









应朋友之要求,要爬一个小数据量的网站数据,过程分享下来(菜鸟一只,哪里不对望谅解么么哒(*  ̄3)(ε ̄ *))
那么给出target:
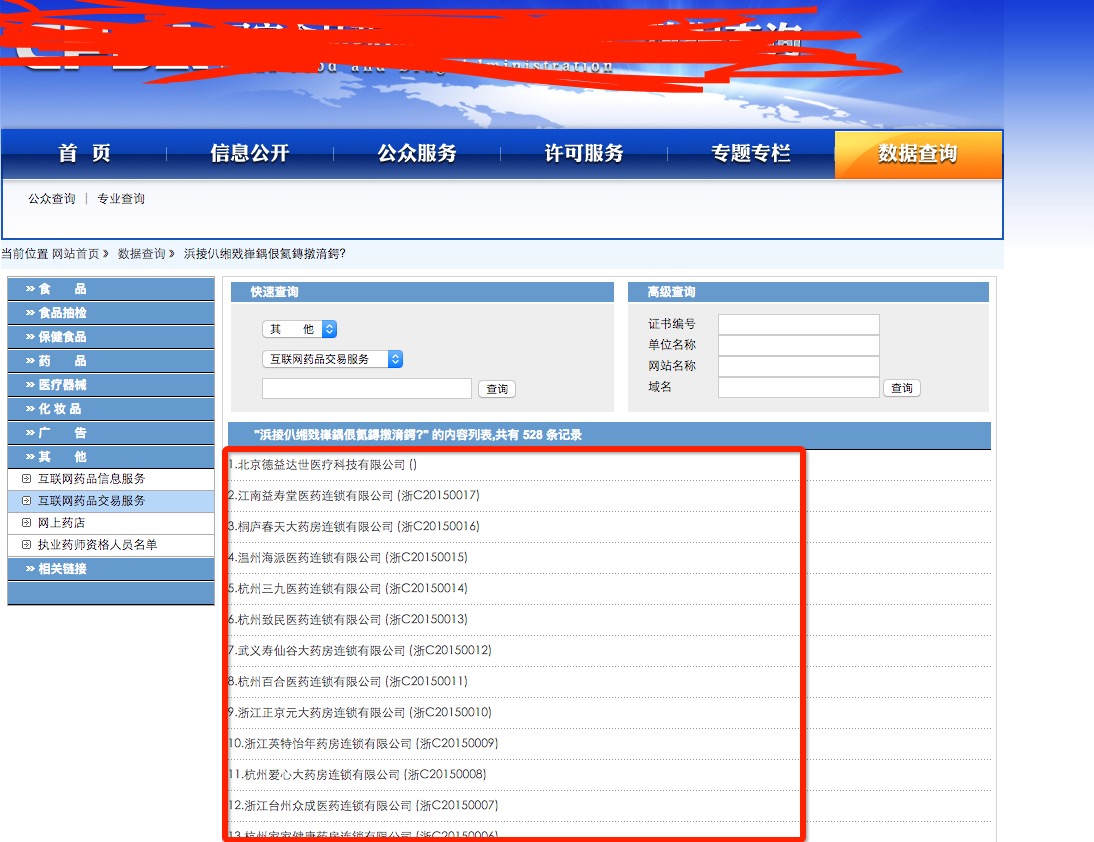
常规流程,先requests 抓下来发现并没有想要的记录数据,是动态网站无疑了,那么接下来就开始分析。
chrome打开网页,检查元素
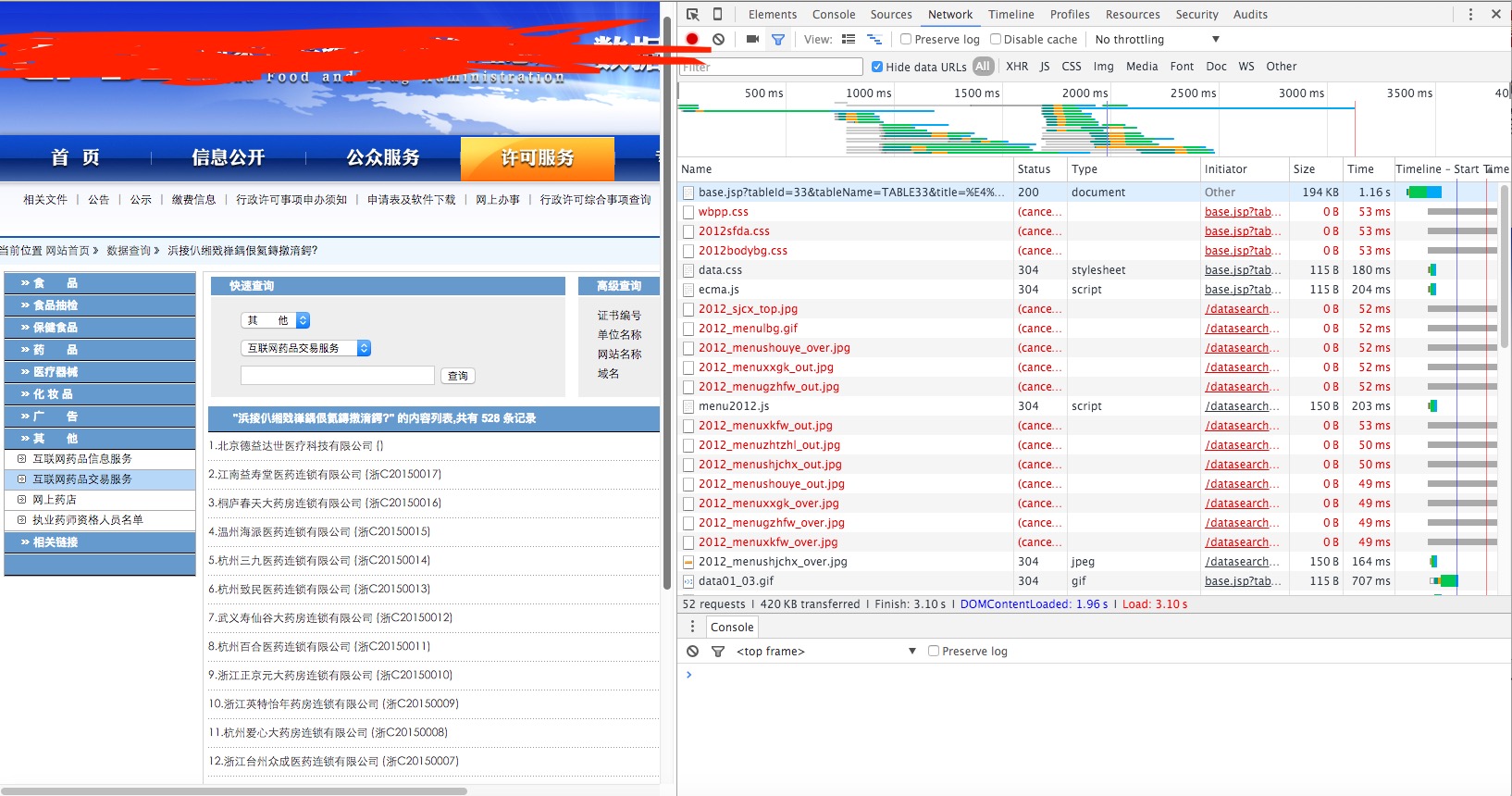
filter过滤非js请求

基本可以锁定请求是在这个js请求里的(别问我是怎么知道的233333),复制下来
接下来就是看网页源码了,右键显示源码

这里先以“互联网药品交易服务入手”为例子
搜素该关键字

发现onclick=javascript:sform(7,0,this,'28') 是它的点击事件,我们在刚才的复制下来的js请求中搜索该函数 sform
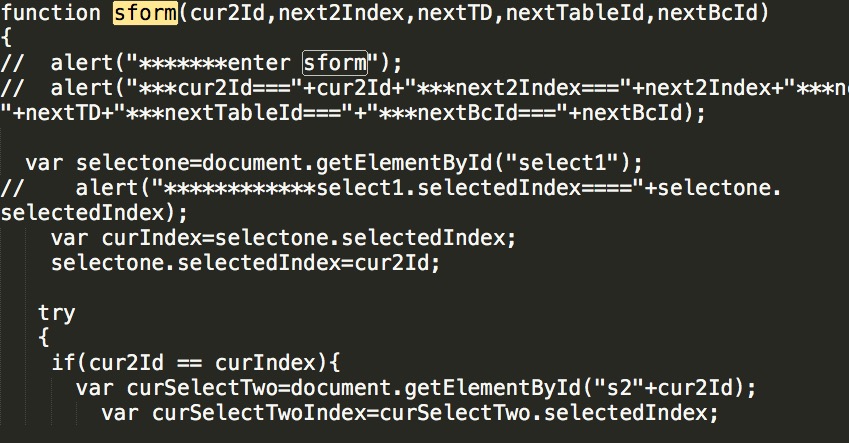
//cur2id 当前select2的Div的Id
//next2Index select2的然后selectedIndex
//nextText 然后显示表名
//nextTableId 然后tableId
function sform(cur2Id,next2Index,nextTD,nextTableId,nextBcId)
{
// alert("*******enter sform");
// alert("***cur2Id==="+cur2Id+"***next2Index==="+next2Index+"***nextTD==="+nextTD+"***nextTableId==="+"***nextBcId==="+nextBcId);
var selectone=document.getElementById("select1");
// alert("************select1.selectedIndex===="+selectone.selectedIndex);
var curIndex=selectone.selectedIndex;
selectone.selectedIndex=cur2Id;
try
{
if(cur2Id == curIndex){
var curSelectTwo=document.getElementById("s2"+cur2Id);
var curSelectTwoIndex=curSelectTwo.selectedIndex;
// alert("&&&&&&&&&&&&&&&&&&&&&===========curSelectTwoIndex===="+curSelectTwoIndex);
curSelectTwo.selectedIndex=next2Index;
var curDivThree=document.getElementById("s3d"+cur2Id+'p'+curSelectTwoIndex);
var curFormDiv=document.getElementById("formDiv"+cur2Id+'p'+curSelectTwoIndex);
if(curFormDiv.style.display=="none")
{
curFormDiv=s3Form;
}
curFormDiv.style.display="none";
curDivThree.style.display="none";
var trs=document.getElementById("ta"+cur2Id).rows;
