










前言:
- 在我们绘图过程中我们用到了 Checkpoint 模型和 VAE模型,但是还有另外三种可以辅助我们出图的模型没有给大家介绍,他们分别是 Embeddings(嵌入)、Lora(低秩适应模型)、Hypernetwork(超网络)这三种模型;
- 在开始讲解这三个模型之前我们一定要记住不止 Checkpoint(大模型)分 SD1.4、SD1.5、SDXL1.0等基础算法型号,这三个模型同样也分,我们在使用时要选择对应基础算法型号才能正常使用。
- 今天我们就讲讲这三种模型分别是什么原理、有什么作用和怎么使 用。
Embeddings:
原理介绍(如果只想知道怎么使用可以跳过原理介绍这段):
- Embeddings 翻译成中文就是“嵌入”,他在深度学习领域通常指的是“嵌入式向量”,这些向量是高维空间中的点,能够代表输入数据(如文本或图像)的关键特征。
- 我们输入的关键词能被识别,正是因为 Text Encoder 将自然语意的 Prompt 转成了数值向量,这些数值向量他们不仅包含数值信息,还包含数据之间的关系和结构信息。
- 想象一下,你正在向别人描述独角兽长什么样,你可能会说‘它像马,有白色的毛发,前额上有一只角’。即使对方从未见过独角兽,通过这些关键描述,他们也能在脑海中形成一个独角兽的形象。在深度学习中,Embeddings模型的作用类似于这种描述。当我们给计算机系统输入一个词,比如‘独角兽’,Embeddings模型会生成一个数值向量,这个向量包含了与‘独角兽’相关的所有关键特征。这样,即使计算机系统‘没见过’独角兽,它也能通过这个向量理解‘独角兽’这个是什么。
