







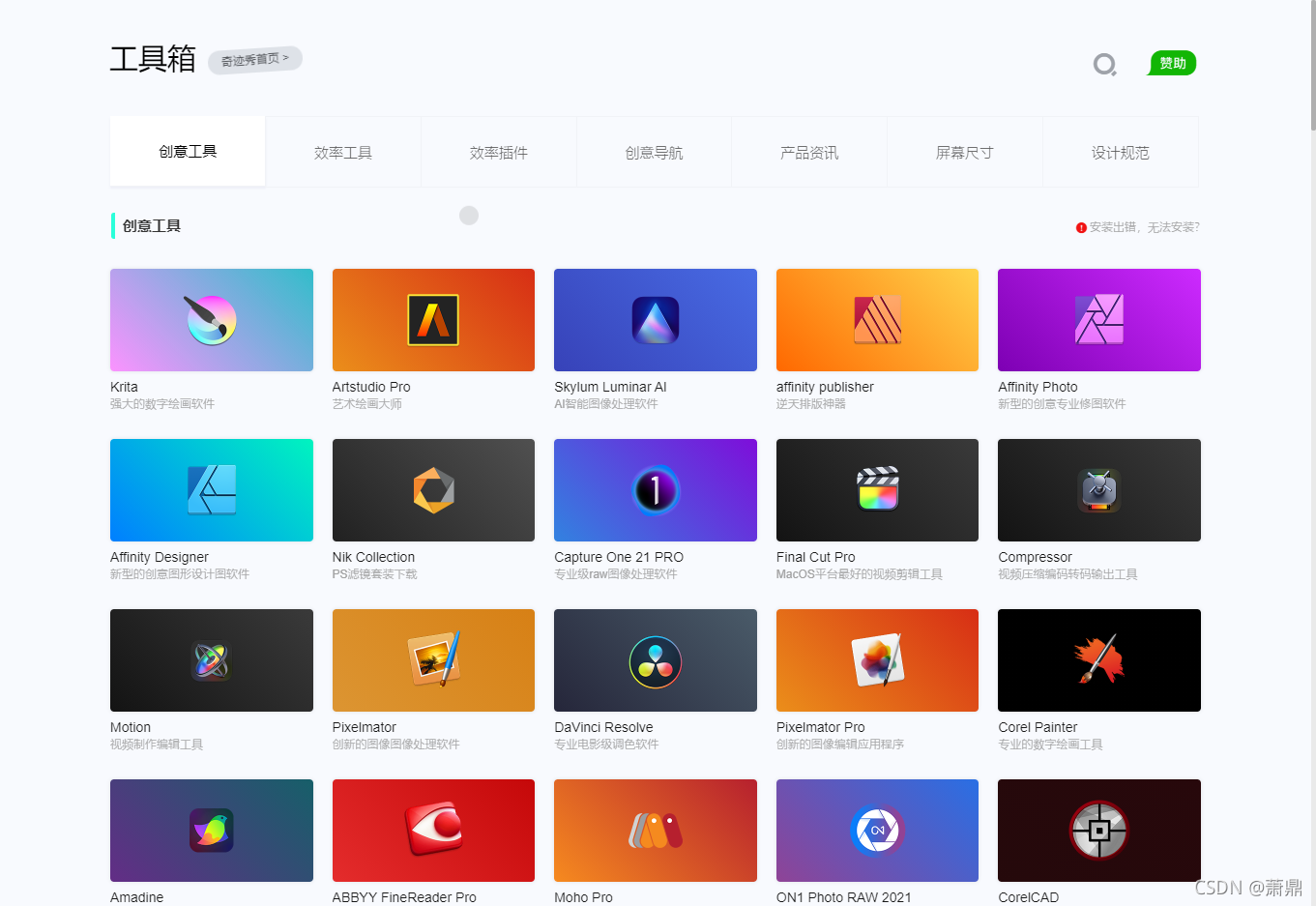
1.爬取的网址:http://www.qijishow.com/down/index.html
2.完整代码展示
from selenium import webdriver
import time
url = 'http://www.qijishow.com/down/index.html'
opt = webdriver.ChromeOptions()
opt.add_argument("--headless")
driver = webdriver.Chrome(chrome_options=opt)
# driver = webdriver.Chrome()
driver.get(url)
k = driver.find_elements_by_class_name("sm-6")
for i in range(1, len(k) + 1):
print(i)
# try:
print("---------------开始----------------------")
a = driver.find_element_by_xpath(
f'//*[@id="page"]/div[4]/div[1]/div[3]/div/div[{i}]/div/a/div[1]/img').get_attribute("data-src")
a1 = 'http://www.qijishow.com/down/' + str(a)
b = driver.find_element_by_xpath(f'//*[@id="page"]/div[4]/div[1]/div[3]/div/div[{i}]/div/a/div[2]').text
print("软件图片地址链接:", a1)
print("软件名字:", b)
time.sleep(2)
# driver.find_element_by_xpath(f'//*[@id="page"]/div[4]/div[1]/div[3]/div/div[{i}]/div/a/div[1]/img').click()
ele=driver.find_element_by_xpath(f'//div[@class="row"]/div[{i}]')
driver.execute_script("arguments[0].scrollIntoView()", ele)
ele.click()
print("11111111111")
time.sleep(2)
windows = driver.window_handles
driver.switch_to.window(windows[-1])
p = driver.find_element_by_xpath('//*[@id="resources"]').text
print(p)
u = driver.find_elements_by_xpath('//img')
src = []
for j in u:
o = j.get_property('src')
src.append(o)
print('文章图片地址:', o)
r = driver.find_element_by_xpath('//*[@id="download"]/a[@id="local"]').get_attribute('href')
print("官网地址:", r)
try:
x = driver.find_element_by_xpath('//*[@id="zoom_download"]/div[2]/p').text
y = driver.find_element_by_xpath('//*[@id="zoom_download"]/div[2]/a[1]').get_attribute('href')
print(x, y)
except:
x = "没有"
y = "没有"
try:
z = driver.find_element_by_xpath('//*[@id="zoom_download"]/div[3]/p').text
h = driver.find_element_by_xpath('//*[@id="zoom_download"]/div[3]/a[1]').get_attribute('href')
print(z, h)
except:
z = "没有"
h = '没有'
with open("爬虫/{}.txt".format(i), "w", encoding="utf-8") as f:
f.write("软件图片地址链接:" + a1 + '\n')
f.write("软件名字:" + b + '\n')
f.write(p + '\n')
f.write('文章图片地址:' + str(src) + '\n')
f.write("官网地址:" + r + '\n')
f.write(x + "Mac版百度网盘地址:" + y + '\n')
f.write(z + "Win版百度网盘地址:" + h)
driver.close()
driver.switch_to.window(windows[0])
print("---------------结束----------------------")
# except:
# pass
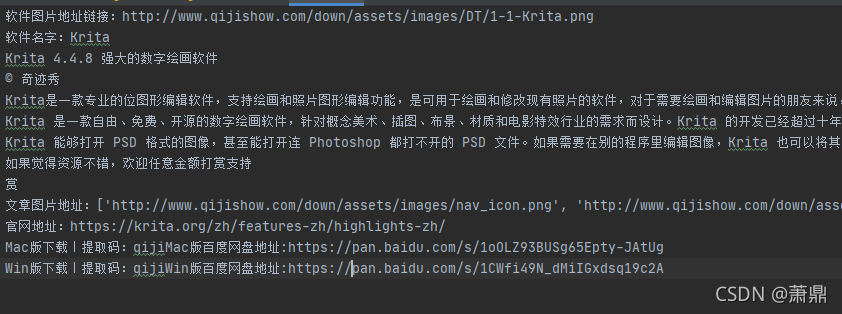
