







字典树(Trie)
数据结构简介…
💻Java中的字典树结构:

💻Python中的字典树结构:

高频面试题
1.实现 Trie (前缀树)
🚀题目链接:LeetCode208.实现 Trie (前缀树)
题目:
Trie(发音类似 “try”)或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
Trie()初始化前缀树对象。void insert(String word)向前缀树中插入字符串word。boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。示例:
输入 ["Trie", "insert", "search", "search", "startsWith", "insert", "search"] [[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]] 输出 [null, null, true, false, true, null, true] 解释 Trie trie = new Trie(); trie.insert("apple"); trie.search("apple"); // 返回 True trie.search("app"); // 返回 False trie.startsWith("app"); // 返回 True trie.insert("app"); trie.search("app"); // 返回 True
🍬C++ AC代码:
// 字典树节点定义:
class TrieNode {
public:
char val;
bool isWord = false;
TrieNode* children[26] = {nullptr};
TrieNode() {}
TrieNode(char c) {
TrieNode* node = new TrieNode();
node->val = c;
}
};
class Trie {
private:
TrieNode* root;
public:
Trie() {
root = new TrieNode();
root->val = ' ';
}
void insert(string word) {
TrieNode* ws = root;
for (int i = 0; i < word.length(); i++) {
char c = word[i];
if (ws->children[c - 'a'] == nullptr)
ws->children[c - 'a'] = new TrieNode(c);
ws = ws->children[c - 'a'];
}
ws->isWord = true;
}
bool search(string word) {
TrieNode* ws = root;
for (int i = 0; i < word.length(); i++) {
char c = word[i];
if (ws->children[c - 'a'] == nullptr)
return false;
ws = ws->children[c - 'a'];
}
return ws->isWord;
}
bool startsWith(string prefix) {
TrieNode* ws = root;
for (int i = 0; i < prefix.length(); i++) {
char c = prefix[i];
if (ws->children[c - 'a'] == nullptr)
return false;
ws = ws->children[c - 'a'];
}
return true;
}
};
☕Java AC代码:
class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
root.val = ' ';
}
public void insert(String word) {
TrieNode ws = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (ws.children[c - 'a'] == null)
ws.children[c - 'a'] = new TrieNode(c);
ws = ws.children[c - 'a'];
}
ws.isWord = true;
}
public boolean search(String word) {
TrieNode ws = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (ws.children[c - 'a'] == null)
return false;
ws = ws.children[c - 'a'];
}
return ws.isWord;
}
public boolean startsWith(String prefix) {
TrieNode ws = root;
for (int i = 0; i < prefix.length(); i++) {
char c = prefix.charAt(i);
if (ws.children[c - 'a'] == null)
return false;
ws = ws.children[c - 'a'];
}
return true;
}
}
// 字典树节点定义:
class TrieNode {
public char val;
public boolean isWord;
public TrieNode[] children = new TrieNode[26];
public TrieNode() {}
TrieNode(char c) {
TrieNode node = new TrieNode();
node.val = c;
}
}
🍦Python AC代码:
class Trie(object):
def __init__(self):
self.root = {}
self.end_of_word = "#"
def insert(self, word):
node = self.root
for char in word:
# 如果key存在则返回value,不存在则构建一个新的key-value再返回
node = node.setdefault(char, {})
node[self.end_of_word] = self.end_of_word
def search(self, word):
node = self.root
for char in word:
if char not in node:
return False
node = node[char]
return self.end_of_word in node
def startsWith(self, prefix):
node = self.root
for char in prefix:
if char not in node:
return False