- 通过上面的例子可以看出他只是在描述什么是“独角兽”,并将其转换成一种数值表示形式,并不直接参与绘画。所以他没有改变大模型的权重参数,也就只能用来固定元素或画面特征,这也是他的局限性。
安装位置:
- 我们在部份模型下载网站很有可能看不到 Embeddings 模型,但是他会以 Textual Inversion(文本倒置)这个名字出现,他们是同一个东西(下图是 C 站和 LibLib 的筛选框)。
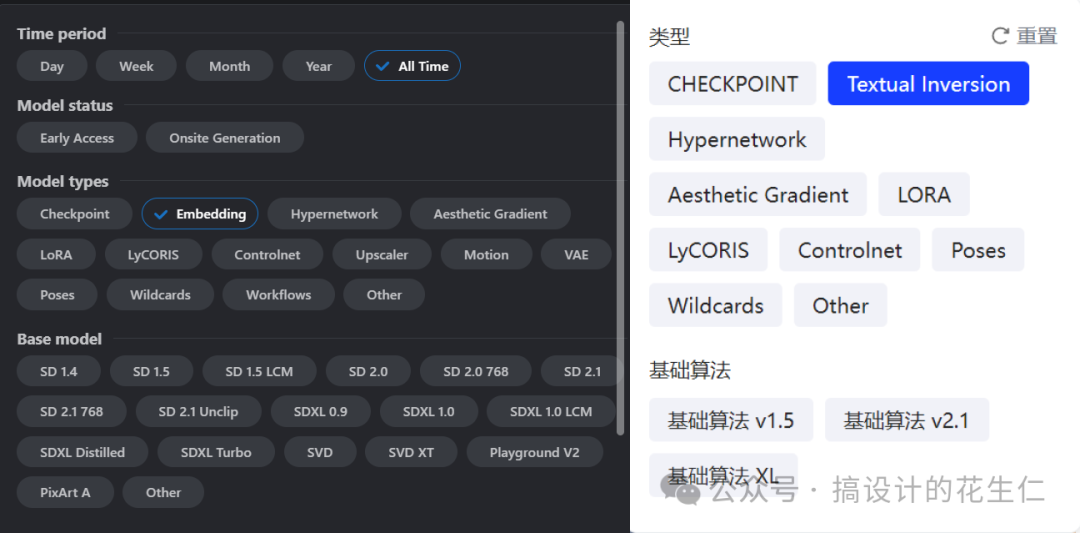
- 模型存放位置在:“ComfyUI_windows_portable\ComfyUI\models\embeddings”目录下,如果你是和 Web UI 共用的模型,那就放在“sd-webui\embeddings”目录下。
作用及如何使用:
- 此模型通常用来嵌入元素特征(比如人物特征)、负面信息(用来减少图的崩坏几率)
- 使用 Embeddings 模型我们只需要在提示词输入框输入他的“触发词”就可以,一般我们在下载模型的时候会看到作者给出的触发词。
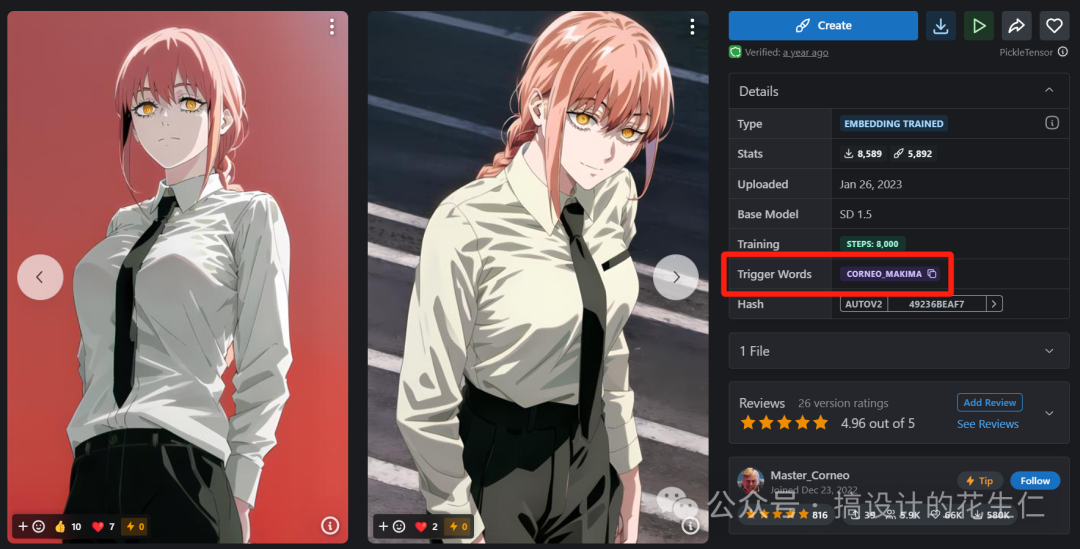