3.爬取的文档展示
4.爬取并保存为表格完整代码
from selenium import webdriver
import time
import csv
url = 'http://www.qijishow.com/down/index.html'
opt = webdriver.ChromeOptions()
# opt.add_argument("--headless")
# driver = webdriver.Chrome(chrome_options=opt)
driver = webdriver.Chrome()
driver.get(url)
k = driver.find_elements_by_class_name("sm-6")
with open("交互设计.csv", "w", newline="", encoding="utf-8-sig") as datacsv:
csvwriter = csv.writer(datacsv, dialect=("excel"))
csvwriter.writerow(["软件图片地址链接", "软件名字", "富文本", "官网地址", "Mac版下载", "Win版下载"])
for i in range(1, len(k) + 1):
l=[]
print(i)
try:
print("---------------开始----------------------")
a = driver.find_element_by_xpath(
f'//*[@id="page"]/div[4]/div[5]/div[3]/div/div[{i}]/div/a/div[1]/img').get_attribute("data-src")
a1 = 'http://www.qijishow.com/down/' + str(a)
b = driver.find_element_by_xpath(f'//*[@id="page"]/div[4]/div[5]/div[3]/div/div[{i}]/div/a/div[2]').text
print("软件图片地址链接:", a1)
print("软件名字:", b)
l.append(a1)
l.append(b)
# driver.find_element_by_xpath(f'//*[@id="page"]/div[4]/div[1]/div[3]/div/div[{i}]/div/a/div[1]/img').click()
ele=driver.find_element_by_xpath(f'//*[@id="page"]/div[4]/div[5]/div[3]/div/div[{i}]/div/a/div[1]/img')
driver.execute_script("arguments[0].scrollIntoView()", ele)
time.sleep(2)
ele.click()
windows = driver.window_handles
driver.switch_to.window(windows[-1])
p = driver.find_element_by_xpath('//*[@id="resources"]').get_attribute('outerHTML')
print(p)
l.append(p)
r = driver.find_element_by_xpath('//*[@id="download"]/a[@id="local"]').get_attribute('href')
print("官网地址:", r)
l.append(r)
try:
x = driver.find_element_by_xpath('//*[@id="zoom_download"]/div[2]/p').text
y = driver.find_element_by_xpath('//*[@id="zoom_download"]/div[2]/a[1]').get_attribute('href')
print(x, y)
l.append(x+" "+y)
except:
x = "没有"
y = "没有"
l.append(x+" "+y)
try:
z = driver.find_element_by_xpath('//*[@id="zoom_download"]/div[3]/p').text
h = driver.find_element_by_xpath('//*[@id="zoom_download"]/div[3]/a[1]').get_attribute('href')
print(z, h)
l.append(z+" "+h)
except:
z = "没有"
h = '没有'
l.append(z+" "+h)
csvwriter.writerow(l)
driver.close()
driver.switch_to.window(windows[0])
print("---------------结束----------------------")
except:
pass
5.爬取的表格展示




















 1993
1993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