node = node[char]
return True
✨Tips:
- ⭐Python中可以使用字典
dictionary来代替我们自己定义的字典树结构,key是字符char,value是一个新的字典{}或者结束字符#。
2. 单词搜索 II
🚀题目链接:LeetCode212. 单词搜索 II
题目:
给定一个m x n二维字符网格board和一个单词(字符串)列表words, 返回所有二维网格上的单词 。
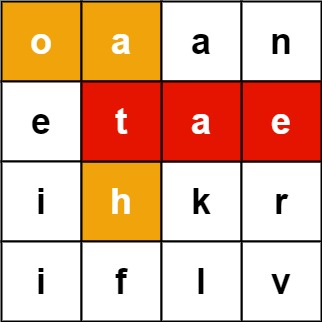
单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。示例 1:
输入: board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"] 输出:["eat","oath"]示例 2:
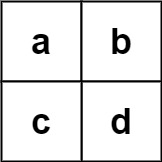
输入:board = [["a","b"],["c","d"]], words = ["abcb"] 输出:[]
🍬C++ AC代码:
// 字典树节点定义:
struct Trie {
Trie* child[26];
string word = "";
Trie() {
for (int i = 0; i < 26; i++)
child[i] = nullptr;
}
};
class Solution {
public:
// set保存结果用来去重
set<string> temp_res;
int dirs[4][2] = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
vector<string> findWords(vector<vector<char>>& board, vector<string>& words) {
vector<string> res;
Trie* trie = new Trie();
// 将单词加入字典树
for (int i = 0; i < words.size(); i++) {
Trie* cur = trie;
for (int j = 0; j < words[i].size(); j++) {
if (cur->child[words[i][j] - 'a'] == nullptr)
cur->child[words[i][j] - 'a'] = new Trie();
cur = cur->child[words[i][j] - 'a'];
}
cur->word = words[i];
}
int m = board.size(), n = board[0].size();
// 对二维网格的每一个位置进行dfs搜索
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
dfs(board, i, j, trie);
}
}
// set转换成vector返回
res.assign(temp_res.begin(), temp_res.end());
return res;
}
void dfs(vector<vector<char>>& board, int x, int y, Trie* trie) {
// 超出网格边界直接返回
if (x < 0 || x >= board.size() || y < 0 || y >= board[0].size()) return;
char c = board[x][y];
// 检查是否访问过该位置和单词是否在字典树中存在
if (c == '*' || trie->child[c-'a']==nullptr) return;
trie = trie->child[c - 'a'];
// 在字典树中存在当前dfs访问路径构成的单词
if (trie->word != "") {
temp_res.insert(trie->word);
trie->word = "";
}
// 标记该位置已经访问
board[x][y] = '*';
// 递归访问上下左右四个方向
for (int i = 0; i < 4; i++)
dfs(board, x + dirs[i][0], y + dirs[i][1], trie);
// 回溯
board[x][y] = c;
}
};
✨Tips:
- ⭐C++代码调用上面一题已经写好的字典树中的方法提交上去会超时,这里将字典树的
search()和startWith()方法写在dfs中,避免每次dfs调用这两个方法造成不必要的时间开销。 - ⭐
dfs()函数向上下左右四个方向递归访问时,我们需要判断访问的位置之前是否已经访问过了,可以使用一个额外的bool类型的二维数组visited[][]标记走过的位置,更好的办法是向上面的代码这样,直接修改board数组,将访问过的位置置为"*"。 - ⭐经过测试使用额外数组标记的方式提交会超时,而下面的Java代码使用额外数组却能通过😂~
☕Java AC代码:
class Solution {
// set用来存保存结果并去重
Set<String> res = new HashSet<>();
// 代表上下左右四个方向,dfs中会用到
int[][] dirs = new int[][]{{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
public List<String> findWords(char[][] board, String[] words) {
Trie trie = new Trie();
// 将单词加入到字典树中
for (String word : words)
trie.insert(word);
int m = board.length, n = board[0].length;
boolean[][] visited = new boolean[m][n];
// 对二维网格的每一个位置进行dfs搜索
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
dfs(board, visited, "", i, j, trie);
}
}
return new ArrayList<String>(res);
}
public void dfs(char[][] board, boolean[][] visited, String str, int x, int y, Trie trie) {
// 超出网格边界直接返回
if (x < 0 || x >= board.length || y < 0 || y >= board[0].length) return;
// 访问到了之前访问过的位置,直接返回
if (visited[x][y]) return;
str += board[x][y];
// 检查单词是否在字典树中存在
if (!trie.startsWith(str)) return;
if (trie.search(str)) res.add(str);