- 是不是输入触发词比较麻烦,我们需要记住每个模型的触发词。我们可以通过一个插件去选择 Embeddings 模型,还记得我第一节课给大家推荐的“小瑞士军刀美化辅助(ComfyUI-Custom-Scripts)”插件吗,在输入框输入“embeddings”中的任意一个字母或“模型名称的任意一个字母”即可在弹窗中选择模型,并且点击模型右侧的“ℹ️”还可以查看模型的相关信息及 C 站跳转链接。
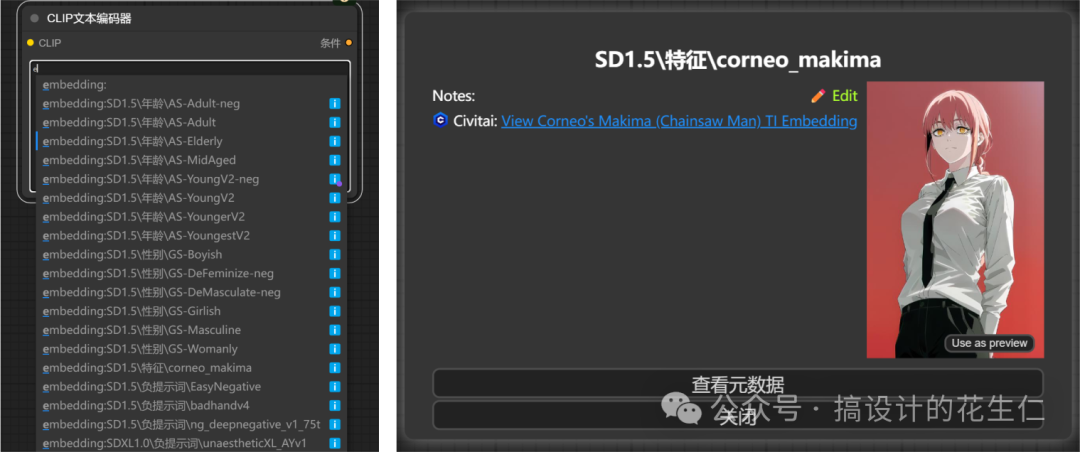
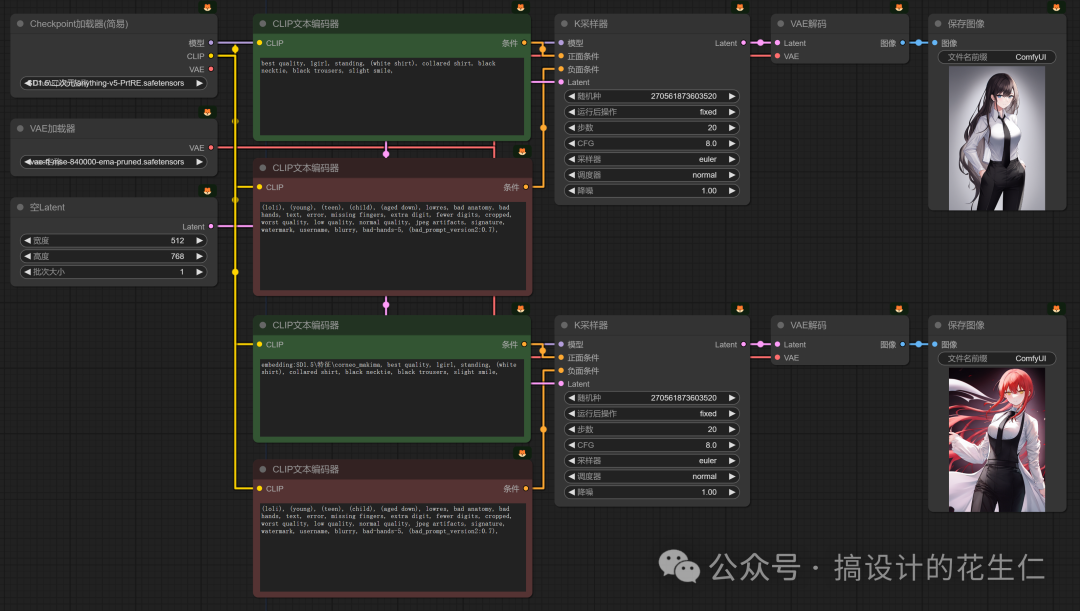
- 我们用《电锯人》中 Makima 的 Embeddings 模型来对比一下不使用和使用的效果(相同关键词和种子下,上/左图:未使用,下/右图:使用)

-
很明显的看出下面这张图带有 Makima 的特征,当然和真正的 Makima 还是有一定区别的,要想让图像更加符合人物特征还是要用 Lora 模型。
-
我们用的最多的还是用来解决AI不会画手或肢体错乱,颜色混杂等痛点,这时候就有大佬整合一些 AI 画错了的图像(比如:六指,畸形的图像,三条腿…),训练成了 Embeddings 模型也叫 Negative Embeddings(负面词嵌入)模型,我们只需要把他输入到负向关键词里面,在绘图时让他禁止绘制此类案例就可以了。
-
常用的 Negative Embeddings(负面词嵌入)模型:
-
- SD1.5:badhandv4、EasyNegative、ng_deepnegative_v1_75t
- SDXL1.0:unaestheticXL_AYv1
-
我们来看一下效果(相同关键词和种子下,上图:未使用,下图:使用),我们很明显地看出有一定的效果

