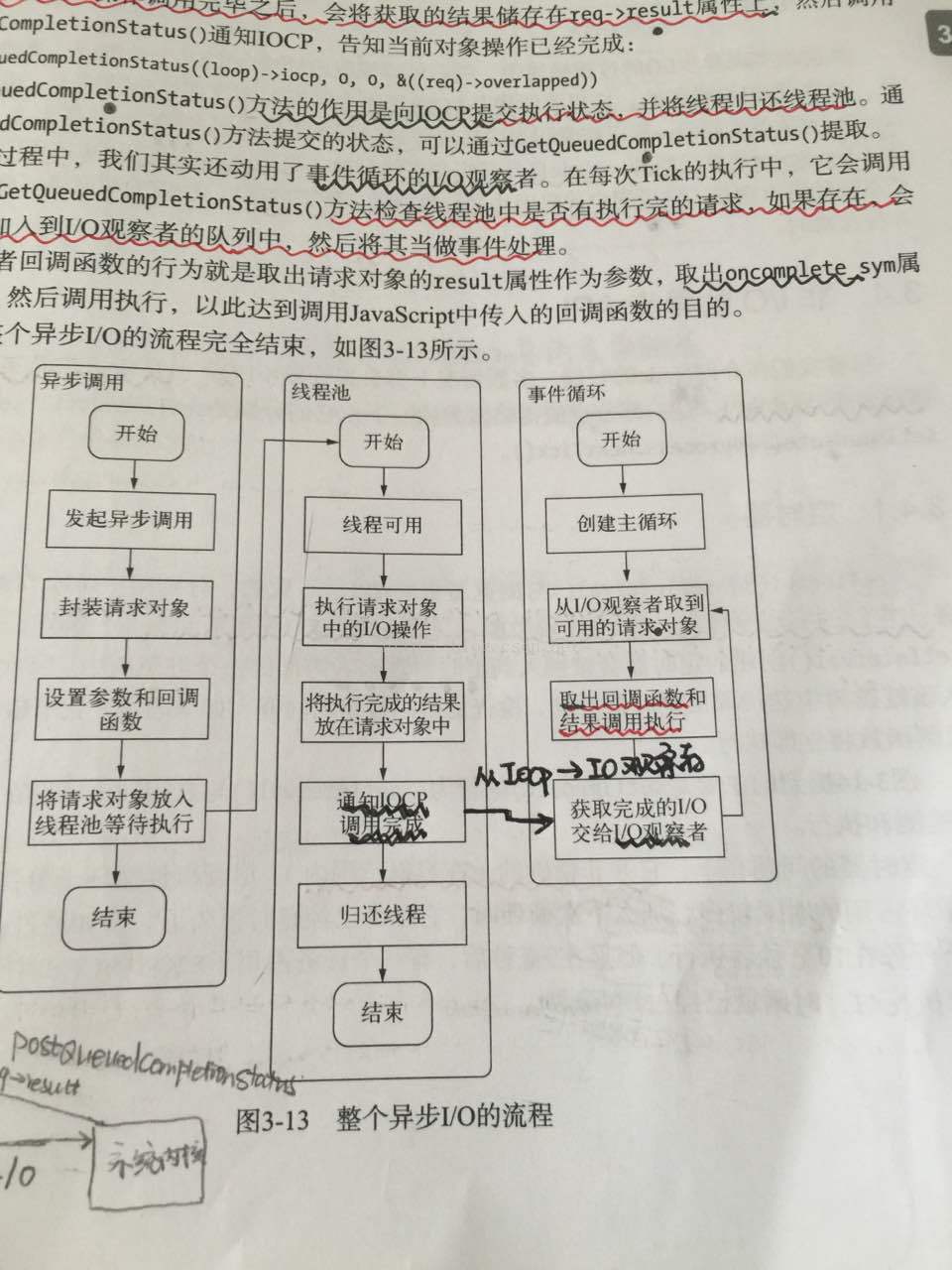
注意:iocp执行完后把结果通知给io观察者,用于事件循环。
详见RESTful API 理解RESTful架构 nodeJs
设计指南:API与用户的通信协议,总是使用HTTPs协议;应该尽量将API部署在专用域名之下;如果确定API很简单,不会用进一步扩展,则可以考虑放在主域名下;应该将API的版本号放入URI;对于资源的具体操作,由HTTP动词表示,常用的HTTP动词包括一下几个,括号里是对应的SQL命令!
*(优点)因为Node是基于事件驱动和无阻塞的,所以非常适合处理并发请求, 因此构建在Node上的代理服务器相比其他技术实现(如Ruby)的服务器表现要好得多。
此外,与Node代理服务器交互的客户端代码是由javascript语言编写的,
因此客户端和服务器端都用同一种语言编写,这是非常美妙的事情。
*(缺点)Node是一个相对新的开源项目,所以不太稳定,它总是一直在变, 而且缺少足够多的第三方库支持。看起来,就像是Ruby/Rails当年的样子。
高并发、聊天、实时消息推送
问题61:移动端和PC端的差别是什么?
从用户角度:pc端主要使用鼠标,而移动端主要是触屏。
从开发人员角度:UI(网页用户界面)设计师要考虑到移动端特点,便于触屏操作。布局方面:PC端咱们最常用的就是固定宽度980px(也有960,1000,1200),然后水平居中 width:980px;margin:0 auto;但移动端就不能这么用了,因为很多网页都是可以横屏看,也可以竖屏看;很多屏幕的分辨率不一样;所以只要牵涉到移动端,就要牵涉到响应式(也叫自适应);如果是只针对移动端的项目,我平时主要考虑的是320px宽 到 750px宽的兼容;事件方面:在PC端可能更多的使用mouse相关的事件,如果是移动端那么可能更多的使用touch Events规范,如touchstart,touchmove, touchend, touchcancel等;测试方面:在移动端可能要特定的插件,如window resizer而如果是PC端那么可能只要用简单的浏览器就可以了!
问题62:你知道css reset吗?
解决iphone字体调整:
(1)iPhone中浏览器纵向 (Portrate mode) 和橫向 (Landscape mode) 模式皆有自动调整字体大小的功能。控制它的就是 CSS 中的 -webkit-text-size-adjust。设置为none和100%都可以关闭自动调整字体大小的功能(2)none和100%的区别在于,100%不会阻止用户zoom!(3)当样式表里font-size<12px时,中文版chrome浏览器里字体显示仍为12px,这时可以用 html{-webkit-text-size-adjust:none;}
(2)去掉没用的margin/padding,如body的margin,HTML5标签figure默认的上下16px,左右40px!legend的padding左右是2px,上下是0也要去掉等等(figure+body+legend)
(3)为了让textarea在所有浏览器中有统一的表现,我们去除了IE8/9中默认的垂直滚动条!(overflow:auto)
(3)HTML5新标签的处理:如HTML5新支持的一些标签在低版本的IE中被解析为inline水平,所以设置为block;或者audio,video,canvas要设为inline-block;
问题63:word-wrap和white-space的不同?
white-space的几种属性:
pre:保留空格,类似于pre标签
nowrap:不换行,直到遇到br标签为止
pre-wrap:保留空格,但是正常换行
pre-line:合并空白符,但是保留换行符
word-wrap的几种属性:
break-word:在长单词的内部进行换行
word-break的几种属性:
word-break: break-all; 允许任意非CJK(Chinese/Japanese/Korean)文本间的单词断行
word-break: keep-all;不允许CJK(Chinese/Japanese/Korean)文本中的单词换行,只能在半角空格或连字符处换行。非CJK文本的行为实际上和normal一致。
其中,break-all这个值所有浏览器都支持。但是keep-all就不这样了,虽然有一定的发展和进步 – Chrome44正式支持了,但是,iOS下的Safari8/9都还不支持(下表黄绿色的表示不支持keep-all)。换句话说,基本上现在移动端还不适合使用word-break:keep-all.
可以发现,word-break:break-all正如其名字,所有的都换行。毫不留情,一点空隙都不放过。而word-wrap:break-word则带有怜悯之心,如果这一行文字有可以换行的点,如空格,或CJK(Chinese/Japanese/Korean)(中文/日文/韩文)之类的,则就不打英文单词或字符的主意了,让这些换行点换行,至于对不对齐,好不好看,则不关心,因此,很容易出现一片一片牛皮癣一样的空白的情况。详见word-break:break-all和word-wrap:break-word的区别
问题64:什么是UED?
UED团队包括:交互设计师(Interaction Designer)、视觉设计师(Vision Designer)、用户体验设计师(User Experience Design)、用户界面设计师(User Interface Design)和前端开发工程师(Web Developer)等等。
问题65:请你谈谈Cookie的弊端?(HTTP协议是无状态的)
cookie虽然在持久保存客户端数据提供了方便,分担了服务器存储的负担,但还是有很多局限性的。 第一:每个特定的域名下最多生成20个cookie
1.IE6或更低版本最多20个cookie
2.IE7和之后的版本最后可以有50个cookie。
3.Firefox最多50个cookie
4.chrome和Safari没有做硬性限制(CS游戏)
IE和Opera 会清理近期最少使用的cookie,Firefox会随机清理cookie。
cookie的最大大约为4096字节,为了兼容性,一般不能超过4095字节。IE 提供了一种存储可以持久化用户数据,叫做uerData,从IE5.0就开始支持。每个数据最多128K,每个域名下最多1M。这个持久化数据放在缓存中,如果缓存没有清理,那么会一直存在。
优点:极高的扩展性和可用性
1.通过良好的编程,控制保存在cookie中的session对象的大小。
2.通过加密和安全传输技术(SSL),减少cookie被破解的可能性。
3.只在cookie中存放不敏感数据,即使被盗也不会有重大损失。
4.控制cookie的生命期,使之不会永远有效。偷盗者很可能拿到一个过期的cookie。
缺点:
1.`Cookie`数量和长度的限制。每个domain最多只能有20条cookie,每个cookie长度不能超过4KB,否则会被截掉。
2.安全性问题。如果cookie被人拦截了,那人就可以取得所有的session信息。即使加密也与事无补,因为拦截者并不需要知道cookie的意义,他只要原样转发cookie就可以达到目的了。设置HttpOnly头,那么这时候cookie只能从服务端进行读取,因此js无法获取这一类的cookie
(1)没有删除已有cookie的直接方法,所以需要使用相同的路径,域,安全选项再次设置cookie并把失效时间设置为一个过去的时间
(2)子cookie是为了绕过单域名下cookie有限制而设置的,就是用cookie值来存储多个名称值对,如name=name1=value1&name2=value2等
(3)javascript的cookie设置只能通过BOM的document.cookie来设置,所有名和值都是经过URL编码的,也就是encodeURIComponent等!
(4)cookie的secure标记表明cookie只有在使用SSL连接的时候才会发送到服务器,这时候使用https协议
问题66:localStorage vs Cookie?
cookie会持续发送到服务器;API要自己设定,但是localStorage提供了getItem,setItem,removeItem,clear等;cookie的大小受到限制;cookie会过期。简称:“发送,API,容量,过期” 其它内容参见最全前端开发面试问题及答案整理
问题67:link和import区别?
(1) link属于HTML标签,而@import是CSS提供的; (2) 页面被加载的时,link会同时被加载,而@import引用的CSS会等到页面被加载完再加载;(3) import只在IE5以上才能识别,而link是HTML标签,无兼容问题; (4) link方式的样式的权重 高于@import的权重. 简称“HTML加载兼容权重”
问题68:position的absolute与fixed共同点与不同点
共同点:
1.改变行内元素的呈现方式,display被置为block;2.让元素脱离普通流,不占据空间;3.默认会覆盖到非定位元素上 简称“脱离文档流覆盖block”
不同点:
absolute的”根元素“是可以设置的,而fixed的”根元素“固定为浏览器窗口。当你滚动网页,fixed元素与浏览器窗口之间的距离是不变的。
问题69:介绍一下CSS的盒子模型?
1)有两种, IE 盒子模型、标准 W3C 盒子模型;IE的content部分包含了 border 和 pading;
2)盒模型: 内容(content)、填充(padding)、边界(margin)、 边框(border).
问题70:那些属性可以继承?
* 可继承的样式: font-size font-family color, text-indent;
* 不可继承的样式:border padding margin width height ;
* 优先级就近原则,同权重情况下样式定义最近者为准;
* 载入样式以最后载入的定位为准;
优先级为:
!important > id > class > tag
important 比 内联优先级高,但内联比 id 要高
问题71:CSS3有哪些新特性?
CSS3实现圆角(border-radius),阴影(box-shadow),对文字加特效(text-shadow、),线性渐变(gradient),旋转(transform)
transform:rotate(9deg) scale(0.85,0.90) translate(0px,-30px) skew(-9deg,0deg);//旋转,缩放,定位,倾斜;增加了更多的CSS选择器 ;多背景;rgba ;在CSS3中唯一引入的伪元素是::selection.;媒体查询
问题71:css Sprite是什么?
CSS Sprites其实就是把网页中一些背景图片整合到一张图片文件中,再利用CSS的“background-image”,“background- repeat”,“background-position”的组合进行背景定位,background-position可以用数字能精确的定位出背景图片的位置。这样可以减少很多图片请求的开销,因为请求耗时比较长;请求虽然可以并发,但是也有限制,一般浏览器都是6个。对于未来而言,就不需要这样做了,因为有了`http2`。
问题72:语义化的理解?
1,去掉或者丢失样式的时候能够让页面呈现出清晰的结构
2,有利于SEO:和搜索引擎建立良好沟通,有助于爬虫抓取更多的有效信息:爬虫依赖于标签来确定上下文和各个关键字的权重;
3,方便其他设备解析(如屏幕阅读器、盲人阅读器、移动设备)以意义的方式来渲染网页;
4,便于团队开发和维护,语义化更具可读性,是下一步吧网页的重要动向,遵循W3C标准的团队都遵循这个标准,可以减少差异化。简称“其它设备团队去掉SEO”
问题72:你知道多少种Doctype文档类型?
该标签可声明三种 DTD 类型,分别表示严格版本、过渡版本以及基于框架的 HTML 文档。
HTML 4.01 规定了三种文档类型:Strict、Transitional 以及 Frameset。
XHTML 1.0 规定了三种 XML 文档类型:Strict、Transitional 以及 Frameset。
Standards (标准)模式(也就是严格呈现模式)用于呈现遵循最新标准的网页,而 Quirks(包容)模式(也就是松散呈现模式或者兼容模式)用于呈现为传统浏览器而设计的网页。
(1)浏览器开发初期W3C倡导的网页标准并不流行,因此浏览器有独特的对网页标签或属性的解析模式,随着日后网页标准的流行,浏览器增加了对新标准的支持(Standards Mode),但又没有放弃对原有模式的兼容(Quirks mode),这就是浏览器多种表现模式的来源。
(2)当微软开始开发与标准兼容的浏览器时,他们希望确保向后兼容性。为了实现这一点,他们IE6.0以后的版本在浏览器内嵌了两种表现模式: Standards Mode(标准模式或Strict Mode,让IE的行为更加接近标准,主要影响CSS内容呈现,某些情况下也会影响到JS的解释执行)和Quirks mode(怪异模式或兼容模式Compatibility Mode,让IE的行为和IE5相同)。在标准模式中,浏览器根据W3C所定的规范来显示页面;而在怪异模式中,页面将以IE5,甚至IE4的显示页面的方式来表现,以保持以前的网页能正常显示。
(3)对于这两种模式引起最大的问题就是盒模式的问题,或者现在大家已经忽视了IE5的存在,但是,IE在怪异模式运行的盒模式依然在最新版本的IE保留着,甚至在IE6—IE10都保留有多种模式供开发者使用。其实为了与可能数量众多的网页维持兼容,现代的网页浏览器一般都具有多种渲染模式:在“标准模式”(standards mode) 页面按照 HTML 与 CSS 的定义渲染,而在“quirks 模式”中则尝试模拟更旧的浏览器的行为。一些浏览器(例如,那些基于Mozilla 的 Gecko 渲染引擎的,或者 Internet Explorer 8 在 strict mode 下)也使用一种尝试于这两者之间妥协的“近乎标准”(almoststandards) 模式,实施了一种表单元格尺寸的怪异行为,除此之外符合W3C标准定义
(4)两者区别之两个width,一个height,一个margin,一个padding:
区别1之盒子模型:IE6 IE7 在标准模式下盒模型是一模一样的 即width=width。IE6 IE7 在怪异模式下盒模型也是一模一样的即width=width+padding+border
区别2之设置内联元素的height/width:在Standards模式下,给span等行内元素设置wdith和height都不会生效,而在quirks模式下,则会生效。
区别3之父元素没有高度子元素的百分比高度无效:在standards模式下,一个元素的高度是由其包含的内容来决定的,如果父元素没有设置高度,子元素设置一个百分比的高度是无效的
区别4之margin;0 auto失效:这时候给body用text-align:center而子元素用text-align:left就可以了,这里的body就是父元素
区别5之图片的padding:quirk模式下设置图片的padding会失效;quirk模式下white-space:pre会失效;Quirk模式下Table中的字体属性不能继承上层的设置
(5)准标准模式和标准模式很多是符合标准的,但是不尽然。不标准的地方主要体现在处理图片间隙的时候,在表格中使用图片时候问题更加明显。但是两者十分接近,他们的差异几乎可以忽略不计(用document.documentCompatMode来看是什么模式!)
(6)标准模式下不允许使用任何表现层的东西,必须和层叠样式表配合使用;过渡性DTD是一种不严格的DTD,允许在页面中使用HTML4.01标识符(符合xhtml语法标准,但是不允许使用框架集,元素多一点);框架的如果页面中包含框架元素就用这个DTD!
(7)IE8引入了文档模式的概念,文档模式决定你可以使用那个级别的CSS可以在js中使用那些API,以及如何对待文档类型。如果要强制浏览器以某种模式渲染页面,可以用X-UA-Compatible!
<meta http-equiv='X-UA-Compatible' content='IE=IEVersion'></meta> IEVersion有一下几种值:
Edge:始终用最新的文档模式渲染页面,忽略文档类型声明
EmulateIE9/EmulateIE8/EmulateIE7:如果有文档声明就用IE9标准渲染,否则用IE5渲染
9/8/7/5:强制以IE9/8/7/5而忽略文档声明!
(8)在绝大多数浏览器,文档对象模型的扩展 document.compatMode 指示当前页面的渲染模式。在标准模式和接近标准模式,document.compatMode
(9)严格性包括HTML4.01,XHTML1.0,HTML5的方式;准标准性可以用过渡性和框架集型文档类型来触发,如HTML4.01过渡性和HTML4.01框架集型,XHTML1.0过渡性和,XHTML1.0框架集型
问题73:HTML与XHTML——二者有什么区别
区别:
1.所有的标记都必须要有一个相应的结束标记
2.所有标签的元素和属性的名字都必须使用小写
3.所有的XML标记都必须合理嵌套
4.所有的属性必须用引号""括起来
5.把所有<和&特殊符号用编码表示
6.给所有属性赋一个值
7.不要在注释内容中使“--”
8.图片必须有说明文字(如果需要javascript在XHTML中运行可以用CDATA这种方式)
问题74:解释下浮动和它的工作原理?清除浮动的技巧
浮动元素脱离文档流,不占据空间。浮动元素碰到包含它的边框或者浮动元素的边框停留。
1.使用空标签清除浮动。
这种方法是在所有浮动标签后面添加一个空标签 定义css clear:both. 弊端就是增加了无意义标签。
2.使用overflow。
给包含浮动元素的父标签添加css属性 overflow:auto; zoom:1; zoom:1用于兼容IE6。
3.使用after伪对象清除浮动。
该方法只适用于非IE浏览器。具体写法可参照以下示例。使用中需注意以下几点。一、该方法中必须为需要清除浮动元素的伪对象中设置 height:0,否则该元素会比实际高出若干像素;
#parent:after{
content:".";
height:0;
visibility:hidden;
display:block;
clear:both;
}
IE8以下浏览器的盒模型中定义的元素的宽高不包括内边距和边框
问题76:DOM操作——怎样添加、移除、移动、复制、创建和查找节点。
(1)创建新节点
createDocumentFragment() //创建一个DOM片段
createElement() //创建一个具体的元素
createTextNode() //创建一个文本节点
(2)添加、移除、替换、插入
appendChild()
removeChild()
replaceChild()
insertBefore() //在已有的子节点前插入一个新的子节点
(3)查找
getElementsByTagName() //通过标签名称
getElementsByName() //通过元素的Name属性的值(IE容错能力较强,会得到一个数组,其中包括id等于name值的)
getElementById() //通过元素Id,唯一性
问题75:html5有哪些新特性、移除了那些元素?如何处理HTML5新标签的浏览器兼容问题?如何区分 HTML 和 HTML5?
* HTML5 现在已经不是 SGML 的子集,主要是关于图像,位置,存储,多任务等功能的增加。
* 拖拽释放(Drag and drop) API
语义化更好的内容标签(header,nav,footer,aside,article,section)
音频、视频API(audio,video)
画布(Canvas) API
地理(Geolocation) API
本地离线存储 localStorage 长期存储数据,浏览器关闭后数据不丢失;
sessionStorage 的数据在浏览器关闭后自动删除
表单控件,calendar、date、time、email、url、search
新的技术webworker, websocket, Geolocation
* 移除的元素
纯表现的元素:basefont,big,center,font, s,strike,tt,u;
对可用性产生负面影响的元素:frame,frameset,noframes;
支持HTML5新标签:
* IE8/IE7/IE6支持通过document.createElement方法产生的标签,
可以利用这一特性让这些浏览器支持HTML5新标签,
浏览器支持新标签后,还需要添加标签默认的样式:
* 当然最好的方式是直接使用成熟的框架、使用最多的是html5shim框架
<!--[if lt IE 9]>
<script> src="http://html5shim.googlecode.com/svn/trunk/html5.js"</script>
<![endif]-->
如何区分: DOCTYPE声明
问题76:如何实现浏览器内多个标签页之间的通信?
调用localstorge(它支持一个事件方法window.onstorage,只要其中一个窗口修改了本地存储,其他同源窗口会触发这个事件)、cookies,postMessage,window.opener/window.showModalDialog(sURL [, vArguments] [,sFeatures])等本地存储方式 详见如何使用 JavaScript 在两个浏览器窗口间通信?