visited[x][y] = true;
// 递归访问上下左右四个方向
for (int i = 0; i < 4; i++)
dfs(board, visited, str, x + dirs[i][0], y + dirs[i][1], trie);
// 回溯
visited[x][y] = false;
}
}
✨Tips:
- ⭐Java代码要用到上面一题的字典树结构,这里只展示本题的核心代码,提交代码时记得复制一份字典树代码在本题后面😎。
- ⭐Java代码超时的判定比较宽松,只要用了字典树就不会超时,不做额外的优化也可以通过。
🍦Python AC代码:
# 方向数组,用来dfs访问上下左右四个位置
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
# 字典树单词结束标志
END_OF_WORD = "#"
class Solution(object):
def findWords(self, board, words):
if not board or not board[0]: return []
if not words: return []
# set保存结果同时去重
self.result = set()
# 使用python中的dict字典创建字典树
root = collections.defaultdict()
# 将单词加入字典树
for word in words:
node = root
for char in word:
node = node.setdefault(char, collections.defaultdict())
node[END_OF_WORD] = END_OF_WORD
self.m, self.n = len(board), len(board[0])
# 遍历网格中的每个位置,调用dfs搜索单词
for i in xrange(self.m):
for j in xrange(self.n):
if board[i][j] in root:
self._dfs(board, i, j, "", root)
# set转换成list返回
return list(self.result)
def _dfs(self, board, i, j, cur_word, cur_dict):
# 获取当前字母在字典树中的位置
cur_word += board[i][j]
cur_dict = cur_dict[board[i][j]]
# 当前字符是结束字符,说明找到了单词列表中的单词
if END_OF_WORD in cur_dict:
self.result.add(cur_word)
# 标记当前位置已经访问过
tmp, board[i][j] = board[i][j], '@'
# 递归访问上下左右四个位置
for k in xrange(4):
x, y = i + dx[k], j + dy[k]
# 判断访问的位置是否在网格内以及之前是否访问过
if 0 <= x < self.m and 0 <= y < self.n and board[x][y] != '@' and board[x][y] in cur_dict:
self._dfs(board, x, y, cur_word, cur_dict)
# 回溯
board[i][j] = tmp
✨Tips:
- ⭐Python的代码执行时间比较长,我们需要标记已经访问过的位置,和C++代码的方式一样,直接修改原数组
board即可,不用借助额外的标记数组,这里可以优化一下。
总结

字典树(Trie)
数据结构简介…
💻Java中的字典树结构:
💻Python中的字典树结构:
高频面试题
1.实现 Trie (前缀树)
🚀题目链接:LeetCode208.实现 Trie (前缀树)
题目:
Trie(发音类似 “try”)或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
Trie()初始化前缀树对象。void insert(String word)向前缀树中插入字符串word。boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。示例:
输入 ["Trie", "insert", "search", "search", "startsWith", "insert", "search"] [[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]] 输出 [null, null, true, false, true, null, true] 解释 Trie trie = new Trie(); trie.insert("apple"); trie.search("apple"); // 返回 True trie.search("app"); // 返回 False trie.startsWith("app"); // 返回 True trie.insert("app"); trie.search("app"); // 返回 True
🍬C++ AC代码:
// 字典树节点定义:
class TrieNode {
public:
char val;
bool isWord = false;
TrieNode* children[26] = {nullptr};
TrieNode() {}
TrieNode(char c) {
TrieNode* node = new TrieNode();
node->val = c;
}
};
class Trie {
private:
TrieNode* root;
public:
Trie() {
root = new TrieNode();
root->val = ' ';
}
void insert(string word) {
TrieNode* ws = root;
for (int i = 0; i < word.length(); i++) {
char c = word[i];
if (ws->children[c - 'a'] == nullptr)
ws->children[c - 'a'] = new TrieNode(c);
ws = ws->children[c - 'a'];
}
ws->isWord = true;
}
bool search(string word) {
TrieNode* ws = root;
for (int i = 0; i < word.length(); i++) {
char c = word[i];
if (ws->children[c - 'a'] == nullptr)
return false;
ws = ws->children[c - 'a'];
}
return ws->isWord;
}
bool startsWith(string prefix) {
TrieNode* ws = root;
for (int i = 0; i < prefix.length(); i++) {
char c = prefix[i];
