






近来学习了一下 cpu cache的知识,网上查了一些资料,在此整理一下。
一cache结构:
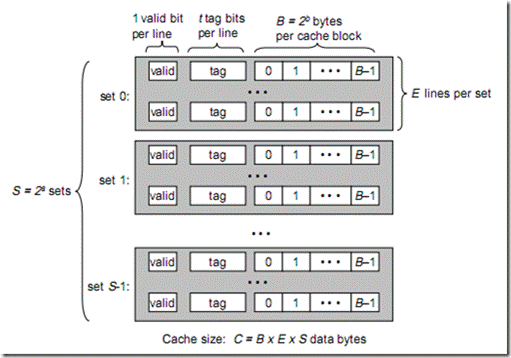
如图所示,一个cache被分为S个组,每个组有E个cacheline,而一个cacheline中,有B字节存储单元。 valid通常是一位,代表该cacheline是否是有效的(当该cacheline不存在内存映射时,当然是无效的)。tag就是内存地址的高t位,因为可能会有多个内存地址映射到同一个cacheline中,所以该位是用来校验该cacheline是否是CPU要访问的内存单元
当cpu需要去获取每个内存地址的数据时,内存地址分为以下三个区间:

其中:
B = 2^b
S = 2^s
因此,在一个内存地址中,中间的s位决定了该单元被映射到哪一组,通过内存地址的高t位及cache中valid位可以定位到再那个cacheline中,而最低的b位决定了该单元在cacheline中的偏移量。
当从内存中取单元到cache中时,会一次取一个cacheline大小(一般64字节)的内存区域到cache中,然后存进相应的cacheline中。
二:如何提高命中率
1、缓存命中
当程序需要第k+1层中的某个数据时d,会首先在它的缓存k层中寻找。如果数据刚好在k层中,就称为缓存命中(cache hit)。
2、缓存不命中
当需要的数据对象d不再缓存k中时,称为缓存不命中。当发生缓存不命中时,第k层的缓存会从k+1层取出包含数据对象d的那个块,如果k层的缓存已经放满的话,就会覆盖其中的一个块。至于要覆盖哪一个块,这是有缓存中的替换策略决定的,比如说可以覆盖使用频率最小的块,或者最先进入缓存的块。。这里不再讨论。在k层从k+1层中取出数据对象d后,程序就能在缓存中读取数据对象d了。
3、缓存命中和局部性
时间局部性:被引用过一次的存储器位置在未来会被多次引用(通常在循环中)。
空间局部性:如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。
这里简单的说说为什么局部性好的程序能有更好的性能
利用时间局部性:由于时间局部性,同一个数据对象会多次被使用。一旦一个数据对象从k+1层进入到k层的缓存中,就希望它多次被引用。这样能节省很多访问造成的时间开支。
利用空间局部性:假设缓存k能存n个数据块。在对数组访问的时候,由于数组是连续存放的,对第一个元素访问的时候,会把第一个元素后面的一共n个元素(缓存k有n个数据块)拷贝到缓存k中,这样在对第二个元素到第n个元素的访问时就可以直接从缓存里获取,从而提高性能,同理,访问第n个元素的时候 ,n不在缓存中,缓存管理器会把从n到2n的元素拷贝到缓存中,对它们的访问就可以直接在缓存中进行。
4:伪共享问题:
这里不对cpu多核数据同步机制进行描述了,这里只是简单的描述一下现象,先看以下例子:
系统是双核的,即为有2个CPU,CPU(例如Intel Pentium处理器)L1 cache是专有的,对于其他CPU不可见,每个cacheline有8个储存单元。
我们的程序中,有一个 char arr[8] 的数组,这个数组当然会被映射到CPU L1 cache中相同的cacheline,因为映射机制是硬件实现的,相同的内存都会被映射到同一个cacheline。
2个线程分别对这个数组进行写操作。当0号线程和1号线程分别运行于0号CPU和1号CPU时,假设运行序列如下:
开始CPU 0对arr[0]写;
随后CPU 1对arr[1]写;
随后CPU 0对arr[2]写;
……
CPU 1对arr[7]写;
根据多处理器中cache一致性的协议:
当CPU 0对arr[0]写时,8个char单元的数组被加载到CPU 0的某一个cacheline中,该cacheline的modified位已经被置1了;
当CPU 1对arr[1]写时,该数组应该也被加载到CPU 1的某个cacheline中,但是该数组在cpu0的cache中已经被改变,所以cpu0首先将cacheline中的内容写回到内存,然后再从内存中加载该数组到CPU 1中的cacheline中。CPU 1的写操作会让CPU 0对应的cacheline变为invalid状态注意,由于相同的映射机制,cpu1 中的 cacheline 和cpu0 中的cacheline在逻辑上是同一行(直接映射机制中是同一行,组相联映射中则是同一组)
当CPU 0对arr[2]写时,该cacheline是invalid状态,故CPU 1需要将cacheline中的数组数据传送给CPU 0,CPU 0在对其cacheline写时,又会将CPU 1中相应的cacheline置为invalid状态
……
如此往复,cache的性能遭到了极大的损伤!此程序在多核处理器下的性能还不如在单核处理器下的性能高。
三:了解机器的cpu cache情况
可以通过如下方法查看到本机的cpucache情况:
(1) 第一种方法:
dmesg | grep cache
(2) 第二种方法:
[root@gc15 ~]# ls /sys/devices/system/cpu/cpu0/cache/index
index0/ index1/ index2/ index3/
其中index0和index1对应的为L1, index2对应的为L2, index3对应的为L3。每个目录中包含一些cache的信息。
参考链接:
http://blog.csdn.net/erlib/article/details/40539499
http://www.oschina.net/translate/what-every-programmer-should-know-about-memory-part1
http://www.oschina.net/translate/what-every-programmer-should-know-about-cpu-cache-part2















 1691
1691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