for(var i=0;i<trs.length;i++)
{
trs[i].bgColor="";
}
}else{
var curSelectTwo=document.getElementById("s2"+curIndex);
var curSelectTwoIndex=curSelectTwo.selectedIndex;
// alert("&&&&&&&&&&&&&&&&&&&&&===========curSelectTwoIndex===="+curSelectTwoIndex);
curSelectTwoNew=document.getElementById("s2"+cur2Id);
curSelectTwoNew.selectedIndex=next2Index;
var curDivTwo=document.getElementById("s2d"+curIndex);
var curDivThree=document.getElementById("s3d"+curIndex+'p'+curSelectTwoIndex);
var curFormDiv=document.getElementById("formDiv"+curIndex+'p'+curSelectTwoIndex);
if(curFormDiv.style.display=="none")
{
curFormDiv=s3Form;
}
curFormDiv.style.display="none";
curDivThree.style.display="none";
curDivTwo.style.display="none";
var trs=document.getElementById("ta"+cur2Id).rows;
for(var i=0;i<trs.length;i++)
{
trs[i].bgColor="";
}
}
//var curSelectTwo=document.getElementById("s2"+cur2Id);
// var curSelectTwoIndex=curSelectTwo.selectedIndex;
// alert("&&&&&&&&&&&&&&&&&&&&&===========curSelectTwoIndex===="+curSelectTwoIndex);
//curSelectTwo.selectedIndex=next2Index;
// var curDivThree=document.getElementById("s3d"+cur2Id+'p'+curSelectTwoIndex);
//var curFormDiv=document.getElementById("formDiv"+cur2Id+'p'+curSelectTwoIndex);
//if(curFormDiv.style.display=="none")
//{
// curFormDiv=s3Form;
//}
//curFormDiv.style.display="none";
//curDivThree.style.display="none";
//var trs=document.getElementById("ta"+cur2Id).rows;
//for(var i=0;i<trs.length;i++)
//{
// trs[i].bgColor="";
// }
}
catch(e)
{}
try
{
var nextDivTwo=document.getElementById("s2d"+cur2Id);
nextDivTwo.selectedIndex=next2Index;