if (ws->children[c - 'a'] == nullptr)
return false;
ws = ws->children[c - 'a'];
}
return true;
}
};
☕Java AC代码:
class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
root.val = ' ';
}
public void insert(String word) {
TrieNode ws = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (ws.children[c - 'a'] == null)
ws.children[c - 'a'] = new TrieNode(c);
ws = ws.children[c - 'a'];
}
ws.isWord = true;
}
public boolean search(String word) {
TrieNode ws = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (ws.children[c - 'a'] == null)
return false;
ws = ws.children[c - 'a'];
}
return ws.isWord;
}
public boolean startsWith(String prefix) {
TrieNode ws = root;
for (int i = 0; i < prefix.length(); i++) {
char c = prefix.charAt(i);
if (ws.children[c - 'a'] == null)
return false;
ws = ws.children[c - 'a'];
}
return true;
}
}
// 字典树节点定义:
class TrieNode {
public char val;
public boolean isWord;
public TrieNode[] children = new TrieNode[26];
public TrieNode() {}
TrieNode(char c) {
TrieNode node = new TrieNode();
node.val = c;
}
}
🍦Python AC代码:
class Trie(object):
def __init__(self):
self.root = {}
self.end_of_word = "#"
def insert(self, word):
node = self.root
for char in word:
# 如果key存在则返回value,不存在则构建一个新的key-value再返回
node = node.setdefault(char, {})
node[self.end_of_word] = self.end_of_word
def search(self, word):
node = self.root
for char in word:
if char not in node:
return False
node = node[char]
return self.end_of_word in node
def startsWith(self, prefix):
node = self.root
for char in prefix:
if char not in node:
return False
node = node[char]
return True
✨Tips:
- ⭐Python中可以使用字典
dictionary来代替我们自己定义的字典树结构,key是字符char,value是一个新的字典{}或者结束字符#。
2. 单词搜索 II
🚀题目链接:LeetCode212. 单词搜索 II
题目:
给定一个m x n二维字符网格board和一个单词(字符串)列表words, 返回所有二维网格上的单词 。
单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。示例 1:
输入: board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"] 输出:["eat","oath"]示例 2:
输入:board = [["a","b"],["c","d"]], words = ["abcb"] 输出:[]
🍬C++ AC代码:
// 字典树节点定义:
struct Trie {
Trie* child[26];
string word = "";
Trie() {
for (int i = 0; i < 26; i++)
child[i] = nullptr;
}
};
class Solution {
public:
// set保存结果用来去重
set<string> temp_res;
int dirs[4][2] = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
vector<string> findWords(vector<vector<char>>& board, vector<string>& words) {
vector<string> res;
Trie* trie = new Trie();
// 将单词加入字典树
for (int i = 0; i < words.size(); i++) {
Trie* cur = trie;
for (int j = 0; j < words[i].size(); j++) {
if (cur->child[words[i][j] - 'a'] == nullptr)
cur->child[words[i][j] - 'a'] = new Trie();
cur = cur->child[words[i][j] - 'a'];
}
cur->word = words[i];
}
int m = board.size(), n = board[0].size();
// 对二维网格的每一个位置进行dfs搜索
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
dfs(board, i, j, trie);
}
}
// set转换成vector返回
res.assign(temp_res.begin(), temp_res.end());
return res;
}
void dfs(vector<vector<char>>& board, int x, int y, Trie* trie) {
// 超出网格边界直接返回
if (x < 0 || x >= board.size() || y < 0 || y >= board[0].size()) return;
char c = board[x][y];
// 检查是否访问过该位置和单词是否在字典树中存在
if (c == '*' || trie->child[c-'a']==nullptr) return;
