







经过一段时间的摸索,终于有了一套爬取动态网页的方法,此方法适合大多数的动态网页爬取,至于另外少数的动态网页爬取,还必须利用其它的办法。在此分享给大家。
举例:例如在百度中搜索成语词典,显示如下,需要爬取所有的成语词汇。我们可以点击下一页查看,有经验的同学一眼就可以看出这里是使用javascript异步加载的。在网页源码上是找不到的。下面就介绍爬取所有词典的方法
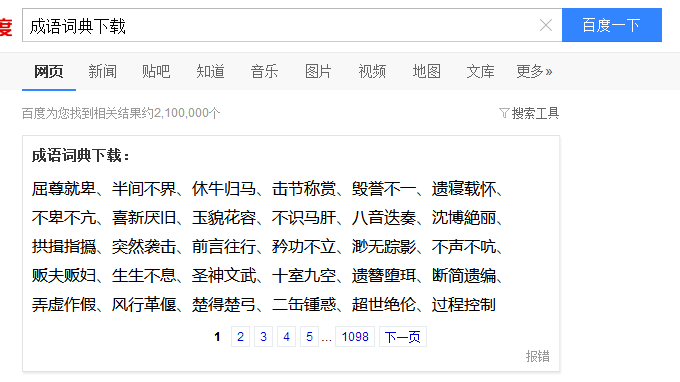
1.点击鼠标右键–>审查元素
