







`
文章目录
前言
一、Python基础
python官网:(https://www.python.org/)
官网链接直达
缩进
Python语言采用严格的缩进来表明程序的格式框架。缩进是指每一行代码开始前的空白区域。(4个空格或者一个Tab)
注释
单行注释:一个#注释一行
#注释内容
多行注释:一对’''注释多行
'''
注释内容
'''
导入模块(包)(库)
模块又名包,库。使用任何一门语言时,都不可能完完全全的从底层编写每个步骤,所以为了加快效率往往会引用别人的代码,从而诞生了库(包)。在Python中使用包时需要先导入包,
import packagename
eg.
import random python自带的random库
import numpy as np 这里是导入下载好的第三方库numpy库并命名np,当要使用numpy里的函数时,只需np.来带调用函数
pip使用
pip是通用的Python包管理工具包,提供了对 Python 包的查找、下载、安装、卸载、更新等功能.python3.6以上已经捆绑下载安装,不必单独安装。
pip命令行具体使用:
保留字
相当于C/C++里面的关键字,命名时应该注意不要同保留字同名,否则会报错。
保留字往往是一些函数或操作的名称或特定的常值。
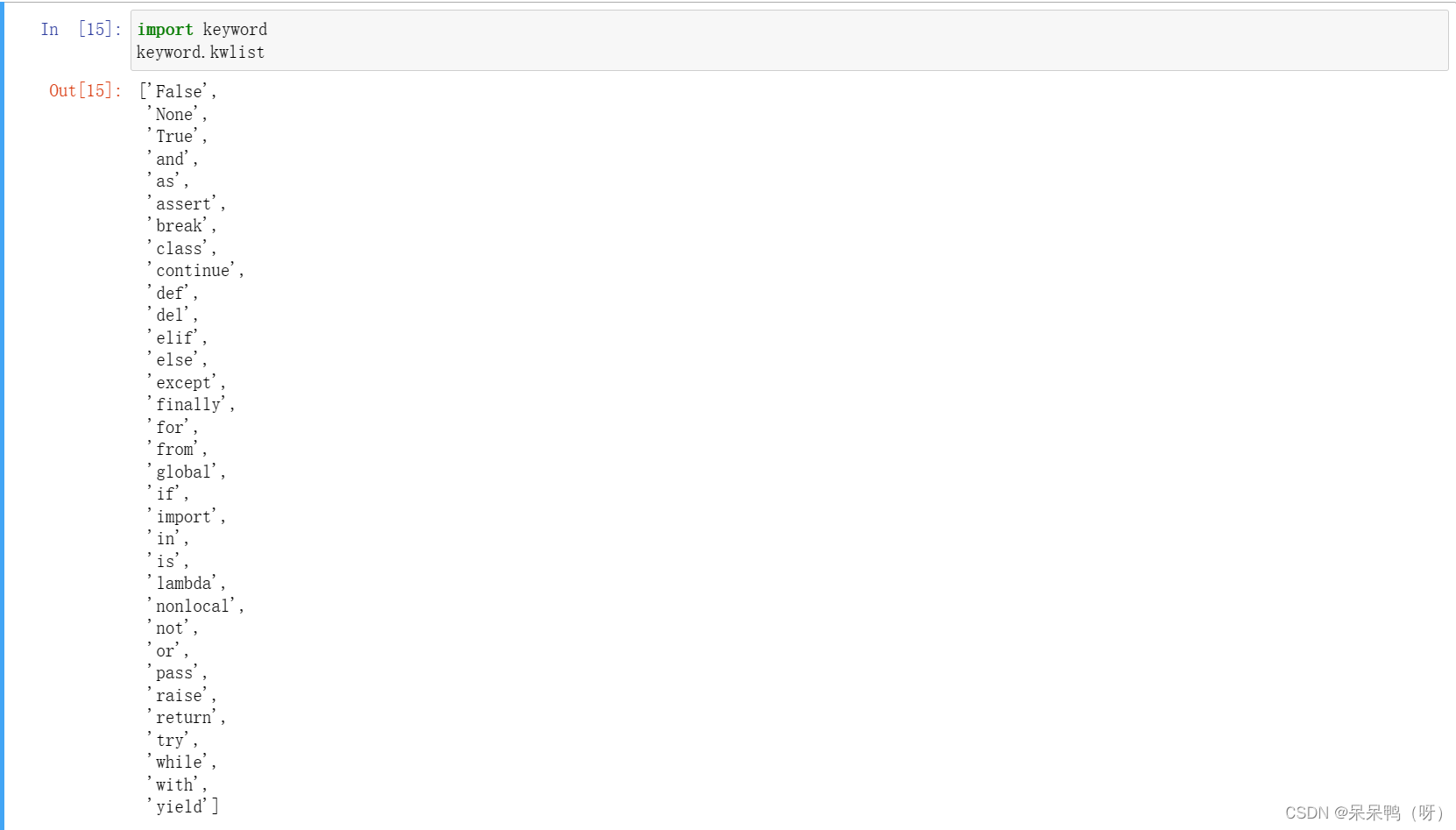
可以通过代码列出所有关键字:
import keyword
