









距离上一篇博客已经过去了四天,“每日一题”这个标题给的压力还是挺大的,这四天一直在学习查找树,同时更进一步地接触STL,所以更新慢了。查找树的删除操作整整花了一天才学会,比较耗时,另外两个有点麻烦的地方是迭代器的前进与后退,需要画图再根据查找树的性质推理。这三个操作算得上两个题吧,整个查找树操作算得上一个题,这样想想,嗯,勉强对得起标题啦,O(∩_∩)O。好了,闲话少说,上代码,吸取了以前的教训,注释全部写在源代码中,直接复制过来就可以了,关于注释只写了比较麻烦的一些操作的,那些简单的就没写了,希望以后拿来看的时候还能看懂:
#ifndef _SEARCH_TREE_H_
#define _SEARCH_TREE_H_
#include "../Utilites/type_traits.h"
#include "Functor.h"
namespace MyDataStructure
{
//将node结构分为两层,可以带来一定的弹性,节点
//基类只负责节点连接的功能,而子类增加了实际的
//数据成员,所谓的弹性在这里得到了体现,本例的
//子类只需要拥有一个数据成员,而对于红黑树而言,
//子类还需要表示颜色的成员,所有使用分层结构可以
//复用
struct BinaryNodeBase
{
typedef BinaryNodeBase* BasePtr;
BasePtr parent; //为了支持迭代器,增设该指针
BasePtr left;
BasePtr right;
//查找以本节点为根的树中的最小值,
//如果有左子树,则一直左转到最左边
//的节点,否则本身为最小
BasePtr minimum()
{
BinaryNodeBase* res = this;
while (res->left)
{
res = res->left;
}
return res;
}
//查找以本节点为根的树中的最大值,
//如果有右子树,则一直右转到最右边
//的节点,否则本身为最大
BasePtr maximum()
{
BinaryNodeBase* res = this;
while (res->right)
{
res = res->right;
}
return res;
}
};
//具体的节点类
template<typename ValueType>
struct BinaryNode : public BinaryNodeBase
{
typedef BinaryNode<ValueType>* LinkType;
ValueType value;
};
//查找树迭代器基类
struct SearchTreeIteratorBase
{
typedef BinaryNodeBase::BasePtr BasePtr;
BasePtr node;
//让迭代器移动到下一个节点
void Increament()
{
//如果迭代器指示的节点有右子节点,
//则以该右子节点为根的树的最小值节
//点就是下一个迭代器该指示的节点
if (node->right) node = node->right->minimum();
else
{
//否则,如果当前指示的节点是右子节
//点,就需要往上搜索第一个不是右子节点
//的节点,如果当前指示的节点是左子节点,
//那么父节点就是了。画图根据查找树的性质容易
//的到算法
BasePtr p = node->parent;
//根节点的父节点为nullptr,需要注意
while (p && p->right == node)
{
node = p;
p = p->parent;
}
node = p;
}
}
//让迭代器移动到上一个节点,和Increament
//算法大同小异,对称地考虑
void Decreament()
{
if (node->left) node = node->left->maximum();
else
{
BasePtr p = node->parent;
while (p && p->left == node)
{
node = p;
p = p->parent;
}
node = p;
}
}
//模拟指针行为,迭代器是一种智能指针
bool operator ==(const SearchTreeIteratorBase& it)
{
return this->node == it.node;
}
bool operator != (const SearchTreeIteratorBase& it)
{
return this->node != it.node;
}
};
//真正的查找树迭代器
template<typename Value,typename Ref,typename Ptr>
struct SearchTreeIterator : public SearchTreeIteratorBase
{
typedef Value ValueType;
typedef Ref reference;
typedef Ptr pointer;
typedef SearchTreeIterator<Value, Value&, Value*> iterator;
typedef SearchTreeIterator<Value, const Value&, Value*> const_iterator;
typedef SearchTreeIterator<Value, Value&, Value*> self;
typedef BinaryNodeBase* LinkType;
typedef BinaryNode<Value>* NodePtr;
SearchTreeIterator() {}
SearchTreeIterator(LinkType x) { node = x; }
SearchTreeIterator(const iterator& it) { node = it.node; }
self& operator =(const iterator& it) { node = it.node; return *this; }
//模拟指针行为,迭代器是一种智能指针
reference operator *(){ return NodePtr(node)->value; }