var nextDivThree=document.getElementById("s3d"+cur2Id+'p'+next2Index);
var nextFormDiv=document.getElementById("formDiv"+cur2Id+'p'+next2Index);
nextDivTwo.style.display="block";
nextDivThree.style.display="block";
nextFormDiv.style.display="block";
var tn=document.getElementById("tn");
var keyTableId=document.getElementById("keyTableId");
var keyBcId=document.getElementById("keyBcId");
tn.innerHTML=nextTD.innerHTML;
keyTableId.value=nextTableId;
keyBcId.value=nextBcId;
document.getElementById("tr"+cur2Id+'p'+next2Index).bgColor=sColor;
try
{
nextDivThree.firstChild.selectedIndex=0;
}catch(eee)
{}
}
catch(e)
{
tn.innerHTML="";
keyTableId.value=""
}
document.getElementById("keyword").value="";
document.getElementById("form"+cur2Id+'p'+next2Index).submit();
}好吧,我承认你头昏脑胀的看完代码后并不能得到什么有用的东西
那么接下来怎么办呢,我们知道js一般是ajax请求的,我们尝试搜索XMLHttpRequest
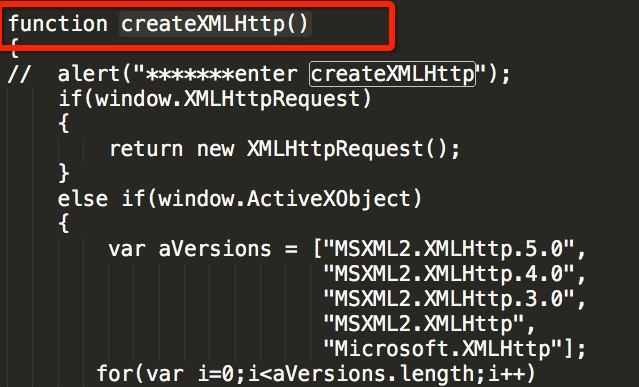
我们发现了这一个createXMLHttp()函数,稍微看下代码,发现是初始化请求的函数,应该请求数据的函数会调用这个函数,我们搜索这个函数名
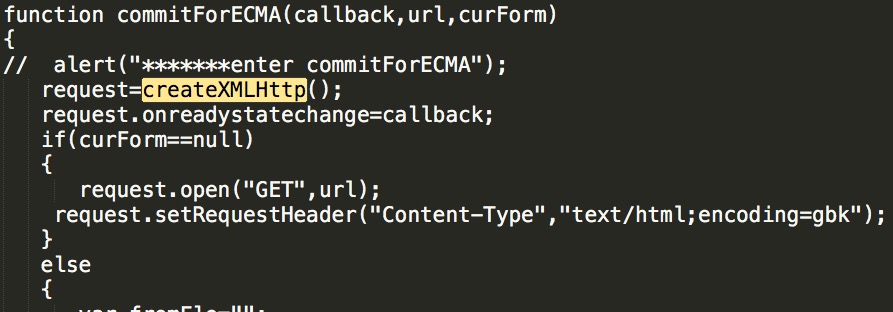
function commitForECMA(callback,url,curForm)
{
// alert("*******enter commitForECMA");
request=createXMLHttp();
request.onreadystatechange=callback;
if(curForm==null)
{
request.open("GET",url);
request.setRequestHeader("Content-Type","text/html;encoding=gbk");
}
else
{
var fromEle="";
var myElements=curForm.elements;
var myLength=myElements.length;
for(var i=0;i<myLength;i++)
{
var myEle=myElements[i];
if(myEle.type!="submit"&&myEle.value!="")
{
if(fromEle.length>0)
{
fromEle+="&"+myEle.name+"="+myEle.value;
}
else
{
fromEle+=myEle.name+"="+myEle.value;
}