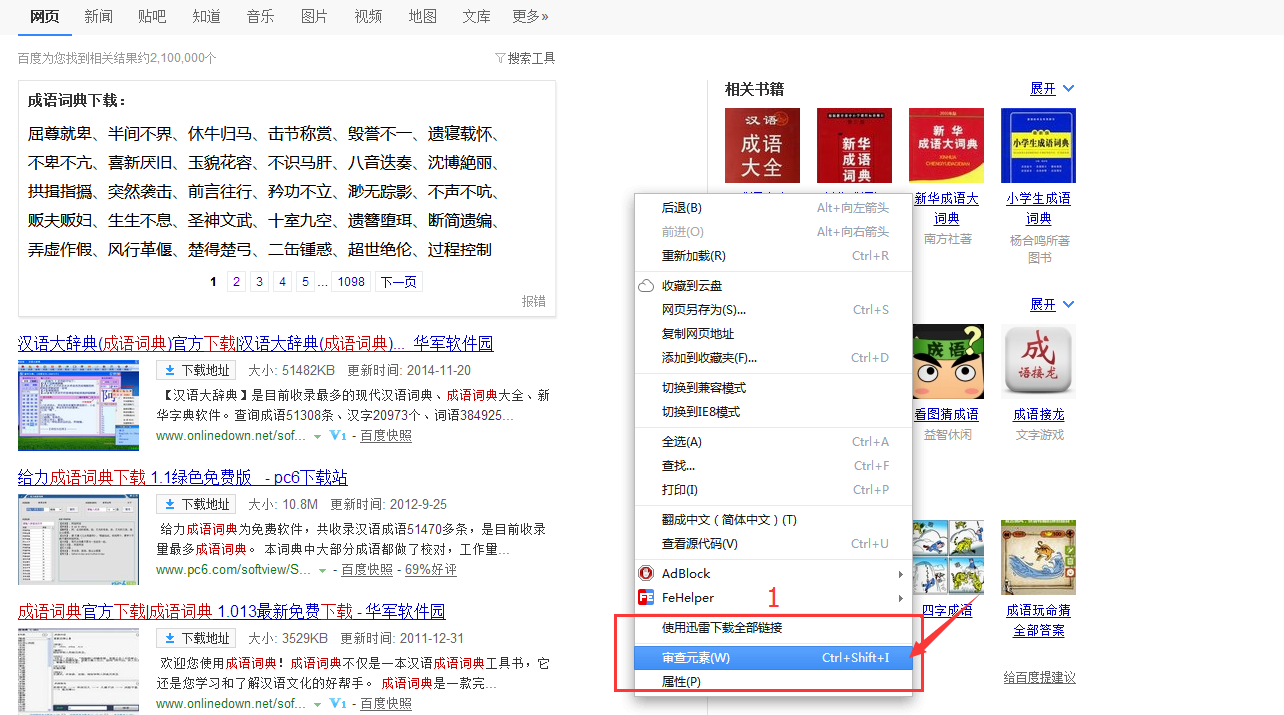
2.选择Network按钮
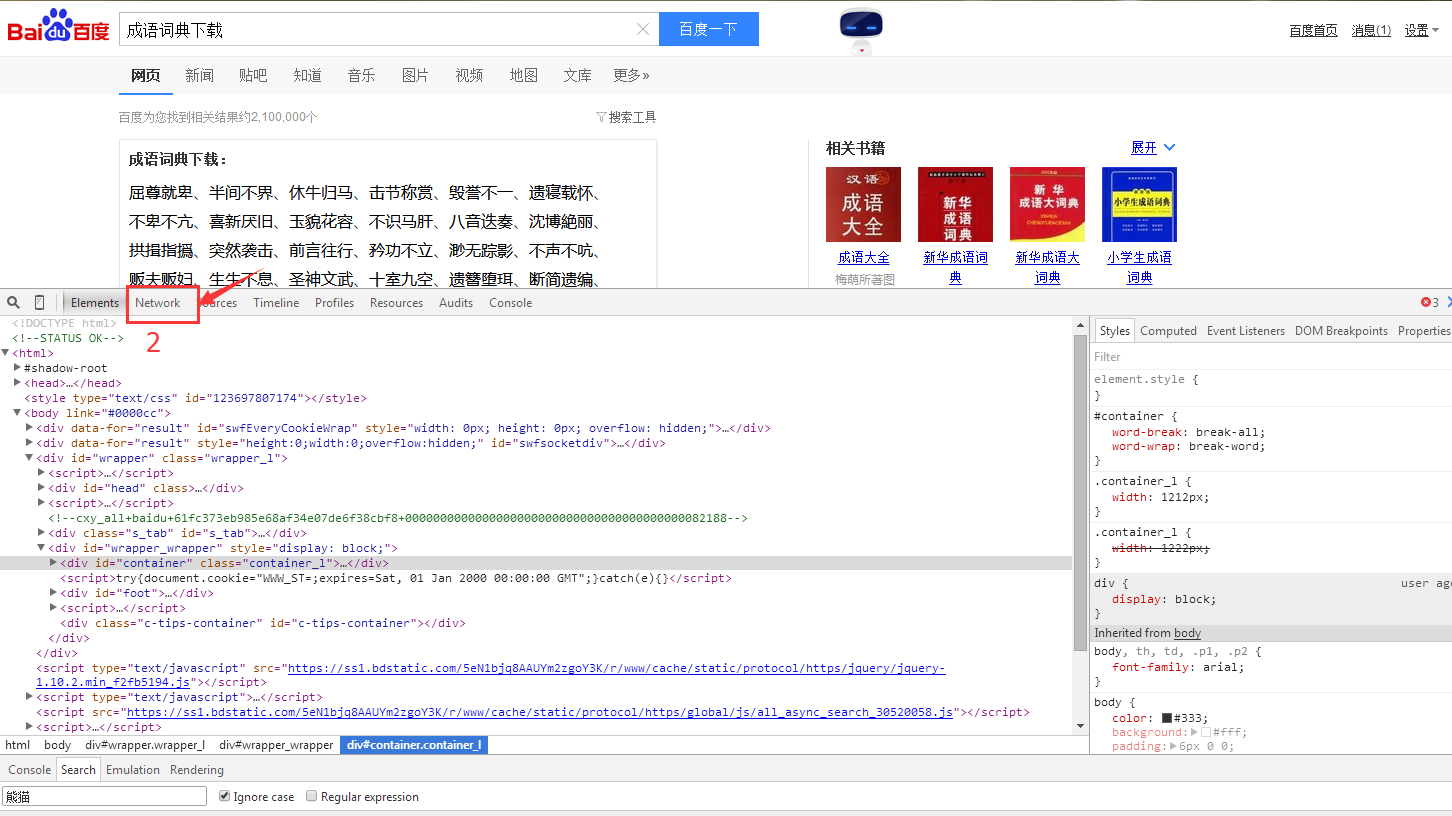
3.选择下一页按钮 得到的效果是如下图,我们可以发现出现两个网址,
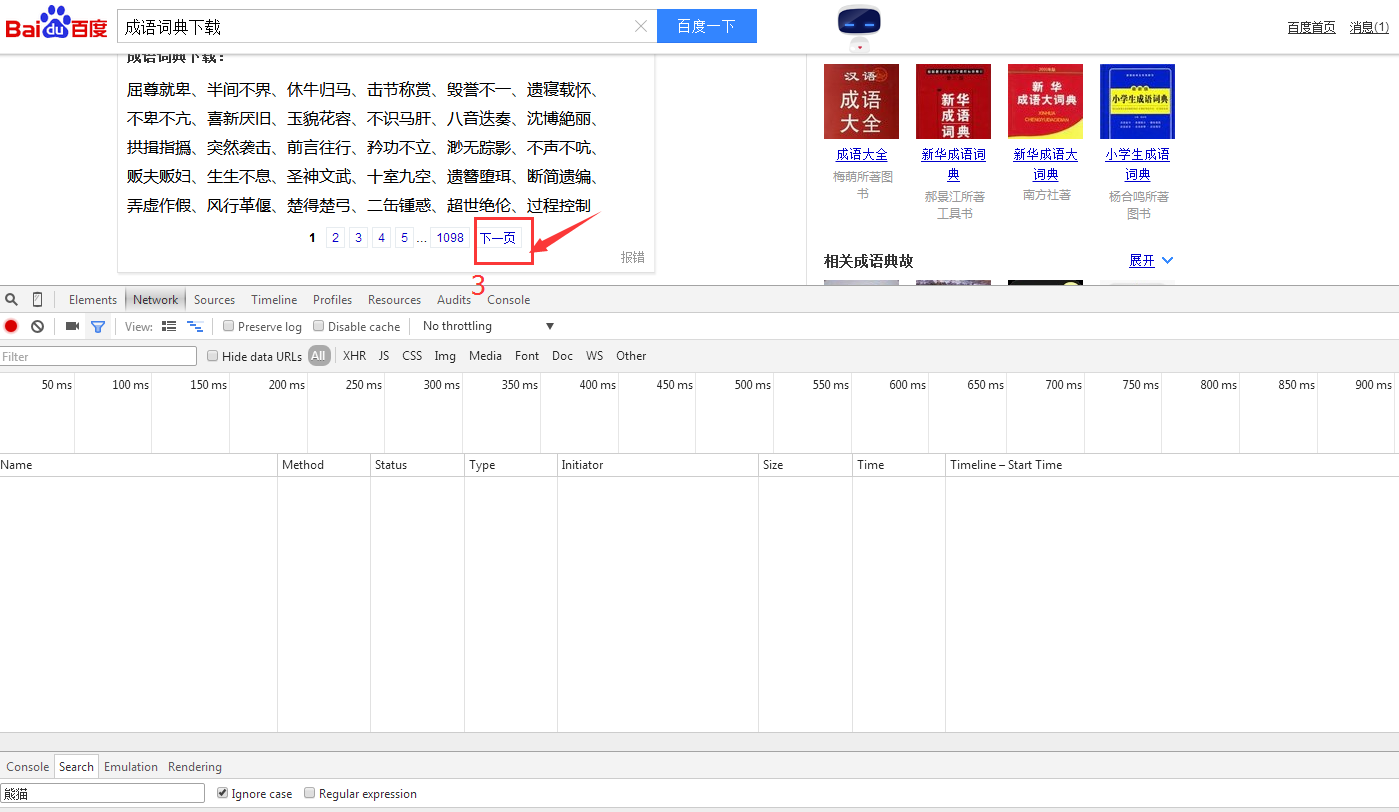
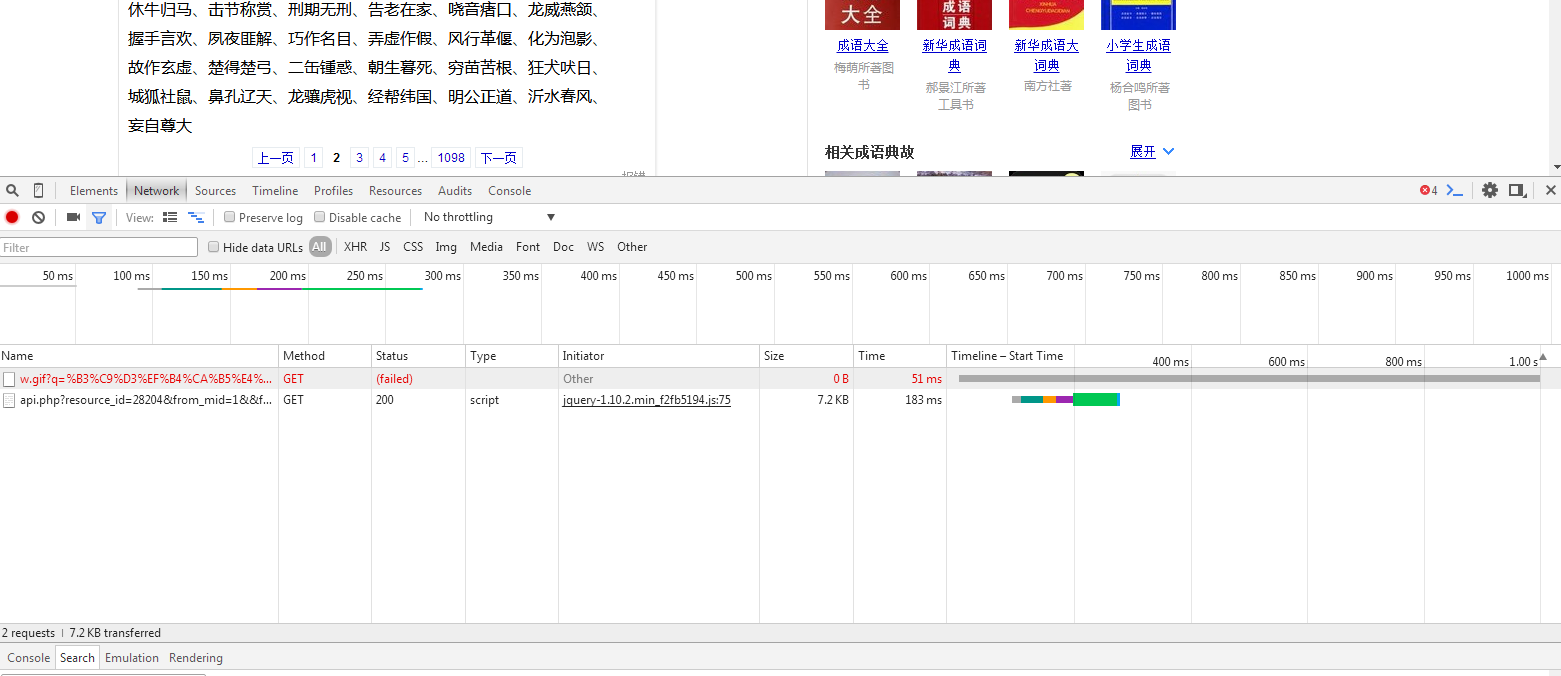
为了清楚显示我们想要的东西,我们选择js按钮
