







SoulX-Podcas中最近比较火的语音合成项目,目前gighub上已经有1.8kStar。从https://github.com/Soul-AILab/SoulX-Podcast.git 克隆项目,并根据其requirements.txt创建python3.11环境后,经历了一番折腾,用了差不多一夜的时间,终于跑通。现将几个关键点分享如下:
1.选择python3.10创建环境。
https://github.com/Soul-AILab/SoulX-Podcast中的安装说明用如下指令创建环境
conda create -n soulxpodcast -y python=3.11利用这个环境安装requirements.txt,torch==2.7.1依赖报错。我降级至torch2.6,会引发s3tokenizer.load_audio函数报错。而且最大的问题是triton>=3.0.0依赖包无法安装。在网编寻解决方案,最终结果是pip支持linux环境下的triton,windwos环境要自行进行源代码编译。于是我在github上找到了triton的两个版本的wheel,分别是针对python3.10和python3.12的whl文件。同时考虑troch2.7.1版本的需求,我将环境降到python3.10。并安装pytroch2.7.1:
pip install torch==2.7.1 torchaudio torchvision torchvision --index-url https://download.pytorch.org/whl/cu118注意我此处用的是cuda11.8(cuda+cudnn+onnxruntime-gpu配置请参考我的其他文章),cuda12.0以上我只尝试了12.6,其他的版本请朋友们自行验证。
同时下载triton3.3.0的wheel,直接安装(我已经将其放在我的资源下载列表中,且包含了匹配的sageattention-2.1.1,地址:https://download.csdn.net/download/liangma/92270366)。
提示:CSDN资源库中有python3.11的triton包,大家可以尝试在python3.11中部署此项目。
2.下载speech_tokenizer_v2_25hz.onnx
项目除了要从huggingface下载Soul-AILab/SoulX-Podcast-1.7B外,还要下载speech_tokenizer_v2_25hz.onnx,473M的大小。默认下载后保存路径在windows用户的\.cache\huggingface\hub\s3tokenizer中,我将其搬到项目默认的pretrained_models目录中,并修改models\soulxpodcast.py第25行如下:
self.audio_tokenizer = s3tokenizer.load_model("speech_tokenizer_v2_25hz",download_root="./pretrained_models/s3tokenizer").cuda().eval()
该模型下载地址:https://www.modelscope.cn/models/iic/CosyVoice2-0.5B/resolve/master/speech_tokenizer_v2.onnx
3.单人语音合成说话人2语音参考样本不能为空
项目运行后,其页面上有一些对话示例,点击示例会将相关文字和示例语音填入对应输出框,点击“合成”按钮运行,等待一段时间会出现合成结果。但是如果你只想用单人语音合成,说话人2参考语音不能为空,否则会引发ValueError: Failed to process data. Please check if the prompt audio and text are valid.原因是PodcastDataset.__getitem__中,“说话人 2 参考文本”对应的prompt_text='',而prompt_wav=None。s3tokenizer.load_audio(prompt_wav, sr=16000)运行时,语音文件为None出错。此处代码有兴趣的朋友可以自行修改优化。
另外,合成语音文本输入必须以[S1][S2]开头,分别代表说话人1和说话人2。
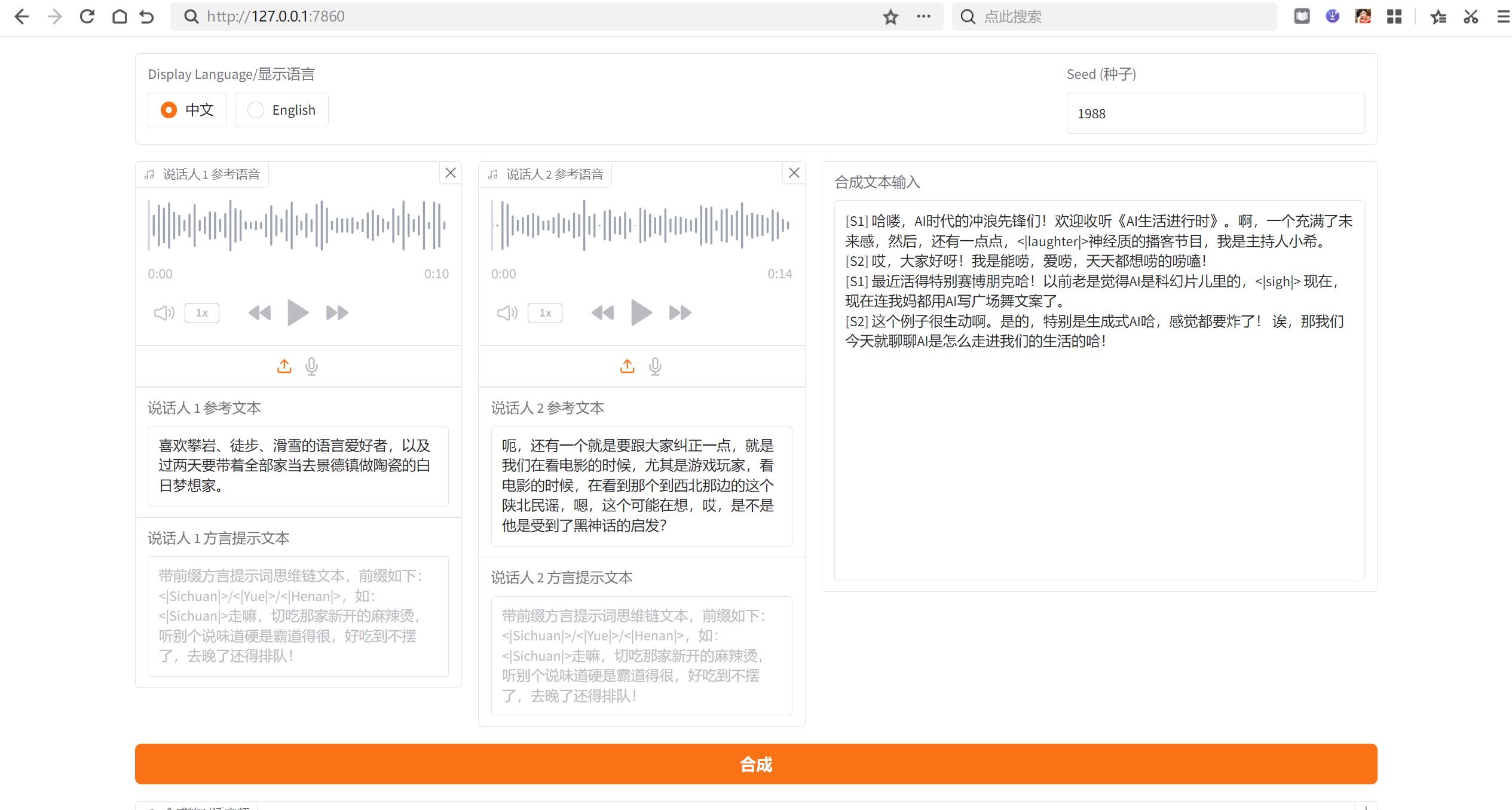
下面是项目运行后浏览器界面
4.关于项目中的Docker+vllm
项目中包含了[Optional] VLLM accleration(Modified version from vllm 0.10.1),我构建image加运行container用了进2个小时,build+vhdx占用磁盘空间近40G,有需求的朋友可以尝试训练,如果仅仅是用现有语音样本合成,则没有必要部署此docker。尤其是电脑硬件条件和我一样的,建议就看看吧。
我的笔记本电脑内存16G,nvidia 4060,8G显存,跑第一个示例用时56秒,听起来效果比index-tts、GPT-SoVITS、Spark-TTS等要自然的多。
最后,上述手记,希望能够帮大家尽快跑通此项目,祝大家好运。


















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