keyword.kwlist
运行代码:
Hello world
python的输入输出语句:
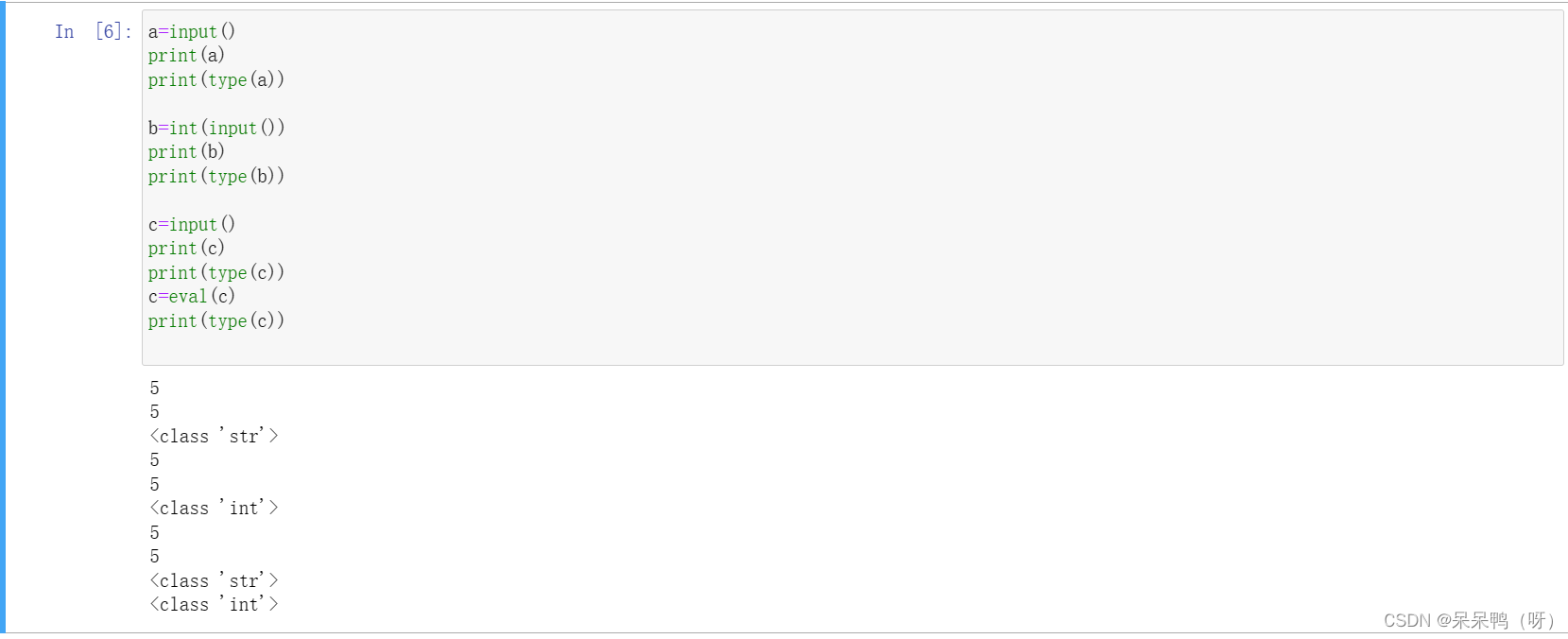
输入通过input()函数输入,input()函数都以字符串返回结果
输出通过print()函数输出
通过type()函数可以查看变量的类型
要想输入赋值int整数类型可以进行强制转换int(),也可以使用python的eval()函数转换为int
a=input()
print(a)
print(type(a))
b=int(input()) #在输入时强制转换为int
print(b)
print(type(b))
c=input()
print(c)
print(type(c)) #打印未使用eval()前的c变量可见是‘str’,字符串
c=eval(c)
print(type(c)) #使用eval()后的c变量,int类型
二、基本数据类型
python数据类型基本上和C/C++数据类型和变量相同,只是些许操作细节方面不同
1.数字
整数,浮点数,复数
整数:略
浮点数:
浮点数科学计数法:<a>e/E<b>=a*10^b
eg.
4.5e-3=4.5*10^-3=0.0043
9.7E+5=9.7*10^5=970000.0
通过
import sys
sys.float_info
可以列出python解释器所运行系统的浮点数的各项参数(浮点数的数值范围和小数精度)