(1)localStorage大多数桌面浏览器是5MB,CS对每一个来源的限制是2.5MB,IOS的Safari浏览器和Androd的webkit是2.5MB
(2)SessionStorage也有限制,如CS和IOS的SF和Android的webkit都是2.5MB,IE8+和Opera是5MB!(CS都是5MB)
(3)保存在sessionStorage里面的数据可以跨越页面刷新而存在,同时如果浏览器支持重启后依然可以用(FF和webkit都支持,IE不支持),存储在sessionStorage里面的数据只能由最初给对象存储数据的页面访问到,所以对多页面应用存在限制。不同浏览器写入数据方面略有不同,FF/webkit实现了同步写入,所以添加到存储空间里面的数据是立刻被提交的,而IE实现是异步写入,所以在设置数据和将数据写入磁盘之间有一个延迟,对于少量数据来说这个差异可以忽略,对于大量数据来说你会发现IE要比其它浏览器更加快速的回复执行,因为他会跳过实际的磁盘写入过程。IE8如果要强制写入磁盘,在设置数据之前调用begin,设置数据之后用commit就可以了。如果是删除属性可以是调用sessionStorage的这些方法和属性:getItem(获取键值),length,key(获取键名),用delete之间删除
for(var i=0,len=sessionStorage.length;i<len;i++)
{
var key=sessionStorage.key(i);//获取键名
var value=sessionStorage.getItem(key);//
console.log(key+value);
//如果是删除数据,那么就可以用sessionStorage.removeItem方法
//如果需要跨域会话存储数据,那么globalStorage和localStorage更为合适
}globalStorage对象:
(1)该对象会跨越会话存储数据,但是有特定的访问限制,要使用globalStorage首先要指定那些域可以访问该数据。
globalStorage['wrox.com'].name='qinliang';//globalStorage不是Storage实例,而具体的指定的参数的对象才是
globalStorage[''].name='xxx';//存储数据,任何人都可以访问,但是不要这么做
globalStorage['.net'].name='yyy';//任何以.net结尾的域名都可以访问,但是不要这么做
//注意:对gobalStorage的访问是依据发起请求的页面的:域名,协议,端口来访问的,如https协议保存的数据通过http无法访问,类似于ajax的同源策略,如果事先不确定域名,那么用location.host比较好
(2)不能给localStroage指定任何访问规则,要访问同一个localStorage必须是同样的域名,子域名无效,使用同一种协议在同一个端口号上,相当于globalStorage[location.host]
websql主要API:openDatabase方法,
问题77:webSocket如何兼容低浏览器?
Adobe Flash Socket 、 ActiveX HTMLFile (IE) 、 基于 multipart 编码发送 XHR 、 基于长轮询的 XHR(传统轮询是无序的而这里是有序的)
长轮询:
1. 轮询的建立
建立轮询的过程很简单,浏览器发起请求后进入循环等待状态,此时由于服务器还未做出应答,所以HTTP也一直处于连接状态中。
2. 数据的推送
在循环过程中,服务器程序对数据变动进行监控,如发现更新,将该信息输出给浏览器,随即断开连接,完成应答过程,实现“服务器推”。
3. 轮询的终止
轮询可能在以下3种情况时终止:
3.1. 有新数据推送
当循环过程中服务器向浏览器推送信息后,应该主动结束程序运行从而让连接断开,这样浏览器才能及时收到数据。
3.2. 没有新数据推送
循环不能一直持续下去,应该设定一个最长时限,避免WEB服务器超时(Timeout),若一直没有新信息,服务器应主动向浏览器发送本次轮询无新信息的正常响应,并断开连接,这也被称为“心跳”信息。
3.3. 网络故障或异常
由于网络故障等因素造成的请求超时或出错也可能导致轮询的意外中断,此时浏览器将收到错误信息。
4. 轮询的重建
浏览器收到回复并进行相应处理后,应马上重新发起请求,开始一个新的轮询周期。
HTTP流:
(1)HTTP流在整个生命周期只使用一个HTTP链接,具体来说就是浏览器发送一个请求,而服务器保持链接打开,然后周期性发送数据。所有服务器都支持打印到输出缓存然后刷新,也就是将缓存中的内容一次性全部发送到客户端的功能,这就是HTTP流的关键所在。
(2)FF/SF/Opera/Chrome通过侦听readystatechange事件和检测readyState是否为3就可以利用xhr对象实现http流。在上述浏览器中不断从服务器接受数据readystate会周期性变为3,当readyState为3时候responseText就会保存接收到的所有的数据,此时比较此前接收到的数据决定从什么位置取得最新的数据。IE浏览器不支持!
(3)在流方式中,服务器推送数据到客户端,但是连接始终保持,直到超时或者客户端断开连接,超时后通知客户端重新链接,并关闭原来的链接!(减少发送数据的延迟,建立connection的开销,客户端发送请求的等待时间。缺点:长期占用连接,丧失了高并发的特点)
XHR MultipartStreaming:
(1)首先声明xhr-multipart仅适用于Gecko内核的浏览器.也就是firefox.原理是通过在HTML头声明ContentType为multipart/x-mixed-replace,通过设置boundary来区分每次发送的数据…意思如下headers[‘Content-Type’] = ‘multipart/x-mixed-replace;boundary=“woca”’;
(2)客户端这一段代码很重要xhr.multipart = true; //注意这里很重要!!xhrMultipartStreaming
function createStreamClient(url,progress,finished)
{
var xhr=new XMLHttpRequest(),
received=0;
xhr.open('get',url,true);
xhr.onreadystatechange=function()
{
var result;
if(xhr.readyState==3)
{
//只取得最新数据并且调整计数器
result=xhr.responseText.substring(received);
received+=received;//这种方式是不是因为只有一个链接,所以前面发送的数据后面也会再次发送一次
//调用progress函数
progress(result);
}else if(xhr.readyState==4)
{
finished(xhr.responseText);
}
};
xhr.send(null);
return xhr;
}
var client=createStreamClient('http',function(data){console.log(data);},function(data){console.log("done");});(1)XMLSocket 类实现了客户端套接字,这使得运行 Flash Player 的计算机可以与由 IP 地址或域名标识的服务器计算机进行通信。 对于要求滞后时间较短的客户端/服务器应用程序,如实时聊天系统,XMLSocket 类非常有用。 传统的基于 HTTP 的聊天解决方案频繁轮询服务器,并使用 HTTP 请求来下载新的消息。 与此相对照,XMLSocket 聊天解决方案保持与服务器的开放连接,这一连接允许服务器即时发送传入的消息,而无需客户端发出请求。 若要使用 XMLSocket 类,服务器计算机必须运行可识别 XMLSocket 类使用的协议的守护程序。
(2) 具体实现的方法:在HTML页面中陷入一个使用了XMLSocket类的Falsh程序。JavaScript通过调用此Flash程序提供的套接口接口与服务端的套接口进行通信。JavaScript在收到服务器端以XML格式传送的信息控制HTML的Dom对象改变页面的内容显示。
这种方案实现的基础是:一、Flash提供了 XMLSocket类。二、 JavaScript 和 Flash的紧密结合:在 JavaScript可以直接调用 Flash程序提供的接口。
缺点:
a) 因为XMLSocket没有HTTP隧道功能,XMLSocket类不能自动穿过防火墙;
b) 因为是使用套接口,需要设置一个通信端口,防火墙、代理服务器也可能对非HTTP通道端口进行限制;
应用: 网络聊天室,网络互动游戏
问题78:线程与进程的区别
一个程序至少有一个进程,一个进程至少有一个线程. 线程的划分尺度小于进程,使得多线程程序的并发性高。 另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。 线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。 从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。这就是进程和线程的重要区别。
问题79:你都使用哪些工具来测试代码的性能?
Profiler, JSPerf(http://jsperf.com/nexttick-vs-setzerotimeout-vs-settimeout), Dromaeo; dynaAjax
问题80:如何判断当前脚本运行在浏览器还是node环境中?
通过判断Global对象是否为window,如果不为window,当前脚本没有运行在浏览器中
console.log(global.setImmediate);
//如果在node中,这个global对象包含了很多属性和方法setImediate,setInterval,console等
console.log(window);
//打印 window is not defined问题81:99%的网站都需要被重构是那本书上写的?
* 网站重构:应用web标准进行设计(第2版)Jeffrey Zeldman
问题82:对前端界面工程师这个职位是怎么样理解的?它的前景会怎么样?(前后端界限模糊;最贴近用户的程序;卖白菜;所见即所得)
前端是最贴近用户的程序员,比后端、数据库、产品经理、运营、安全都近。
不仅仅是前端了,前后端界限模糊,完成一个功能不能仅仅会前端相关的内容;
测试,我喜欢摆弄各种工具,而不仅仅是打印一个log,就像是卖东西,要看色香味,而前端程序员比后端更加有色香味一点
1、实现界面交互
2、提升用户体验
3、有了Node.js,前端可以实现服务端的一些事情
前端是最贴近用户的程序员,前端的能力就是能让产品从 90分进化到 100 分,甚至更好, 参与项目,快速高质量完成实现效果图,精确到1px;
与团队成员,UI设计,产品经理的沟通;做好的页面结构,页面重构和用户体验;处理hack,兼容、写出优美的代码格式;针对服务器的优化、拥抱最新前端技术。
问题82:什么是全端工程师?
全栈工程师,也叫全端工程师,英文Full Stack developer。是指掌握多种技能,并能利用多种技能独立完成产品的人
问题83:平时如何管理你的项目?(MyEclipse分包存放)
先期团队必须确定好全局样式(globe.css),编码模式(utf-8) 等; 编写习惯必须一致(例如都是采用继承式的写法,单样式都写成一行); 标注样式编写人,各模块都及时标注(标注关键样式调用的地方);页面进行标注(例如 页面 模块 开始和结束);CSS跟HTML 分文件夹并行存放,命名都得统一(例如style.css);JS 分文件夹存放 命名以该JS功能为准的英文翻译。图片采用整合的 images.png png8 格式文件使用 尽量整合在一起使用方便将来的管理
问题83:说说最近最流行的一些东西吧?常去哪些网站?
Node.js、npm,angularJs等
网站:慕课,博客园,脚本之家,CSDN,github,stackoverflow等
问题84:ie各版本和chrome可以并行下载多少个资源
IE6 两个并发,iE7升级之后的6个并发,之后版本也是6个。Firefox,chrome也是6个
注意:这里突然想到了为什么浏览器需要限制同域名下并发的请求的数量。原因主要有几个:第一个是为了保护服务器端,因为服务器并发处理的请求的数量也是有限制的,是客户端和服务器端一种默契的配合;第二个原因是TCP连接需要一个端口号,而端口号的数量最多是65536,而很多端口号都被系统的其他内置进程占用,而创建TCP连接需要消耗系统资源,因此这种方法可以保护操作系统的 TCP\IP 协议栈资源不被迅速耗尽,因此浏览器不好发出太多的 TCP 连接,而是采取用完了之后再重复利用 TCP 连接或者干脆重新建立 TCP 连接的方法;第三个原因是:创建TCP/IP需要一定的系统资源,而且操作系统在调用进程的时候需要切换上下文,因此也会限制浏览器并发的数量,这是操作系统一种自我保护措施!
注意:半开连接指的是 TCP 连接的一种状态,当客户端向服务器端发出一个 TCP 连接请求,在客户端还没收到服务器端的回应并发回一个确认的数据包时,这个 TCP 连接就是一个半开连接。若服务器到超时以后仍无响应,那么这个 TCP 连接就等于白费了,所以操作系统会本能的保护自己,限制 TCP 半开连接的总个数,以免有限的内核态内存空间被维护 TCP 连接所需的内存所浪费。
问题85:什么是 "use strict"; ? 使用它的好处和坏处分别是什么?(arguments.caller和callee会报错,8进制这时候会报错)
ECMAscript 5添加了第二种运行模式:"严格模式"(strict mode)。顾名思义,这种模式使得Javascript在更严格的条件下运行。
设立"严格模式"的目的,主要有以下几个:
- 消除Javascript语法的一些不合理、不严谨之处,减少一些怪异行为;
- 消除代码运行的一些不安全之处,保证代码运行的安全;(undefined是否可以修改)
- 提高编译器效率,增加运行速度;
- 为未来新版本的Javascript做好铺垫。
注:经过测试IE6,7,8,9均不支持严格模式。
缺点: 现在网站的JS 都会进行压缩,一些文件用了严格模式,而另一些没有。这时这些本来是严格模式的文件,被merge 后,这个串就到了文件的中间,不仅没有指示严格模式,反而在压缩后浪费了字节。
问题86:GET和POST的区别,何时使用POST?
GET:一般用于信息获取,使用URL传递参数,对所发送信息的数量也有限制,一般在2000个字符;会缓存结果,但是post不会
POST:一般用于修改服务器上的资源,对所发送的信息没有限制。
a、get是用来从服务器上获取数据,post是向服务器传递数据
b、get将表单的数据按照variable=value的形式,添加到action所指向的URL后面,并且以?连接,而各个变量之间以&连接,post是将表单中的数据放在form的数据体中
c、get是不安全的,因为在传输的过程中,数据被放在请求URL中,而post所有的操作对用户来说都是不可见的。
d、get传输量小,主要是URL长度,而post传输量大,所以在做文件上传的时候用post比较好
enctype="multipart/form-data"//上传文件的做法问题87:WEB应用从服务器主动推送Data到客户端有那些方式?
html5 websoket;WebSocket通过Flash;XHR长时间连接;XHR Multipart Streaming; 不可见的Iframe;<script>标签的长时间连接(可跨域);dwr也是一种很常见的应用
问题88:如何获取UA?
<script>
function whatBrowser() {
document.Browser.Name.value=navigator.appName; //'Netscape'表示浏览器名
document.Browser.Version.value=navigator.appVersion;
//'"5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36"'
document.Browser.Code.value=navigator.appCodeName; //'Mozilla'表示浏览器代码名
document.Browser.Agent.value=navigator.userAgent;
//"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36"
}
</script>Flash的缺点是需要客户端安装Flash插件,比较大,且更改了默认的HTML页面行为;但可以方便地实现很多特效及 动画,且具有较高权限。
Ajax的缺点是编程较为复杂,需要服务器端的支持,能实现的效果只能是DOM API提供的,权限很低, 较难跨域;但可以显著加快页面的载入速度和用户体验。
此外,二者都不能被搜索引擎索引(Google已支持Flash文本的索引),不利于SEO。 建议:重要和关键部分直接用HTML,交互部分可以使用Ajax,复杂的动画可采用Flash
问题90:行内元素和块元素有那些 (width/margin区别)?
块级元素:div , p , form, ul, li , ol, dl, form, address, fieldset, hr, menu, table
行内元素:span, strong, em, br, img , input, label, select, textarea, cite,
空元素:input,br,img,link,meta,hr
1)块级元素会独占一行,其宽度自动填满其父元素宽度行内元素不会独占一行,相邻的行内元素会排列在同一行里,知道一行排不下,才会换行,其宽度随元素的内容而变化
2) 块级元素可以设置 width, height属性,行内元素设置width, height无效
【注意:块级元素即使设置了宽度,仍然是独占一行的】
详见行内元素和块元素区别
问题91:css的基本语句构成是?
选择器、属性和属性值。
问题92:用过那些jQuery插件
lazyload, loadmask, kindSlideShow, accordion, datePicker, validate, xhEditor等等
问题93:为什么选择jQuery?
jQuery简化了工作,同时提供了很多UI插件,有利于布局的完成;jQuery加载更快;jQuery有助于seo,网站的代码结构对各种搜索引擎的排名影响较大,jQuery提供了大量优化的插件帮助开发人员完成这项工作。详见选择jQuery的理由
问题94:、谈谈以前端角度出发做好SEO需要考虑什么?
1、了解搜索引擎如何抓取网页和如何索引网页
你需要知道一些搜索引擎的基本工作原理,各个搜索引擎之间的区别,搜索机器人(SE robot 或叫 web cra何进行工作,搜索引擎如何对搜索结果进行排序等等。
2、Meta标签优化 (h1标签,iframe标签)
主要包括主题(Title),网站描述(Description),和关键词(Keywords)。还有一些其它的隐藏文字比如Au者),Category(目录),Language(编码语种)等。
3、如何选取关键词并在网页中放置关键词
搜索就得用关键词。关键词分析和选择是SEO最重要的工作之一。首先要给网站确定主关键词(一般在5个上后针对这些关键词进行优化,包括关键词密度(Density),相关度(Relavancy),突出性(Prominency)等等。
4、了解主要的搜索引擎
虽然搜索引擎有很多,但是对网站流量起决定作用的就那么几个。比如英文的主要有Google,Yahoo,Bing等有百度,搜狗,有道等。不同的搜索引擎对页面的抓取和索引、排序的规则都不一样。还要了解各搜索门户和搜索的关系,比如AOL网页搜索用的是Google的搜索技术,MSN用的是Bing的技术。
5、主要的互联网目录 Open Directory自身不是搜索引擎,而是一个大型的网站目录,他和搜索引擎的主要区别是网站内容的收集方目录是人工编辑的,主要收录网站主页;搜索引擎是自动收集的,除了主页外还抓取大量的内容页面。
6、按点击付费的搜索引擎
搜索引擎也需要生存,随着互联网商务的越来越成熟,收费的搜索引擎也开始大行其道。最典型的有Overture当然也包括Google的广告项目Google Adwords。越来越多的人通过搜索引擎的点击广告来定位商业网站,这里面化和排名的学问,你得学会用最少的广告投入获得最多的点击。
7、搜索引擎登录
网站做完了以后,别躺在那里等着客人从天而降。要让别人找到你,最简单的办法就是将网站提交(submit)擎。如果你的是商业网站,主要的搜索引擎和目录都会要求你付费来获得收录(比如Yahoo要299美元),但是好消少到目前为止)最大的搜索引擎Google目前还是免费,而且它主宰着60%以上的搜索市场。
8、链接交换和链接广泛度(Link Popularity)
网页内容都是以超文本(Hypertext)的方式来互相链接的,网站之间也是如此。除了搜索引擎以外,人们也不同网站之间的链接来Surfing(“冲浪”)。其它网站到你的网站的链接越多,你也就会获得更多的访问量。更重你的网站的外部链接数越多,会被搜索引擎认为它的重要性越大,从而给你更高的排名。
问题95:一份标准的HTML应该有那些标签?
html/head/title/body标签
问题96:XML文件的典型结构?
<?xml version='1.0' encoding='utf-8' ?>
问题97:什么是Semantic HTML(语义HTML)?
Semantic HTML是一种编码风格, 它通过添加能够被计算器所理解的语义(Meta data),从而使HTML成为一个通用的信息交换媒介。在语义HTML中,<b></b>,<i></i>这类其中的内容不具有实际意义的标签是不应该被使用的,因为他们只是为了进行格式化,没有提供要表达的意义及页面结构。
问题98:IE和FF的区别?
detachEvent vs addEventListener;event vs window.event;srcElement vs target;getComputedStyle vs currentStyle;input.type在IE中只读而FF中可读可写;css部分如:styleFloat vs cssFloat ;insertRule vs addRule;removeRule vs deleteRule等等
问题99:为什么web标准中不能设置IE滚动条的颜色了?
body { scrollbar-face-color:#f6f6f6; scrollbar-highlight-color:#fff; scrollbar-shadow-color:#eeeeee; scrollbar-3dlight-color:#eeeeee;
scrollbar-arrow-color:#000; scrollbar-track-color:#fff; scrollbar-darkshadow-color:#fff; }问题100:如何定义1px左右高度的容器?
IE6下这个问题是因为默认的行高造成的,解决的方法也有很多,例如 :overflow:hidden | line-height:1px
问题101:怎么样才能让层显示在FLASH之上呢?
解决的办法是给FLASH设置透明:
<param name=”wmode” value=”transparent” />
问题102:如何放大元素?
<div style="border:1px solid red">
<div style="width:200px;height:200px;background-color:#ccc;position:absolute;z-index:10;"></div>
<div style="width:100px;height:100px;background-color:blue;position:absolute;margin-top:110px;;"></div>
</div>
<div style="width:100px;height:210px;background-color:red;position:absolute;margin-left:110px;"></div>var time=document.querySelector('#timer');
function printTime(){
var timer1=new Date();
var timer=timer1.toLocaleString();
console.log(timer);
timer=timer.replace(/[年月]/g,"-");
timer=timer.replace(/日/,"");
time.innerHTML=timer;
}
setInterval("printTime()",1000); var t = null;
var weeks=['星期日','星期一','星期二','星期三','星期四','星期五','星期六'];
t = setTimeout(time,1000);//开始执行
function time()
{
clearTimeout(t);//清除定时器
dt = new Date();
var y=dt.getFullYear();
//getYear只是返回116而不是2016!
var week=weeks[dt.getDay()];
var month=dt.getMonth()+1;
var date=dt.getDate();
var h=dt.getHours();
var m=dt.getMinutes();
var s=dt.getSeconds();
document.getElementById("timeShow").innerHTML = "现在的时间为:"+y+"年"+month+"月"+date+"日"+h+"时"+m+"分"+s+"秒"+week;
t = setTimeout(time,1000); //设定定时器,循环执行
} 问题104:遇到什么问题,最后怎么解决的?
记得自己一开始搭建SSH框架的时候,老是报错,最后跑去达内去试听课程,准备报补习班,还把自己的笔记本抱过去叫老师帮忙解决。
问题105:页面可见性(Page Visibility)API 可以有哪些用途?
不知道用户是不是正在页面交互是困扰广大web开发人员的一个主要问题,如果页面最小化了或者影藏在了其它标签页后面,那么有些功能可能停下来,比如轮询服务器或者某些动画效果,而page visibility就是为了让开发人员知道页面是否对用户可见而推出的。API如下:
document.hidden:页面是否影藏的布尔值,包括页面在后台标签中或者浏览器最小化(document.msHidden||document.webkitHidden||document.hidden)
document.visibilityState四个可能的状态:页面在后台标签也中或者浏览器最小化;页面在前台标签页中;实际的页面已经隐藏,但是用户可以看到页面的浏览;页面在屏幕外执行预渲染处理(IE10是msVisibilityState有四种状态,而webkitVisibilityState有"hidden/visibility/prerender",由于存在这种差异建议只用hidden)
visibilityChange事件:可见性发生变化时候触发(msVisibilitychange,webkitvisibiltychange分别是在IE中和Chrome中的事件,在IE10以上浏览器才支持)
详见Page Visibility(页面可见性) API介绍、微拓展
问题106:Geolocation API的用法?