pointer operator ->() { return &(operator*()); }
self& operator ++()
{
Increament();
return *this;
}
self operator ++(int)
{
self tmp = *this;
Increament();
return tmp;
}
self& operator --()
{
Decreament();
return *this;
}
self operator --(int)
{
self tmp = *this;
Decreament();
return tmp;
}
};
template < typename T, typename Compare = less<T>>
class SearchTree
{
public:
typedef typename ParameterTrait<T>::ParameterType ParameterType;
typedef typename BinaryNode<T> NodeType;
typedef typename BinaryNode<T>* NodePtr;
typedef typename BinaryNode<T>::BasePtr BasePtr;
typedef typename SearchTreeIterator<T, T&, T*>::iterator iterator;
public:
//有两种方式构造一棵查找树:
// 1)构造一颗空树。
// 2)复制一颗已经存在的树
SearchTree() : size(0),head(nullptr){}
SearchTree(const SearchTree& st)
{
copy(st);
}
SearchTree& operator = (const SearchTree& st)
{
if (&st != this)
{
Clear();
copy(st);
}
return *this;
}
~SearchTree(){ Clear(); }
const int Size(){ return size; }
void Clear()
{
_destroy(head);
head = nullptr;
size = 0;
}
//允许插入重复值的方法(批量版)
void Insert(T values[], int count)
{
for (int i = 0; i < count; ++i)
{
Insert(values[i]);
}
}
//允许插入重复值的方法
void Insert(const ParameterType value)
{
//q表示插入后新节点的父节点
BasePtr q = find_position_for_insert(value);
//q为nullptr,树是空的,所以构造头结点
if (q == nullptr)
{
create_head(value);
}
//否则,插入就好了
else
{
NodePtr node = create_node(value);
insert(&q, node);
}
}
//不允许插入重复值的方法(批量版)
void UniqueInsert(T values[], int count)
{
for (int i = 0; i < count; ++i)
{
UniqueInsert(values[i]);
}
}
//不允许插入重复值的方法
void UniqueInsert(const ParameterType value)
{
//q同Insert中,通过p可以知道树中是否
//已经插入同样的值了
BasePtr q = nullptr;
BasePtr p = find_first(head,value, &q);
if (q == nullptr)
{
create_head(value);
}
else
{
//p不为空,插入会变成重复值,所以什么也不做了
if (p != nullptr) return;
NodePtr node = create_node(value);
insert(&q, node);
}
}
iterator FindFirst(const ParameterType value)
{
BasePtr temp = nullptr;
return iterator(find_first(head,value,&temp));
}
iterator FindLast(const ParameterType value)
{
BasePtr temp = nullptr;
return iterator(find_last(head, value, &temp));
}
//从树中删除一个节点
void Erase(iterator& it)
{
erase(it.node);
}
//从树中删除一个节点
void Erase(const ParameterType value)
{
Erase(FindFirst(value));
}
//查找树中的元素是排序的,获得树中最左端的节点
iterator First()
{
BasePtr first = nullptr;
if (head) first = head->minimum();
return iterator(first);
}
//查找树中的元素是排序的,获得树中最右端的节点
iterator Last()
{
BasePtr last = nullptr;
if (head) last = head->maximum();
return iterator(last);
}
//nullptr指示到了尽头了
iterator End()
{
return iterator(nullptr);
}
private:
NodePtr create_node(const ParameterType value)
{
NodePtr node = new NodeType;
node->parent = node->left = node->right = nullptr;
node->value = value;
return node;
}
void copy(const SearchTree& st)
{