复数:
Python语言中,复数的虚数部分通过后缀“J”或“j”来表示。
a+bj/J(a为实部,b为虚部)
eg.
12.3+4j //实部是1.23 虚部是4
1.23e-4+5.67e+89j //实部是1.23e-4 虚部是5.67e+89
1.52e-5+5.12e+51J //实部是1.52e-5 虚部是5.12e+51
数值运算
| 操作符 | 描述 |
|---|---|
| + - * / | 加减乘除 |
| ** | x的y次幂,即x^y |
| % | x与y之商的余数,模运算 |
| // | x与y之整数商,不大于x与y之商的最大整数 |
数值函数
| 函数 | 描述 |
|---|---|
| abs(x) | x的绝对值 |
| pow(x,y) | x**y,求x的y次幂 |
| max(x1,x2…xn) | 求x1到xn的最大值 |
| min(x1,x2…xn) | 求x1,x2到xn的最小值 |
| round(x,n) | x是要进行四舍五入的数,n是四舍五入多少位的位数 |
| divmod(x,y) | 执行输出(x//y,x%y) |
| complex(re,im) | 生成一个复数,re为实部,im为虚部 |
2.字符串
| 操作符 | 描述 |
|---|---|
| x+y | 连接字符串x与y |
| x * n或n * x | 复制n次字符串x |
| x in s | x为s的子串,返回True否则返回False |
| str[i] | 索引,返回第i 个字符 |
| str[N:M] | 切片,返回索引[N,M)的子串,左闭右开,不包含M |
字符串函数
| 函数 | 描述 |
|---|---|
| len(x) | 返回字符串x的长度 |
| str(x) | 返回任意类型x所对应的字符串形式 |
| x.lower() | 将字符串x转小写 |
| x.upper() | 将字符串x转大写 |
| x.islower() | 判断字符串x是否全为小写,是则返回True,否则返回False |
| x.isnumeric | 判断字符串x是否全为数字,是则返回True,否则返回False |
| x.count(s) | 返回字符串中s字符子串出现的个数 |
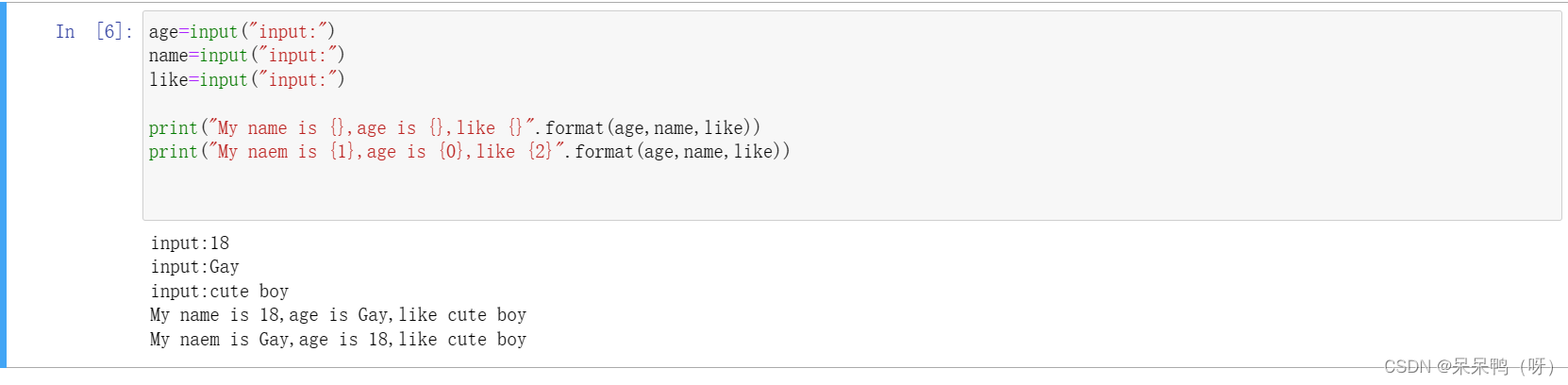
字符串格式控制format()
{}中可以填format()中输出值的索引,从0开始。
输出的格式具有<填充><对齐><宽度><精度><类型>等属性,索引后加’ :'(冒号)即可定义输出格式
<对齐>
| 符号 | 描述 |
|---|---|
| < | 左对齐 |
| > | 右对齐 |
| ^ | 居中对齐 |
<填充>
一般以空格填充,在冒号后加符号即可。
<宽度>
(小数点)‘.’ 开头前跟数字,即宽度。
<精度>
(小数点)‘.’ 开头后跟数字,对于浮点数该数字表示小数部分的有效输出,对于字符串,表示输出的最大长度。