Geolocation还不是HTML5规范的一部分,不过W3C为其独立出了一份详细的规范,因此,该API的血统还算比较纯正,来路比较清白。
检测是否支持:
if (navigator.geolocation) {//getCurrentPostion该方法有三个参数:成功回调函数;可选的失败回调函数;可选的选项对象
// 成功回调函数接受一个Postion对象有coords和timestamp,而coords含有latitude,longitude,accuray有些浏览器还可能altitude,altudeAccuracy,heading,speed
}问题107:请解释一下CSS3的Flexbox(弹性盒布局模型),以及适用场景?
(现代)是指从最近规范的语法(例如display:flex;)
(混合)是指从2011个非官方的语法(例如display:flexbox;)
(旧)从2009以来的语法手段(如display:box;)
我们给出了给出了关于flexbox的许多实际应用:
简单三栏布局(兼容版);居中对齐;自适应导航;移动优先三栏布局,多行对齐的表单,垂直居中对齐。可以参考CSS box-flex属性,然后弹性盒子模型简介
flexbox布局的主体思想是似的元素可以改变大小以适应可用空间,当可用空间变大,Flex元素将伸展大小以填充可用空间,当Flex元素超出可用空间时将自动缩小。总之,Flex元素是可以让你的布局根据浏览器的大小变化进行自动伸缩。
(1)居中对齐的css:
.flex-container {
display: flex;
flex-flow: row wrap;//正常换行
justify-content: space-around;
}/* Large */
.navigation {
display: flex;
flex-flow: row wrap;//正常换行
justify-content:flex-end;//布局时候所有在右边
}
/* Medium screens */
@media all and (max-width: 800px) {
.navigation {
//让justify-content设置为space-around就可以
justify-content: space-around;
}
}
/* Small screens */
@media all and (max-width: 500px) {
.navigation {
//小屏幕的时候干脆把flex-direction设置为column也就是按列显示
flex-direction: column;
}
}(3)三栏布局如下,移动三栏布局必须使用媒体查询:
<section>
<article>我是主要内容</article>
<nav>左边导航</nav>
<aside>我在右边栏</aside>
</section>section{
display:-webkit-flex;
display: flex;
flex-flow:row wrap;
-webkit-flex-flow:row wrap;//设置垂直方向上的伸缩项目
flex:1;//设置伸缩特性
-webkit-flex:1;
//为了实现三列等高,需要设置侧轴排列方法
-webkit-align-items:stretch;
align-items:stretch;
}
body{
display:flex;
display:-webkit-flex;
//对于body中的元素是采用按列排列
flex-flow:column wrap;
-webkit-flex-flow:column wrap;
}
article{
-webkit-flex:1;
flex:1;//让主要内容伸缩性
order:2;//祝内容排列在中间
-webkit-order:2;
background-color: red;
}
aside{
order:3;
-webkit-order:3;
background-color: blue;
}问题108:使用 CSS 预处理器吗?喜欢那个,Why?
//第一部分:变量的使用,如果变量要嵌套在字符串之中那么应该用#{}
$color:blue;
$bg:background;
div{
background-color:$color;
}
#content
{
#{$bg}-color:red;
}
//第二部分:sass允许在css中使用算式
body
{
border:1px+2px solid #ccc;
}
//第三部分:sass允许选择器嵌套
.outer
{
border:1px solid blue;
margin-top:10px+1px;
padding:10px;
.inner{
border:1px solid red;
}
}
//第四部分:属性也可以嵌套,这时候background后面必须加冒号
#section{
background:
{
color:#ccc;
};
margin:
{
top:10px;
}
}
//第四部分:在嵌套的类里面可以用&来引用父级的选择器
section
{
margin-top:10px;
a
{
&:hover{#{$bg}-color:red;}
}
}
//第五部分:双斜杠注释在编译后不存在,而/**/编译后存在,如果是/*!*/即使压缩模式编译也会存在,通常用于设置版权信息!
//第六部分:测试继承,这时候extend后面没有冒号!
.gray
{
#{$bg}-color:#ccc;
}
#extend{
@extend .gray;
border:1px solid red;
margin-top:10px;
}
//第七部分:mixin表示可以重用的代码快,优点类似C语言的宏的概念(这里就是清除浮动)
@mixin clearfix{
display:block;
content:"";
overflow:hidden;
clear:both;
height:0;
}
@mixin clearfix1{
overflow:hidden;
}
.left
{
float:left;
with:200px;
height:100px;
margin-right:10px;
#{$bg}-color:yellow;
}
.right
{
height:100px;
overflow:hidden;
#{$bg}-color:red;
}
.clearFloat{
border:1px solid red;
@include clearfix1;
}
//第八部分:用mixin指定缺省参数和缺省值
@mixin color($color:#ccc)
{
#{$bg}-color:$color;
}
.def{
@include color(red);
border:1px solid red;
margin-top:20px;
}
//第九部分:sass内置的颜色函数
//第十部分:插入外部文件用import "style.scss"如果是.css文件就等同于css的import命令
//第十一部分:测试if..else循环
@mixin colorChange($color:1)
{
@if $color==1
{
background-color:red;
} @else
{
#{$bg}-color:yellow;
}
}
.ifElse1{
@include colorChange(1);
margin-top:2em;
}
.ifElse2{
@include colorChange(2);
}
//第十二部分:测试for循环使得表格隔行变色
@for $i from 3 to 8
{
@if $i%2==0
{
.ifElse#{$i}
{
background-color:red;
}
} @else
{
.ifElse#{$i}
{
background-color:#ccc;
}
}
}
//第十三部分:测试while循环
$i:3;
@while $i<=8
{
.ifElse#{$i}
{
border:2px solid black;
}
$i:$i+1;
}
//十四部分:测试each函数
@each $member in ifElse3,ifElse5,ifElse3
{
.#{$member}{
border-radius:10px;
}
}
//第十五部分:自定义函数
@function double($n)
{
@return $n*10;
}
.double{
border:double(1px) solid red;
margin-top:10px;
}
//总结:sass就是extend,mixin,include的使用,所有关键字都要加上"艾特"符号!问题109:如何让chrome浏览器支持小于12px的字体大小?
低版本浏览器:在设置小于12px的选择器对象里设置一个-webkit-text-size-adjust:none样式:.abc{font-size:7px;-webkit-text-size-adjust:none}
高版本浏览器中:
p span{font-size:10px;-webkit-transform:scale(0.8);display:block;}问题110:li之间的空隙?
第1种情况:
子元素全部浮动,在不设置宽/高的情况下,不会有bug;一旦设置宽/高/zoom,bug就产生了
解决办法:参见li与li之间的空隙
1、给li添加浮动,如有需要可设置宽度。
2、把li设置成display:inline-block(变成inline也可以,但是样式就杯具了)
3、为li中所有元素都设置vertical-align值,此值可为top, bottom, middle, text-top, text-bottom, middle, sub, super中的一项(有博文说可设置vertical-align的任何值,这是错的,有些值不能解决bug,比如auto,centrial
并不是所有的li都会有这个问题,只有纵向排列的li才有可能出现。根据经验推测此3px bug 产生和 IE 特有的 haslayout 有关,因为在 ie8(ie取消了haslayout)和其它浏览器中没有这个问题。但是又不完全依赖haslayout,并不是所有触发haslayout的属性都会产生3px的bug。
问题111:visibility为collapse有什么用,不同浏览器处理的不同?
其实visibility可以有第三种值,就是collapse。当一个元素的visibility属性被设置成collapse值后,对于一般的元素,它的表现跟hidden是一样的。但例外的是,如果这个元素是table相关的元素,例如table行,table group,table列,table column group,它的表现却跟display: none一样,也就是说,它们占用的空间也会释放。
在chrome浏览器中collapse类似于hidden,在FF其它浏览器中类似于display:none;参见CSS里的visibility属性有个鲜为人知的属性值:collapse
问题112:position跟display、margin collapse、overflow、float这些特性相互叠加后会怎么样?
参见该博客 太难
问题113:如何去除inline-block元素之间的空格?
当两个inline-block元素之间有空格的时候就会产生。解决方案:借助注释;负数margin(和上下文的字体大小有关系);font-size:0,-webkit-text-ajust:none;letter-spacing;word-spacing等,具体参见去除inline-block元素间间距的N种方法
问题114:事务的特点和Spring事务的几种方式?
原子性;一致性;隔离性;持久性。spring几种事务传播行为见该图。SUPPORT,NOT_SUPPORT(有事务就挂起),NEVER,MANDATORY,REQUIRED!等事务传播机制
附加:为什么选择spring?
首先是自己想学SSH;其次是因为他的扩展性,他为Hibernate提供了HibernateTemplate,为jdbc提供了jdbcTemplate等,同时也可以继承ibatis,quartz等等一系列的插件,非常灵活,而且API非常简单!同时为了防止链接泄漏,也就是忘记关闭数据库链接,为我们提供了DataSourceUtil这个类
问题115:什么是切面?
提取其中共有的功能,如日志,权限管理,事务管理,性能监测等,并将其封住到一个类中,这个类就是切面,去除了共有的功能的逻辑代码变得十分简洁。包括前置通知,后置通知,环绕通知,异常通知等(连接池有层p和dbcp)
问题116:Spring中的BeanFactory与ApplicationContext的作用有哪些?
1、BeanFactory负责读取bean的配置文件,管理bean的加载、实例化,维护bean之间的依赖关系,负责bean的生命周期。
2、ApplicationContext除了提供上述BeanFactory所能提供的功能之外,还提供了更完整的框架功能:
a. 国际化支持
b. 资源访问
c. 事件传递
问题117:如何在spring中配置事务通知和切面切点?
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"></property>
</bean>
<!-- 定义事务通知 -->
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<!-- 定义方法的过滤规则 -->
<tx:attributes>
<!-- 所有方法都使用事务 -->
<tx:method name="*" propagation="REQUIRED"/>
<!-- 定义所有get开头的方法都是只读的 -->
<tx:method name="get*" read-only="true"/>
</tx:attributes>
</tx:advice>
<!-- 定义AOP配置 -->
<aop:config>
<!-- 定义一个切入点 -->
<aop:pointcut expression="execution (* com.iflysse.school.services.impl.*.*(..))" id="services"/>
<!-- 对切入点和事务的通知,进行适配 -->
<aop:advisor advice-ref="txAdvice" pointcut-ref="services"/>
</aop:config> <bean id="adviceTest" class="com.abc.advice.AdviceTest" />
<aop:config>
<!-- 注意这里可以使用order属性为Aspect指定优先级 -->
<aop:aspect id="firstAspect" ref="adviceTest" order="2">
<!-- @Before切点 -->
<aop:before pointcut="execution(* com.abc.service.*.*(..))"
method="permissionCheck"/>
<!-- @After切点 -->
<aop:after pointcut="execution(* com.abc.service.*.*(..))"
method="releaseResource"/>
<!-- @AfterReturning切点 -->
<aop:after-returning pointcut="execution(* com.abc.service.*.*(..))"
method="log"/>
<!-- @AfterThrowing切点 -->
<aop:after-throwing pointcut="execution(* com.abc.service.*.*(..))"
method="handleException"/>
<!-- @Around切点(多个切点提示符使用and、or或者not连接) -->
<aop:around pointcut="execution(* com.abc.service.*.*(..)) and args(name,time,..)"
method="process"/>
</aop:aspect>
</aop:config>问题118:爬虫用了什么框架jsoup+htmlunit?
Java 程序在解析 HTML 文档时,相信大家都接触过 htmlparser 这个开源项目,我曾经在 IBM DW 上发表过两篇关于 htmlparser 的文章,分别是:从 HTML 中攫取你所需的信息和 扩展 HTMLParser 对自定义标签的处理能力。但现在我已经不再使用 htmlparser 了,原因是 htmlparser 很少更新,但最重要的是有了 jsoup 。
jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据。
jsoup 的主要功能如下:
1. 从一个 URL,文件或字符串中解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找、取出数据;
3. 可操作 HTML 元素、属性、文本;
我们知道,要获取网页内容必须知道网页url,这时候通过不断点击下一页就可以知道,然后匹配出来了pageoffset=%d,这时候如果我要获取到第一页那么就设置为1。获取排名前1000,那么就用1000%25就可以知道有多少页了。至于获取到网页内容后用jsoup解析是十分容易的,因为他和jQuery选择器十分类似!
当然,因为我还要获取类似于粉丝的页面,所以我就要模拟鼠标点击来完成,这时候就用到了htmlUnit,这个包甚至可以模拟特定的浏览器,如chrome/Firefox/IE:
简介:`HtmlUnit`说白了就是一个浏览器,这个浏览器是用Java写的无界面的浏览器,正因为其没有界面,因此执行的速度还是可以滴,`HtmlUnit`提供了一系列的API,这些API可以干的功能比较多,如表单的填充,表单的提交,模仿点击链接,由于内置了`Rhinojs`引擎,因此可以执行`Javascript`
作用:web的自动化测试(最初的目的),浏览器,网络爬虫
问题119:有状态的bean和无状态的bean是什么?(scope是prototype还是singletion?当然其它的还收request/session/global session,有状态的如购物车)
有状态会话bean :每个用户有自己特有的一个实例,在用户的生存期内,bean保持了用户的信息,即“有状态”;一旦用户灭亡(调用结束或实例结束),bean的生命期也告结束。即每个用户最初都会得到一个初始的bean。
无状态会话bean :bean一旦实例化就被加进会话池中,各个用户都可以共用。即使用户已经消亡,bean 的生命期也不一定结束,它可能依然存在于会话池中,供其他用户调用。由于没有特定的用户,那么也就不能保持某一用户的状态,所以叫无状态bean。但无状态会话bean 并非没有状态,如果它有自己的属性(变量),那么这些变量就会受到所有调用它的用户的影响,这是在实际应用中必须注意的。其中有五种状态的bean,见该图
问题120:servlet声明周期是什么?
当servlet被装载到容器中的时候,首先调用init初始化;调用service方法处理客户端请求,并将结果封装到HttpServletResponse中返回给客户端;当servlet实例从容器中移除的时候调用destory方法!
Servlet 生命周期:Servlet 加载--->实例化--->服务--->销毁。
init():在Servlet的生命周期中,仅执行一次init()方法。它是在服务器装入Servlet时执行的,负责初始化Servlet对象。可以配置服务器,以在启动服务器或客户机首次访问Servlet时装入Servlet。无论有多少客户机访问Servlet,都不会重复执行init()。
service():它是Servlet的核心,负责响应客户的请求。每当一个客户请求一个HttpServlet对象,该对象的Service()方法就要调用,而且传递给这个方法一个“请求”(ServletRequest)对象和一个“响应”(ServletResponse)对象作为参数。在HttpServlet中已存在Service()方法。默认的服务功能是调用与HTTP请求的方法相应的do功能。destroy(): 仅执行一次,在服务器端停止且卸载Servlet时执行该方法。当Servlet对象退出生命周期时,负责释放占用的资源。一个Servlet在运行service()方法时可能会产生其他的线程,因此需要确认在调用destroy()方法时,这些线程已经终止或完成。
问题121:JSP的9大隐式对象是什么?
request, response, session, application这几个是很容易记起来的,page, pageContext, config, out, error等
page:是JSP页面本身,是this变量的别名,对JSP页面创建者通常不可访问,作为JSP开发人员很少使用
config:config 对象代表当前JSP 配置信息,但JSP 页面通常无须配置,因此也就不存在配置信息。该对象在JSP 页面中非常少用,但在Servlet 则用处相对较大。因为Servlet 需要配置在web.xml 文件中,可以指定配置参数。有getInitParameter, getInitParameterNames, getServletContext, getServletName等
session:因为HTTP协议无状态,因此用了session机制,sessionID保存到客户端的cookie中,这样就可以记住客户端的信息了。session过期可能是:时间过期;关闭浏览器;服务器端调用session的invalidate方法
application:存放应用级别的信息,直到服务器关闭,如可以存放是当前的第几位访客
pageContext:管理JSP页面中可见部分已经命名对象的访问,可以是PAGE_SCOPE, REQUEST_SCOPE, SESSION_SCOPE, APPLICATION_SCOPE!
exception:在jsp中设置了<%@ page isErrorPage='true' %>就可以使用exception对象了!
问题122:jsp和servlet的关系是怎么样的?
1.jsp经编译后就变成了Servlet.(JSP的本质就是Servlet,JVM只能识别java的类,不能识别JSP的代码,Web容器将JSP的代码编译成JVM能够识别的java类)
2.jsp更擅长表现于页面显示,servlet更擅长于逻辑控制.
3.Servlet中没有内置对象,Jsp中的内置对象都是必须通过HttpServletRequest对象,HttpServletResponse对象以及HttpServlet对象得到.
Jsp是Servlet的一种简化,使用Jsp只需要完成程序员需要输出到客户端的内容,Jsp中的Java脚本如何镶嵌到一个类中,由Jsp容器完成。而Servlet则是个完整的Java类,这个类的Service方法用于生成对客户端的响应
问题123:jsp有哪些动作作用分别是什么
答:JSP共有以下6种基本动作
jsp:include:在页面被请求的时候引入一个文件。
jsp:useBean:寻找或者实例化一个JavaBean。
jsp:setProperty:设置JavaBean的属性。
jsp:getProperty:输出某个JavaBean的属性。
jsp:forward:把请求转到一个新的页面。
jsp:plugin:根据浏览器类型为Java插件生成OBJECT或EMBED标记
问题124:JSP中动态INCLUDE与静态INCLUDE的区别?
答:动态INCLUDE用jsp:include动作实现,它总是会检查所含文件中的变化,适合用于包含动态页面,并且可以带参数
静态INCLUDE用include伪码实现,定不会检查所含文件的变化,适用于包含静态页面
问题125:cookie的setDomain和setPath的区别和作用?
domain:如果是".wrox.com"那么表示对于wrox.com和所有的子域都发送cookie
path:如果是http://www.wrox.com/books/,那么http://www.wrox.com不会发送cookie信息,即使来自于同一个域!详见主要看看 cookie 的 path 和 domain
问题126:拦截器和过滤器的区别 (调用一次)?
1、拦截器是基于java反射机制的,而过滤器是基于函数回调的。
2、过滤器依赖于servlet容器,而拦截器不依赖于servlet容器。
3、拦截器只能对Action请求起作用,而过滤器则可以对几乎所有请求起作用。
4、拦截器可以访问Action上下文、值栈里的对象,而过滤器不能。
5、在Action的生命周期中,拦截器可以多次调用,而过滤器只能在容器初始化时被调用一次。
问题127:简述 Struts2 的工作流程:
①. 请求发送给 StrutsPrepareAndExecuteFilter
②. StrutsPrepareAndExecuteFilter 判定该请求是否是一个 Struts2 请求
③. 若该请求是一个 Struts2 请求,则 StrutsPrepareAndExecuteFilter 把请求的处理交给 ActionProxy
④. ActionProxy 创建一个 ActionInvocation 的实例,并进行初始化
⑤. ActionInvocation 实例在调用 Action 的过程前后,涉及到相关拦截器(Intercepter)的调用。
⑥. Action 执行完毕,ActionInvocation 负责根据 struts.xml 中的配置找到对应的返回结果。调用结果的 execute 方法,渲染结果。
⑦. 执行各个拦截器 invocation.invoke() 之后的代码
⑧. 把结果发送到客户端(详见该图)
ActionProxy是Action的一个代理类,也就是说Action的调用是通过ActionProxy实现的,其实就是调用了ActionProxy.execute()方法,而该方法又调用了ActionInvocation.invoke()方法。
问题128:为什么要使用 Struts2 & Struts2 的优点:
①. 基于 MVC 架构,框架结构清晰。
②. 使用 OGNL: OGNL 可以快捷的访问值栈中的数据、调用值栈中对象的方法(Object-Graph Navigation Language)
③. 拦截器: Struts2 的拦截器是一个 Action 级别的 AOP, Struts2 中的许多特性都是通过拦截器来实现的, 例如异常处理,文件上传,验证等。拦截器是可配置与重用的
④. 多种表现层技术. 如:JSP、FreeMarker、Velocity 等
问题129:Struts2 如何访问 HttpServletRequest、HttpSession、ServletContext 三个域对象 ?
①. 与 Servlet API 解耦的访问方式
> 通过 ActionContext 访问域对象对应的 Map 对象
> 通过实现 Aware 接口使 Struts2 注入对应的 Map 对象
②. 与 Servlet API 耦合的访问方式
> 通过 ServletActionContext 直接获取 Servlet API 对象
> 通过实现 ServletXxxAware 接口的方式使 Struts2 注入对应的对
问题130: Struts2 中的默认包 struts-default 有什么作用?
①. struts-default 包是 struts2 内置的,它定义了 struts2 内部的众多拦截器和 Result 类型,而 Struts2 很多核心的功能都是通过这些内置的拦截器实现,如:从请求中把请求参数封装到action、文件上传和数据验证等等都是通过拦截器实现的。当包继承了struts-default包才能使用struts2为我们提供的这些功能。
②.struts-default 包是在 struts-default.xml 中定义,struts-default.xml 也是 Struts2 默认配置文件。Struts2 每次都会自动加载 struts-default.xml文件。
③. 通常每个包都应该继承 struts-default 包。
问题131:说出 struts2 中至少 5 个的默认拦截器
exception;fileUpload;i18n;modelDriven;params;prepare;token;tokenSession;validation 等
1)token
token拦截器进行拦截,如果为重复请求,就重定向到名为invalid.token的Result。
2)tokenSession
tokenSession拦截器与token拦截器唯一的不同是在判断某个请求为重复请求之后,并不是立即重定向到名为invalid.token的Result,而是先阻塞这个重复请求,直到浏览器响应最初的正常请求,然后就可以跳转到处理正常请求后的Result了
问题132: 谈谈 ValueStack:
①. ValueStack 贯穿整个 Action 的生命周期,保存在 request 域中,所以 ValueStack 和 request 的生命周期一样. 当 Struts2 接受一个请求时,会迅速创建 ActionContext,ValueStack,Action.然后把 Action 存放进 ValueStack,所以 Action 的实例变量可以被 OGNL 访问。请求来的时候,Action、ValueStack 的生命开始;请求结束,Action、ValueStack的生命结束
②. 值栈是多实例的,因为Action 是多例的(和 Servlet 不一样,Servelt 是单例的),而每个 Action 都有一个对应的值栈,Action 对象默认保存在栈顶;
③. ValueStack 本质上就是一个 ArrayList(查看源代码得到);
④. 使用 OGNL 访问值栈的内容时,不需要#号,而访问 request、session、application、attr 时,需要加#号;
⑤. Struts2 重写了 request 的 getAttribute 方法,所以可以使用 EL 直接访问值栈中的内容
问题133:ActionContext、ServletContext、pageContext的区别 ?