__copy(&head, nullptr, st.head);
}
//复制只能采取先序的方式进行,要让子
//节点有归属,得先构造父节点
void __copy(BasePtr* dst,BasePtr p, BasePtr src)
{
if (src == nullptr)
{
*dst = nullptr;
return;
}
*dst = create_node(((NodePtr)src)->value);
(*dst)->parent = p;
++size;
__copy(&((*dst)->left),*dst, src->left);
__copy(&((*dst)->right),*dst,src->right);
}
//摧毁最好采取后序的方式进行,
//这样思考起来会自然更多
void _destroy(BasePtr p)
{
if (p == nullptr) return;
_destroy(p->left);
_destroy(p->right);
delete (NodePtr)p;
}
//删除一个节点是最麻烦的操作
void erase(BasePtr node)
{
if (node == nullptr) return;
//如果待删除的节点只有一个子节点
//,直接让节点的父节点绕过它,指向
//它的子节点就好了,代码之所以复杂,
//是因为需要考虑父节点是否为空,以及
//处理节点的连接时要考虑parent指针,
//而维护parent指针则是为了支持迭代器
//只有右节点
if (node->left == nullptr)
{
BasePtr p = node;
node = node->right;
BasePtr q = parent(p);
if(node != nullptr) node->parent = q;
if (p == head) head = node;
else
{
if (q->left == p) q->left = node;
else q->right = node;
}
delete NodePtr(p);
}
//只有右节点
else if (node->right == nullptr)
{
BasePtr p = node;
node = node->left;
BasePtr q = parent(p);
if (node != nullptr) node->parent = q;
if (p == head) head = node;
else
{
if (q->left == p) q->left = node;
else q->right = node;
}
delete NodePtr(p);
}
//上面两种情况还包含了没有子节点的情况
//待删除节点具有两个节点,根据查找二叉树的性质,
//使用其左子树中的最大值代替待删除节点,左子树最大值
//节点要么某个节点的右子节点,要么就是待删除节点的
//左子节点
else
{
BasePtr p = (node->left)->maximum();
BasePtr q = p->parent; //因为node有两个子节点,所以p的parent不会为空
//把待删除节点的值替换为其左子树中的
//最大值,实际上直接将节点进行替换更合理,
//在节点值为类并拥有许多笔数据时效率更高,
//只是指针操作跟复杂一点
((NodePtr)node)->value = ((NodePtr)p)->value;
//最大值是某个节点的右子节点,
//该最小值节点最多拥有一个左子树
//否则子树中就有一个值比它还大,
//于是调整最大值节点的左子树
if (q != node)
{
q->right = p->left;
}
//最小值是左子节点,此时左子树最多有一个
//左子树,于是调整最大值节点的左子树
else
{
q->left = p->left;
}
//连接时处理parent指针
if (p->left != nullptr) p->left->parent = q;
delete NodePtr(p);
}
--size;
}
void insert(BasePtr* parent, BasePtr node)
{
node->parent = *parent;
if (*parent == nullptr)
head = node;
else if (compare((NodePtr(node))->value, ((NodePtr)(*parent))->value))
(*parent)->left = node;
else
(*parent)->right = node;
++size;
}
void create_head(const ParameterType value)
{
head = create_node(value);
++size;
}
BasePtr left(const BasePtr node){ if (node) return node->left; else return nullptr; }
BasePtr right(const BasePtr node){ if (node) return node->right; else return nullptr; }
BasePtr parent(const BasePtr node){ if (node) return node->parent; else return nullptr; }
BasePtr find_first(BasePtr h,const ParameterType value,BasePtr* last_visited_valid_node)
{
BasePtr res = nullptr;
BasePtr p = h;
*last_visited_valid_node = nullptr;
while (p)
{
*last_visited_valid_node = p;
if (compare(value, ((NodePtr)p)->value)) p = p->left;
else if (value == ((NodePtr)p)->value){ res = p; break; }
else p = p->right;
}
return res;
}
//假设有重复,那么根据插入算法,后来的重复值都被插到第一个值
