







当前计算机工程方向已经进入云原生时代,容器和容器编排(K8s)成为计算机工程方向热门技术,之前文章“容器技术之发展简史"梳理了容器和云原生的关系,我们得出容器技术恒等式:

我们今天先聊执行引擎,后续将有一篇关于容器镜像的专题文章具体聊镜像格式和镜像加速。
从集装箱革命说起

容器技术需要解决的核心问题之一运行时的环境隔离。
有一本非常有名的书,叫《集装箱改变世界》,说的是看起来平淡无奇的铁箱子,如何从二十世纪起永久性的改变了这个世界,并促进了全球化和全球分工。集装箱的出现和发展是实体货物包装、运输、交付方式的一次革命。

《经济学家》杂志曾经评价说“没有集装箱,不可能有全球化”。集装箱为什么具有革命性?经济全球化的基础就是现代运输体系,而一个高度自动化、低成本和低复杂性的货物运输系统的核心就是集装箱。集装箱最大的成功在于其产品的标准化及由此建立的一整套运输体系。能够让一个载重几十吨的庞然大物实现标准化,并且以此为基础逐步实现全球范围内的船舶、港口、航线、公路、中转站、桥梁、隧道、多试联运相配套的物流系统,这的确堪称人类有史以来创造的伟大奇迹之一,而撬动这个系统的理念就是标准化和系统化。
改变世界的不仅仅是集装箱本身,还有一整套货物处理的新方法,包括港口、货船、起重机、卡车,还有发货人的自身操作方式等。容器技术对于IT领域的意义非常类似于集装箱,只是里面装载的不再是实体货物,而是虚拟世界的二进制代码和软件。
制作集装箱可以采用不同的材料与工艺流程,只需要符合相应的标准。同理,容器技术也有不同架构和实现,只要遵循相应的技术规范,就是合格的容器技术。在具体介绍容器执行引擎方案及技术路线之前,先上一张容器引擎技术江湖门派概览图,以飨读者。
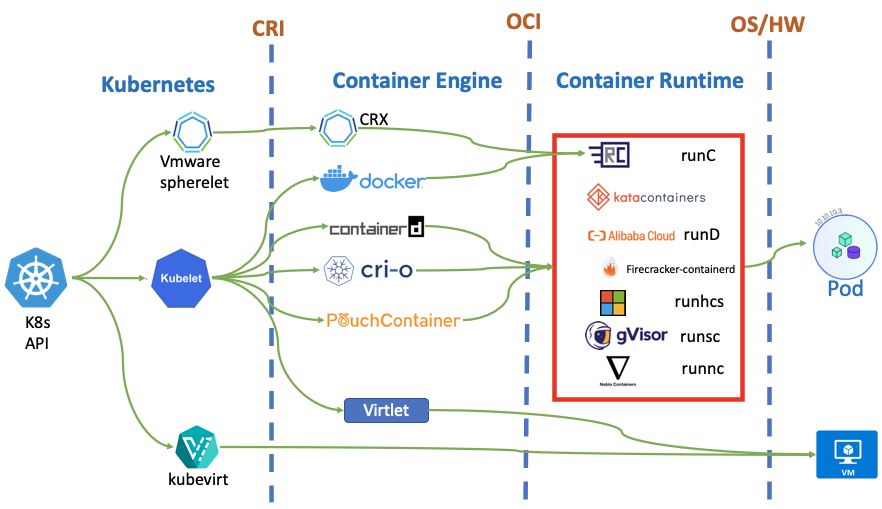
提到容器引擎(Container Engine)、容器运行时(Container Runtime)这些名称,总是有点容易让人犯晕。为了让事情简化一些,我们关注在云原生、K8S场景下的定义吧。从CNCF Cloud Native Interactive Landscape可以发现,容器引擎领域是一个很活跃的技术领域,该领域的大致发展(战争)史如右下图。