trie = trie->child[c - 'a'];
// 在字典树中存在当前dfs访问路径构成的单词
if (trie->word != "") {
temp_res.insert(trie->word);
trie->word = "";
}
// 标记该位置已经访问
board[x][y] = '*';
// 递归访问上下左右四个方向
for (int i = 0; i < 4; i++)
dfs(board, x + dirs[i][0], y + dirs[i][1], trie);
// 回溯
board[x][y] = c;
}
};
✨Tips:
- ⭐C++代码调用上面一题已经写好的字典树中的方法提交上去会超时,这里将字典树的
search()和startWith()方法写在dfs中,避免每次dfs调用这两个方法造成不必要的时间开销。 - ⭐
dfs()函数向上下左右四个方向递归访问时,我们需要判断访问的位置之前是否已经访问过了,可以使用一个额外的bool类型的二维数组visited[][]标记走过的位置,更好的办法是向上面的代码这样,直接修改board数组,将访问过的位置置为"*"。 - ⭐经过测试使用额外数组标记的方式提交会超时,而下面的Java代码使用额外数组却能通过😂~
☕Java AC代码:
class Solution {
// set用来存保存结果并去重
Set<String> res = new HashSet<>();
// 代表上下左右四个方向,dfs中会用到
int[][] dirs = new int[][]{{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
public List<String> findWords(char[][] board, String[] words) {
Trie trie = new Trie();
// 将单词加入到字典树中
for (String word : words)
trie.insert(word);
int m = board.length, n = board[0].length;
boolean[][] visited = new boolean[m][n];
// 对二维网格的每一个位置进行dfs搜索
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
dfs(board, visited, "", i, j, trie);
}
}
return new ArrayList<String>(res);
}
public void dfs(char[][] board, boolean[][] visited, String str, int x, int y, Trie trie) {
// 超出网格边界直接返回
if (x < 0 || x >= board.length || y < 0 || y >= board[0].length) return;
// 访问到了之前访问过的位置,直接返回
if (visited[x][y]) return;
str += board[x][y];
// 检查单词是否在字典树中存在
if (!trie.startsWith(str)) return;
if (trie.search(str)) res.add(str);
visited[x][y] = true;
// 递归访问上下左右四个方向
for (int i = 0; i < 4; i++)
dfs(board, visited, str, x + dirs[i][0], y + dirs[i][1], trie);
// 回溯
visited[x][y] = false;
}
}
✨Tips:
- ⭐Java代码要用到上面一题的字典树结构,这里只展示本题的核心代码,提交代码时记得复制一份字典树代码在本题后面😎。
- ⭐Java代码超时的判定比较宽松,只要用了字典树就不会超时,不做额外的优化也可以通过。
🍦Python AC代码:
# 方向数组,用来dfs访问上下左右四个位置
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
# 字典树单词结束标志
END_OF_WORD = "#"
class Solution(object):
def findWords(self, board, words):
if not board or not board[0]: return []
if not words: return []
# set保存结果同时去重
self.result = set()
# 使用python中的dict字典创建字典树
root = collections.defaultdict()
# 将单词加入字典树
for word in words:
node = root
for char in word:
node = node.setdefault(char, collections.defaultdict())
node[END_OF_WORD] = END_OF_WORD
self.m, self.n = len(board), len(board[0])
# 遍历网格中的每个位置,调用dfs搜索单词
for i in xrange(self.m):
for j in xrange(self.n):
if board[i][j] in root:
self._dfs(board, i, j, "", root)
# set转换成list返回
return list(self.result)
def _dfs(self, board, i, j, cur_word, cur_dict):
# 获取当前字母在字典树中的位置
cur_word += board[i][j]
cur_dict = cur_dict[board[i][j]]
# 当前字符是结束字符,说明找到了单词列表中的单词
if END_OF_WORD in cur_dict:
self.result.add(cur_word)
# 标记当前位置已经访问过
tmp, board[i][j] = board[i][j], '@'
# 递归访问上下左右四个位置
for k in xrange(4):
x, y = i + dx[k], j + dy[k]
# 判断访问的位置是否在网格内以及之前是否访问过
if 0 <= x < self.m and 0 <= y < self.n and board[x][y] != '@' and board[x][y] in cur_dict:
self._dfs(board, x, y, cur_word, cur_dict)
# 回溯
board[i][j] = tmp
✨Tips:
- ⭐Python的代码执行时间比较长,我们需要标记已经访问过的位置,和C++代码的方式一样,直接修改原数组
board即可,不用借助额外的标记数组,这里可以优化一下。
总结















 131
131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