fromEle+="&State=1";
}
}
request.open("POST",url);
fromEle=encodeURI(fromEle);
fromEle=encodeURI(fromEle);
request.setRequestHeader("cache-control","no-cache");
request.setRequestHeader("Content-Type","application/x-www-form-urlencoded");
}
// alert('FAFA44');
request.send(fromEle);
//alert('AAA22');
if(curForm != null){
curForm.reset();
}
}我们分析下代码,if (curForm == null)是一个GET请求,else则构造一个POST请求,
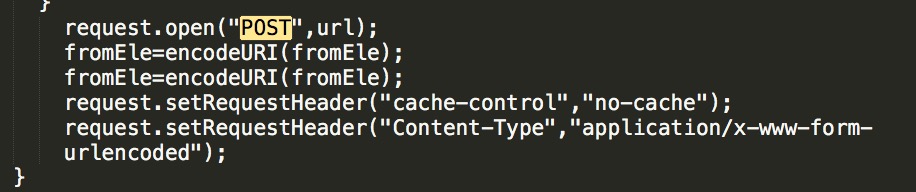
我们在在源码里搜索这个函数名CommitForECMA
发现这处调用很特别
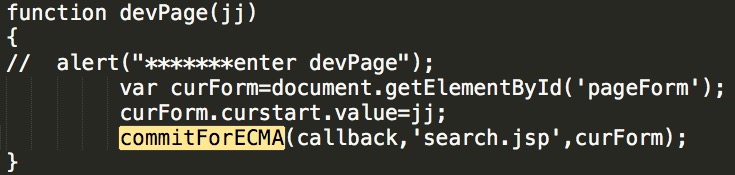
devPage难道和页面跳转有关?,我们仔细研读一下,我们发现它有获得id为‘pageForm’的标签,搜索它

<form method=post id=pageForm nam<form method=post id=pageForm name=pageForm>
<input type=hidden name=tableId value=33>
<input type=hidden name=bcId value=118715801943244717582221630944>
<input type=hidden name=tableName value=TABLE33>
<input type=hidden name=viewtitleName value=COLUMN312>
<input type=hidden name=viewsubTitleName value=COLUMN310>
<input type=hidden name=keyword value=>
<input type=hidden name=curstart value=>
<input type=hidden name=tableView value=浜掕仈缃戣嵂鍝佷氦鏄撴湇鍔?>
</form>诶嘿,你是不是发现了什么?POST请求和参数是不是有了?跳转下一页参数curstart不就是吗!好的我们已经很接近真相了
那么问题来了post请求的URL是什么?别忘了之前的devPage这个函数,
function devPage(jj)
{
// alert("*******enter devPage");
var curForm=document.getElementById('pageForm');
curForm.curstart.value=jj;
commitForECMA(callback,'search.jsp',curForm);
}
‘search.jsp’是不是?什么你说这个不是url?
“http://app1.sfda.gov.cn/datasearch/face3/search.jsp”主站页面加它不就是url了吗~
至于,跳转到下一页怎么跳呢?忘了之前的GET了吗?我们再次搜索commitForECMA这个函数

you got it,get地址你有了,我们试一试
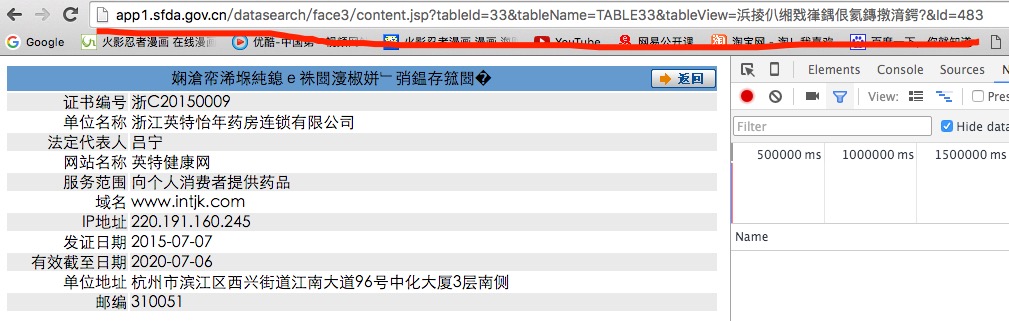