相对较为正式的术语定义如下图,可以把容器管理系统分为三层:
High-level Container Management:容器管控的UI层。直接实现容器的管控和使用界面,也是用户最熟悉的子系统。
High-level Container Runtime:容器状态及资源供给。包括镜像管理、网络接入、容器状态、调用Low Level Runtime执行容器等功能。习惯上这层称之为容器引擎(Container Engine)。
Low-level Container Runtime:容器执行层。负责具体构建容器运行环境并执行容器进程。习惯上这层直接简称为容器运行时(Container Runtime)。
High-level Container Management和Container Engine之间的接口规范是CRI,Container Engine和Container Runtime之间的接口规范是OCI。

下文将分别从容器引擎(High-level container runtime)和容器运行时(Low-level container runtime)两个纬度讨论容器执行引擎相关技术。
容器引擎

容器引擎的核心是准备运行容器所需要的资源以及管理容器生命周期。在K8S生态圈中,容器编排系统通过CRI接口来调用容器引擎。支持CRI接口的容器引擎主要有docker、rkt、pouch、containerd和cri-o等,其中活跃度比较高的是containerd和CRI-O。
containerd
Containerd是从dockerd中抽离出来的容器管理的核心功能,是在社区影响下dockerd模块化的结果,也是现在最热门的容器引擎。由于containerd是从dockerd演化出来的,使用接口是针对容器管理而设计,内置管理对象是Image和Container。K8S CRI的管控对象是Image/Pod/Container,为了让containerd支持Pod对象以及实现CRI接口,引入了CRI-containerd组件来粘合Kubelet和containerd两个子系统。现在cri-containerd组件已经作为一个功能模块内置到containerd。Containerd依赖后端container runtime来具体管理容器,最常见的container runtime是runC。

CRI-O
而CRI-O则是专门支持K8S CRI接口而设计实现的容器引擎,它抛弃了对docker的支持而专注于支持K8S CRI,所以架构相对containerd要简洁不少。但是,虽然架构简洁优雅,但是从实际使用体验看CRI-O在成熟度、可扩展性方面相对cantainerd还是有一定差距。今年CRI-O也增加了对shimv2接口的支持,从而可以支持runC之外其它容器运行时,但是实际测试发现功能还不成熟。
进一步看CRI-O的架构,一个CRI实现需要实现的核心功能包括:镜像管理(Image service)、运行管理(runtime service,管理Pod、container生命周期)、容器网络(CNI)和对接OCI兼容的容器运行时。这儿有一个非常重要的细节,虽然cri-containerd和CRI-O都是同时实现CRI的image service和runtime service,但是CRI规范其实允许用不同的组件来分别实现image service和runtime service。

容器运行时

runC是目前使用最广泛的容器运行时,但是runC也不是完美的。业界对runC的担心主要集中在runC的隔离能力,众所周知runC容器共享一个host内核,利用cgroup和namespace机制来构建相互隔离的容器执行环境。Docker、LXC、RKT和runC这类原生容器都是基于共享主机操作系统的,这些技术的优点是资源利用率高、弹性能力强,缺点则是受攻击面大和攻击后果严重。特别是在多租户的云环境中,不同客户的容器会被编排部署到同一个服务器系统,这种威胁就变得尤其明显了。
其实,容器引擎技术领域也存在类似CAP理论的三边关系:资源效率、安全隔离和标准通用。目前所有的容器运行时技术最多都只能满足资源效率、安全隔离和标准通用中的两项,还没有一个技术能做到同时满足三项。比如:runC在资源效率和标准通用方面最强,但是在安全隔离方面却最弱。Kata containers/firecracker-containerd/runD在安全隔离和标准通用上有优势,但是在资源效率方面却有不足。

