









纯技术交流,请勿用于非法用途,如有权益问题可以发私信联系我删除.
最近分析了个VMP,首先查看页面
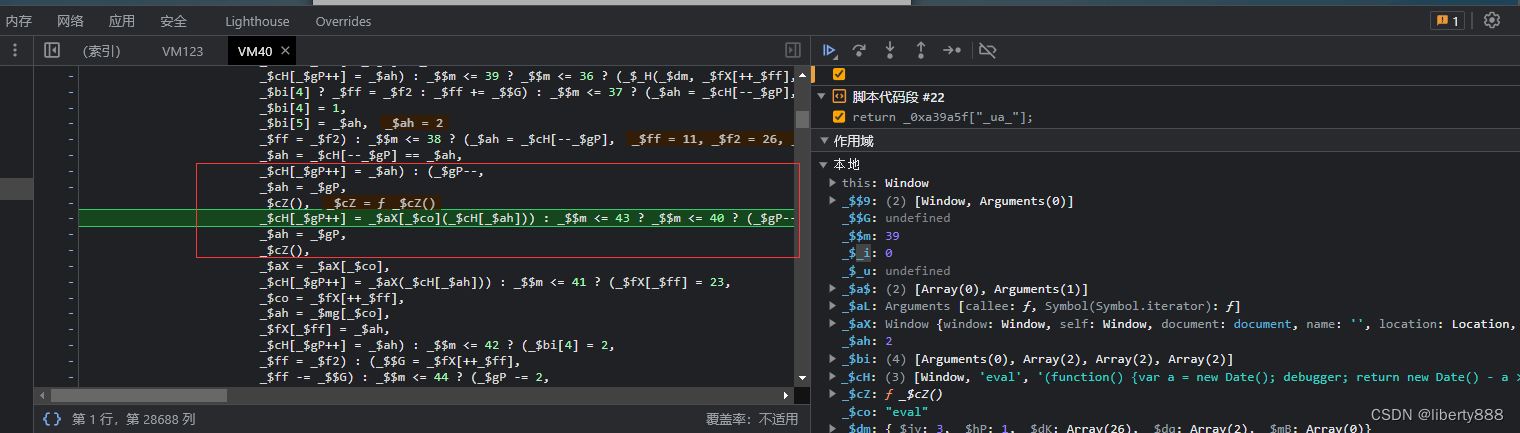
应该就是个典型的VMP,这种相当难扣代码,本人能力不足是扣不出来的。
果断采用补环境框架处理,经过补环境框架处理后,日志如下。
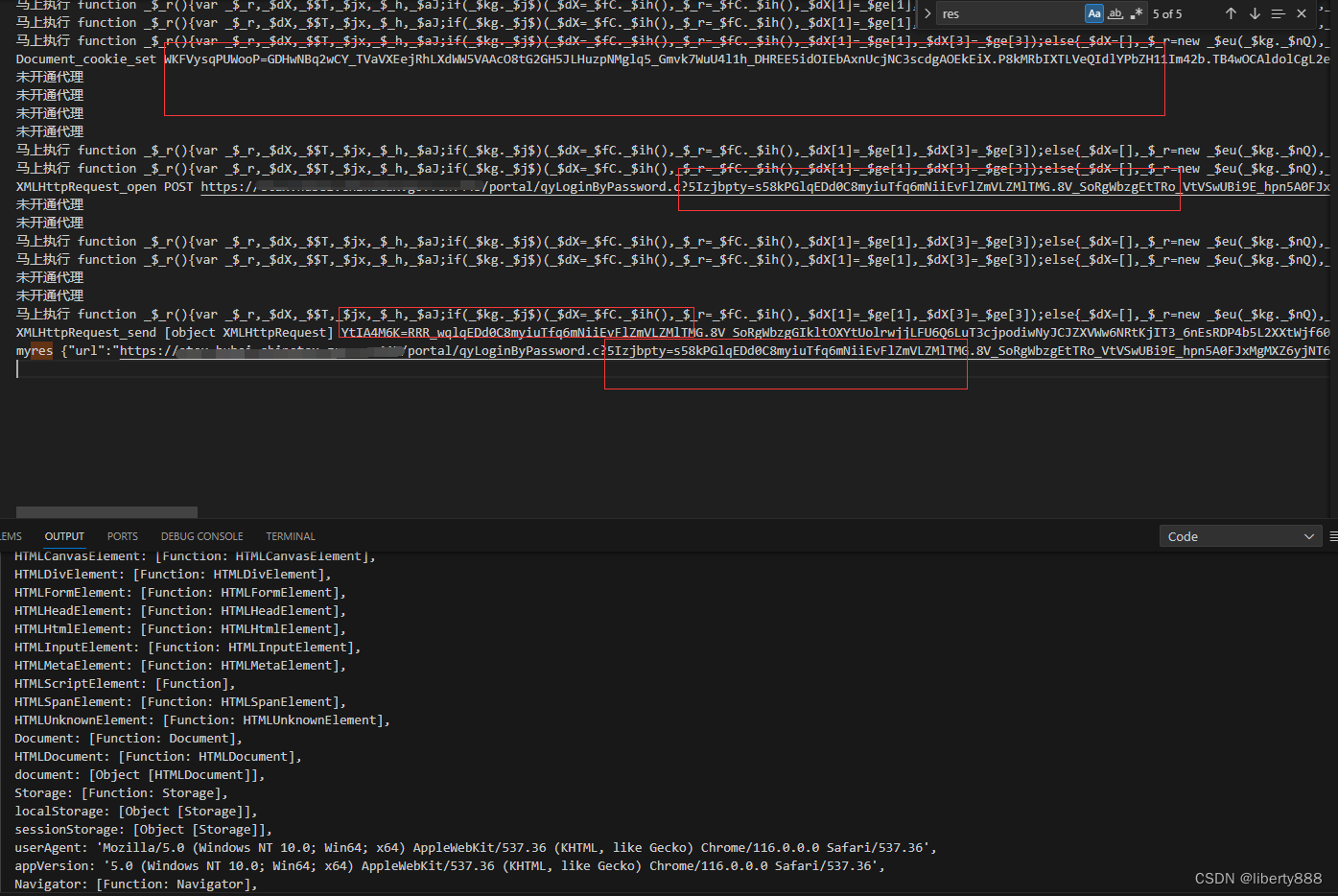
发现需要的参数都生成了。搭建个node服务使用VM2调用测试下,如下

都是返回200,测试通过。
最终结论还是补环境框架处理VMP比较合适,扣代码简直太难了。如果你还在为VMP烦恼,使用补环境框架处理吧,只要你的环境真,那么结果也会真。
部分可能的监测点,具体自己测试。
navigator
document.documentElement
navigator.webkitPersistentStorage
document.createExpression
Document_visibilityState_get
HTMLAllCollection_length_get
window.RegExp
RegExp
webkitRequestFileSystem
IDBFactory_open
document.all
form = document.createElement('form')
form.id = 'test'
document.body.appendChild(form)
window.test
Window.prototype.test
window.proto.proto
window.proto.proto.test
location
纯技术交流,请勿用于非法用途,如有权益问题可以发私信联系我删除.
















 4258
4258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