yes~那么已经拨云见日了,post请求header和data你都有了,下一级的页面地址你也有了,那么就开始愉快的写代码吧~~~
下面给出丑陋的python代码:
# -*- coding: utf-8 -*-
from multiprocessing import Process, Pool
import os, threading
from bs4 import BeautifulSoup
import requests
from requests import Request, Session
import pymysql,random, selenium, re
# 下一级的url列表
URLS = []
# 地址列表
IPANDPORT = []
# 目标host
HOST = 'http://app1.sfda.gov.cn/datasearch/face3/'
# session会话
session = Session()
# 获取代理列表
def getTheRemoteAgent():
f = open("proxy_list.txt", "r")
for line in f:
IPANDPORT.append(line)
f.close()
def getNextUrl(target_url, index):
headers = {'User-Agent':'Mozilla/5.0 (compatible; WOW64; MSIE 10.0; Windows NT 6.2)',
'X-Requested-With':'XMLHttpRequest',
"cache-control":"no-cache",
"Content-Type":"application/x-www-form-urlencoded"
}
if index != 0:
data = {
'tableId':'33',
'bcId':'118715801943244717582221630944',
'tableName':'TABLE33',
'viewtitleName':'COLUMN312',
'viewsubTitleName':'COLUMN310',
'curstart':'%s' % index,
}
else:
data = {
'tableId':'33',
'bcId':'118715801943244717582221630944',
'tableName':'TABLE33',
'viewtitleName':'COLUMN312',
'viewsubTitleName':'COLUMN310',
}
prepare = Request('POST', target_url, headers=headers, data=data).prepare()
# try多次
attempts = 0
success = False
while attempts < 3 and not success:
try:
index = random.randint(0, len(IPANDPORT)-1)
proxy = {'http':'http://%s' % IPANDPORT[index].strip()}
print proxy
result = session.send(prepare, timeout=20, proxies=proxy)
success = True
except Exception, e:
print '请求失败, 重试...'
print e
attempts += 1
if attempts==3:
print '请求三次失败,跳过'
pass
# print result.text
prase(result.text)