基于共享内核的OS虚拟化技术总是让人不放心,“安全容器”便应运而生了。安全容器的核心思路是摒弃共享内核,为每个Pod/Container实例配置一个专用的容器OS,再辅以硬件虚拟化、应用内核等技术以获得更好的隔离性。我们可以按是否使用共享内核、是否使用硬件虚拟化、是否使用Linux Kernel作为容器内核几个纬度来对容器运行时进行分类。从下面的分类表可以看出,基于硬件虚拟化+Linux分离内核是目前行业的主流技术路线。
内核形态 | 隔离机制 | 应用内核类型 | 容器运行时 |
共享内核 | Cgroup/namespace | Linux | 基于runC的原生容器 |
Windows | Windows Server Containers | ||
独享内核 | 硬件虚拟化 | Linux | Kata containers,Alibaba Cloud Sandbox - runD,firecracker-containerd,Project Pacific CRX |
Windows | Hyper-V containers | ||
Sentry | gvisor | ||
libOS | NetBSD | Nabla containers | |
Linux | Nabla containers |
runC
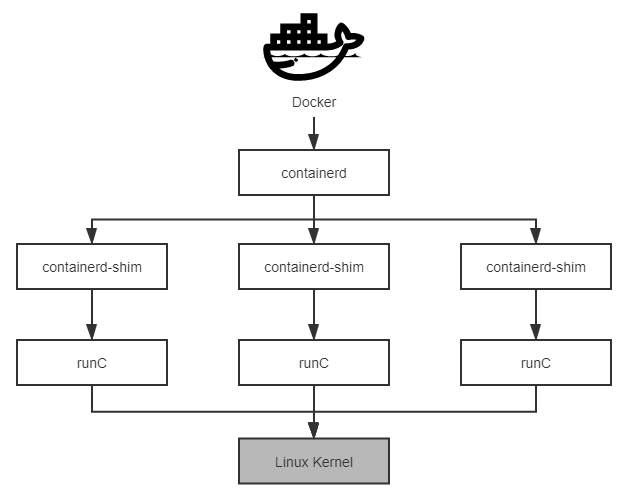
为了符合 OCI 标准,Docker 推动自身的架构继续向前演进,首先将 libcontainer 独立出来,封装重构成runC 项目,并捐献给了 Linux 基金会管理。runC 是 OCI Runtime 的首个参考实现,提出了“让标准容器无所不在”(Make Standard Containers Available Everywhere)的口号。为了能够兼容所有符合标准的 OCI Runtime 实现,Docker 进一步重构了 Docker Daemon 子系统,将其中与运行时交互的部分抽象为containerd 项目,这是一个负责管理容器执行、分发、监控、网络、构建、日志等功能的核心模块,内部会为每个容器运行时创建一个 containerd-shim 适配进程,默认与 runC 搭配工作,但也可以切换到其他 OCI Runtime 实现上(然而实际并没做到,最后 containerd 仍是紧密绑定于 runC)。2016 年,Docker 把 containerd 捐献给了 CNCF 管理,runC 与 containerd 两个项目的捐赠托管,即带有 Docker 对开源信念的追求,也带有 Docker 在众多云计算大厂夹击下自救的无奈。
Kata Containers
出于对传统容器安全性的担忧,Intel 在 2015 年启动了它们以虚拟机为基础的容器技术:Clear Container。Clear Container 依赖 Intel VT 的硬件虚拟化技术以及高度定制的 QEMU-KVM(qemu-lite)来提供高性能的基于虚拟机的容器。在 2017 年,Clear container 项目加入了 Hyper RunV,这是一个基于 hypervisor 的 OCI 运行时,从而启动了 Kata 容器项目(https://clearlinux.org/news-blogs/kata-containers-next-evolution-clear-containers?spm=ata.13261165.0.0.217a57c62rMc0r)。Kata containers的核心思路是:
操作系统本身的容器机制没办法解决安全性问题,需要一个隔离层;
虚拟机是一个现成的隔离层,云服务已经让全世界相信,对户来说,"*secure of VM*" 是可以满足需求的;
虚机里面只要有个内核,就可以支持 OCI 规范的语义,在内核上跑个 Linux 应用这并不太难实现;
虚机可能不够快,阻碍了它在容器环境的应用,那么可不可以拥有 "speed of container" 呢?
所以,Kata containers核心之一是把VM变得轻快稳,使之能满足容器高密弹性的需求。同时,作为一个容器运行时,必须深度融入生态,支持相关规范。

Kata containers 最大的特点是它专注于实现一个开放的符合OCI标准的安全容器runtime实现,对于对接什么样的虚拟化方案,它抽象了一套hypervisor接口,如今已经对接了多种虚拟化实现,比如qemu、nemu、firecracker、cloud-hypervisor等。
2019年,Kata containers有个非常重要的技术进步,和containerd社区共同制定了shimv2接口规范,并率先在Kata containers支持了该规范。通过containerd-shim-v2和vsock技术,kata精简了大量的组件,配合轻量级hypervisor和精简内核,kata可以大幅降低内存开销和容器启动时间。更关键的是,降低系统部署复杂度还大幅提高了稳定性,特别是在系统重载情况下的稳定性。从实际使用体感看,阿里云沙箱容器1.0从shimv1升级到shimv2后,稳定性得到大幅提升,缺陷数量大幅下降。一个技术,同时服务于“轻”、“快”、“稳”三个目标,当之无愧重要的技术进步!