- 当然加了 Embeddings 也并不意味着就能解决这些问题,它只是提高了生成好图片的概率,但是总比不加时效果好了很多。
- 在使用 Embeddings 模型时,我们可以多个 Embeddings 模型 进行组合使用,会让我们得到意想不到的效果;
- 常用的 Embeddings 模型我也会放在本节课的文件里面,比如对年龄、性别的控制模型。
Lora:
原理介绍(如果只想知道怎么使用可以跳过原理介绍这段):
- LoRA:Low-Rank Adaptation Models(低秩适应模型),他的核心思想是在不显著改变原有模型结构的情况下,通过添加一些额外的、低秩(即简化的)矩阵来调整模型的权重,从而提升模型的性能或适应性。
- 在微调 Stable Diffusion 模型的情况下,相较于大模型的 Dreambooth(训练方法,输出 Checkpoint 模型)的全面微调模型方法,Lora 的训练参数可以减少很多倍,对硬件性能的要求也降低很多。
- 想象一下你有一辆车,这辆车已经可以满足你的日常需求,比如上班通勤。但有一天,你决定参加一场越野赛车比赛。你知道你的车在原有状态下无法应对越野赛的挑战,但你也不想换一辆新车。这时,你可以选择对你的车进行一些改装,比如换上越野轮胎、增强悬挂系统,这样你的车就能适应越野赛的环境。
