







快速排序是目前平均性能最好的排序算法(从通用层面上考虑),其平均时间复杂度为O(nlogn).快速排序的思想很简单,首先将待排序的序列以某个元素为轴划分为两组,轴的左边元素不大于轴,右边的元素不小于轴,接下来分别对轴左边的元素(左子序列)和右边的元素(右子序列)进行同样的划分(每个子序列均不包含作为轴的元素,因为此时它已经处在了正确的位置上),这个过程不断重复下去,知道子序列元素个数为1时,那么排序就完成了。由此观之,快速排序算法就是不断对序列划分的过程,快排算法的框架如下:
void qsort(int array[],int start,int end)
{
if(start < end)
{
int pivot_index = partition(array,start,end);
qsort(array,start,pivot_index - 1);
qsort(array,pivot_index + 1,end);
}
}划分(partition)的方法有很多种,其中比较简单的一种方法是先选择第一个元素作为枢纽元素,然后同时从待排序列的两端向中间扫描,当从尾端向头端扫描时,如果元素大于或等于枢纽元素,则不必对序列做任何操作,因为这些元素都是在正确位置上的,如果发现某个元素小于枢纽元素,那么就将枢纽元素与该元素交换,然后停止扫描,保存扫描器的位置;当从头端向尾端扫描时,如果元素小于或等于枢纽元素,那么也不必对序列做任何操作,因为这些元素也是在正确位置上的,如果发现某个元素大于枢纽元素,则将枢纽元素与该元素的交换,停止扫描,保存扫描器的位置。接下来检查两个扫描器的位置,如果扫描器相交,则说明扫描完成;否则,从扫描器现在位置开始,重复上述扫描过程。扫描完成后,则一次划分也就完成了。程序代码如下:
int partition(int array[],int start,int end)
{
int pivot = array[start];
while(start < end){
//start < end保证了start不会和end交叉,否则
//后面的元素交换并不总是正确的
while(start < end && array[end] >= pivot) --end;
int temp = array[start];
array[start] = array[end];
array[end] = temp;
//start < end保证了start不会和end交叉,否则
//后面的元素交换并不总是正确的
while(start < end && array[start] <= pivot) ++start;
int temp = array[start];
array[start] = array[end];
array[end] = temp;
}
return start;
}仔细观察上述代码,其实两次元素交换不是必须的,扫描过程重要的是最终枢纽元素的位置,至于中途枢纽元素放在哪里并不重要,因为它是一直在变化着的,重要的是枢纽元素的值,而对于扫描过程中需要与枢纽元素交换的元素则必须立即将其安排到正确的位置上,这样扫描结束后,再将枢纽元素直接放到其最终位置上即可。
int partition(int array[],int start,int end)
{
int pivot = array[start];
while(start < end){
while(start < end && array[end] >= pivot) --end;
array[start] = array[end];
//此时array[start]是小于pivot的,下一个循环得以
//从array[start]开始,并往后推进,而 array[end]
//后的元素都是大于pivot的,而它本身是的值已经转移到
//正确的位置上去了,这个位置上的值实际上已经无效
while(start < end && array[start] <= pivot) ++start;
array[end] = array[start];
//此时,如果在这个方向上找到一个大于pivot的元素,也
//array[start],用array[start]填充array[end]
//这个位置是正确的,前面已经说过,现在
//这个位置上的值是失效的;如果没有找到大于pivot的元素
//那么,start会等于end,则上面这个赋值操作是无效的,
//因为,start等于end,表明扫描完成,外层循环结束,这 //个位置会被pivot填充(见循环外的第一行代码),这
//也将array[end]这个值无效的位置填充,并且所有 //的元素都在正确的位置上了
}
array[start] = pivot;
return start;
}可以看到,减少了很多不必要的赋值操作。划分算法完成后,则整个快排算法也就完成了。为了方便使用,再用一个函数将上面的函数包裹起来:
void QuickSort(int array[],int n)
{
qsort(array,0,n - 1);
}下面是测试代码:
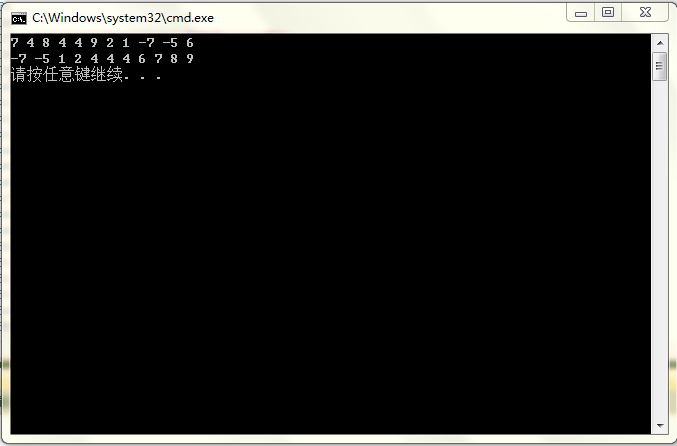
int _tmain(int argc, _TCHAR* argv[])
{
const int N = 11;
int array[] = {7,4,8,4,4,9,2,1,-7,-5,6};
for (int i = 0; i < N; ++i)
{
cout<<array[i]<<' ';
}
cout<<endl;
QuickSort(array,N);
for (int i = 0; i < N; ++i)
{
cout<<array[i]<<' ';
}
cout<<endl;
return 0;
}
快速排序还可以更快,当划分区间小于包含的元素个数小于某个值时,由于快排使用递归因而会慢于插入排序(STL源码剖析语,这个值从5-20效果都差不多),所以一种改进就是如果划分区间元素小于这个值的时候就用插入排序来代替快排,就可以带来更好的性能。使用快排的思想还能在O(N)时间复杂度内找到一个序列中第K大的数(当然可以是中位数喽)和前K大的数(找到了第K大的数,也就找到了前K大的数)。具体思路是当完成一次划分后,不再对两个区间分别调用划分算法,而只在包含了要找的数的那一个区间上使用划分算法,当然,当要找的数所在的区间是后半区间,那么要先计算一下要找的数在后半区间上应该落在哪个位置。如果在前半区间,这一计算就省略了,如果就是pivot所在的位置,那么恭喜,任务完成!















 6152
6152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