第二个热点则是Kata containers 2.0架构。从2019年8月开始,阿里云、蚂蚁和intel三方共同推动Kata containers 2.0架构定义及设计,核心是进一步提升多租隔离能力及可观测性。现在蚂蚁可信原生团队、阿里云容器团队和阿里云操作系统团队三方正在合力推进Kata containers 2.0架构。
回头再聊聊Kata Containers和runC的关系吧!Kata Containers和runC不是替代与被替代,而是青出于蓝而胜于蓝。Kata Containers把runC一层基于OS虚拟化的隔离机制扩展为三层隔离:Guest OS 虚拟化(等效于runC),硬件虚拟化和Host OS虚拟化。所以Kata Containers通过引入更多的间接层来提升系统的隔离能力,但是需要付出“更多间接层”的代价。

Firecracker-containerd
Firecracker-containerd是firecracker和containerd的合体。Firecracker是AWS基于Google crosvm开发的、配合KVM使用的一个轻量级安全VMM,用以支持和实现MicroVM。Firecracker MicroVM 同时具备传统虚拟机的安全性和工作负载隔离能力以及容器的速度和资源利用率。Firecracker具有如下一些特色:
抛弃 QEMU 使用的 C 语言,选择内存安全的 Rust 作为开发语言。
基于 crosvm 使用极简设备模型,模拟尽可能少的必要设备,减小暴露的攻击面。
高性能和低开销:得益于极简的设备模型, Firecracker 取消了 SeaBIOS (开源的 X86 BIOS),移除了 PCI 总线,取消了 VGA 显示等等硬件模拟,严格的说它甚至不是一台完整的虚拟计算机。而 Firecracker 运行的 GuestOS 使用的也是 AWS 定制过的精简 Linux 内核,同样裁剪掉了对应的设备驱动程序、子系统等等。因此叫它 MicroVM,其启动步骤和加载项要远远少于传统虚拟机。因此 Firecracker 目前已经能提供小于125ms 的 MircroVM 启动速度,每秒150台的启动能力,小于5MiB 的内存开销,并发运行4000台的极限承载容量(AWS i3.metal EC2 作为宿主机),以及热升级能力等。这些都是传统虚拟机所遥不可及,但现代化弹性工作负载又有强烈需求的性能指标。
但是,Firecracker毕竟只是一个VMM,还必须配合上containerd才能支持容器生态。所以,AWS又开源了firecracker-containerd项目,用于对接K8S生态。本质上Firecracker-containerd是另外一个私有化、定制化的Kata containers,整体架构和Kata containers类似,只是放弃了一些兼容性换取更简化的实现。

gVisor
Google gVisor 是 GCP App Engine、Cloud Functions Cloud Run和 CloudML 中使用的沙箱技术,正式商用名称是Google Sandbox。Google 意识到在公有云基础设施中运行不受信容器的风险,以及虚拟机沙箱的低效,因此开发了用户空间的内核作为沙箱来运行不受信应用。gVisor是沿着libdune的系统调用拦截思路发展而来的用户态内核或进程虚拟化技术。gVisor 通过拦截所有从应用到主机内核的系统调用,并使用用户空间中 gVisor 的内核实现来处理这些调用。