- 在这个例子中,你的原始车辆就像是一个已经训练好的神经网络模型,它在大多数情况下都能很好地工作。然而,当面对新的或特殊的任务(比如越野赛)时,它可能需要一些调整才能更好地适应。LoRA(Low-Rank Adaptation)模型的作用就像是对车辆进行的这些特定改装。通过在原有模型上添加低秩矩阵(相当于对车辆的特定部分进行改装),我们可以使模型更好地适应新的任务,而不需要完全重新设计或训练一个新模型。
安装位置:
模型存放位置在“ComfyUI_windows_portable\ComfyUI\models\loras”目录下,如果你是和 Web UI 共用的模型,那就放在“sd-webui\models\Lora”目录下。
作用及如何使用:
- 通常 Lora 模型用来指定目标特征(比如:人物、动作、年龄、服装、材质、视角、风格等);
- 在使用上比较简单,“右键-新建节点-加载器-LoRA加载器”;
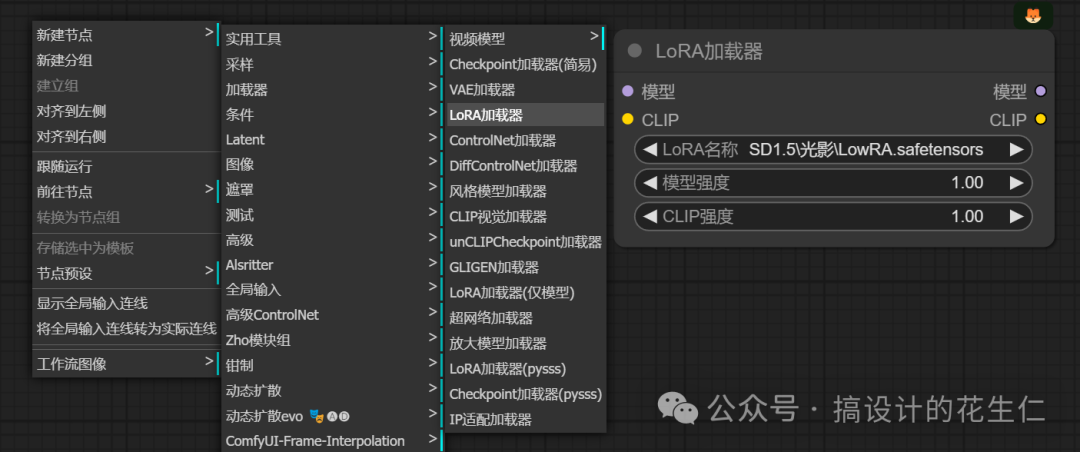
- 看到这个节点我们应该能猜到怎么连接吧,左侧的“模型/CLIP”和“Checkpoint加载器”连接,右侧的“模型/CLIP”分别和“K采样器”、“CLIP文本编码器”连接。
- 这时候我们会发现个问题,有两个“CLIP文本编码器”(正向和负向)啊,我们连哪个,还是都连。经过测试只对正向关键词有效果,也就是说,我们可以两个都连接,也可以只连正向关键词对应的“CLIP文本编码器”。
- 我们选择个 Lora模型 试一下效果,我以原神中的角色 芭芭拉 为例:
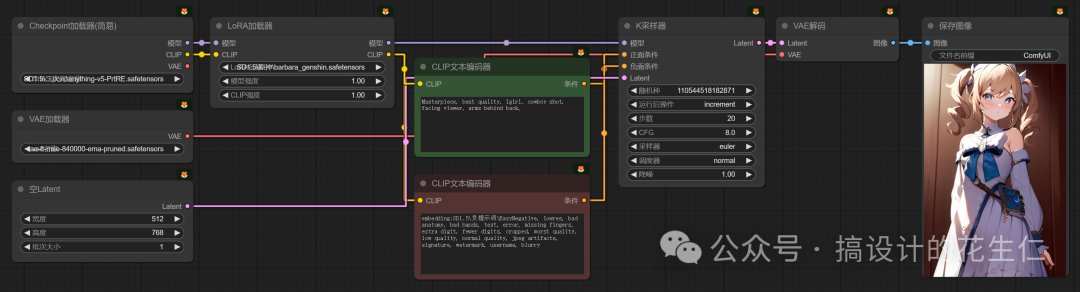