①. ActionContext Struts2 的 API:是当前的 Action 的上下文环境
②. ServletContext 和 PageContext 是 Servlet 的 API
问题134:action生命周期?
问题135:Struts2 有哪几种结果类型 ?
参看 struts-default.xml 中的相关配置:dispatcher、redirect、chain、stream, json, freemaker, velocity 等.
问题136:拦截器的生命周期与工作过程 ?
每个拦截器都是需要实现 Interceptor 接口
> init():在拦截器被创建后立即被调用, 它在拦截器的生命周期内只被调用一次. 可以在该方法中对相关资源进行必要的初始化;
> intercept(ActionInvocation invocation):每拦截一个动作请求,该方法就会被调用一次;
> destroy:该方法将在拦截器被销毁之前被调用, 它在拦截器的生命周期内也只被调用一次;
问题137:如何在 Struts2 中使用 Ajax 功能 ?
①. JSON plugin
②. DOJO plugin
③. DWR plugin
问题138:Struts框架的数据验证可分为几种类型?
表单验证(由ActionForm Bean处理):如果用户没有在表单中输入姓名,就提交表单,将生成表单验证错误
业务逻辑验证(由Action处理):如果用户在表单中输入的姓名为“Monster”,按照本应用的业务规则,不允许向“Monster”打招呼,因此将生成业务逻辑错误。
问题139:简述Form Bean的表单验证流程。
1、当用户提交了HTML表单,Struts框架自动把表单数据组装到ActionForm Bean中。
2、接下来Struts框架会调用ActionForm Bean的validate()方法进行表单验证。
3、如果validate()方法返回的ActionErrors 对象为null,或者不包含任何ActionMessage对象,就表示没有错误,数据验证通过。
4、如果ActionErrors中包含ActionMessage对象,就表示发生了验证错误,Struts框架会把ActionErrors对象保存到request范围内,然后把请求转发到恰当的视图组件,视图组件通过标签把request范围内的ActionErrors对象中包含的错误消息显示出来,提示用户修改错误。
问题140:在struts配置文件中action元素包含哪些属性和子元素?(name, class, method,converter)
path属性:指定请求访问Action的路径
type属性:指定Action的完整类名
name属性:指定需要传递给Action的ActionForm Bean
scope属性:指定ActionForm Bean的存放范围
validate属性:指定是否执行表单验证
input属性:指定当表单验证失败时的转发路径。
元素还包含一个子元素,它定义了一个请求转发路径。详见struts面试题
问题141:不用js实现页面刷新的方式?
<p>5秒之后刷新本页面:</p>
<meta http-equiv="refresh" content="5" />
<p>5秒之后转到梦之都首页:</p>
<meta http-equiv="refresh" content="5; url=http://www.dreamdu.com/" />
1.传统轮询(短轮询,meta标签或者定时ajax):此方法是利用 HTML 里面 meta 标签的刷新功能,在一定时间间隔后进行页面的转载,以此循环往复。它的最大缺点就是页面刷性给人带来的体验很差,而且服务器的压力也会比较大。定时ajax的时候后台程序容易编写,但是会返回很多无用的数据,浪费了带宽。
2.Ajax 轮询(长轮询):异步响应机制,即通过不间断的客户端 Ajax 请求,去发现服务端的变化。这种方式由于是客户端主动连接的,所以会有一定程度的延时,并且服务器的压力也不小。(后台hold连接浪费资源,同时大多数链接都是重复的,而且返回的数据没有顺序,所以不易于维护,如webQQ, facebookIM)
$(function () {
window.setInterval(function () {
$.get("${pageContext.request.contextPath}/communication/user/ajax.mvc",
{"timed": new Date().getTime()},
function (data) {
$("#logs").append("[data: " + data + " ]<br/>");
});
}, 3000);
});3.长连接:这也是我们之前所介绍的一种方式。由于它是利用客户端的现有连接实现服务器主动向客户端推送信息,所以延时的情况很少,并且由于服务端的可操控性使得服务器的压力也迅速减小。其实这种技术还有其他的实现方式,通过 Iframe,在页面上嵌入一个隐藏帧(Iframe),将其“src”属性指向一个长连接的请求,这样一来,服务端就能够源源不断的向客户端发送数据。这种方式的不足就在于:它会造成浏览器的进度栏一直显示没有加载完成,当然我们可以通过 Google 的一个称为“htmlfile”的 ActiveX 控件解决,但是毕竟他需要安装 ActiveX 控件,对于终端用户也是不合适的。
$(function () {
(function longPolling() {
$.ajax({
url: "${pageContext.request.contextPath}/communication/user/ajax.mvc",
data: {"timed": new Date().getTime()},
dataType: "text",
timeout: 5000,
error: function (XMLHttpRequest, textStatus, errorThrown) {
$("#state").append("[state: " + textStatus + ", error: " + errorThrown + " ]<br/>");
if (textStatus == "timeout") { // 请求超时
longPolling(); // 递归调用
// 其他错误,如网络错误等
} else {
longPolling();
}
},
success: function (data, textStatus) {
$("#state").append("[state: " + textStatus + ", data: { " + data + "} ]<br/>");
if (textStatus == "success") { // 请求成功
longPolling();
}
}
});
})();
});4.套接字:可以利用 Flash 的 XMLSocket 类或者 Java 的 Applet 来建立 Socket 连接,实现全双工的服务器推送,然后通过 Flash 或者 Applet 与 JavaScript 通信的接口来实现最终的数据推送。但是这种方式需要 Flash 或者 JVM 的支持,需要考虑Flash的安全问题,同样不太合适于终端用户。详见利用Flash XMLSocket实现”服务器推”技术
5.HTML5 的 WebSocket:这种方式其实与套接字一样,但是这里需要单独强调一下:它是不需要用户额外安装任何插件的。HTML5 提供了一个 WebSocket 的 JavaScript 接口,可以直接与服务端建立 Socket 连接,实现全双工通信,这种方式的服务器推送就是完全意义上的服务器推送了,没有半点模拟的成分,只是现阶段支持 HTML5 的浏览器并不多,而且一般老版本的各种浏览器基本都不支持。不过 HTML5 是一套非常好的标准,在将来,当 HTML5 流行起来以后将是我们实现服务器推送技术的不二选择。
//申请一个WebSocket对象,参数是需要连接的服务器端的地址,同http协议使用http://开头一样,
//WebSocket协议的URL使用ws://开头,另外安全的WebSocket协议使用wss://开头
var ws = new WebSocket(“ws://localhost:8080”);
//在支持WebSocket的浏览器中,在创建socket之后。可以通过onopen
//onmessage,onclose即onerror四个事件实现对socket进行响应
ws.onopen = function()
{
console.log(“open”);
ws.send(“hello”);
};
ws.onmessage = function(evt)
{
console.log(evt.data)
};
ws.onclose = function(evt)
{
console.log(“WebSocketClosed!”);
};
ws.onerror = function(evt)
{
console.log(“WebSocketError!”);
};参见Web 通信 之 长连接、长轮询(long polling)。需要支持websocket协议的专门的服务器才能工作,这样就能够在客户端和服务器之间发送非常少量的数据而不用担心HTTP字节级别的开销,非常适合移动应用。如果是只读取服务器端数据,那么用SSE即server send Event,双向通信应该用web socket! SSE用于创建到服务器的单项链接,服务器通过这个连接可以发送任何数量的数据,支持长轮询,短轮询和HTTP流,而且能在断开的时候重新链接,是实现comet的理想选择。
问题142:websocket协议和HTTP协议的区别?
WebSocket与http协议一样都是基于TCP的,所以他们都是可靠的协议,Web开发者调用的WebSocket的send函数在browser的实现中最终都是通过TCP的系统接口进行传输的。WebSocket和Http协议一样都属于应用层的协议,那么他们之间有没有什么关系呢?答案是肯定的,WebSocket在建立握手连接时,数据是通过http协议传输的,正如我们上一节所看到的“GET/chat HTTP/1.1”,这里面用到的只是http协议一些简单的字段。但是在建立连接之后,真正的数据传输阶段是不需要http协议参与的。详见 WebSocket(4)-- WebSocket与TCP、Http的关系。websocket协议需要专门的服务器才能支持。
new serverSocket的过程:
(1)三次握手,时候了后面就不执行了,web应用收到错误消息通知
(2)TCP成功了,浏览器用HTTP协议传送websocket版本号给服务器
(3)服务器收到浏览器握手请求,如果数据包数据和格式正确,版本匹配,接受本次握手,并回复,这个过程是用http协议完成的
(4)浏览器受到服务器的回复的数据包,内容格式正确本次成功,触发open方法和调用send方法发送数据,否则受到onerror!
问题143:FormData是什么?
FormData为表单序列化提供了方便,是XMLHttpRequest 2级别的内容
var oMyForm = new FormData();
oMyForm.append("username", "Groucho");
oMyForm.append("accountnum", 123456); // 数字123456被立即转换成字符串"123456"
// fileInputElement中已经包含了用户所选择的文件
oMyForm.append("userfile", fileInputElement.files[0]);
var oFileBody = "<a id="a"><b id="b">hey!</b></a>"; // Blob对象包含的文件内容
var oBlob = new Blob([oFileBody], { type: "text/xml"});
oMyForm.append("webmasterfile", oBlob);
var oReq = new XMLHttpRequest();
oReq.open("POST", "http://foo.com/submitform.php");
oReq.send(oMyForm);问题144:find和filter的区别?
find保存子元素,如果参数是DOM那么就是通过contains和compareDocumentPostion比较;而filter保存的是调用对象的一个子集。has保存的也是调用对象,如果该调用对象的子元素满足了条件!
问题145:detach和remove的区别?
detach调用的是remove,不过他的第二个参数是true,表示会保存数据,也就是会保存调用对象和子元素的所有的数据,而remove会移除所有的数据。详见两者区别
问题146:find和children的区别?
(1)children是返回直接子元素,而find获取所有的下级元素,即DOM树上的所有的元素
(2)children参数可选,而find方法必选(过滤子元素)
(3)find方法可以通过jQuery(selector,context)实现,第二个参数就是上下文
问题147:jQuery在init中做了什么事情?
(1)我们知道在jQuery构造函数中调用的是init方法,那么返回的对象就是init类型,这时候就需要继承了,也就是让init.prototype=jQuery.fn=jQuery.prototype。
这一步就是修正prototype
(2)修正constructor,因为重写了constructor为一个对象导致jQuery的constructor成了Object了,于是我们要修正constructor为jQuery
(3)一,首先判断传入的第一个参数selector是否为string类型,如果不是string类型那么走下面的“二,三,四”,否则就是走"1,2,3"
1,判断是否是创建HTML标签或者id选择器,如果是创建HTML标签那么调用parseHTML方法得到DOM数组,并且把这个数组封装到JSON对象this上,
同时,创建的时候第二个参数可以是一个对象,这时候如果对象上有jQuery的同名方法那么直接调用!(merge第一个参数为JSON情况),
如果是id选择器那么调用getElementById获取对象,然后封装到this上面!
2,判断第二个参数context如果不存在或者存在同时是对象,那么把这个对象封装成为jQuery对象,同时调用该对象的find方法!(对于class等选择器都是最终调用find方法,Sizzle对象)
二,如果selector是DOM,那么直接把DOM封装到this[0]上面,并返回这个jQuery对象!(源码中的this一直就是jQuery对象,因为这是构造函数内部this)
三,如果selector是函数,那么直接调用$(document).ready()并且把函数作为ready函数的参数执行!
四,如果传入的selector是jQuery对象,那么把参数的jQuery对象的所有信息封装到新返回的对象中!)
问题178:jQuery的parents,parent和closest区别?
parent方法:只返回该元素上一级别,即直接上级父节点,它仅能逐级查找,参数有无无关紧要,如果有参数也只能是直接上级,越级无效果
parents方法:当他返回一个父级节点后不会马上停止,而是继续查找,返回多个父节点,即返回最大返回的DOM选择区域,最大父节点
closest方法:同parents类似,不会局限于直接上级,直接上级不符合css选择器会返回更上一级查找,但是只返回第一个符合要求的节点
问题179:wrapAll,wrapInner, wrap的区别是什么?'
(1)wrapAll是用参数包裹所有的调用对象,最后达到所有调用对象都成为参数的最后一个子元素,如果调用对象不相邻那么会发生移动!
(2)wrapInner是用参数包含每一个调用对象子元素(调用对象还是这个参数对象外层的一层包裹),调用对象如果不相邻,那么不会发生移动!
(3)wrap使用调用参数包裹每一个调用对象(不是子元素),如果对象不相邻也不会移动,因为他是通过each逐个包裹的!
问题180:not, is和is():not的区别?
not():删除与指定表达式匹配的元素,
is():检查元素是否匹配指定的选择器,返回false或true,
:not()和not()相似,不同点在于可以在选择中使用它。
<p class="not">
this is a test.
</p>
<p id="test">jQuery学习</p>$(document).ready(function() {
//输出"jQuery学习"
alert($("p").not(".not").text());
//$("#test")[0]转为dom对象
//输出"this is a test"
alert($("p").not($("#test")[0]).text());
//返回true
alert($("p").is(".not"));
//输出jQuery学习
alert($("p:not(.not)").text());
});
map函数强调的是修改数组元素(只有返回值不是undefined才会放入结果数组中),grep强调的是筛选(和第三个参数比较,看返回值是true还是false),each强调的是遍历(用return false结束循环)。实例each方法和工具each方法中第一个参数是下标,第二个参数是元素;map工具函数第一个参数是元素,第二个下标,map实例函数相反!
问题182:jQuery中attr和prop方法的区别是什么?
(1)在jQuery中,attribute和property却是两个不同的概念。attribute表示HTML文档节点的属性,property表示JS对象的属性。
(2)在jQuery的底层实现中,函数attr()和prop()的功能都是通过JS原生的Element对象(如上述代码中的msg)实现的。attr()函数主要依赖的是Element对象的getAttribute()和setAttribute()两个方法。prop()函数主要依赖的则是JS中原生的对象属性获取和设置方式。
(3)虽然prop()针对的是DOM元素的property,而不是元素节点的attribute。不过DOM元素某些属性的更改也会影响到元素节点上对应的属性。例如,property的id对应attribute的id,property的className对应attribute的class。
注意:在js中这一类的属性还包括:id, title, lang, dir, className等,可以用firebug看一下property!
(4)attr()是jQuery 1.0版本就有的函数,prop()是jQuery 1.6版本新增的函数。毫无疑问,在1.6之前,你只能使用attr()函数;1.6及以后版本,你可以根据实际需要选择对应的函数。
(5)由于attr()函数操作的是文档节点的属性,因此设置的属性值只能是字符串类型,如果不是字符串类型,也会调用其toString()方法,将其转为字符串类型。prop()函数操作的是JS对象的属性,因此设置的属性值可以为包括数组和对象在内的任意类型。
(6)对于表单元素的checked、selected、disabled等属性,在jQuery 1.6之前,attr()获取这些属性的返回值为Boolean类型:如果被选中(或禁用)就返回true,否则返回false。
但是从1.6开始,使用attr()获取这些属性的返回值为String类型,如果被选中(或禁用)就返回checked、selected或disabled,否则(即元素节点没有该属性)返回undefined。并且,在某些版本中,这些属性值表示文档加载时的初始状态值,即使之后更改了这些元素的选中(或禁用)状态,对应的属性值也不会发生改变。因为jQuery认为:attribute的checked、selected、disabled就是表示该属性初始状态的值,property的checked、selected、disabled才表示该属性实时状态的值(值为true或false)。因此,在jQuery 1.6及以后版本中,请使用prop()函数来设置或获取checked、selected、disabled等属性。对于其它能够用prop()实现的操作,也尽量使用prop()函数。
问题183:jQuery中onload和ready的区别是什么?
(1)document.ready表示文档结构加载完成,不包括图片视频等非文字文件,而onload表示图片等非文字文件也加载完成
(2)document.ready与DOMContentLoaded相关,jQuery用document的DOMContentLoaded来检测/其它浏览器用onreadyStatechange表示,只要状态是load/complete就表示加载完成,只要有一个触发了就移除另外一个事件
(3)一个是注册在document上一个是window
jQuery.ready.promise = function( obj ) {
if ( !readyList ) {
readyList = jQuery.Deferred();
// Catch cases where $(document).ready() is called after the browser event has already occurred.
// we once tried to use readyState "interactive" here, but it caused issues like the one
// discovered by ChrisS here: http://bugs.jquery.com/ticket/12282#comment:15
if ( document.readyState === "complete" ) {
// Handle it asynchronously to allow scripts the opportunity to delay ready
setTimeout( jQuery.ready );
// Standards-based browsers support DOMContentLoaded
} else if ( document.addEventListener ) {
// Use the handy event callback
document.addEventListener( "DOMContentLoaded", completed, false );
// A fallback to window.onload, that will always work
window.addEventListener( "load", completed, false );
// If IE event model is used
} else {
// Ensure firing before onload, maybe late but safe also for iframes
document.attachEvent( "onreadystatechange", completed );
// A fallback to window.onload, that will always work
window.attachEvent( "onload", completed );
// If IE and not a frame
// continually check to see if the document is ready
var top = false;
try {
top = window.frameElement == null && document.documentElement;
} catch(e) {}
if ( top && top.doScroll ) {
(function doScrollCheck() {
if ( !jQuery.isReady ) {
try {
// Use the trick by Diego Perini
// http://javascript.nwbox.com/IEContentLoaded/
top.doScroll("left");
} catch(e) {
return setTimeout( doScrollCheck, 50 );
}
// detach all dom ready events
detach();
// and execute any waiting functions
jQuery.ready();
}
})();
}
}
}
return readyList.promise( obj );
};内部数据的方式;delegateType等解决focus/blur等不冒泡!
问题185:知道CSS预处理器吗?
CSS 预处理器是一种语言用来为 CSS 增加一些编程的的特性,无需考虑浏览器的兼容性问题,例如你可以在 CSS 中使用变量、简单的程序逻辑、函数等等在编程语言中的一些基本技巧,可以让你的 CSS 更见简洁,适应性更强,代码更直观等诸多好处
问题186:如何做函数绑定?
function bind(fn,context)
{
var args=Array.prototype.slice.call(arguments,2);
return function()
{
var innerArg=Array.prototype.slice.call(arguments);
var finalArg=args.concat(innerArg);
return fn.apply(context,finalArg);
}
}
var arr=[[1,2],[3,4]];
var result=[].concat.apply([],arr);
//打印[1, 2, 3, 4]
console.log(result); function htmlEscape(text)
{
return text.replace(/[<>"&]/g,function(match,pos,orignalText)
{
switch(match)
{
case:"<":
return "<";
case:">":
return ">";
case:"&":
return "&";
case:"\"":
return """;
}
})
}
E={
proxy:function(fn,context)
{
return function()
{
fn.call(context);
}
},
addHandler:function(elem,type,handler)
{
if(elem.addEventListener)
{
elem.addEventListener(type,handler,false);//冒泡阶段
}else if(elem.attachEvent)
{
elem.attachEvent("on"+type,E.proxy(handler,elem));
}else
{
elem['on'+type]=handler;
}
},
removeHandler:function(elem,type,handler)
{
if(elem.removeEventListener)
{
elem.removeListener(type,handler,false);
}else if(elem.detachEvent)
{
elem.detachEvent('on'+type,handler);
}else
{
elem['on'+type]=null;
}
}
}什么是JavaScript
JavaScript是一种基于对象(Object)和事件驱动(Event Driven)并具有相对安全性的客户端脚本语言。同时也是一种广泛用于客户端Web开发的脚本语言,常用来给HTML网页添加动态功能,比如响应用户的各种操作。它最初由网景公司(Netscape)的Brendan Eich设计,是一种动态、弱类型、基于原型的语言,内置支持类。
什么特点?
面向对象;解释执行;安全性高(不能访问本地磁盘,不能访问网络资源修改);跨平台性;事件驱动;弱类型。即 "对象解释安跨事弱(安化是弱)"
缺点:浏览器支持不一致。详见 JavaScript特点、优缺点及常用框架
问题191:console.log可以传入多个参数?
var people = "Alex";
var years = 42;
console.log("%s is %d years old.", people, years);
//console.log可以传入多个参数
console.log("覃亮",'我爱你','你在那里');问题192:知道那些常用的布局以及实现方法是什么?
负数margin方法可以满足中间预先加载,aside最后加载:
<!--负数margin方法,这种方式可以满足main模块提前加载的情况,第二,这种负数margin为了实现左右间距要利用一个包裹边框 第三,不要给内部设置100%要利用
块状元素的流体布局特征-->
<div id="main" style="width:100%;float:left">
<div style="background-color:#ccc;margin:0 210px;height:100px;"></div>
</div>
<div id="left" style="width:200px;float:left;height:100px;background-color:green;margin-left:-100%;"></div>
<div id="right" style="width:200px;float:left;height:100px;background-color:yellow;margin-left:-200px;"></div><div id="left" style="position:absolute;width:200px;background-color:#ccc;height:100px;left:0;top:0;"></div>
<div id="main" style="background-color:red;height:100px;margin:0 210px;"></div>
<div id="right" style="width:200px;background-color:yellow;height:100px;position:absolute;top:0;right:0;"></div><!--这里通过自身浮动法来完成三栏效果,思路:通过浮动跟随特效的完成,只有inline元素会发现float元素,其他的div块状元素不会发现float元素
会直接插在浮动元素的后面!
测试效果:
第一步:去除marign
第二步:去除background-color-->
<div id="left" style="width:200px;height:100px;background-color:#ccc;float:left;"></div>
<div id="right" style="width:200px;height:100px;background-color:yellow;float:right;"></div>
<div id="main" style="background-color:black;height:100px;margin:0 210px;"></div>
问题193:js为什么会导致精度丢失?
(1)如果8进制0后面的数字超过了8那么就会自动变成10进制!
(2)浮点数保存的内存空间是整数的两倍,因此ECMAScript会不失时机的将浮点数转化为整数,如本身就是整数的情况或者小数点没有跟任何数字
(3)浮点数的最高精度是17位(17位后面可能有数字),但是在进行算数运算的时候精确度远远不如整数,因此永远不要测试某个特点的浮点数值
if(a+b==0.3)//这时候如果是0.1和0.2就是false;如果是0.05和0.25就是true!这是IEEE754数值浮点计算的通病,而ECMA不是独家(Python和Java)
</script>
(4)最小数保存在Number.MIN_VALUE最大保存在Number.MAX_VALUE中,不在这个返回就是Infinity!如Number.NEGATIVE_INFINITY和Number.POSITIVE_INFINITY!