//的右子树中,但未必就是它的右子节点,所以查找到一个节点后,
//还要在该节点的右子树中继续查找
BasePtr find_last(BasePtr h,const ParameterType value, BasePtr* last_visited_valid_node)
{
BasePtr res = find_first(h,value, last_visited_valid_node);
if (res != nullptr)
{
BasePtr last_visited_valid_node_1 = nullptr;
BasePtr res_1 = find_first(res->right, value, &last_visited_valid_node_1);
if (res_1 != nullptr)
{
res = res_1;
*last_visited_valid_node = last_visited_valid_node_1;
}
}
return res;
}
//找到位置一定是插入节点的父节点
BasePtr find_position_for_insert(const ParameterType value)
{
BasePtr res = nullptr;
BasePtr p = head;
while (p)
{
res = p;
if (compare(value, ((NodePtr)p)->value)) p = p->left;
else p = p->right;
}
return res;
}
private:
BasePtr head;
int size;
Compare compare;
};
}
#endif上面连同注释一共使用了500行代码,应该还有可以精简的地方,代码行数越少越好,想起刚学编程的时候只想着怎样把代码写长,不禁好笑,现在呢觉得对于完成某个功能的代码,不丢失可读性的情况下越短越好,个人写过的总代码行呢,则是越多越好,这一多一少应该就是作为一个学习者应该追求的吧。
Functor.h文件的代码:
#ifndef _FUNCTOR_H_
#define _FUNCTOR_H_
#include "../Utilites/type_traits.h"
namespace MyDataStructure
{
template<typename T>
struct less
{
typedef typename ParameterTrait<T>::ParameterType ParameterType;
bool operator ()(const ParameterType op1, const ParameterType op2)
{
return op1 < op2;
}
};
}
#endiftype_traits.h文件前面的博文已经展示过,不在列出。测试代码(有重复插入):
// SearchTreeTest.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <iostream>
#include "../../include/SearchTree.h"
using namespace MyDataStructure;
using namespace std;
int _tmain(int argc, _TCHAR* argv[])
{
int v[] = { 1, 3, 3, 9, 7, 9, 4, 2, 8, 10 };
SearchTree<int> st;
st.Insert(v, 10);
for (SearchTree<int>::iterator it = st.Last(); it != st.End(); --it)
cout << *it << " ";
cout << endl;
SearchTree<int> st1(st);
st = st;
SearchTree<int>::iterator it1 = st.FindFirst(9), it2 = st.FindLast(9);
cout << "they are " << (it1 == it2) <<" : "<<*it1<<" "<<*it2<<endl;
for (int i = 0; i < 10; ++i)
{
st.Erase(v[i]);
}
for (SearchTree<int>::iterator it = st.Last(); it != st.End(); --it)
cout << *it << " ";
cout << endl;
for (SearchTree<int>::iterator it = st1.First(); it != st1.End(); ++it)
cout << *it << " ";
cout << endl;
const int n = st.Size();
cout << n << endl;
const int m = st1.Size();
cout << m << endl;
st.Clear();
return 0;
}运行结果:
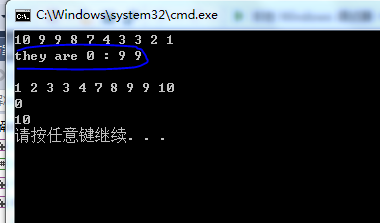
把插入操作改为不允许插入重复值的版本:
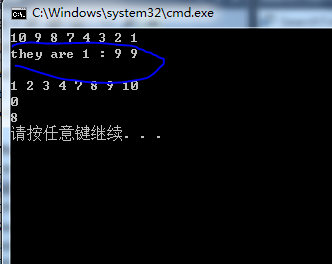
st.Insert(v, 10);改为:
st.UniqueInsert(v, 10);在运行,得到结果:
可以看到,程序通过了基本的测试,而对于一些比较复杂的测试则不再构造了,本序列博客与程序只为学习算法和数据结构,程序的健壮性还暂不考虑。写这个数据结构最复杂的就是删除操作,参看了四本书:《STL源码剖析》、《算法导论》、《数据结构与算法分析(第二版)》以及严蔚敏版的《数据结构》,个人感觉最后一本讲得最清楚,倒数第二本是用递归实现的,容易懂,但是不是太喜欢。写完了这个结构就可以做许多关于二叉树的题目了,如果不以查找树这种方式构建二叉树,输入就太麻烦了,现在有了这一个类,后面的题目全部自主产权,还能继续测试这个类,真是一举两得。















 1103
1103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