本质上来说,gVisor 是 VMM 和客户内核的组合,或者说gVisor是syscall虚拟化。基于lock-in-pop理论,假设Linux内核被高频访问的syscall是安全的,这部分可以开放给容器进程直接使用而不会导致严重的安全风险;对于冷僻Linux syscall则需单独处理,要不就是sentry模拟实现,要不就是在一个专用受限环境中执行(gofer)。sentry实现了多数的 Linux 系统调用,尤其是内核功能,例如信号分发、内存管理、网络栈以及线程模型。gVisor 和 Nabla 有很相似的策略:保护主机。它们都使用了不到 10%的系统调用来和主机内核通信。gVisor 创建通用内核,而 Nabla 依赖的是 Unikernel,它们都是在用户空间运行特定的客户内核来支持沙箱应用的运行。
gVisor 还在婴儿期,也一样有一些限制。gVisor 要拦截和处理沙箱应用中的系统调用,总要有一定开销,因此不适合系统调用繁重的应用。gVisor 没有直接的硬件访问(透传),所以如果应用需要硬件(例如 GPU)访问,就无法在 gVisor 上运行。最后,gVisor 没有实现所有的系统调用,因此使用了未实现系统调用的应用是无法在 gVisor 上运行的。
出于对使用C语言开发系统软件导致的安全风险和软件缺陷的担忧,Google开创了使用安全语言开发系统软件的先河。2013年开发的gVisor选择了Golang,2017年开源的crosvm则使用Rust。从目前状态看,Rust更适合开发底层系统软件,Golang则更适合开发上层便应用管理的系统软件。也许Rust早成熟几年gVisor就会有不同的选择啦!
Nabla Containers
Nabla Containers的核心思想是用libOS作为容器运行时的隔离机制。通过增加一个隔离层,libOS kernel,把容器应用和host OS给隔离开来。nabla是继承于unikernel的隔离方式,应用采用rumprun打包成一个unikernel镜像,直接运行在一个专为运行unikernel定制虚拟机(ukvm)中。应用直接打包首先可以降低很多内核态和用户态转换的开销,另外通过ukvm暴露非常有限的主机上的syscall(只剩7个),可以大大缩小主机的攻击面。它是这些安全容器实现中,最安全的。

这条技术路径从学术理论角度看是很好的路线,但是libOS一二十年发展不起来是有原因的。它要求应用打包成unikernel镜像,因此和当前docker的镜像标准是不兼容的。另外,unikernel应用在诸如支持创建子进程等一些常规操作上都有很难解决的问题。核心原因是应用侵入性没法解决,需要修改应用来适配容器运行时,和K8S部分语义也是冲突。
最近Nabla containers项目发生了一个有意思的转变,从采用rumpkernel切换到user model linux。估计背后的原因是rumpkernel已经有6年没有更新了,背后的NetBSD活跃度也不高,Linux compatibility layer的质量有限。但是,即使切换到UML解决部分syscall ABI兼容兼容问题,这条路前途也很渺茫。
我的观点是用libOS做容器运行时是条死路,我们在这个上面有血的教训!2018年5月加入阿里云就开始unikernel,基本思路和软件架构和Nabla基本一摸一样,rumpkernel + miniOS + ukvm + OCI接口实现。搞了四五个月之后rumpkernel + miniOS + ukvm的核心架构基本ready,但是当我们计划支持OCI时,发现模拟Linux namespace、支持多进程难度太大,如果一步一步做下去最后就会做成另外一个简化版的KVM + linux实现。进一步评估发现解决OS ABI兼容或应用改造的代价都很大,所以这条技术路线不具有广泛落地生产的可能性。所以,当IBM宣布Nabla Containers项目时,我们已经基本放弃这条路线了。
Windows容器
受Windows操作系统的限制导致Windows容器天然有臃肿及生态的问题,所以Windows容器一直相对比较小众。但是从软件架构上看,Windows容器架构反而是一个非常优秀的案例,值得探讨一番。Windows 2016开始支持Windows Containers,具有两种形态:Windows Server Containers和Hyper-v Containers,其具体架构如下图。

直观的理解,Windows Server Container相当于runC,而Hypver-V Containers则相当于Kata Containers。也就是从诞生的一天开始,Windows就提供了两种不同的Container Runtime,以提供不同的特性来满足不同场景的需求。

具体到Windows Server Containers的架构细节,基本上和Linux容器技术类似,没有太多的惊喜。内核支持容器技术的关键子系统名称都是一致的:Control Groups、Namespaces、Layer Capabilities。比较特殊的是Windows内核子系统Host Compute Service实现了containerd + runc的能力,也就是说Windows内核内置支持容器对象。