{0:*>10.3}是format中的第一个值用 * 填充,右对齐,10个宽度,保留3个字符
{1:-<10.2}是format中的第二个值用-填充,左对齐,十个宽度,保留两位小数
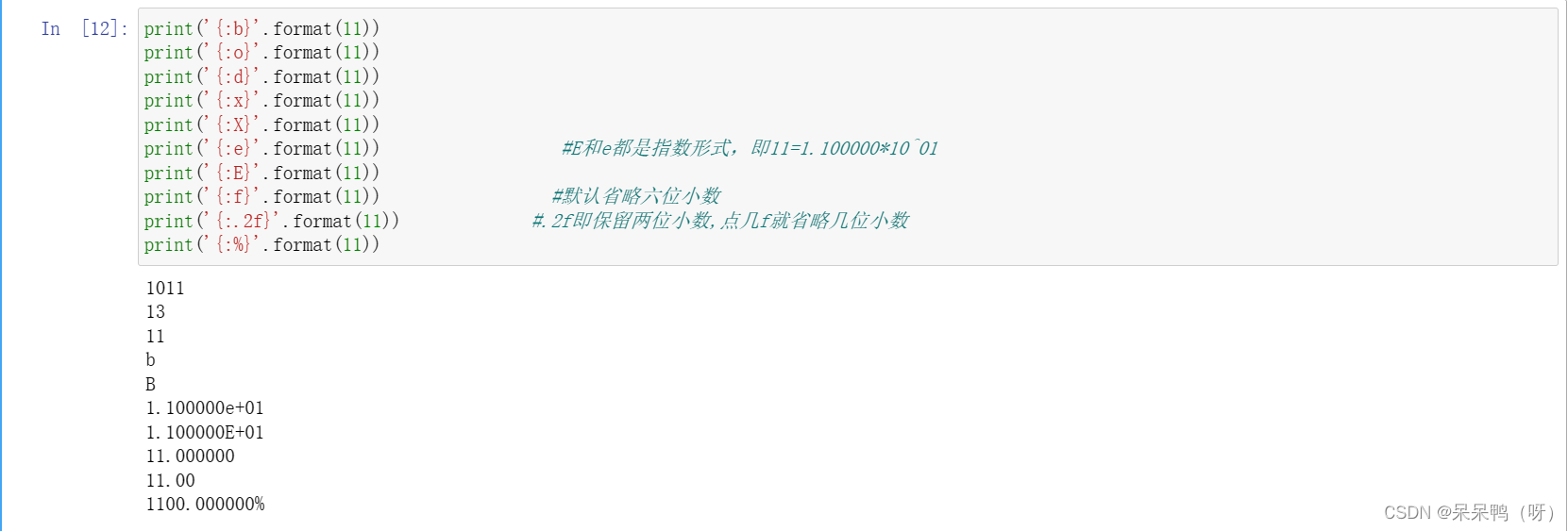
<类型>
| 符号 | 描述 |
|---|---|
| b | 二进制 |
| c | 整数对应的Unicode字符 |
| d | 十进制 |
| o | 八进制 |
| x | 小写十六进制 |
| X | 大写十六进制 |
| e | 小写e指数形式 |
| E | 大写E指数形式 |
| f | 标准浮点数形式 |
| % | 浮点数的%形式 |
eg.
3.列表
列表和数组的区别:
数组不是Python的内置数据类型。 列表是Python的数据类型。 #python里的数组通常要导入第三方模块(库)才能使用,例如numpy等
数组只能存储相同 的数据类型。 列表可以存储不同的数据类型。
list[num]可以选取list中的元素。
从0开始。当num是负数时,从后往前(从右往左)选取元素。
list[0]即第一个元素,list[-1]即最后一个元素
例如