(5)计算机的二进制实现和位数限制有些数无法有限表示。就像一些无理数不能有限表示,如 圆周率 3.1415926...,1.3333... 等。JS 遵循 IEEE 754 规范,采用双精度存储(double precision),占用 64 bit。1位用来表示符号位,11位用来表示指数,52位表示尾数。此时只能模仿十进制进行四舍五入了,但是二进制只有 0 和 1 两个,于是变为 0 舍 1 入。这即是计算机中部分浮点数运算时出现误差,丢失精度的根本原因(可以知道看似有穷的数字, 在计算机的二进制表示里却是无穷的,由于存储位数限制因此存在“舍去”,精度丢失就发生了)。
(6)解决办法:把小数放到位整数(乘倍数),再缩小回原来倍数(除倍数)
// 0.1 + 0.2
(0.1*10 + 0.2*10) / 10 == 0.3 // true// toFixed 修复
function toFixed(num, s) {
var times = Math.pow(10, s)
//如果原来的小数小于0.5那么加上0.5然后parseInt还是没有!
var des = num * times + 0.5
//为了使得四舍五入,之所以要parseInt是因为我们只需要整数部分的位数!
des = parseInt(des, 10) / times;
return des + ''
}
console.log(toFixed(0.6263,2));
//打印0.63
console.log(63.56/100);
//打印0.6356问题194:那些js容易混淆的计算结果?记住下面的规律就行了。
总之:加法运算如果有了一个字符串那么所有的都要变成字符串;减法运算只要有一个不是数字那么就转化为数字;大于号等于号小于号比较时候只要有一个数字那么都转化为数字,如果有一个是布尔值那么也要转化为数字,因为最主要还是数字的比较
console.log(typeof ("11"+2-"1"));//打印number//情况一:等号的比较的时候:(1)只要有布尔值不管什么情况都把它转化为数字再说;(2)数值和字符串在一起转化为数字,但是是数字和字符串两者同时出现才行;(3)undfined和null在比较的时候不能转化为任意值,所以如undefined==0或者null==0都是false
var undefined;
undefined == null;
// true
1 == true;
// true
2 == true;
// false
0 == false;
// true
0 == '';
// true
NaN == NaN;
// false
[] == false;
//false转化为0,而[]调用valueOf得到"",然后""转化为数字就是0!
[] == ![];
//和上面一样,但是要注意NaN!=NaN返回的是true!
if([]){console.log("[]被转化成了true,因为相当于new Array这种形式,同时{}也是一样的,本质上他们就是对象!");}
//情况二:如果是减法,(数值为大),那么所有的基本数据类型如字符串,布尔值,null,undefined全部调用Number转化为数值,然后计算!
//如果是对象那么调用valueOf/toString获取基本值,然后计算!如果有一个为NAN结果就是NAN!
console.log(typeof ("11"+2-"1"));
//是number类型
//情况三:如果是加号运算,(字符串为大)。只要有一个操作数是字符串那么就把另外一个转化为字符串。如果是对象,数值或者布尔值就调用toString方法
//如果是undefined或者null也是调用String函数转化为字符串
//注意:只要是加法或者减法,只要能把Infinity抵消掉,那么就是NaN,否则就是正负Infinity!
//情况四:如果是%,那么不管分子(儿子)多么厉害,只要分母(母亲)不厉害都是NaN!翻译:只要分子是Infinity,不管分母是多少都是NaN;不管分子是多少,只要分母是0都是Infinity!
//如果被除数是有限大的数值而除数是无穷大,那么就是被除数;如果被除数是0那么结果就是0!
console.log(0/Infinity);
//打印0
console.log(3/Infinity);
//打印0
//情况五:乘法运算,需要注意的就是Infinity乘以0是NaN,其它如有一个数是NaN就是结果NaN,Infinity*Infinity=Infinity。对于其它类型全部调用Number转化为数字!
console.log(0*Infinity);
//打印NaN
console.log(Infinity*Infinity);
//打印Infinity
//情况六:除法运算,需要注意的是其它类型全部调用了Number进行数值转化。需要注意的是Infinity/Infinity和0/0的情况,返回值都是NaN!
console.log(Infinity/Infinity);
console.log(0/0);
//都是NaN详见搞定所有计算题。如果是字符串和数值在一起比较的时候会把字符串变成数值,但是这仅仅是在==比较的时候,在计算的时候字符串的优先级是第一的。
问题195:如何按照特定的属性对对象排序?
function compare(obj1,obj2)
{
//如果第一个参数应该在前面那么就是"前面是负数,即前夫"
//这里是a>b返回负数,表示大的数在前面,即逆序排列!
if(obj1.name>obj2.name)
{
return -1;
}else if(obj1.name==obj2.name)
{
return 0;
}else
{
return 1;
}
}
//逆序排列,按照名字先后顺序排列
console.log([{name:"qinliang"},{name:"fkl"},{name:"qinyy"}].sort(compare));var result=[];
function fn(n){
//典型的斐波那契数列
if(n==1){
return 1;
}else if(n==2){
return 1;
}else{
if(result[n]){
return result[n];
}else{
//argument.callee()表示fn()
result[n]=arguments.callee(n-1)+arguments.callee(n-2);
return result[n];
}
}
} var iArray = [];
function getRandom(istart, iend){
//Math.random需要乘以istart
var iChoice = iend - istart +1;
//Math.random实际上是断尾的,是获取[0,1)之间的一个数
return Math.floor(Math.random()*iChoice + istart);
}
//随机去除10-100之间的10个数,然后排序
for(var i=0; i<10; i++){
iArray.push(getRandom(10,100));
}
console.log(iArray);src用于替换当前元素,href用于在当前文档和引用资源之间确立联系。src是source的缩写,指向外部资源的位置,指向的内容将会 嵌入到文档中当前标签所在位置;在请求src资源时会将其指向的资源下载并应用到文档内,例如js脚本,img图片和frame等元素。
<script src =”js.js”></script>
当浏览器解析到该元素时,会暂停其他资源的下载和处理, 直到将该资源加载、编译、执行完毕,图片和框架等元素也如此,类似于将所指向资源嵌入当前标签内。这也是为什么将js脚本放在底部而不是头部。
href是Hypertext Reference的缩写,指向网络资源所在位置,建立和当前元素(锚点)或当前文档(链接)之间的链接,如果我们在文档中添加
<link href=”common.css” rel=”stylesheet”/>
那么浏览器会识别该文档为css文件, 就会并行下载资源并且不会停止对当前文档的处理。这也是为什么建议使用link方式来加载css,而不是使用@import方式。
问题199:rgba()和opacity的透明效果有什么不同?
rgba()和opacity都能实现透明效果,但最大的不同是opacity作用于元素,以及元素内的所有内容的透明度,而rgba()只作用于元素的颜色或其背景色。(设置rgba透明的元素的子元素不会继承透明效果!)
问题200:知道什么是微格式吗?谈谈理解。在前端构建中应该考虑微格式吗?
(1)微格式(Microformats)是一种让机器可读的语义化XHTML词汇的集合,是结构化数据的开放标准。是为特殊应用而制定的特殊格式。优点:将智能数据添加到网页上,让网站内容在搜索引擎结果界面可以显示额外的提示。
(2)出现了很多自定义的属性,如itemscope, itemtype, itemprop等。这些属性就是方面机器识别的特定的标记
(3)给元素添加额外的语义东西,可以使用自定义data属性(data-*). 但是,自定义data属性只是纯粹的属性,而微数据有特定的规范,有特定属性名称的词汇表,且更多是服务于现实世界,在这方面是很强大的。自定义属性等如itemScope,itemProp等等 详见HTML5扩展之微数据与丰富网页摘要
问题201:几种舍入有什么区别?
ceil, floor, round。详见 Math ceil()、floor()、round()方法
问题202:如何判断script加载完成?
function loadScript(url,callback)
{
var script=document.createElement('script');
script.type='text/javascript';
if(script.readyState)//IE浏览器
{
script.onreadyStateChange=function()
{
if(script.readyState=='loaded'||script.readyState=='complete')
{//是loaded和complete而不是interative!
callback();
script.onreadyStateChange=null;
script=null;//解除引用
}
}
}else{
script.οnlοad=function()
{
callback();
}
}
script.src=url;//添加
}数据属性:
Object.preventExtension:
var obj={name:'qinliang'};
Object.preventExtensions(obj);
obj.sex='male';
//在非严格模式下继续赋值然后获取得到undefined,在严格模式下会直接抛出错误configurable是否可以delete,是否可以修改属性特性或者把属性修改为访问器属性defineProperty(Object.seal)
var obj={name:'qinlaing'};
Object.seal(obj);
//seal是第二个封闭的级别,因此这时候的preventExtension是true
delete obj.name;
console.log(obj.name);
//此时是无法删除的Writtable属性是否可以修改属性的值(Object.freeze)
var obj={name:'qinlaing'};
Object.freeze(obj);
//这时候preventExtension调用了,configurable为false,同时writtable也为false
//没法添加新属性,没法delete,没法修改访问器属性:configurable同样的含义
enumerable同样的含义
get读取属性的时候函数
set设置属性的时候的函数
问题204: ECMAScript对象类型有那些?
(1) 本地对象Object、Function、Array、String、Boolean、Number、Date、RegExp、Error、EvalError、RangeError、ReferenceError、SyntaxError、TypeError、URIError
(2) 内置对象,开发者不用明确实例化,只有Gblobal,Math对象
(3) 宿主对象,如DOM,BOM等由宿主提供的对象
问题205:如何克隆一个对象在js中?
function clone(obj) {
// Handle the 3 simple types, and null or undefined
if (null == obj || "object" != typeof obj) return obj;
// Handle Date
if (obj instanceof Date) {
var copy = new Date();
copy.setTime(obj.getTime());
return copy;
}
// Handle Array
if (obj instanceof Array) {
var copy = [];
for (var i = 0, var len = obj.length; i < len; ++i) {
copy[i] = clone(obj[i]);
}
return copy;
}
// Handle Object
if (obj instanceof Object) {
var copy = {};
for (var attr in obj) {
if (obj.hasOwnProperty(attr)) copy[attr] = clone(obj[attr]);
}
return copy;
}
throw new Error("Unable to copy obj! Its type isn't supported.");
}一下是对象和数组的克隆
function clone(obj)
{
var o,i,j,k;
if(typeof(obj)!="object" || obj===null)return obj;
//如果typeof obj不是对象那么就直接返回!
if(obj instanceof(Array))
{
//如果是数组那么用for循环
o=[];
i=0;j=obj.length;
for(;i<j;i++)
{
if(typeof(obj[i])=="object" && obj[i]!=null)
{
o[i]=arguments.callee(obj[i]);
}
else
{
o[i]=obj[i];
}
}
}
else//如果不是数组用for..in
{
o={};
for(i in obj)
{
if(typeof(obj[i])=="object" && obj[i]!=null)
{
o[i]=arguments.callee(obj[i]);
}
else
{
o[i]=obj[i];
}
}
}
return o;
}
var obj={name:"qinliang",sex:"male",school:{name:"DLUT",location:"Dalian"}};
var result=clone(obj);
//克隆对象
console.log(result);
console.log(clone([1,2,3]));
//克隆数组
console.log(clone(123));
//直接返回不是克隆的push,pop是栈方法;shift用于去除栈中元素,unshift用于往栈中添加一个元素
var arr=[1,2,3];
//插入0,1替换
//第一部分:插入的用法(在第几项插入)
//在第一项后面插入4和5(这时候就是在下标为1的地方插入)
arr.splice(0,0,4,5);
console.log(arr);//[4, 5, 1, 2, 3]
//在5后面插入6
arr.splice(2,0,6);
console.log(arr);//[4, 5, 6, 1, 2, 3]
//第二部分:替换的用法(中间参数为1,只能逐个替换)
//把4,5,6替换成0(这时候只能一个一个替换,不能三个一起替换)
arr.splice(0,1,0);
arr.splice(1,1,0);
arr.splice(2,1,0);
console.log(arr);//[0, 0, 0, 1, 2, 3]
//第三部分:删除(第一项的位置和项数目,返回值为删除的项的值)
arr.splice(0,3);
console.log(arr);//打印[1, 2, 3]
//第四部分:下面展示indexOf函数的特殊用法(indexOf用于寻找参数在数组中的下标,第二个参数是负数如果加上length依然为负数那么从头开始查,和lastIndexOf类似)
console.log(arr.indexOf(1,-1));//返回-1,倒数第一项不存在1
console.log(arr.indexOf(3,-1));//打印2,下标为2
//lastIndexOf和indexOf的比较,indexOf从头往后查找,而lastIndexOf表示从尾部向前面查找!第二个参数用于lastIndexOf就是从后面往前查找的坐标开始
console.log(arr.lastIndexOf(3,1));//打印-1,因为从下标为1往前查找不存在3
console.log(arr.indexOf(3,1));//打印2 var numbers=[1,2,3,1,'abv',' ad '];
//第一部分:forEach方法,对每一个项执行一个函数,但是注意该方法没有返回值,同时该方法只是遍历,要修改用
//map方法,而且退出循环用return false!
//js中是元素下标,只是jQuery高反了
var result=numbers.forEach(function(elem,index,arr)
{
if(index===3)
{
return false;
}else
{
console.log(elem);
}
})
console.log(result);//undefined
console.log(numbers);//[1, 2, 3, 1]
//第二部分:用map方法对元素进行修改,这个方法具有返回值,内部用return就可以了!
var result=numbers.map(function(item,index,arr)
{
return item*2;
})
console.log(result);//[2, 4, 6, 2]
console.log(numbers);//[1, 2, 3, 1]原来的数组不会改变
//这里是map的特殊的用法
var upperCase=numbers.map(Function.prototype.call,String.prototype.toUpperCase);
console.log(upperCase);
var trim=numbers.map(Function.prototype.call,String.prototype.trim);
console.log(trim);
//第三部分:用filter方法对数组中的元素进行筛选,这个方法和map一样有返回值,不修改原来的数组
var filterResult=numbers.filter(function(item,index,arr)
{
return item>1;//选择大于1的数
})
console.log(filterResult);//打印[2,3]
//第四部分:every函数,每一个满足才行,返回值是true/false
var everyResult=numbers.every(function(item,index,arr)
{
return item>1;
})
console.log(everyResult);//打印false
//第五部分:some函数,返回值是false/true
var someResult=numbers.some(function(item,item,arr)
{
return item>1;
});
console.log(someResult);//打印truevar start=Date.now();//获取当前事件毫秒数
var end=+new Date();//获取当前事件毫秒数问题207:常见的正则表达式,如QQ号
QQ号码:/[1-9][0-9]{4,}/ 因为QQ号从10000开始的
Email邮箱: /^(\w)+(\.\w+)*@(\w)+((\.\w+)+)$/;第一个必须是(\w)+也就是至少有一个,后面也是(\.\w+)+因为必须至少一次!(不需要捕获组用?:)
电话号码:/^1[3|5|8][0-9]\d{4,8}/;如果匹配失败表示不是有效的电话号码,或者说不是有效的电话号码前7位!
身份证号码:/(^\d{15}$)|(^\d{18}$)|(^\d{17}[\d|X\x]$)/ 要么是18位数字,要么是15位数字,要么18为的前17位为数字后一位是X或者x!
匹配中文:如果是简单中文用/[\u4e00-\u9fa5]+/,这是中文的unicode范围;或者匹配非中文\[\u0000-\u00ff]\或者]\[\x00-\xff]\匹配双字节的方法
String.prototype.lengthB=function()
{
var s=this.replace(/[^\x00-\xff]/g,'**');
return s.length;
}问题208:Array类一些特别方法的使用?push,concat
var a=[1,2],b=[3,4,5];
var c=[[9,10],[3,4]];
//方法1:用concat连接两个数组
console.log(a.concat(b));
//一个数组里面的元素是数组,那么可以用concat连接,这也是jQuery的map方法的做法
console.log(Array.prototype.concat.apply([],c));
//方法2:用push方法来合并数组,不过这时候合并成的数组就是第一个参数的,返回值是数组项的个数!
[].push.apply(a,b);
console.log(a);问题209:如何删除一个class和添加一个class?用replace方法正则表达式匹配!第一个参数是匹配,接下来是捕获组,接下来是下标,接下来是源字符串!
var sec=document.querySelector('section');
//第一步:添加class
sec.className+=" love";
//第二步:记住,这时候添加class必须要前面有空格
//这时候我们再次删除一个className为love!
function func($1,$2,$3,$4,$5)
{
//$1表示匹配的文本,$2表示第一个捕获组,第二个是第二个捕获组,第三个是匹配文本在字符串中的下标,第四个是字符串本身
return $2+$3;
//如果是匹配了第一个,那么$2是没有空格的,这时候$3有空格,所以在前面多出了一个空格也是没有关系的;如果替换了中间的那么这时候就保留多了空格了
//当然这里可以用if判断!
}
//要替换的一个类名前面只有两种可能性:开始符号或者空格。同时,要替换的类名后面也只有两个种可能性:空格或者结束符!
var result=sec.className.replace(/(^|\s*)liang($|\s*)/,func);
sec.className=result; var classNames=document.querySelector('section').className.split(/\s/);
//删除类名
for(var i=0,j=classNames.length;i<j;i++)
{
if("liang"===classNames[i])
{
classNames.splice(i,1);
}
}
document.querySelector('section').className=classNames.join(' ');
//如果可以用classList的remove,add,toggle等属性!后者相当于同时调用了preventDefault和stopPropagation!
问题211:js中encodeURL和encodeURIComponent和escape的区别?(unicode vs UTF-8;整体编码 vs部分编码;jQuery的param就是用encodeURIComponent)
(1)“只有字母和数字[0-9a-zA-Z]、一些特殊符号“$-_.+!*'(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于 URL。”
(2)不同的操作系统、不同的浏览器、不同的网页字符集,将导致完全不同的编码结果。如果程序员要把每一种结果都考虑进去,是不是太恐怖了?有没有办法,能够保证客户端只用一种编码方法向服务器发出请求?回答是有的,就是使用Javascript先对URL编码,然后再向服务器提交,不要给浏览器插手的机会。因为Javascript的输出总是一致的,所以就保证了服务器得到的数据是格式统一的。
(3)escape()不能直接用于URL编码,它的真正作用是返回一个字符的Unicode编码值。比如“春节”的返回结果是%u6625%u8282,也就是说在Unicode字符集中,“春”是第6625个(十六进制)字符,“节”是第8282个(十六进制)字符。它的具体规则是,除了ASCII字母、数字、标点符号“@ * _ + - . /”以外,对其他所有字符进行编码。在\u0000到\u00ff之间的符号被转成%xx的形式,其余符号被转成%uxxxx的形式。对应的解码函数是 unescape()。
(4)首先,无论网页的原始编码是什么,一旦被Javascript编码,就都变为unicode字符。也就是说,Javascipt函数的输入和输出,默认都是Unicode字符。这一点对下面两个函数也适用。其次,escape()不对“+”编码。但是我们知道,网页在提交表单的时候,如果有空格,则会被转化为+字符。服务器处理数据的时候,会把+号处理成空格。所以,使用的时候要小心。
(5)encodeURI()是Javascript中真正用来对URL编码的函数。它着眼于对整个URL进行编码,因此除了常见的符号以外,对其他一些在网址中有特殊含义的符号“; / ? : @ & = + $ , #”,也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。需要注意的是,它不对单引号'编码。
(6)最后一个Javascript编码函数是encodeURIComponent()。与encodeURI()的区别是,它用于对URL的组成部分进行个别编码,而不用于对整个URL进行编码。因此,“; / ? : @ & = + $ , #”,这些在encodeURI()中不被编码的符号,在encodeURIComponent()中统统会被编码。至于具体的编码方法,两者是一样。[转]URL汉字编码问题(及乱码解决) 字符编码:GBK、GB2312、UTF-8
问题212:CSS3中常见的一些问题?
多列布局:
(1)column-count,column-width,columns(前两个属性的结合),max-height/height设置了以后排列,column-gap(默认是1em),column-rule(width/style/color复合属性),column-span(定义子元素跨列多少,可以是none/all),column-fill(定义多列具有相同的高度效果,属性值可以是auto/balance)
(2)css3过渡时候用到了如transition-property,transition-duration,transition-timing-function,transition-delay等
(3)box-sizing:content-box|border-box|inherit其中content-box就是W3C标准盒模型,而border-box就是IE6盒模型
(4)CSS3背景添加了background-origin(改变背景图片定位的起始点,属性值为padding-box/border-box/content-box),background-clip(背景图片的剪裁区域,padding-box/border-box/content-box),background-size(指定背景图片的尺寸,控制背景图片在水平和垂直方向上的缩放,可以控制图片拉伸覆盖背景区域的方式甚至可以截取背景图片)等属性(auto|length|百分比(相对于元素的宽度计算并不是背景图片宽度计算/cover/contain(将背景图片保持本身的宽度和高度比例,将背景图片缩放到宽度和高度正好适应所定义背景的区域)))
(5)RGBA在RGB的基础上增加了透明通道设置,其中通道值的返回是0~1,其中0表示完全透明,而1表示完全不透明。opacity只能为背景设置透明度,但是rgba可以用于任何颜色的属性设置,如border-color等。
(6)HSL(Hue,Saturation,Lightness),HSLA(加上Opacity值越大透明度越低)。使用RGBA很难一眼辨认他是什么颜色,需要一定时间去研究或者借助工具来完成,同时如果对一个颜色进行调整就不得不对每一项参数进行修改。使用HSL/HSLA获取一个颜色,没有必要向RGB一样调整红,绿,蓝三个颜色,只需要将色调值设置为一个特定的值,只要记住360和0度代表同一种颜色也就是纯红色,然后按照彩虹的颜色顺序排列,最终回到纯红色就可以了。通过0~360选定一个色调之后,想将颜色变暗或者变亮调整L就可以,变浓或者变淡用S就可以了。
(7)对于RGBA/HSLA对于IE来说兼容:一般只要在前面设置一个其它颜色(没有透明色)后跟着一个RGBA/HSLA颜色模式,这样就可以了!