- 是不是知道怎么使用了,但是我们在 Web UI 上可以设置 Lora模型 的权重和使用多个 Lora模型对吧,一个个来说,我们先说怎么设置权重;
- 在“LoRA加载器”节点上除了选择模型外是不是还有两个可以设置参数的地方,模型强度、CLIP强度。至于我们设置哪个参数能达到控制权重的效果,完全取决于模型的训练方式。所以我们在不知道受哪个参数影响的情况下,我们可以对两个参数都进行调节,而 Web UI 上是把两个参数整合在一起了。
- 至于多个 Lora模型那就更简单了,我们在这个“LoRa模型加载器”后面再连一个就可以了;
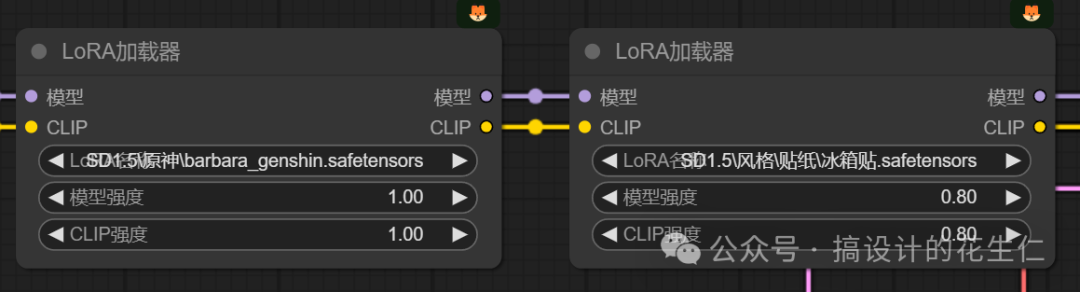
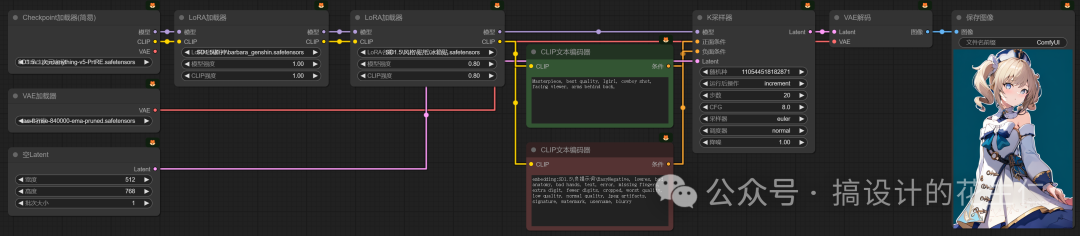
-
是不是已经学会了怎么使用 Lora模型了,但是我们使用多个 Lora模型 的时候就会让流程图更复杂、更乱,调节权重也比较麻烦,我们可以使用一个插件帮我们解决。
-
efficiency-nodes-comfyui(效率节点):https://github.com/jags111/efficiency-nodes-comfyui.git
-
我们先看一下怎么使用,直接把三个节点都加载出来“右键-新建节点-效率节点-堆栈- LoRA堆”、“右键-新建节点-效率节点-效率加载器”、“右键-新建节点-效率节点-采样-K采样器(效率)”。
-
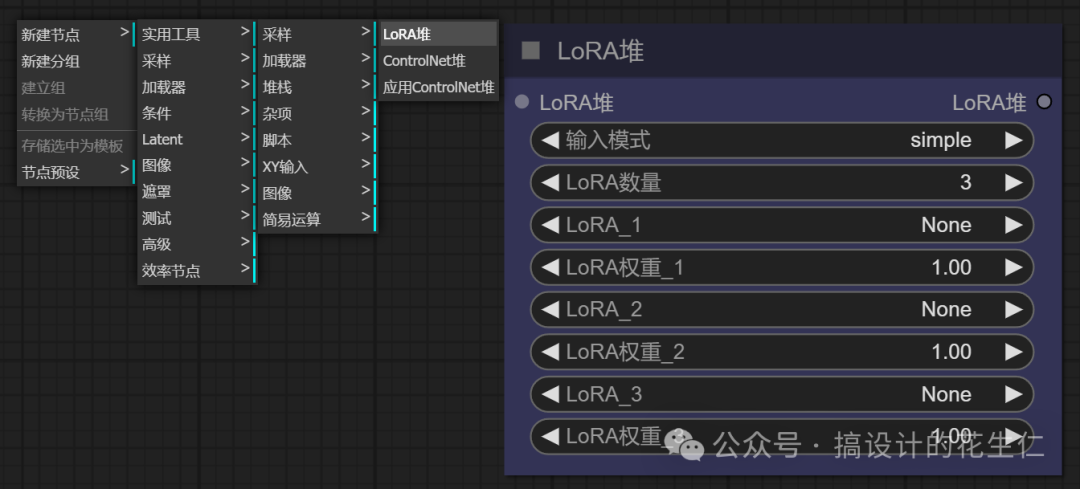
先看“LoRA堆”节点我们可以看到有三类可调节的地方;