1.list[num1:num2]可以截取一个片段子集.
2.截取的范围左闭右开,即[num1,num2).
3.如果选取全部元素直接打印列表即可.
例如

4.元组
元组和列表的区别:
不可变性: 元组具有不可变性,体现在一旦创建,就不能修改其他元素的值. 列表则能随时更改.
性能: 元组的创建速度比列表更快(因为不用增删操作).
使用场景: 元组通常用于不会改变的数据,例如字典的key. 列表通常用于频繁增删改的数据集合.
元组在定义时需要()来定义,且在定义时,元组中只有单个元素时需要“,”,否则会将其作为‘int’类型

关于不可变性:
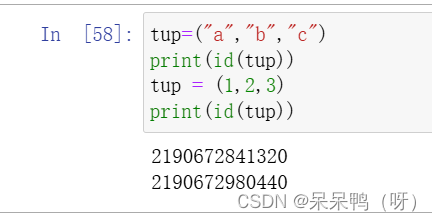
所谓元组的不可变指的是元组所指向的内存中的内容不可变。
id()内置函数会返回该对象的内存地址,由此可见当给tup元组重新赋值时,指向的内存是一块新的内存而不是在原有内存上更改数据值。
虽然定义后的元组不能直接更改值,但是能够将其转化为列表进行更改,再转化为元组。
Python函数利用了元组来实现返回多个值(函数实际上还是返回一个值,一个tuple类型的值)