(8)3D变形函数包括rotateX,rotateY,rotate3d,translateZ,translate3d,scaleZ,scale3d等(translateX,translateY,scaleX,scaleY,skewX,skewY等)。transform-origion(元素的中心点位置默认情况下在X和Y轴的50%处),transform-style(3D空间一个属性,指定嵌套元素如何在3D空间中显示,可以是flat/preserve-3d),perspective(设置查看者的位置并将可视内容映射到一个视锥上,继而投到一个2d视平面上),persperstive-origion,backface-visibility等
网格布局:
(1)就像表格一样,网格布局可以让Web设计师根据元素按列或行对齐排列,但他和表格不同,网格布局没有内容结构,从而使各种布局不可能与表格一样。例如,一个网格布局中的子元素都可以定位自己的位置,这样他们可以重叠和类似元素定位。
(2)没有内容结构的网格布局有助于使用流体、调整顺序等技术管理或更改布局。通过结合CSS的媒体查询属性,可以控制网格布局容器和他们的子元素,使用页面的布局根据不同的设备和可用空间调整元素的显示风格与定位,而不需要去改变文档结构的本质内容。
(3)flexbox是一维布局,他只能在一条直线上放置你的内容区块;而grid是一个二维布局。前面也简单说到,你可以根据你的设计需求,将内容区块放置到任何你想要放的地方。
(4)grid网格布局涉及的属性,如grid-column,grid-row,grid-column-span,grid-row-span,grid-column-align,grid-row-align,z-index,grid-columns,grid-rows(定义网格线名称)等等
(5)用在chrome地址栏中输入:chrome://flags可以开启chrome浏览器的一些特性
详细内容参见CSS3网格布局介绍——网格的运行 Grid布局的一些问题 CSS Grid布局:浏览器开启CSS Grid Layout
问题212:File API介绍一下?
File API:
(1)不能直接访问用户计算机中的文件一直是web应用开发中的一大障碍。2000以前唯一的方式就是用<input type='file'/>。File API的宗旨就是为web开发人员提供一种安全的方式,以便在客户端访问用户计算机中的文件,并且更好的对文件进行操作。IE10,Chrome等支持。HTML5在DOM中为文件输入元素添加了一个files集合,在通过文件输入字段选择一个或者多个文件的时候files集合中就保存了一组File对象,每个File对象对应一个File文件,该文件有name,size,type,lastModifiedDate(只有chrome)等属性.
(2)上面仅仅是一个小进步,FileReader类型甚至还可以读取文件中的数据。是一种异步文件读取机制,可以把FileReader想象程XMLHttpRequest区别只是前者读取的是文件系统,而不是远程服务器。提供了readAsText, readAsDataURL,readAsBinaryString,readyAsArrayBuffer方法。由于是异步的,所以还提供了几个事件如progress, error,load事件,分别表示是否读取了新数据,是否发生了错误,是否读完了整个文件。每隔50ms就可以触发一次progress事件,通过该事件可以获取到xhr的progress相同的信息,如lengthComputable,loaded, total。另外,尽管可能没有包含全部数据,但每次progress事件中都可以通过FileReader的result读取到文件的内容。如果发生了错误,那么error事件触发,这时候相关信息就保存到FileReader的error属性中,该属性保存一个对象,该对象只有一个code属性,1表示未找到文件,2表示安全性错误,3表示中断,4表示文件不可读,5表示编码错误。文件成功加载就触发load!
(3)如果中断调用abort方法,如果读取部分用slice方法,如mozSlice/webkitSlice等。Blob类型有一个size和type属性,也支持slice。
(4)对象URL指的是引用保存在File或Blob中数据的URL,使用对象URL的好处是可以不必把文件读取到js中而直接使用文件内容。
function createObjectURL(blob)
{
if(window.URL)
{
return window.URL.createObjectURL(blob);//window.URL.revokeObjectURL
}else if(window.webkitURL)
{
window.webkitURL.createObjectURL(blob);//window.webkitURL.revokeObjectURL
}else{
return null;
}
}这个函数返回一个字符串,指向内存中的地址,因为这个字符串是URL,所以在DOM中可以直接使用。img会自动找到相应的内存地址直接读取数据并且显示在页面中。如果不需要用revokeObjectURL就可以了,不过和上面一样要兼容!
(5)拖放文件,把桌面的文件拖放到浏览器中也可以触发drop事件,而且在event.dataTransfer.files读取被放置的文件,此时是一个File对象,与通过文件输入字段取得的File一样。 必须首先去掉dragenter,dragover,drop默认行为。
(6 )流行的功能,结合XMLHttpRequest和拖放文件实现上传。通过File API能够访问到文件内容,利用这一点就可以通过XHR直接把文件上传到服务器,当然把文件内容放到send方法中,在通过post请求很容易上传,但这时候传递的是文件的内容,因而服务器必须收集提交的内容,然后把他们保存到另外一个文件中。所以我们可以用FormData。
var formdata=new FormData().append()file[i];xhr.send(formdata);
//判断浏览器是否支持FileReader接口
if(typeof FileReader == 'undefined'){
result.InnerHTML="<p>你的浏览器不支持FileReader接口!</p>";
//使选择控件不可操作
file.setAttribute("disabled","disabled");
}
function readAsDataURL(){
//检验是否为图像文件
var file = document.getElementById("file").files[0];
if(!/image\/\w+/.test(file.type)){
alert("看清楚,这个需要图片!");
return false;
}
var reader = new FileReader();
//将文件以Data URL形式读入页面
reader.readAsDataURL(file);
reader.οnlοad=function(e){
var result=document.getElementById("result");
//显示文件 ,我们直接把reader对象的result属性作为image对象的src属性就可以了
result.innerHTML='<img src="' + reader.result +'" alt="" />';
}
}
//传入一个Blob对象,然后读取数据的结果作为二进制字符串的形式放到FileReader的result属性中。
function readAsBinaryString(){
var file = document.getElementById("file").files[0];
var reader = new FileReader();
reader.readAsBinaryString(file);
reader.οnlοad=function(f){
var result=document.getElementById("result");
//显示文件
result.innerHTML=this.result;
}
}
//第一个参数传入Blog对象,然后第二个参数传入编码格式,异步将数据读取成功后放到result属性中,读取的内容是普通的文本字符串的形式。
function readAsText(){
var file = document.getElementById("file").files[0];
var reader = new FileReader();
//将文件以文本形式读入页面
reader.readAsText(file);
reader.οnlοad=function(f){
var result=document.getElementById("result");
//显示文件
result.innerHTML=this.result;
}
} 问题213:请谈一谈js中的事件委托?
如果能够绑定到document上,那么有以下优点:
(1)document对象很快就能访问,而且可以在页面任何时间点为他添加事件处理程序。也就说,只要可单机的元素出现在页面上就可以具备适当的功能
(2)只添加一个事件处理程序所需要的DOM引用少,所花的时间更少
(3)整个页面占用的内存更少,提升页面性能
(4)事件代理还有一个重要的好处,那就是方便移除事件处理程序防止内存泄漏,因为绑定的事件越少,越容易集中移除。同时代理可以代理后面在DOM中动态添加的内容
$(document).ready(function(){
var jquery=$();
//事件绑定的,但是这里面传入的是jQuery.Event对象,该对象也有target/currentTarget/delegateTarget等,返回都是jS对象
//如果要获取原生的js事件对象,那么可以用e.originalEvent对象,该对象也有target,该属性也是DOM对象!
//isTrusted如果是true表示是浏览器生成的,而false表示是开发人员生产的,如initEvent等
$('section').on('click',function(e){console.log(e.originalEvent);})
//如果要实现代理对象,那么可以如下设置(第一个是事件,第二个参数是代理,第三个是数据,第四个是回调。所以称为"事件代理数据回调")
$('section').on('click','article',{name:"qinliang"},function(e){console.log(e.data)});
//通过e.data获取数据,或者也可以通过delegate来进行事件委托
$('section').delegate('article','click',{sex:"male"},function(e){console.log(e.data);});
//对于delegate方法来说,他的逻辑和on差异不是很明显,只是把前面两个参数换了位置!
//如果是需要绑定执行一次的事件就需要用one函数,该函数和on函数的参数是完全一样的
$('section').one('click','article',{school:"DLUT"},function(e){console.log(e.data);});
}问题214:请谈一谈js中事件捕获和事件冒泡?
事件冒泡(的过程):事件从发生的目标(event.srcElement||event.target)开始,沿着文档逐层向上冒泡,到document为止。所有浏览器都支持冒泡,IE5.5以前会跳过html元素,而IE9/FF/CS一直冒泡到window对象。
事件捕获(的过程):则是从document开始,沿着文档树向下,直到事件目标为止。DOM2级规范要求从document对象向下传播,但是所有浏览器都从window对象开始捕获。大多数浏览器在捕获阶段都包含目标阶段,虽然DOM2明确要求并非如此!
关键一句:在IE浏览器中,只发生事件冒泡的过程;在W3C(或支持事件捕获的)浏览器中,先发生捕获的过程,再发生冒泡的过程。
(1)想要添加一个由捕获过程触发的事件,只能这样了:
addEventListener('click',functionname,true);//该方法在IE下报错(对象不支持此属性或方法)
注:将第三个参数设置为true,表明该事件是为捕获过程设置的。如果第三个参数为false,则等同onclick =functionname;
(2)把事件捕获和冒泡的过程统称为事件的传播
事件的传播是可以阻止的:
• 在W3C中,使用stopPropagation()方法
• 在IE下设置cancelBubble = true;
(3)在捕获的过程中stopPropagation()后,后面的冒泡过程也不会发生了~
阻止事件的默认行为,例如click <a>后的跳转~
• 在W3C中,使用preventDefault()方法;
• 在IE下设置window.event.returnValue = false;
注:不是所有的事件都能冒泡,例如:blur、focus、load、unload,。
问题215:你了解git吗?
(1)最显而易见的缺点是中央服务器的单点故障。如果宕机一小时,那么在这一小时内,谁都无法提交更新,也就无法协同工作。要 是中央服务器的磁盘发生故障,碰巧没做备份,或者备份不够及时,就还是会有丢失数据的风险。最坏的情况是彻底丢失整个项目的所有历史更改记录,而被客户端 提取出来的某些快照数据除外,但这样的话依然是个问题,你不能保证所有的数据都已经有人事先完整提取出来过。
(2)有了它你就可以将某个文件回溯到之前的状态,甚至将整个项目都回退到过去某个时间点的状态。你可以比较文件的变化细节,查出最 后是谁修改了哪个地方,从而导致出现怪异问题,又是谁在何时报告了某个功能缺陷等等。使用版本控制系统通常还意味着,就算你乱来一气把整个项目中的文件改 的改删的删,你也照样可以轻松恢复到原先的样子。但额外增加的工作量却微乎其微。(保存某一幅图片或页面布局文件的所有修订版本/记录文件的历次更新差异)
(3)Centralized Version Control Systems,简称 CVCS。分布式版本控制系统( Distributed Version Control System,简称 DVCS )面世(客户端并不只提取最新版本的文件快照,而是把原始的代码仓库完整地镜像下来。这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜 像出来的本地仓库恢复。因为每一次的提取操作,实际上都是一次对代码仓库的完整备份,更进一步,许多这类系统都可以指定和若干不同的远端代码仓库进行交互。籍此,你就可以在同一个项目中,分别和不同工作小组的人相互协作。你可以根据需要设定不同的协作流程,比如层次模型式的工作流,而这在以前的集中式系统中是无法实现的。
(4)git和其它版本控制系统的差异。Git 和其他版本控制系统的主要差别在于,Git 只关心文件数据的整体是否发生变化,而大多数其他系统则只关心文件内容的具体差异;Git 并不保存这些前后变化的差异数据。实际上,Git 更像是把变化的文件作快照后,记录在一个微型的文件系统中。每次提交更新时,它会纵览一遍所有文件的指纹信息并对文件作一快照,然后保存一个指向这次快照 的索引。为提高性能,若文件没有变化,Git 不会再次保存,而只对上次保存的快照作一链接;在 Git 中的绝大多数操作都只需要访问本地文件和资源,不用连网。但如果用 CVCS 的话,差不多所有操作都需要连接网络。因为 Git 在本地磁盘上就保存着所有当前项目的历史更新,所以处理起来速度飞快。
(5)在保存到 Git 之前,所有数据都要进行内容的校验和(checksum)计算,并将此结果作为数据的唯一标识和索引。换句话说,不可能在你修改了文件或目录之后,Git 一无所知。这项特性作为 Git 的设计哲学,建在整体架构的最底层。所以如果文件在传输时变得不完整,或者磁盘损坏导致文件数据缺失,Git 都能立即察觉。
(6)对于任何一个文件,在 Git 内都只有三种状态:已提交(committed),已修改(modified)和已暂存(staged),已提交表示该文件已经被安全地保存在本地数据库 中了;已修改表示修改了某个文件,但还没有提交保存;已暂存表示把已修改的文件放在下次提交时要保存的清单中。
(7)所谓的暂存区域只不过是个简单的文件,一般都放在 Git 目录中。有时候人们会把这个文件叫做索引文件,不过标准说法还是叫暂存区域。
(8)1. 在工作目录中修改某些文件。 2. 对修改后的文件进行快照,然后保存到暂存区域。 3. 提交更新,将保存在暂存区域的文件快照永久转储到 Git 目录中。所以,我们可以从文件所处的位置来判断状态:如果是 Git 目录中保存着的特定版本文件,就属于已提交状态;如果作了修改并已放入暂存区域,就属于已暂存状态;如果自上次取出后,作了修改但还没有放到暂存区域,就 是已修改状态。
问题216:textInput和keypress的区别?
keyPress和textInput的区别:任何可以获取焦点的元素可以触发keypress,但是只有可编辑区才触发textInput;textInput要按下可以输入实际字符键的时候才触发,但keypress在按住那些影响文本显示的键也会触发;textInput主要考虑字符,于是event.data是用户输入的字符,同时IE对该event对象还提供了inputMethod属性表示文本输入到文本框的方式,如键盘,粘贴等
问题217:变动事件
<ul id="myList">
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
<li>Item 4</li>
</ul>
注意:DOMNodeRemoved事件的目标也就是target属性是被删除的节点,而event.relatedNode包含的是对父元素的引用,这个事件触发时候元素还没有从父节点删除,因此其parentNode仍然是父节点(和event.relatedNode相同),这个事件会冒泡,因而可以在DOM的任何层次上面处理他!但是DOMNodeRemovedFromDocument事件不会冒泡,所以事件要直接绑定到自身上才行,这个事件的目标是相应的子节点或者那个被移除的节点,除此之外event不包含任何信息!DOMSubtreeModified事件,这个事件的目标是被移除节点的父节点,此时的event不包含任何信息!
DOMNodeRemoved,DOMNodeInserted,DOMSubtreeModified都是冒泡的;DOMNodeInsertedIntoDocument,DOMNodeRemovedFromDocument不冒泡
问题218:主页面和iframe进行的通信是怎么回事,父亲必须给儿子一个名字才能找到,这个名字就是name属性。
1.父窗口调用iframe中的js:child.window.child_js(this)其中child是iframe的name属性
iframe调用父窗口中的js:parent.window.parent_js(this)其中parent指代的就是父窗口
2.父窗口修改iframe中的DOM:child.window.document.getElementById('name').value="";其中child是iframe的name;或者通过frames集合进行访问
window.frames['child'].document.getElementById('name').value=''"
3.iframe修改父窗口的DOM:parent.document.getElementById('name').value='子iframe调用父亲';或者通过以下这种方式,也就是通过parent.window的形式来修改DOM,也 是可以的 parent.window.document.getElementById('name').value='调用结束'
问题219:jQuery中typeof和自定义工具函数和自定义实例函数的用法
var arr=[];
//需要实现的是arr[['object String']]='string'这种类型
$.each(['Date','String','RegExp','Boolean'],function(index,elem){
arr['['+'object '+elem+"]"]=elem.toLowerCase();
})
//为jQuery添加一个工具函数的方法
jQuery.myEach=function(obj){
return typeof obj=='object'||typeof obj=='function'?arr[{}.toString.call(obj)]||'object':typeof obj;
}
//如果需要为每一个jQuery对象添加一个方法可以用jQuery.fn.myEach!
//获取jQuery的版本号用jQuery.fn.jquery就可以了
var str=new Date();
console.log($.myEach(str));
console.log(jQuery.fn.jquery);
//上面还需要实现一个自定义的工具函数
jQuery.extend({
myEach1:function(){
return 'this is my each';
}
})
console.log(jQuery.myEach1());
//如果是为每一个元素都添加一个实例方法,这时候就需要用jQuery.fn.extend就可以了
$.each([1,2,3],function(name,sex){
console.log(name+sex);//打印namesex,记住最后一个参数只能是数组类型,因为底层调用的是apply
},['name','sex']) //保存用户数据部分:通过为每一个元素添加一个自定义属性jQueyr.expando来保存数据
$('#sec').data('name','sex');
$('#sec').data('school','DLUT');
$('#sec').on('click','article',{name:"sex"},function(e){
//这里面是回调的逻辑,这里面的event对象的handleObj保存了这个事件所有的信息
//event.data获取数据,event.delegateTarget,event.currentTarget,namespaces,origType,selector,type,guid等
console.log(e.handleObj.selector);
});
var expando=jQuery.expando;
var dom=$('#sec')[0];
var id=dom[expando];
var walhouse=jQuery.cache;
var data=walhouse[id];
console.log(data);
//这时候我们发现用户的数据是保存在data域下面的,同时绑定的事件是events域下面
//每一种类型对应的都是一个数组,如click:[]等,这里的对象就是我们说的handleObj
//jQuery.data和$('selector').data的区别是什么?
//虽然使用全局和局部的变量可以保存数据,但是变量无法缓存数据,并且并不依附于某一个元素自身
//如果使用data方法保存数据可以针对元素定义元素在数据中存取数据,避免数据被循环引用的风险
$.data($('#sec')[0],"age",23);
//jQuery的对象实例方法$.fn.data就是调用这种方式来完成的,也是将数据放在了data域下面
//如果是内部数据就要用_data方法,如下演示
$._data($('#sec')[0],'gf','fkl');
//这时候你会发现这个gf的数据是保存在和handler同样的位置的,而不是放在了data域下面了!
<span style="white-space:pre"> </span> var expando=jQuery.expando;
var dom=$('#sec')[0];
var id=dom[expando];
var walhouse=jQuery.cache;
var data=walhouse[id];
console.log(data);
//这里面用到了guid表示每一个绑定事件和保存数据的元素都有的一个唯一的属性,他的作用是
//:jQuery.guid的作用是用于事件绑定中和数据保存中,为每一个保存的数据的DOM和每一个绑定事件的回调函数分配一个唯一的guid值!但是你应该马上反应过来,上面的parseAttrs没有保存到data域下面,这就是他通过内部数据保存的结果。同时,你也应该看到内部数据和用户自定义数据在这个图上存在的共存的情况!//取消绑定事件
var func=function (){}
$('#sec').bind('click',{sex:"femal"},func);
$('#sec').unbind('click',func);
//如果是undelegate就用下面的方式来完成,也就是取消"那些元素的那些事件的那些回调函数""
//这是因为delegate在绑定事件的时候就不和别人相同是按照如下方式完成的,也就是不和on函数的前两个参数顺序一致
$('#sec').delegate('#article','click',{name:"klfang"},func);
$('#sec').undelegate('#article','click',func);
//如果是用on方法那么就用off来移除,其方法如下
$('#sec').on('click','#article',{sex:"male"},func);
$('#sec').off('click','#article',func下面这这种方式是通过一次绑定多个对象和事件处理函数的,也可以通过jQuery.event.add来完成
var data = { id: 5, name: "张三" };
var events = {
"mouseenter": function(event){
$(this).html( "你好," + event.data.name + "!");
},
"mouseleave": function(event){
$(this).html( "再见!");
}
};
//为n5绑定mouseenter mouseleave两个事件,并为其传入附加数据data
$("#sec").delegate("article",events,data);
//事件部分应该知道的内容?如jQuery.event.add
jQuery.event.add($("#child")[0],"qinliang",function(e)//绑定qinliang事件
{
console.log("child");
});
var event1=new jQuery.Event("qinliang")
jQuery.event.dispatch.call($("#child")[0],event1); 选项卡特效:
(1)难点在于布局的实现而不是特效的实现,在一个notice下面放了notice-tit和notice-con两个部分,在notice-tit中用div里面嵌套ul的方式来布局,给div一个relative定位,同时给ul一个absolute定位。同时如果notice的宽度是298px同时border是1px那么总共的宽度就是300px,这时候给notice-tit一个300px的width同时设置margin-left:-1那么就会导致ul的一部分被notice-tit覆盖住了。
(2)每一个li的宽度都是58px同时padding是1px,因此每一个li的宽度就是60px,这时候总共就是300px宽度
(3)ul穿入了notice-tit一部分,但是ul本身没有border,因此后面元素也就是li的显示仅仅靠在左边了,因此当以后把padding用border替换过后那么宽度是没有变化的,但是因为替换的border在外层notice的边框下面,所以被覆盖掉了,因此左边和右边是没有边框的!
(4)注意:设置了margin-left:-1那么后面的元素的边框会覆盖父元素的边框,即使是背景色也是会同样发生覆盖的。但是按照选项卡的理解,如果元素是padding那么把padding设置为border以后那么不会发生覆盖!
(5)如果是onmouseover那么就首先隐藏所有的元素,然后显示特定的元素也就是把display设置为block把class设置为选中的时候的class,如果是自动切换那么可能设置setTimeout还要考虑如果用户选中了那么也要切换回来!
弹出层特效(activeBar2,loadmask特效):
(1)首先要获取页面的宽度和高度,如果有滚动条那么要兼容,然后通过创建一个div元素添加到body中,让他覆盖了整个页面。
function getDocParameter()
{
if(document.compatMode=='BackCompat')//怪异模式
{
return{
docHeight:Math.max(document.body.scrollHeight,document.body.clientHeight),
docWidth:Math.max(document.body.scrollWidth,document.body.clientHeight)
}
}else//标准模式
{
return{
docHeight:Math.max(document.documentElement.scrollHeight,document.documentElement.clientHeight),
docWidth:Math.max(document.documentElement.scrollWidth,document.documentElement.clientHeight)
}
}
}放大镜特效原理:
<div id="demo">
<div id="small-box">
<div id="mark" style="background-color:red;"></div>
<div id="float-box"></div>
<img src="macbook-small.jpg"/>
</div>
<div id="big-box">
<img src="macbook-big.jpg"/>
</div>
</div>然后通过放大镜移动的距离x求出大图片应该移动的距离是多少
(2)放大镜left的值=event.clientX-demo.offsetLeft-smallBox.offsetLeft-FloatBox.offsetWidth/2
(3)B/D=A/C=x/y =>B-A/D-C=x/y因此:鼠标style.left/(小图片offsetWidth-放大镜offsetWidth)=大图片移动的距离/大图片的宽度。
(4)要兼容鼠标移除了外边框那么就不会显示了(不过也是一个原理)
瀑布流布局的原理:
(1)下一行的图片和上一行图片最矮的那个元素对齐(水平offsetLeft值相同)
(2)动态加载完成以后手动调用waterfall,解决参差不齐问题,强烈建议这里用文档碎片减少页面重绘!