为了更好地与K8S生态融合,Windows 2019在docker之外增加了对Containerd/CRI的支持,以及相关组件runhcs(run Host Computer Service,对应Linux runC)。Windows 容器技术整体架构升级为下图的架构。至此,Windows容器通过支持OCI规范基本无缝融入了K8S生态。

Windows容器技术架构中有两个很有意思的组件。一是Host Compute Service(hcs),这个是专门为容器服务的service。相对Linux直接暴露支撑容器的底层技术(cgroup,namespace,seccomp等),Windows选择了对底层基础技术进行一层封装由内核直接容器暴露容器兑现而不暴露底层技术。阿里云操作系统团队内部也进行过类似的技术探讨,Linux kernel是否应该内置支持container object,目前还没结论。二是轻量化的Hyper-V虚拟机,Microsoft基于轻量化的Hyper-V虚拟机长出了Hyper-V container,Windows Subsystem for Linux 2和Windows Sandbox三个技术。最近Redhat基于rust-vmm搞的runK类似Windows Sandbox的思路,值得关注。
VMware Project Pacific
相对其它家的技术路线,VMware Project Pacific走了一条与众不同的路线来融入K8S生态。Project Pacific没有采用常规路线实现一个runP之类的容器运行时,而是选择了全链路技术改造。Project Pacific通过spherelet、CRX等组件完全重构kubelet、containerd、runc等组件,直接对接到K8S API server。从下图的架构可以看出,Project Pacific核心是在节点上实现容器和虚拟机的混合部署,同时支持虚拟机管理系统vCenter和容器编排系统K8S。

进一步展开Project Pacific节点级的架构细节。为了支持K8S容器生态,ESXi节点上增加了Spherelet、Image Service、Spherelet Agent等组件。ESXi上同时部署了hostd(相当于pync + libvirt)和Spherelet(相当于Kubelet)两种管控系统以支持容器虚拟机混合部署,同时还为容器专门部署了Image Service用以管理容器镜像。
VMware Project Pacific和ECI使用场景和部署形态有很多共通之处,部分设计理念值得借鉴。

Alibaba Cloud Sandbox - runD
敬请期待下回分解!
小结

结尾一张图,功法全靠悟!

欢迎大家加入极客星球圈子:
全网独家最专业的技术学习提升圈子:
修炼基本功:直播分享多年工作经验和基础技术深度理解(深入理解系列,基础概念的深入理解等等);
扩展视野:真正的分享海内外技术发展,大厂技术内幕,业界解决方案;
找工作系列:面试问题,简历修改,问题答疑,各类大厂(芯片,自动驾驶,嵌入式,互联网等)制定学习路线和指导;
职场普升:可以分享各种不同公司宝贵的职场工作经验, 项目经验,做事经验,普升经验,少走弯路;
专属VIP群:问题答疑,任何技术问题,任何疑难杂症,都可以咨询,讨论,交流!