-
- 输入模式:和控制权重有关,在这个节点我们可以通过调节一个参数就能控制权重了,如果我们把输入模式改为高级,Lora权重就会分成模型强度、CLIP强度;
- Lora数量:用来调节我们使用几个 Lora模型的,当前数值是3,我们就有三个Lora可选;
- Lora选择和权重就不用说了吧。
-
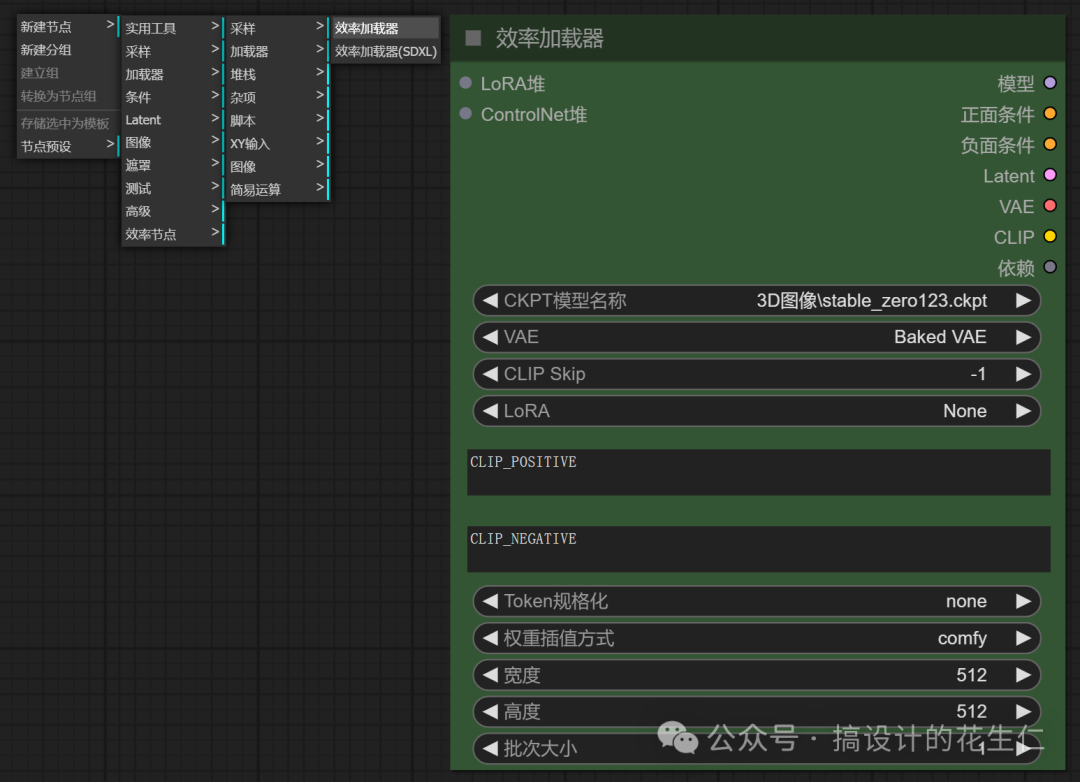
效率加载器,我们需要操作的地方有:大模型选择、VAE模型选择、Lora模型(不使用选无,如果只使用一个就可以在这个节点选择,多个情况下就使用我们上面说的 Lora堆节点)、正反提示词、宽高、批次;
-
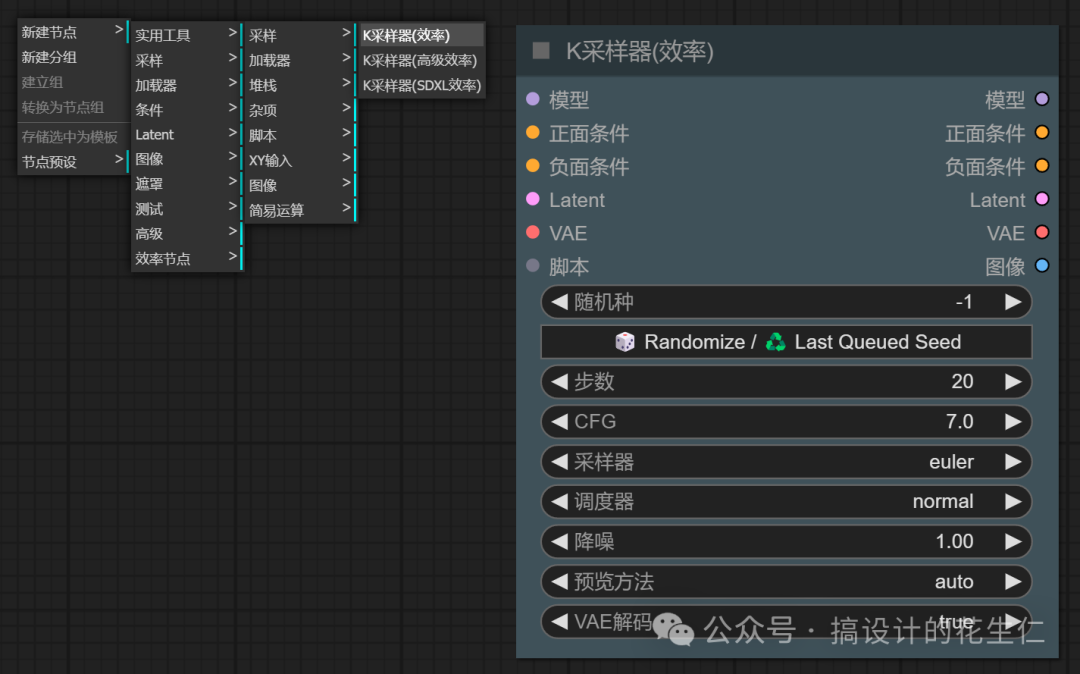
K采样器基本上一样,没什么大的区别。
- 是不是在这三个节点上就很明显的看出减少了很多的连接,我还是以芭芭拉和冰箱贴纸两个Lora为例进行连接;
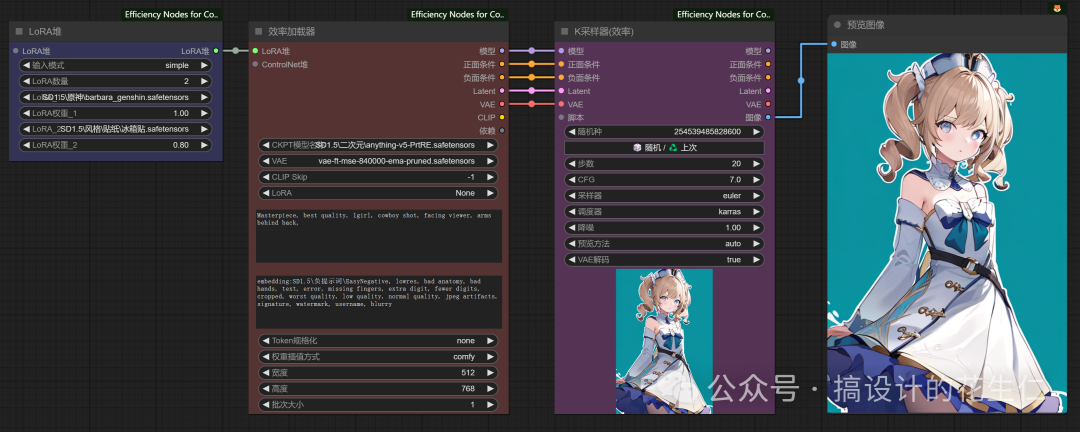
- 是不是简单了很多,这个插件可不止用来帮我们解决 Lora模型的连接的问题,他能帮我们简化很多节点的连接,包括我们下节课要讲的多个 ControlNet 使用,也能减少连接步骤。
Hypernetwork:
原理介绍(如果只想知道怎么使用可以跳过原理介绍这段):
- 这个,,,现在用的很少了,我们简单说一下。Hypernetwork 也叫超网络,他的原理是在扩散模型的基础上新建一个神经网络来调整模型参数,就是因为这个原因才叫做超网络模型。