5.集合
创建一个集合需要使用{},但是空集合需要使用set()函数来创建空集合,不能直接使用{}来创建空集合,因为创建出来的是空字典。

6.字典-
创建一个字典
{key1:value1,key2:value2}
空字典则直接使用{}

三、条件控制及循环语句
if…elif…else
if <条件1>:
<语句块1>
elif <条件2>:
<语句块2>
.....
else:
<语句块N>
for
for <循环变量> in <循环列表>:
<语句块>
for i in range(n) 循环n次
while
while <条件>:
<语句块>
else: //可有可无
<语句块>
四、推导式
推导式是用来快速高效处理数据并,将一个数据序列构建成另一种数据序列的结构体。
推导式的大体格式都大致相同。
特殊的,元组推导式构建的并不直接是元组,而是构建成生成器对象,需要再在后续操作中转换为所需的数据序列。因此元组推导式不仅仅能构建为元组还能构建为除字典外其他数据序列。
列表推导式
推导格式:
[输出表达式 for 变量 in 列表];
[输出表达式 for 变量 in 列表 if 条件表达式];
num=[i for i in range(20) if i>10]
print(num)
word1=['Tom','Lisa','Coco','Lucky']
word2=[w.upper()for w in word1 if len(w)>3 ]
print(word2)
集合推导式
推导格式:
{输出表达式 for 变量 in 列表};
{输出表达式 for 变量 in 列表 if 条件表达式};
dict1={w:len(w) for w in word1 if len(w)>3}
print(dict1)
字典推导式
推导格式:
{输出表达式 for 变量 in 列表};
{输出表达式 for 变量 in 列表 if 条件表达式};
set1={w for w in word1 if len(w)>3}
print(set1)
元组推导式
推导格式:
(输出表达式 for 变量 in 列表);
(输出表达式 for 变量 in 列表 if 条件表达式);
tup1=(w for w in word1 if len(w)>3) #返回生成器对象
print(tup1)
print(tuple(tup1)) #构建为元组
tup2=(w for w in word1 if len(w)>3) #返回生成器对象
print(tup2)
print(list(tup2)) #构建为列表

元组本身具有不可变性,但推导式并不会改变原有元组,推导式是从原有的数据基础上选出数据构建一个新的数据列表。

五、迭代器和生成器
for循环实际上是创建了一个迭代器对象,并一直调用next(),直到没有下一个元素时返回StopTteration异常。
string0='LittleBear' #python中的for循环原理
it=iter(string0)
while True:
try:
print(next(it))
except StopIteration:
break

python中的数据有可迭代对象和不可迭代两种类型。
for循环遍历列表:

for循环遍历字符串:

而数字不可迭代:

报错为:int类型对象不可被迭代。 原因:int类型并不包含__iter__方法
查看对象是否含有某个属性
hasattr(对象,属性名)
返回True / False
查看对象是否__iter__即可查看其对象是否含有迭代器。注意是两个_

迭代器作用:
能使用更小的内存处理更多的数据。
假设有一个文件需要将文件中的数据每行都进行process_line(line)的操作。
filepath='./logfile.log' //假设有一个文件
process_line(line): //假设一个函数操作
pass //略
1.直接读取文件中所有内容到lines列表中(内存消耗大)
with open(filepath,'r') as f:
lines=f.rendline() //将文件内容读取到一个lines列表中,此时内存为lines的总大小,即为全部读取后的数据开辟的内存空间
for line in lines: //再对列表中的每行数据进行操作
process_line(line)

2.定义一个迭代器类,创建一个迭代器,一行一行进行操作(内存消耗小)
class LineIterator: //定义一个迭代器类
def __init__(self,filepath): //初始化迭代器
self.file=open(filepath,'r')
def __iter__(self): //迭代器需要定义一个__iter__来返回迭代器本身
return self
def __next__(self):
line=self.file.readline() //line读取一行并开辟一行的内存
if line: //如果line存在
return line //返回这一行的数据
else //如果line不存在
self.file.close() //关闭文件
raise StopIteration //返回StopIteration异常
line_iter=LineIterator(filepath) //创建 0
for line in line_iter: //line_iter取代了原先lines的位置
process_line(line)

生成器
生成器是一种特殊的迭代器,是迭代器的简单实现,生成器有两种写法,生成器函数和生成器表达式。
在python中一个函数内含有yield,就会被当生成器函数,当运行到yield时会被传出值并且暂停函数内部yield的下面的语句执行,等待下一次调用函数时从当前yield的下一条语句开始执行。
def generator(n):
for i in range(n):
print('A')
yield i //生成i的值即传出i
print('B')
gen =generator(3)
print(next(gen)) //next函数执行一次
print('---')
for i in gen:
print(i)
print("\n")