def getNextPage(url):
attempts = 0
success = False
while attempts < 3 and not success:
try:
index = random.randint(0, len(IPANDPORT)-1)
proxy = {'http':'http://%s' % IPANDPORT[index].strip()}
print proxy
result = session.get(url, timeout=20, proxies=proxy, headers={'User-Agent':'Mozilla/5.0 (compatible; WOW64; MSIE 10.0; Windows NT 6.2)',})
success = True
except Exception, e:
print '请求失败, 重试...'
print e
attempts += 1
if attempts==3:
print '请求三次失败,跳过'
pass
parseSecPage(result.text)
def parseSecPage(text):
soup = BeautifulSoup(text, 'lxml')
trs = soup.find_all('tr')
args = []
for tr in trs:
td = tr.find('td', {'width':'83%'})
if (td):
print td.text
args.append(td.text)
writeTofile(*args)
def prase(text):
soup = BeautifulSoup(text, 'lxml')
As = soup.find_all('a')
for a in As:
urlSuff = a['href'].split('\'')[1]
print HOST + urlSuff
# 开启多线程获取下一级页面
t = threading.Thread(target=getNextPage, args=(HOST + urlSuff,))
# getNextPage(HOST+urlSuff)
t.start()
t.join()
def writeTofile(*arr):
print arr
path = os.path.expanduser(r'~/Desktop/data/test.txt')
print path
f = open(path, "a")
if arr:
for rag in arr:
if isinstance(rag, int):
f.write(str(rag)+',')
else:
f.write(rag.encode('utf8')+',')
f.write('\n')
f.close()
# if __name__ == '__name__':
getTheRemoteAgent()
pool = Pool()
for index in range(37):
host = 'http://app1.sfda.gov.cn/datasearch/face3/search.jsp'
pool.apply_async(getNextUrl, args=(host, index,))
pool.close()
pool.join()
print 'All subprocesses done.'















 5272
5272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