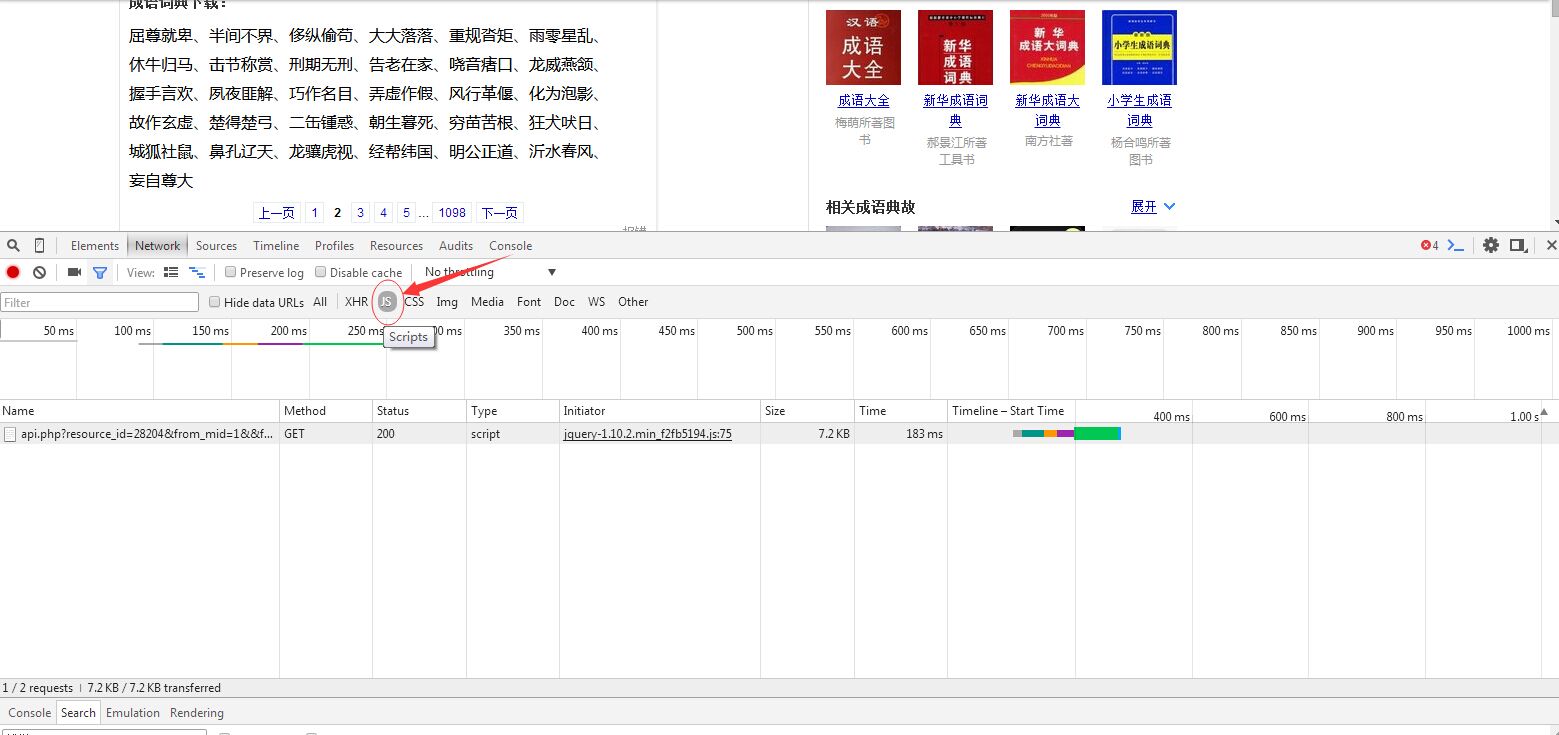
4.将鼠标放在网址那,点击右键选择open link in new tab

5.以上四部便可以得到大致是一个json格式的内容,做到这一步,算是完成了一大部分的工作,由于为了方便解析内容,需要将网站稍作修改,这一步大家需要去尝试在此我将这部分(&cb=jQuery1102011321965302340686_1450094493974)去掉后,内容变成纯的json格式文档。接下来的和爬取静态网页的方法一样了
6. 第五步可以得到这样的网址:=1450094493985”>https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=28204&from_mid=1&&format=json&ie=utf-8&oe=utf-8&query=%E6%88%90%E8%AF%AD%E8%AF%8D%E5%85%B8%E4%B8%8B%E8%BD%BD&sort_key=&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn=30&rn=30&=1450094493985,pn=30,表示每页显示30个,我们需要改变pn的值来爬取所有的成语,具体操作是pn+=30。
所有的步骤说完了,接下来上代码:
import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileNotFoundE 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