六、函数
def 函数名(参数列表):
函数体
return 返回值列表
函数可以有返回值也可以没有,print(函数名)即可打印出函数的返回值
def hello():
print("hello"+" "+world())
def world():
return "world"
hello()

当函数return多个值时会以元组的形式返回
def r():
x=3
return 1,2,x
print(r())

*参数,将以元组形式导入。存放后面的未知参数
**参数,将以字典形式导入。存放后面的未知参数
def add(a,b):
return a+b
x1=add(3,5)
print(x1)
def p(arg1,*arg2):
print(arg1)
print(arg2)
p(1,2,3,4,5,6,7,8,9)

lambda匿名函数
函数名=lambda 参数1,参数2 : 表达式

七、类和对象
假如人类是一个类,你是一个对象,你的对象也是一个对象.....,类内会有属性和方法,就如人类有身高等数值人物的固有属性,方法就像一些先天人会做的规律动作,如人吃饭睡觉拉屎等动作规律
创建一个Person类:
class Person:
nation='中国'
def eat(self):
print('eat rice')
def get_nation(self):
print(nation)
创建一个实例对象
p1=person() //对象名=类名(参数1,参数2...)
调用类内方法和类内属性
p1.eat() //调用eat()
p1.get_nation() //调用类内打印nation属性
print(p1.nation) //打印p1中的ntion属性

__init __()
__ init__(self,…)是一个内置方法
在python中每次创建对象时会自动调用__init__()内置方法
我们可以通过__init__()函数赋值给实例对象的属性,而不是像刚刚上述一样在类内固定的那些值,通过__init__()初始化对象实例属性。
def __init__(self,参数1,参数2...): //这里的参数1,参数2是外部在创建实例时传入的
self.参数_1=参数1 //这里的参数_1,参数_2是在类内部的
self.参数_2=参数2

注意:在python中,self是一个约定俗成的参数,指向类实例本身。在类中的任意函数都含有self参数,且首个参数都是self.
如果不带self参数,就会报TypeError的异常错误,提示该函数接受了0个参数,但给定了一个参数,如下:

你也可以用其他字符来命名self,比如abc,或者s

del
del 类名 //删除类
del 对象名 //删除对象实例
del 对象.属性 //删除对象的属性
id(object) //会返回object的内存地址

pass语句
类和函数定义不能为空,若要写无内容的类或类方法时,可以使用pass语句避免报错。
class A:
pass
继承
继承用于大类中还有小类的时候,例如动物,假如动物中又可以分为海洋动物和陆地动物,这里动物就是父类,海洋动物和陆地动物就是子类,两个子类都继承了父类的一些属性但又在父类的基础上多出了一些不同的属性和行为方法
M和T继承了父类Animal
class Animal:
pass
class M(Animal):
pass
class T(Animal):
pass
C同时继承了A,B两个父类
class A:
pass
class B:
pass
class C(A,B)
pass
super()
使用super()方法继承父类的方法和属性。
super().父类中的方法名(属性名)
子类son继承父类father中的smart()函数
class father:
def __init__(self,name,age):
self.age=age
self.name=name
def smart(self):
print("very smart!")
class son(father):
def __init__(self,name,age):
self.name=name
self.age=age
def smart(self):
super().smart()
father1=father("Make",32)
son1=son("jake",5)
print(father1.name,father1.age)
print(son1.name, son1.age)
son1.smart()

class A:
def __init__(self):
print("A")
class B(A):
def __init__(self):
print("B")
super().__init__()
class C(A):
def __init__(self):
print("C")
super().__init__()
class D(B,C):
def __init__(self):
print("D")
super().__init__()
d=D()
print(D.__mro__)