扫码进入!
还有更多的精彩分享:
深入理解计算机系统
深入理解操作系统(调度,内存,网络,IO)
深入理解并发技术全景指南
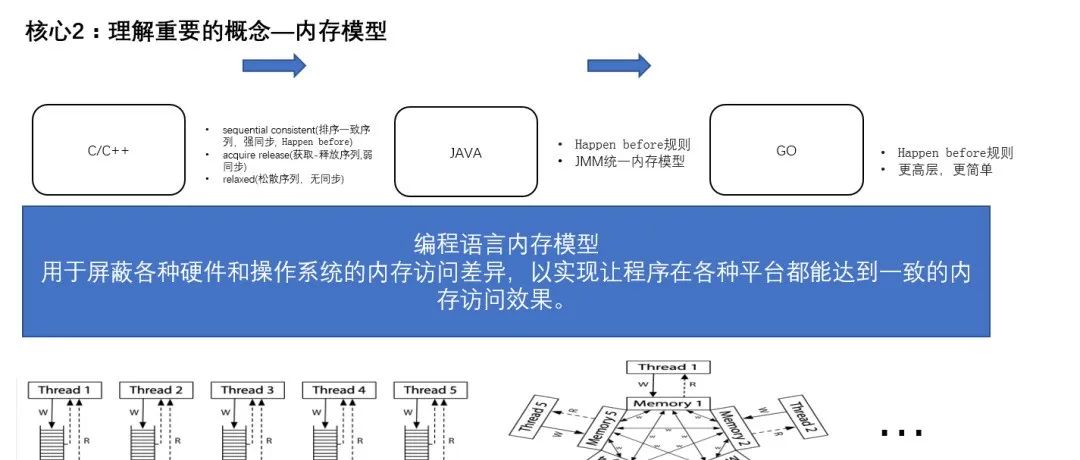
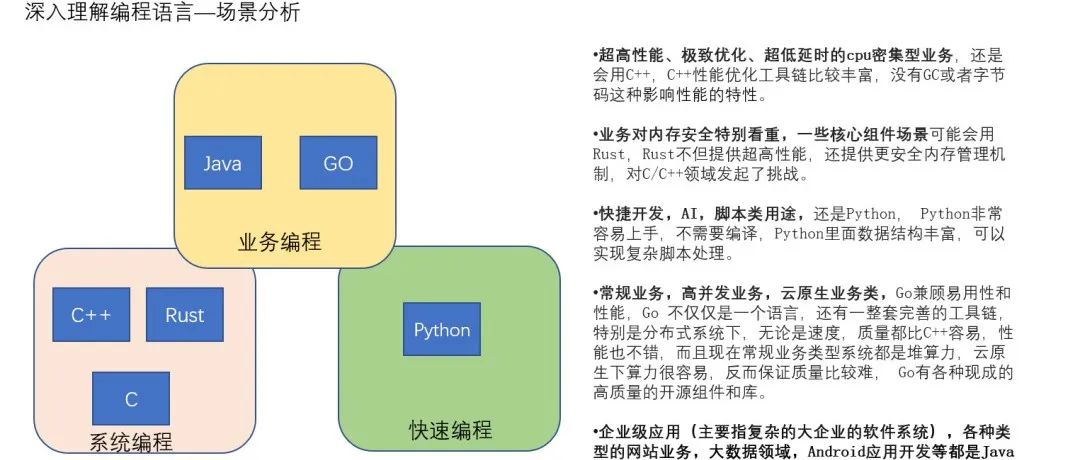
深入理解编程语言
深入理解算法与数据结构
深入理解网络协议
深入理解网络编程
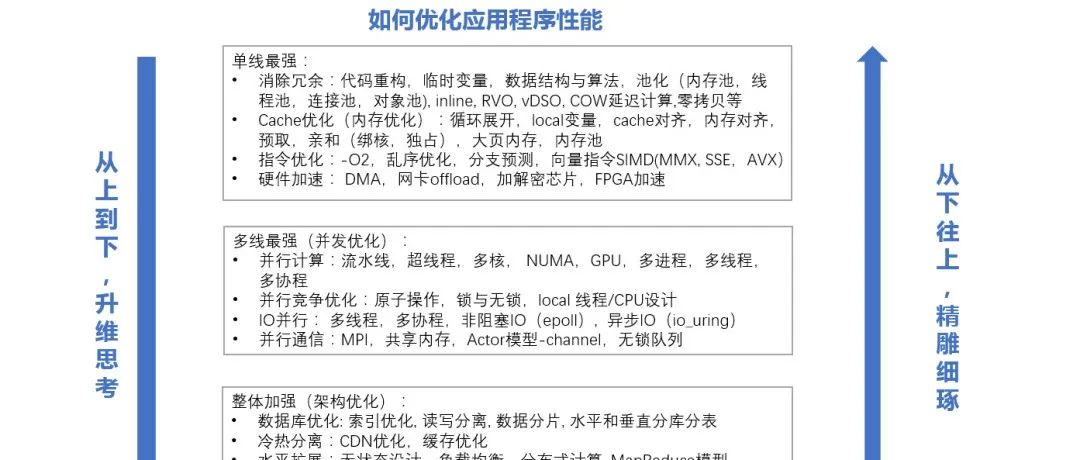
深入理解性能优化
深入理解分布式技术
深入理解数据库
深入理解代码设计
深入理解系统架构设计
...



感谢一键三连在看,转发,点赞















 5975
5975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