(3)var num=Math.floor(document.documentElement.clientWidth/iPinW);//表示每行中能容纳的pin个数【窗口宽度除以一个块框宽度】,同时用一个全局变量表示每一列的当前的高度
回到顶部特效的原理:
(1)滚动的距离已经超过了屏幕的高度,这时候就显示那么元素
(2)这里如果用正数,那么舍入的时候会往下舍入,导致每次减去的像素较少,所以最后减去不到0,于是一会触发清除定时器的代码但是,如果是负数,那么舍入的时候会变成更小的负数,导致最后可以减少到0!document.scrollTop+Math.floor(-top/3)
xhEditor插件的原理:
(1)用一个iframe来插入你写入的内容,但是最重要的需要注意的地方是必须在form的onsubmit中才能访问xhEditor写入的内容。目前网络中所有的在线编辑器都是利用新创建的iframe来实现可视化编辑功能,xhEditor也不例外,所以在提交前必需要将最新的编辑结果重新同步到原来的textarea。xhEditor默认会在textarea所在的form对象中绑定onsubmit事件,当用户点击submit按钮时,xhEditor就会将最新结果同步回textarea,随后随表单中的其它表单项一同提交到服务端脚本。因此,如果不需要用Javascript额外处理,普通的表单式提交是没任何问题的。
(2)可以配置的,可以设置皮肤等,如CSDN可以是简介mimi也可以是复杂版本的
问题223:延迟对象和Callback对象?
var func1=function(message){
console.log(this.sex+message);
}
var func2=function(message){
console.log(this.sex+message);
}
var dfd=$.Deferred(),obj={sex:"female"};
//notifyWith和notify会触发通过then和progress添加的回调函数,但是这时候then必须要添加第三个参数才可以,只有第三个表示progress。我们知道在以前版本中用的是pipe不过在新版本中已经推荐用then了,但是pipe依然可用
dfd.progress(func1).then(null,null,func2).always(function(){console.log('always invoke');});
//其中notifyWith第一个参数用于指定执行的上下文,也就是回调函数中的this,而第二个参数通过apply封装到回调函数命名参数上
dfd.notifyWith(obj,['qinlinag']);
//always添加的函数必须在reject/resolve才会调用,notify/notifyWith无效
//通过state函数获取当前Deferred对象的状态
console.log(dfd.state());
dfd.pipe(null,null,func2);
//通过pipe添加的函数也是按照:成功,失败,progess顺序来说的。var defer = $.Deferred(),
//then方法返回一个promise对象,该对象可以对
filtered = defer.then( null, function( value ) {//fail
//console.log(this);
//这里面的this没有resolve,resolveWith等方法
return value * 3;
});
defer.reject( 6 );
//这句代码放在fail后面和前面没有任何关系的!
filtered.fail(function( value ) {
console.log( "Value is ( 3*6 = ) 18: " + value );
});var filterResolve = function() {
var defer = $.Deferred(),
filtered = defer.then(function( value ) {
return value * 2;
});
defer.resolve( 5 );
filtered.done(function( value ) {
$( "p" ).html( "Value is ( 2*5 = ) 10: " + value );//打印10
});
};
//这里也是利用then方法来返回一个Deffered对象来过滤
filterResolve();下面测试的是promise方法,如果有参数就是使得参数对象具有promise对象的所有属性,如果没有参数就是简单的获取promise对象
var dfd=$.Deferred(),obj={};
console.log(dfd.promise());
//如果没有传入参数那么就是返回promise对象,如果传入了参数就是使得参数对象具有promise对象的所有的方法
dfd.promise(obj);
console.log(obj);
//obj具有promise所有的方法和属性,而且要注意promise对象有一个promise方法!var div = $( "<div>" );
div.promise().done(function( arg1 ) {
// 马上调用,打印"true"
alert( this === div && arg1 === div );
});Callback对象如下:
(1)once:只会调用一次,然后list=stack=memory=undefined,所以以后添加进来的所有的函数都不会被调用了,因为根本就没有添加进去,所以只会调用一次而且以后也不会添加调用函数了。
(2)memory:记住上一次的参数调用后面添加的函数而不用手动调用fire方法,所以是非常棒的!但是如果有了手动调用,那么除了有旧参数调用新函数的步骤以外还有新参数调用所有的旧函数!
(3)stopOnFalse+memory告诉我们所有的回调函数都是通过队列形式添加的,因此如果队列前面的函数返回了false那么后面的函数根本就不会执行了,这一点一定要弄明白。还有一点:就是如果有了stopOnFalse后面的函数不执行的同时会导致memory会失效,这一点很重要,但是这时候可以手动调用队列中所有的函数,不过也要受到stopOnFalse的限制。
(4)unique+memory的组合:按照上面的逻辑就可以了
(5)once+memory的组合还有一个特点:说白了其实是memory的特点。也就是当你在once+memory的情况下,调用了一次fire以后(list已经是[]了),当你继续添加函数这时候可以不手动调用fire函数,因为在add方法里面进行了判断,如果有memory那么就会自动拿着参数去调用list里面所有的方法!(如果没有参数就是undefined!)
(6)在没有once的情况下,stack肯定存在!这时候调用fire不会对list,stack,memory等产生任何影响,除非你手动调用disable,empty等函数!也就是once调用了disable,once+memory的组合调用了list=[]!其它fire调用不会影响内部的机制(如memory等stack都会存在)!
223:请简单的介绍一下你自己
那些页面效果,那些页面,那些项目,jQuery源码,科研怎么样?了解一个算法的时间复杂度和空间复杂度,sort方法时间复杂度是nlogn!
224:你还有什么问题吗?
公司是否会提供相应的培训;是否有机会提前转正;
225:css的权重?
详见 CSS Specificity--CSS特性、权重、优先级---CSS specificity规则、算法及实例分析
226:什么是类数组对象,有什么特点?
按照jQuery的isArrayLike他必须有这样的特征:第一种:length恒等于0;第二种:本身就是Array类型;第三种:length>0,同时length是number类型,同时(length-1) in obj为true!
226:h1和title的区别是什么?(文章标题 vs 网站标题)
从网站角度看:title网站标题能直接告诉搜索引擎和用户这个页面是关于什么主题和内容的网站。
从文章的角度上看:用户进到内容页里,想看到的当然就是文章的内容,H1文章标题则是最重要的、最应该突出的。一篇文章只能有一个标题,一个页面最好采用一个H1;多个H1会造成的搜索引擎不知道这个页面哪个标题内容最重要,导致淡化这个页面标题和关键词,起不到突出主题的效果。
从网站角度而言,title则重于网站信息标题;从文章角度而言,H1则概括的是文章主题。
从SEO角度看:title的权重高于H1,其适用性要比H1广。网站SEO过程中,H1标签的作用几乎等同于TITLE标题。标记了H1的文字的页面给予的权重会比页面内其它文字的都要高很多。H1与title权重的高低比较,TITLE无疑是页面中权重最高的,其次是H1标签。一个好网站是:H1与title并存,既突出H1文章主题,又突出网站主题和关键字
227:b和strong标签的区别?(权重)
实体标签还是逻辑标签:<b>标签是一个实体标签,它所包围的字符将被设为bold(粗体), 而<strong>标签是一个逻辑标签,它的作用是加强字符的语气,一般来说,加强字符的语气是通过将字符变为bold(粗体)来实现的。
html标签还是xhtml标签: strong是web标准中xhtml的标签,strong的意思是“强调”;b是html的,b的意思是bold(粗体)。web标准主张 xhtml不涉及具体的表现形式,“强调”可以用加粗来强调,也可以用其它方式来强调,比如下划线,比如字体加大,比如红色,等等,可以通过css来改变 strong的具体表现。但是为了符合现在W3C的标准,还是推荐使用strong标签。strong与b的区别
228:i和em标签的区别是什么?
实体标签还是逻辑标签:其中i表示的就是italic就是实体的意思所以是实体标签,而em是逻辑标签,只是表示是emphasize但是具体的表现可由浏览器决定。但是对于浏览器来说对于em标签和strong标签比对i标签和b标签重视的多,也就是说浏览器重视逻辑标签! 详见关于html标签中b和strong,i与em两个的区别(物理标记和逻辑标记
229:head中和body中的优先级是怎么样的?
(1)body中的css优先级比head中的要高 (2)记住css的样式计算规则就可以了
230:背景图片距离div左边和上面10px
background:url("1.png") no-repeat 15px 10px; 技术大牛多;国内顶尖的互联网公司;前景好希望和优秀的人在一起。
232:html5中的small标签被重新定义的
重新定义<small> (Small Element redefined)
在HTML4或XHTML中,<small>元素已经存在。然而,却没有如何正确使用这一元素的完整说明。在HTML5中,<small>被用来定义小字。试想下你网站底部的版权状态,根据对此元素新的HTML5定义,<small>可以正确地诠释这些信息。在Normalize.css中small被设置为{font-size:80%;} 。HTML5中已经把big移除了
233:那些方式实现三角形?
234:为什么前端工程师都用偶数字体?
UI设计师的角度:
(1)多数设计师用的设计软件(如:ps)大多数都是偶数,所以前端工程师一般都是用偶数字体
浏览器角度:
(2)其一是为了迁就ie6,万恶的ie6会把定义为13px的字渲染成14px,你可以写个页面试试.还有一个原因是,偶数宽的汉字,比如12px宽的汉字,去掉1像素的间距,填充了像素的实际宽是11px,这样汉字的中竖线左右是平分的,以“中”这个字为例,在12像素时,竖线在中间,左右各5像素,显得均衡。
(3)其二像谷歌一些比较流行的浏览器一般会有个默认的最小字体,而且对奇数字体渲染的不太好看
(4)windows自带点阵的相关原因 网页设计中为什么少用奇数字体
235:如果设置了百分比的高度如padding-top,padding-bottom,margin-top,margin-bottom那么这时候子元素的高度是按照父元素的宽度来计算的
这是一个很让人困惑的CSS特征,我之前也谈到过它。我们大家都知道,当按百分比设定一个元素的宽度时,它是相对于父容器的宽度计算的,但是,对于一些表示竖向距离的属性,例如padding-top,padding-bottom,margin-top,margin-bottom等,当按百分比设定它们时,依据的也是父容器的宽度,而不是高度。你未必知道的CSS小知识:元素竖向的百分比设定是相对于容器的宽度,而不是高度
236:css3的media query如何兼容低版本的IE浏览器?(respond.js就可以了)
引入respond.min.js,但要在css的后面(越早引入越好,在ie下面看到页面闪屏的概率就越低,因为最初css会先渲染出来,如果 respond.js加载得很后面,这时重新根据media query解析出来的css会再改变一次页面的布局等,所以看起来有闪屏的现象)
1.把head中所有的css路径取出来放入数组
2.然后遍历数组一个个发ajax请求
3.ajax回调后仅分析response中的media query的min-width和max-width语法,分析出viewport变化区间对应相应的css块
4.页面初始化时和window.resize时,根据当前viewport使用相应的css块。ie兼容响应式布局的实现总结
237:css3中双冒号和单冒号有什么不同?
(1)单冒号(:)用于CSS3伪类,双冒号(::)用于CSS3伪元素。
(2)CSS2之前已有的伪元素,比如:before,单冒号和双冒号的写法::before作用是一样的。如果你的网站只需要兼容webkit、firefox、opera等浏览器,建议对于伪元素采用双冒号的写法,如果不得不兼容IE浏览器,还是用CSS2的单冒号写法比较安全。 CSS3:伪类前的冒号和两个冒号区别
238:如何去掉chrome浏览器的填充的时候默认的背景色?
去掉chrome记住密码后自动填充表单的黄色背景 可以在表单上面用autocomplete设置为"off"!
input:-webkit-autofill {//自动填充的chrome默认的样式
background-color: #FAFFBD;
background-image: none;
color: #000;
}研究发现,一种字库好像不能同时提供斜体和oblique两种字体,因为oblique基本上是一种模仿的斜体,而不是真正的斜体。所以,如果一种字库里没有提供斜体字,那当使用CSS的font-style: italic时,浏览器实际上是按font-style: oblique显示的。你未必知道的CSS小知识:font-style的oblique属性值
CSS规范:让一种字体标识为斜体(oblique),如果没有这种格式,就使用italic字体
240:android下position:fixed无效的解决方法
在head中加入如下的标签就可以了:详见如何解决position:fixed;在android webkit 不起作用的问题
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0, user-scalable=no"/>多数显示器默认频率是60Hz,即1秒刷新60次,所以理论上最小间隔为1/60*1000ms = 16.7ms
242:用原生JavaScript的实现过什么功能吗?
本地存储;ajax;跨域等等
243:javascript基本规范?(with vs 全局变量)
少用width;避免全局变量污染;用一个变量之前要提前定义;少用import;少用eval等
244:document对象和window对象的关系
document对象是window对象的一个属性;window是全局对象,表示浏览器对象,很多全局函数都是在window对象上面的,而document对象表示html文档!
245:我们必须知道js原生的map第二个参数是第一个参数中的this的设定
var arr=[1,2,3];
var obj={name:"qinliang",sex:"male",sayName:function(){console.log(this.name);}};
arr.map(function(elem,index,arr1){
//对于map来说如果传入了第二个参数那么这时候该函数中的this就是
//第二个参数!
console.log(this);
},obj);var trim=numbers.map(Function.prototype.call,String.prototype.trim);//这里第二个参数String.prototype.trim就是Function.prototype.call中的this
console.log(trim); console.log(parseInt('1','0'));
console.log(parseInt('3','2'));
console.log(parseInt('2','1'));
//如果paseInt的参数比基数还大,那么肯定返回了NaN!因为jQuery底层调用了new jQuery.fn.init所以返回的是init对象,但是因为jQuery中有下面的一句代码:
init.prototype = jQuery.fn=jQuery.prorotype;console.log($() instanceof jQuery.fn.init);
console.log($() instanceof jQuery);
//两个都打印true现在浏览器都提供了JSON.Stringify把json转化为字符串,而从字符串转化为JSON提供了SJON.Parse这也是jQuery的做法。但是jQuery提供了parseJSON方法
248:jQuery 的队列是如何实现的?队列可以用在哪些地方?(push,shift,Callbacks,_data)
原理是通过数组的push方法和shift方法来完成的,push用于添加新得函数,而shift从队头拿出一个函数来执行!当然也用到了一些jQuery.Callbacks对象的一些方法,以及一些jQuery._data来保存数据的方法。如果自减后为0(所有函数已经调用了),那么就会hooks.empty.fire清除所有的回调队列,这时候再次调用dequeue已经没有任何意义了,因为Callbacks内部的list以及是空数组了!
249:针对 jQuery性能的优化方法?(选择器 vs 事件委托 vs 内部数据)
缓存对象(先用局部变量保存起来,然后在修改不用每次都查询一次);ID选择器或者标签选择器等优先使用浏览器原生方法,速度快>元素类型选择器如class,IE中无法用原生方法,其它浏览器用getElementByClassName>伪选择器或者属性选择器;使用链式调用,使得每一次执行的结果都得到缓存,速度快;事件委托等;保存数据如_data而不用每次都重新添加如toggleClass就是这样
250:seajs的实现原理是什么?(如何加载模块,如果解决模块依赖,如果解决命名空间冲突)
1. sea.js 是怎样解决 模块加载(这里说的模块其实就是js文件加载),
其实,原理很简单,和手动引入js文件是一样的。就是当调用有加载功能的函数 如 seajs.use 、 require 、require.async 时,其内部代码会创建一个script标签,把src设置成你要引入的js文件,然后append到DOM文档中进行加载,当加载完毕后,再把这个script标签移除掉,所以当我们审查元素时看不到有那个<script>标签,但因为文件已经引入了,即使把这个script移除也不会影响代码使用.我们可以用360卫士限制网速的功能,把网速降低,然后引入jq,是可以看到它就是这样处理的
2. sea.js 是怎样解决 模块依赖
上面的问题清楚了,其实这个依赖也很简单啦,也就是 加载 顺序的问题。例如 a.js 依赖于 b.js, 那在sea.js内部代码中,就先加载b.js然后再加载a.js,这样就可以解决依赖问题了。
3. sea.js 是怎样解决 命名冲突(命名冲突很显然就是接口技术,不过这时候的接口就是export对象)
解决了上面的两个问题,就剩下依赖接口的问题了, 就是模块的依赖是搞定了,但是sea.js是用define( fn )函数来定义模块的,里面的变量都是局部的,得给外面一个接口调用才行啊。so, exports对象就出场啦, 当你使用sea.js定义一个模块的时候,你可以把你的 对外函数接口 都放在exports对象上。当别一个文件要依赖此文件时, 调用 require( url )时,返回值就是这个exports对象,所以就解决了接口的问题。同时也很好的解决了命名冲突的问题,就算几个同事都用一样的名字,也不会有问题。
因为这里返回的exports就相当于一个命名空间了。模块化开发之sea.js实现原理总结
251:closest,parents,parent的区别是什么?(closest可以传入第二个参数!)
closest:返回最近的一个满足选择器的元素,而不再局限于直接父元素。而且如果传入了第二个参数是DOM那么就是表示搜索结束的DOM,而且该方法是从当前元素开始选择的,如果当前元素满足选择器那么也会被选择,不再局限于父元素;如果第一个参数是:event等类似的选择器,那么把两个参数构建起来,组合成为一个包含上下文的选择器
closest( ":even", document.getElementById("n9") ) //相当于 ( "#n9 :even" ),匹配n10、n12parents:返回所有的父元素的集合,一直到html结束
parent:返回直接的父元素
252:png8,png24,png32的区别是什么?
(1)png8对应的是gif格式相同的效果,支持完全透明和完全不透明两种效果和256色,png8的文件更小,目前很多大型门户网站开始使用png8来代替gif,但是png8是没有gif的动画效果的.
(2)png24支持24位的色彩,相对图片的质量很高,但是Fireworks中的png24不支持Alpha透明通道,也就是在FW中的png24是不透明的,但是在PS或者AI中导出的png24是支持Alpha透明的
(3)png32是FW中的支持Alpha通道的png图片
253:meta标签的常用属性
name(author,description,keywords) ,http-equiv,content,charset等
254:什么是EXJS?
ExtJS是一个Ajax框架,是一个用javascript写的,用于在客户端创建丰富多彩的web应用程序界面。ExtJS可以用来开发RIA也即富客户端的AJAX应用。因此,可以把ExtJS用在.Net、Java、Php等各种开发语言开发的应用中。
255:我们来回忆一下replaceChild,insertBefore等的用法
第一个:cloneNode和replaceChild的用法:
var dom=$('textarea')[0];
//我要克隆节点
var clone=dom.cloneNode(true);
//获取到克隆的节点了
clone.appendChild(document.createTextNode('我爱覃亮'));
//修改了这个克隆节点
dom.parentNode.replaceChild(clone,dom);
//replaceChild比较反常,和英语里面的不是一样的,所以第一个是新的节点,第二个参数才是旧的节点第二个:insertBefore调用者和replaceChild一样,是父元素
//我现在要在textarea前面添加一个新的input元素
var dom=document.querySelector('textarea');
var input=document.createElement('input');
input.value='请输入用户名';
//现在调用insertBefore,要添加的元素在第一个参数,第二个参数是参照节点
document.body.insertBefore(input,dom);第三个:appendChild用于往后面添加,调用者也是父元素
//我在body后面添加一个新元素
var dom=document.querySelector('textarea');
document.body.appendChild(document.createTextNode('我是覃亮'));第四个:removeChild移除元素
//我在body后面添加一个新元素
var dom=document.querySelector('textarea');
document.body.removeChild(dom);总结:不管是insertBefore,replaceChild,appendChild调用者都是父元素。appendChild返回值是新添加的元素,insertBefore返回也是新添加的值,replaceChild返回的是老节点,removeChild也是被移除的节点!
256:jQuery为什么移除live事件?(成也冒泡自己定义了也会冒泡,不成也是冒泡因为有些不冒泡)
坏处就是:把事件绑定在document上会在页面上每一个元素都呼叫一次,如使用不当会严重影响性能。而且不支持blur, focus, mouseenter, mouseleave, change, submit。
257:clietWith,srcollWidth,offsetWidth之间的区别?
offsetHeight:包括元素的高度+水平滚动条的高度+上边框高度+下边框高度。offsetWidth=clientWidth+2*borderWidth
clientWidth:元素内容+内边距占据的空间
scrollHeight:在没有滚动条的时候指的是元素的总高度,如果有滚动条的时候html元素的总高度就是document.documentElement.scrollHeight,在不包含滚动条的时候clientHeight和scrollHeight之间的关系不明确,这时候通过document.documentElememnt查看这些属性在不同浏览器中会发现不一致。所以,var docHeight=Math.max(document.documentElement.scrollHeight,document.document.clientHeight);同时在混杂模式下用document.body来代替document.documentElement就可以了
258:Restful API中每一个方法都是什么意思?
Post:新增用户,delete:删除用户,put:修改用户,get:查询用户,dispatch:局部更新用户
259:display:none和visibility:hidden的区别?(回流导致株连)
(1)空间占据 (2)回流与渲染,display:none隐藏产生reflow和repaint(回流与重绘),而visibility:hidden没有这个影响前端性能的问题 (3)株连性,visibility:hidden则具有人道主义关怀,虽然不得已搞死子孙,但是子孙可以通过一定手段避免,也就是通过设置visibility:visible。详见
260:冒泡排序和选择排序?