顺序为DBACA,pyhton3中会去重保留后面的,也就是DBCA
class A:
def __init__(self):
print("A")
class B(A):
def __init__(self):
print("B")
super().__init__()
class C(A):
def __init__(self):
print("C")
super().__init__()
class D(A):
def __init__(self):
print("D")
super().__init__()
class E(A):
def __init__(self):
print("E")
super().__init__()
class F(B,C):
def __init__(self):
print("F")
super().__init__()
class G(C,D):
def __init__(self):
print("G")
super().__init__()
class H(D,E):
def __init__(self):
print("H")
super().__init__()
class I(F,G):
def __init__(self):
print("I")
super().__init__()
class J(G,H):
def __init__(self):
print("J")
super().__init__()
class K(I,J):
def __init__(self):
print("K")
super().__init__()
k=K()
print(K.__mro__)

遍历顺序:
KIFBA
CA
GAC
JGCA
DA
HDA
EA
按顺序链接并去重保留后面的值后:
KIFBJGCHDEA
八、异常处理
try:
语句块1
except 异常类型1:
语句块2
.....
except 异常类型N: (支持多异常处理)
语句块N+1
这里我应该输入的是数字但是输入了一个字符串,报了NameError的异常错误。
NameError就是异常类型,“:”后是具体描述。

这里当你输入某些特殊字符串,会报不一样的异常。比如if和as等…
该异常为SyntaxError,语法错误,解析时预期的EOF。这是因为if和as本身是关键字.

实现只输入数字:
def x2():
x=eval(input("请输入数字:"))
print(x**2)
def tryit():
try:
x2()
except NameError:
print("请重新输入数字")
tryit()
tryit()

九、文件读写
使用open()函数操作文件;
f=open(file,mode)
file是文件路径,相对路径或者绝对路径
mode是可选模式
f即文件对象
| mode | 作用 |
|---|---|
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| + | 打开一个文件进行更新(可读可写)。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| b | 二进制模式。 |
| … | … |
f=open('file.txt')
f=open('file.txt','rt')
在创建了文件对象后使用相应的文件对象函数即可对文件进行操作
file.close()
file.read()
file.read(num) 读取前num个字符
file.readline()
file.write(str) 写入字符串
file.writelines(sequence) 写序列字符串
…
f.open('test.txt')
print(f.read(5))
print(f.read())
f.close()

二进制读取图片数据

文件在打开后需要关闭否则会占用资源
如果觉得每次打开文件后都要关闭很麻烦可以使用with语法不用写close()
with open('test.txt','w') as f:
f.write()
with open('test.txt','r') as f:
f.readline()
十、使用包(库)
python标准库
| 库名 | 用途 |
|---|---|
| os | os 模块提供了许多与操作系统交互的函数。例如创建、移动和删除文件和目录,以及访问环境变量等。 |
| sys | sys 模块提供了与 Python 解释器和系统相关的功能。例如解释器的版本和路径,以及与 stdin、stdout 和 stderr 相关的信息。 |
| time | time 模块提供了处理时间的函数。例如获取当前时间、格式化日期和时间、计时等。 |
| datetime | datetime 模块提供了更高级的日期和时间处理函数。例如处理时区、计算时间差、计算日期差等。 |
| random | random 模块提供了生成随机数的函数,例如生成随机整数、浮点数、序列等。 |
| math | math 模块提供了数学函数,例如三角函数、对数函数、常数等。 |
| re | re 模块提供了正则表达式处理函数,可以用于文本搜索、替换、分割等。 |
| json | json 模块提供了 JSON 编码和解码函数,可以将 Python 对象转换为 JSON 格式,并从 JSON 格式中解析出 Python 对象。 |
| urllib | urllib 模块提供了访问网页和处理 URL 的功能。包括下载文件、发送 POST 请求、处理 cookies 等。 |
第三方库使用
数据分析:
1.Numpy
2.pandas
3.matplotlib
4.jieba
等…
爬虫:
1.requests
2.Beauitiful Soup
3.PySpider
4.Scrapy
5.Portia
6.lxml
等…
机器学习:
TensorFlow
等…















 1340
1340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