- 他在效果上和 Lora 类似,但是因为训练难度大,应用范围小,所以逐渐被 Lora 替代。
安装位置
模型存放位置在“ComfyUI_windows_portable\ComfyUI\models\hypernetworks”目录下,如果你是和 Web UI 共用的模型,那就放在“sd-webui\models\hypernetworks”目录下。
作用及如何使用:
- 大多用来控制图像风格;
- 在使用上他和 Lora 有些类似,“右键-新建节点-加载器-超网络加载器”;
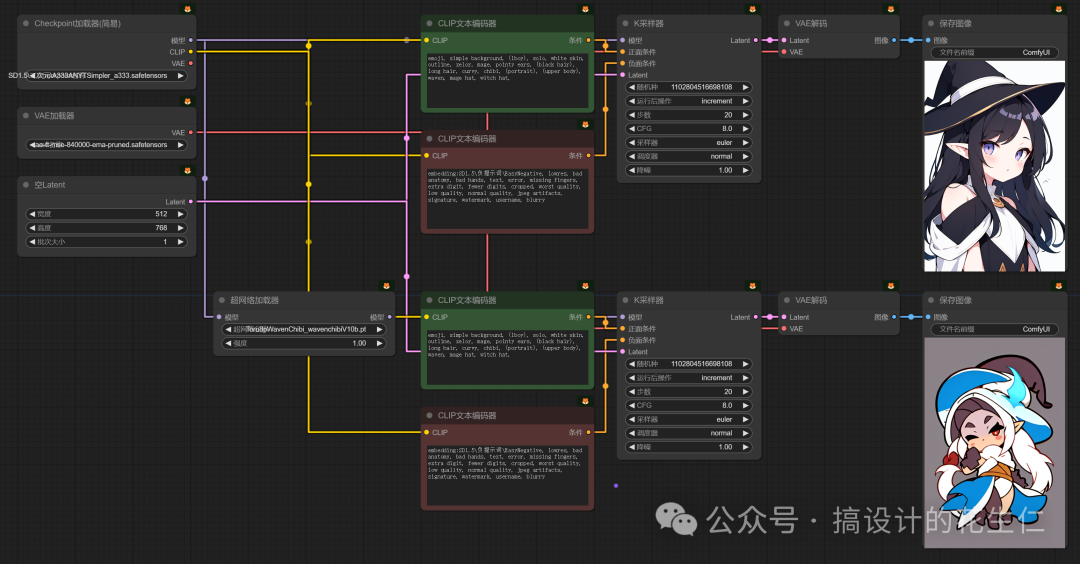
- 可以看到,“超网络加载器”相比“LoRa加载器”少了CLIP的连接,我们只把他串联在“Checkpoint加载器”和“K采样器”之间就可以。
- 下面我使用一个 Chibi风格(日语中翻译为小矮子、小家伙)的超网络模型演示一下(相同关键词和种子下,上/左图:未使用,下/右图:使用)。

总结:
- 这节课十分的简单,我们每一个微调模型都能多个叠加使用,并且这三类可以同时使用;
- 虽然给大家介绍了“效率节点”,但是他不是万能的,我们搭建一个复杂的工作流还是需要了解出图的逻辑。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1916
1916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