冒泡排序的方式
for (var i = 0; i < a.length - 1; i++) {
//比较的次数是length-1
for (var j = 0; j < a.length - 1 - i; j++) {
//内层循环是length-1-i次,这是和外面的循环唯一相关的部分
if (a[j] > a[j + 1]) {
//如果前面的元素比较大,那么前后进行交换,这一直是在内部完成的!
var tmp = a[j];
a[j] = a[j + 1];
a[j + 1] = tmp;
}
}
} 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
若文件的初始状态是正序的,一趟扫描即可完成排序。所需的关键字比较次数Cmin=n-1和记录移动次数Mmin=0均达到最小值: , 。
所以,冒泡排序最好的时间复杂度为O(n)。
若初始文件是反序的,需要进行n-1 趟排序。每趟排序要进行n-i次关键字的比较(1≤i≤n-1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值:
Cmax=(n-1+1)(n-1)/2
Mmax=3n(n-1)/2
冒泡排序的最坏时间复杂度为O(n2)。
综上,因此冒泡排序总的平均时间复杂度为O(n2)。
。选择排序(最后两句代码的顺序不能调换)
function sorrt(ary) {
length = ary.length;
//获取数组长度并且进行遍历
for (var i = 0; i < length; i++) {
_min = ary[i];
//选择排序用来保存值
k = i
//选择排序用来保存下标
for (var j = i + 1; j < length; j++) {
//从外层循环i+1开始循环
if (_min > ary[j]) {
_min = ary[j]
//重新定义外层的值,这是较小的值
k = j
//重新定义外层的下标,该下标是较小的值的下标
}
}
//获取到了一次外部循环的最小的下标和最小的元素值!
//于是就把外层循环的i和内层循环获取到的最小下标和值换位置就可以了!
ary[k] = ary[i]
//把下标k的元素设置为我们现在的外层循环的元素
ary[i] = _min
//把外层的最小值,即下标i的元素设置为我们获取到的最小值,即_min!
}
return ary;
} 261:如何选择页面所有checked的元素?
function getSelectedOptions(select)
{
var result=new Array();
var option=null;
for(var i=0,len=select.options.length;i<len;i++)
{
option=select.options[i];
if(option.selected)
{
result.push(option);
}
}
return result;
}
//这时候当选择select的多个项目时候再次点击按钮
//就会打印选中的所有的options集合!
$('input')[0].οnclick=function(e)
{
var result=getSelectedOptions($('select')[0]);
console.log(result);
} 262:javascript中这些方法的区别?
substring方法:对源字符串无影响;断尾;如果第一个参数为负数,那么设置为0,如果第二个参数是负数,那么两个参数互换(前后互换)
slice方法:断尾;如果有字符串是负数,那么加上length后得到新的字符串(前后不换)
substr方法:第一个参数是开始下标,第二个参数是个数;如果第一个参数为负数那么加上length,如果后面为负数不变(前后不换)
var str="hello world";
console.log(str.substring(-3));//第一个参数是负数那么设为0!打印"hello world"
console.log(str.substring(3,-4));//第二个参数为负数那么前后对调!打印"hel"
console.log(str.slice(-3));//如果有负数那么加上length!打印"rld"
console.log(str.slice(3,-4));//打印"lo w"
console.log(str.substr(3));//打印"lo world"
console.log(str.substr(3,-4));//如果第一个参数为 负数加上length,第二个参数为负数设置为0,打印""! 263:jQuery中有那些方法可以对动画操作?
fadeIn,fadeOut,slideUp,slideDown,show,hide方法等
264:如何控制元素的显示和隐藏?
元素隐藏与显示是我们在页面制作与交互效果实现中非常常见的,如果您只是使用display:none与display:block/inline来实现DOM元素的显隐控制,那你就out了。就元素的显示与隐藏实现,使用display在有些时候算是比较糟糕的方法了。
控制元素显隐的方法很多,但是本文不是讲元素显隐控制的,所以,只讲与absolute相关的一些方法。
.hidden{
position:absolute;/*只会重绘不会产生强烈的回流,但是还是会回流*/
top:-9999em;
}
.hidden{
position:absolute;/*只会重绘不会产生强烈的回流*/
visibility:hidden; /*可用性不满足*/
}
.hidden{
position:absolute;/*只会重绘不会产生强烈的回流*/
clip: rect(1px 1px 1px 1px); /* IE6, IE7 */
clip: rect(1px, 1px, 1px, 1px);
}所谓可用性隐藏,就是兼顾屏幕阅读器这类互联网阅读辅助设备的隐藏方式。Yahoo! 可用性实验室成员Ted Drake就不同隐藏方法下屏幕阅读器的可用性问题作为测试,结果发现下面两种隐藏方式屏幕阅读器是读不了的。
.completelyhidden {
display:none;
}
.visibilityhidden {
visibility:hidden;
}②回流与渲染
早先时候我曾翻译过两篇关于回流与重绘的文章,“最小化浏览器中的回流(reflow)”以及“回流与重绘:CSS性能让JavaScript变慢?”。
我自己是没测过。不过根据上面这两篇文章的说法,以及一位口碑前端前辈的说法,使用absolute隐藏于显示元素是会产生重绘而不会产生强烈的回流。而使用display:none不仅会重绘,还会产生回流,DOM影响范围越广,回流越强烈。所以,就JavaScript交互的呈现性能上来讲,使用absolute隐藏是要优于display相关隐藏的。
③配合JavaScript的控制
况且,随着浏览器的不断进步,以后类似于display:table-cell,display:list-item会越来越多的使用。再想通过display实现通用的显隐方法难度又会增大些。
这就是使用display属性控制元素显隐的局限性。顺带一提的是jQuery的显隐方法show()/hide()/toggle()就是基于display的,其会存储元素先前的display属性值,于是元素再显示的时候就可以准确地显示出之前的display值了。
而使用绝对定位实现的一些元素隐藏方法的控制就相对简单很多的。例如:position:absolute + visibility:hidden方法,当我们要让元素(原本非绝对定位元素)显示的时候,我们需要设置:
dom.style.position = "static";
dom.style.visibility = "visible";dom.style.position = "static";CSS 相对/绝对(relative/absolute)定位系列(三) 实验:absolute/display隐藏与回流等性能
265:如何居中一个宽度未知的元素?
<div class='container'>
<div style="display:inline-block;border:2px solid #fff;_display:inline;_zoom:1;" class="center">
<a href='#'>1</a><a href='#'>2</a><a href='#'>3</a>
</div>
</div> .container{border:1px solid #ccc;width:100%;height:200px;text-align: center;}
.center a{color:red;display: inline-block;padding:0 20px;border: 1px solid black;margin:0 20px;} .center{_display:inline;} 为针对ie6的hack,针对ie6前面的display:inline-block;的作用是在ie下触发元素的layout,使其haslayout。垂直居中一个高度未知的元素很多方法,这就不说了
266:文字超出用省略号显示?
<div class='container' style="width:50px;height:50px;;border:1px solid #ccc;overflow:hidden;text-overflow:ellipsis;white-space:nowrap">
我爱你你啊,你在那里
</div> 267: CSS中可以通过哪些属性定义,使得一个DOM元素不显示在浏览器可视范围内?
visibility:hidden;display:none;height/width:0;opacity:0;position:absolute,top:-9999em
268:CSS3的animation动画如何使用?
.ani{
width:480px;
height:320px;
margin:50px auto;
overflow: hidden;
box-shadow:0 0 5px rgba(0,0,0,1);
background-size: cover;
background-position: center;
-webkit-animation-name: "loops";
/*通过设置animation-name;animation-duration(完成动画花费的时间ms);animation-iteration-count(动画播放的次数)参数;animation-timing-function(动画速度曲线);animation-delay(开始延迟);animation-direction(轮流反向播放动画)*/
-webkit-animation-duration: 20s;
-webkit-animation-iteration-count: infinite;
}
/*设置动画的关键帧*/
@-webkit-keyframes "loops" {
0% {
background:url(4d3.jpg) no-repeat;
}
25% {
background:url(09dd0.jpg) no-repeat;
}
50% {
background:url(b912.jpg) no-repeat;
}
75% {
background:url(72cdda3cc7cd99e4b.jpg) no-repeat;
}
100% {
background:url(192138ad1.jpg) no-repeat;
}
}line-height;letter-spacing(去除inline-block元素之间的空隙)
270:letter-spacing和word-spacing的区别是什么?
letter-spacing修改的是字母或者字符之间的间距,而word-spacing修改的是字(单词)之间的间距。以上代码中letter-spacing将字母之间的间距设置为40px,需要注意的是,空格也算是一个字符,例如"I"与"am"之间的空格与两边的字母的间距也会设置为40px,所以"I"和"a"之间的间距是80px。word-spacing会将单词之间的间距设置为40px。
特别说明:letter-spacing与word-spacing准确的说不是设置字母和字之间的间距,而是在指定的字母和字之后添加指定的间距,最后一个字母和字除外。
对于中文请看下面的例子:
.second {
word-spacing:40px;
}
.third{
word-spacing:40px;
}.first{
letter-spacing:40px;
}<div class="first">蚂蚁部落</div>
<div class="second">蚂蚁部落</div>
<div class="third">蚂 蚁部落</div>
有以上代码的表现可以看出,对于汉字,如果连在一起则被视作一个“word”
271:margin重叠的情况?
什么是外边距重叠?重叠的结果是什么?
情况1:父子元素重叠
当父元素没有指定border-top或者padding-top时候,同时其有margin,而且子元素也有margin,这时候就会发生margin重叠,重叠后选择两者的最大者。可以通过getBoundingClientRect来获取位置
情况2:兄弟元素的margin重叠
折叠结果遵循下列计算规则:
两个相邻的外边距都是正数时,折叠结果是它们两者之间较大的值。
两个相邻的外边距都是负数时,折叠结果是两者绝对值的较大值。
两个外边距一正一负时,折叠结果是两者的相加的和。
272:那些属性会触发BFC?
根元素
float属性不为none
position为absolute或fixed
display为inline-block, table-cell, table-caption, flex, inline-flex
overflow不为visible
273: 图片下方出现几像素的空白间隙?
使用font-size:0或者图片display:block就可以了(图文并排出现的问题,由于基线对齐导致的问题)
274:关于手形光标. cursor: pointer. 而hand 只适用于 IE.
275:animation和transition的区别?
(1)transition 是令一个或多个可以用数值表示的css属性值发生变化时产生过渡效果。
(2)animation 则是属于关键帧动画的范畴,它本身被用来替代一些纯粹表现的javascript代码而实现动画。基于animation和@keyframe 的动画一方面也是为了实现表现与行为的分离,另一方面也使得前端设计师可以专注得进行动画开发而不是冗余的代码中。同时,它还应该被用来提高动画的渲染性能,当然,渲染性能这是浏览器的事情,目前看来,三大主流内核的animation/@keyframe的性能都不算高。webkit甚至在元素被transform矩阵变化并脱离文档流后在某些伪类选择器里应用还会有bug。事实上,animation结合@keyframe可以做的事情远超现在你看到的。我断言,在未来某个css3动画充分发展的时候,它和transition的应用场景和区别将会越来越明显,并且它将会代替绝大多数纯展示的js/flash动画。
问题276:Deferred中三个Callback内部前面如何?
var tuples = [
// action, add listener, listener list, final state
[ "resolve", "done", jQuery.Callbacks("once memory"), "resolved" ],
[ "reject", "fail", jQuery.Callbacks("once memory"), "rejected" ],
[ "notify", "progress", jQuery.Callbacks("memory") ]
]问题277:transition-timing-function?
ease:表示越来越慢(如让马ease,ease就是放松的意思)
linear:线性的函数
ease-in:表示渐显的效果(in表示显示,呈现加速状态,其导数逐渐变大)
ease-out:表示渐隐的效果(out表示隐藏,呈现减速的状态,导数越来越小)
ease-in-out:渐显渐隐效果(首先导数逐渐增减,然后导数逐渐减少)
上面的函数在过渡动画的时候不是十分精确,因此才有了三次贝塞尔曲线,贝塞尔曲线有多个精确控制点,三次贝塞尔曲线由四个点控制曲线形状,每个点有水平和垂直两个值来确定,也就是我们常说的X,Y值,这些点的值为小数或者百分比。其中p0,p3无法设置,它总是存在HTML中,也就是说他们总会是(0,0)和(1,1)。使用如transition-timing-function:cubic-bezier(0.85,0,1,1)可以绘制前面的任何的ease,ease-in等函数,其中这个cubic-bezier函数接受的两个点就是P2和P1。photoShop中可以使用钢笔工具来绘制(计算机图形学),当然也有在线制作cubic-bezier的网址
(1)what did you learn?
第一点:我觉得是从一个理论家到实干家的进步。以前是别人说怎么样怎么样,然后自己就怎么样,把这一切当成金科玉律,比如以前看高质量代码的188条建议,现在更多的思考为什么是这样
第二点:开始专注于前端学习。以前的自己更多的了解前端和后端的交互过程,虽然学习了不少的东西(如前后端http头沟通过程),但是作为前端毕竟有点扩散。现在我更多的去了解一些前端深入的问题
比如我最近关注研究动画的性能,开始深入研究网页分层,GPU加速等等一系列的东西。(RAF,fastdom,stricdom)。当然也是在这里了解了1px!==1px的问题
第三点:如何与人沟通。我记得在实习生面试的时候面试官问我什么选择前端,我的回答是:‘前端更加接近于用户体验,前端编程是一个不断优化的过程,是从0分到100分的过程,而不是yes/no的问题,
套用别人的一句话前端是最靠近用户的程序员’。现在回想我在阿里的三个月,我估计还是这样的理解。因为我们是TV端,必须要和视觉沟通,客户端沟通,服务器端沟通。在这个过程中,我觉得本身
就是一种乐趣吧
第四点:低调做人,高调做事。自己参加了阿里的几次培训,收获其实挺多的。我记得刚来阿里的时候,厕所有一个标语:‘你为什么而来?你为什么而战?什么会因你而不同’,我后面一直在想这个问题。直到参加了后面
的培训,我了解到:‘聪明,皮实,乐观,自省’。其实这四个词已经回答了,或者说我通过这四个词悟到了。我为什么而来:就像我实习生面试的回答一样,我希望和优秀的人在一起,做有意义的事情;我为什么
而战:说小了,是为了团队核心竞争力,说大了是为了我们整个阿里,但都是可以归结于责任,为了我们项目组,乃至整个阿里能顺利度过102岁。至于什么会因我而不同,我想说,兢兢业业,星星之火可以燎原!
总之:理论家专注沟通高调
(2)what is your plan?
查漏补缺,兢兢业业。技术这条路是漫长的,本来就是不断修炼的过程,我最希望看到的就是自己的进步。因为我现在还没有正式毕业,在这段时间内,如果有机会,我希望能继续待在阿里实习,因为我的论文已经发表,暂时也没有什么其他的事情了,我把这段时间定位我自己的查漏补缺的时间,我希望当自己从校园走出来后能成为一名合格的前端工程师。第二个时段我把它定位为‘兢兢业业’,多动手,多思考,多接触一些前沿的知识才能进步。我记得参加一次培训的时候,培训官说了句‘加班是应该的,不加班也是应该的,但是完不成任务是万万不应该的’。总之一句话,以负责任之心做事,做负责任的事!
(3)what is your advantages?
对于这个问题,我还是希望通过上面的四个词语来说一下自己。聪明,乐观:聪明不聪明,乐观不乐观,我就不说了,因为勤能补拙嘛;皮实:其实我觉得这算一个优点吧,我是一个不懂就要问的程序员,当然这是建立在自己仔细
思考的基础上的,在实习的这段时间内师姐也给我不少的帮助,而且我给自己的这方面的定的目标就是,不懂就要问,但是同样的问题不要问第二遍;自省:这个我觉得也算是我的一个特质吧,其实不管是生活上还是学习上,我都是
一个善于总结的人,记得刚来阿里实习的时候遇到了不少技术上问题,周末就躲在房间里面不断的充电,不断的学习新知识,然后总结记录下来,现在总结的遇到的问题应该已经超过100了。我最近也在做互动营销的项目,客户端告诉我
其实互动营销已经很多人做过了,但是每次来一个新人没一个坑还是会踩一次,我确实是希望到我这里能够把所有遇到的问题记录下来,而下次来人的话不要做重复的劳动。
(4)what is your disadvantages?
当时实习生面试的时候问了我这个问题,我当时的回答是‘对技术太过于专注,有时候会影响到自己的生活‘,自从我回答了这个问题过后我就一直担心阿里会不会要我,后面阿里要了我。现在又问了同样的问题。我还是同样的回答,我想把前端发展成为自己的兴趣,既然是兴趣,当然会愿意付出更多的时间和精力,我希望自己以后能够在前端这条道路上越走越远
(5)what is your biggest problems?
我总共做了两个项目:互动营销和活动容器的内容。互动营销遇到的就是https中加载http链接的问题,不管和客户端沟通,最后解决了;活动容器遇到的问题就是在2.6.0下出现黑屏的情况,最后封装了一个https中转页,所有的页面
全部委托给我的页面去打开
(6)what left without asking?
破冰?
278,css/JS是阻塞性的资源?
谷歌 Web 开发最佳实践手册(4.1.3):阻塞渲染的CSS
解答:是的,因为没有css资源的页面是没法显示的,也就是出现了FOUC。
(1)在默认情况下,CSS会被当做渲染中的阻塞性资源,也就是说浏览器即使已经处理好了某些页面内容,只要CSSOM没有构建好,便不会进行渲染。所以要给你的CSS瘦身,提高传输速度,并使用媒介类型和媒介查询来解除阻塞。
(2)在前部分中我们看到了关键的渲染途径需要同时具备DOM(Document Object Mode,文档对象模型)和CSSOM(CSS Object Model,CSS对象模型)来构造渲染树,这在渲染性能上有一个很重要的含义:HTML和CSS都是渲染过程中的阻塞性资源。HTML很明显,因为没有DOM的话,我们也没有任何东西来渲染,但是对CSS的要求也许并不明显。如果我们尝试渲染一个普通的页面,而不让CSS阻塞渲染过程,那会发生什么呢?
(3)默认情况下CSS被视为一种阻塞性渲染资源媒介类型和媒介查询让我们能把一些CSS资源标记为非阻塞性渲染资源,不管是阻塞性的还是非阻塞性的行为,所有的CSS资源都是通过浏览器下载的。使用媒介查询,我们的外观可以定制成特定的使用案例,例如显示和打印,还有一些动态的条件,例如在屏幕方向上的改变,调整大小等等。当声明你的样式资源时,一定要仔细注意媒介类型和媒介查询,因为它们会对关键渲染路径有很大的性能影响!
<link href="portrait.css" rel="stylesheet" media="orientation:portrait">问题:那些display:none的元素虽然不在渲染树中,但是它依然在dom树中,否则我们也就无法通过修改display来显示和隐藏元素了
下面是javascript部分内容:
谷歌 Web 开发最佳实践手册(4.1.4):使用JavaScript增加交互
结论:javascript会阻塞后面的dom的解析,因此当前的js是无法获取后面的dom对象的。同时js的运行也会等到cssom构建完成,如果cssom没有构建完成,那么javascript会等待它构建完成,等待的过程中后面的dom也是阻塞的。也就是说javascrpt阻塞dom有两种方式,第一种方式就是我们所说的无法访问后面的元素,第二种方式是间接的,也就是因为要等到cssom构建完成而阻塞的dom。但是我们可以把js声明为异步的,这样的话js就不会阻塞dom了!!!!
JavaScript让我们能够修改页面的每个方面:内容、样式和用户交互行为。然而,JavaScript也能阻塞DOM的构建,并延迟页面的渲染。使你的JavaScript是异步的,并且从关键渲染路径中消除任何不必要的JavaScript,以提供最佳性能。
关键要理解如下内容:
(1)JavaScript可以查询和修改DOM和CSSOM
(2)CSSOM会阻塞JavaScript执行,因为javascript必须操作的cssom必须是稳定的
(3)JavaScript会阻塞DOM的构建,除非明确地声明为异步执行
重要的注意点1:脚本是在它被插入到文本中的位置处执行的。当HTML解析器遇到一个脚本标签时,它会暂停对构建DOM的处理,并让出控制权给JavaScript引擎。一旦JavaScript引擎完成了运行,浏览器再从之前中断的地方重新开始,并继续进行DOM构建。
重要的注意点2:假如浏览器在我们运行脚本时还没有完成CSSOM的下载和创建会怎么样?答案很简单,并且对于性能不会很好:浏览器会延迟脚本的执行,直到它完成了CSSOM的下载和构建,当我们在等待时,DOM的构建也被阻塞了!简单来说,JavaScript引入了许多DOM、CSSDOM和JavaScript执行之间的依赖,并且在浏览器如何快速处理和渲染页面到屏幕上时产生了严重的延迟:
脚本在文本中的位置是很关键的(一般放在最后,这时候不会阻塞后面的dom解析,同时也不会因为cssom没有构建完毕而出现阻塞)
当遇到script标签时DOM的构建会被暂停,直到脚本完成了执行。
JavaScript可以查询和修改DOM和CSSOM
直到CSSOM准备好了,JavaScript才会执行
当我们讨论“优化关键渲染路径”时,更大程度上是在讨论理解和优化HTML、CSS和JavaScript之间的依赖关系。
谷歌 Web 开发最佳实践手册(4.1.2):渲染树结构、布局和绘制
简要提示一下,CSS中“visibility:hidden”和“display:none”是不同的。前者将元素隐藏起来,但是隐藏元素仍然会在页面最终的布局中占据相应的空间(其实就是一块空白)。然而后者会直接将元素从渲染树中删除,不仅不可见,也不属于最终布局的一部分。
添加了外部CSS和Javascript文件也就在我们的加载流中添加了两个额外的请求,所有这些在大概同一时间被浏览器调用了,目前为止一片祥和。然而需要注意的是,domContentLoaded事件和onload事件的时间差更小了。发生了什么?
与之前简单的HTML例子不同,现在我们需要获取和解析CSS文件去构建CSSOM,并且我们同时需要DOM和CSSOM去构建渲染树。因为我们还有一个解析器阻塞我们的页面上的JavaScript文件。直到CSS文件被下载和解析之前,domContentLoaded事件都是被阻塞的,原因是:也许Javascript需要查询CSSOM,因此在我们可以执行Javascript之前必须阻塞并等待CSS文件。也就是说,这里的javascript一直等待前面的cssom构建完毕,然后才会执行后面的dom,也就是说因为javascript的存在阻塞了后面的domContentLoaded。但是,如果把javascript设置为异步async的,这时候浏览器就不会阻塞后面的dom执行,因此后面的dom可以正常的执行domcontentloaed了!
谷歌 Web 开发最佳实践手册(4.1.6):分析关键渲染路径的性能
279.一些零碎知识点
flex:1//相当于flex:1 1 0%
flex:auto//flex:1 1 auto
flex:none//flex: 0 0 auto,这时候不参与剩余空间的分配,flex-grow,flex-shrink都是0,除了flex:none不参与空间分配,auto/1前两项都是1location.hostname://不包括我们的端口号
location.host://包括我们的端口号
location.search://包括问号和后面所有的内容
location.href//完整的url
















 1902
1902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









