







问题:
HDP重启后,NameNode Last Checkpoint报错误[Checkpoint Critical]
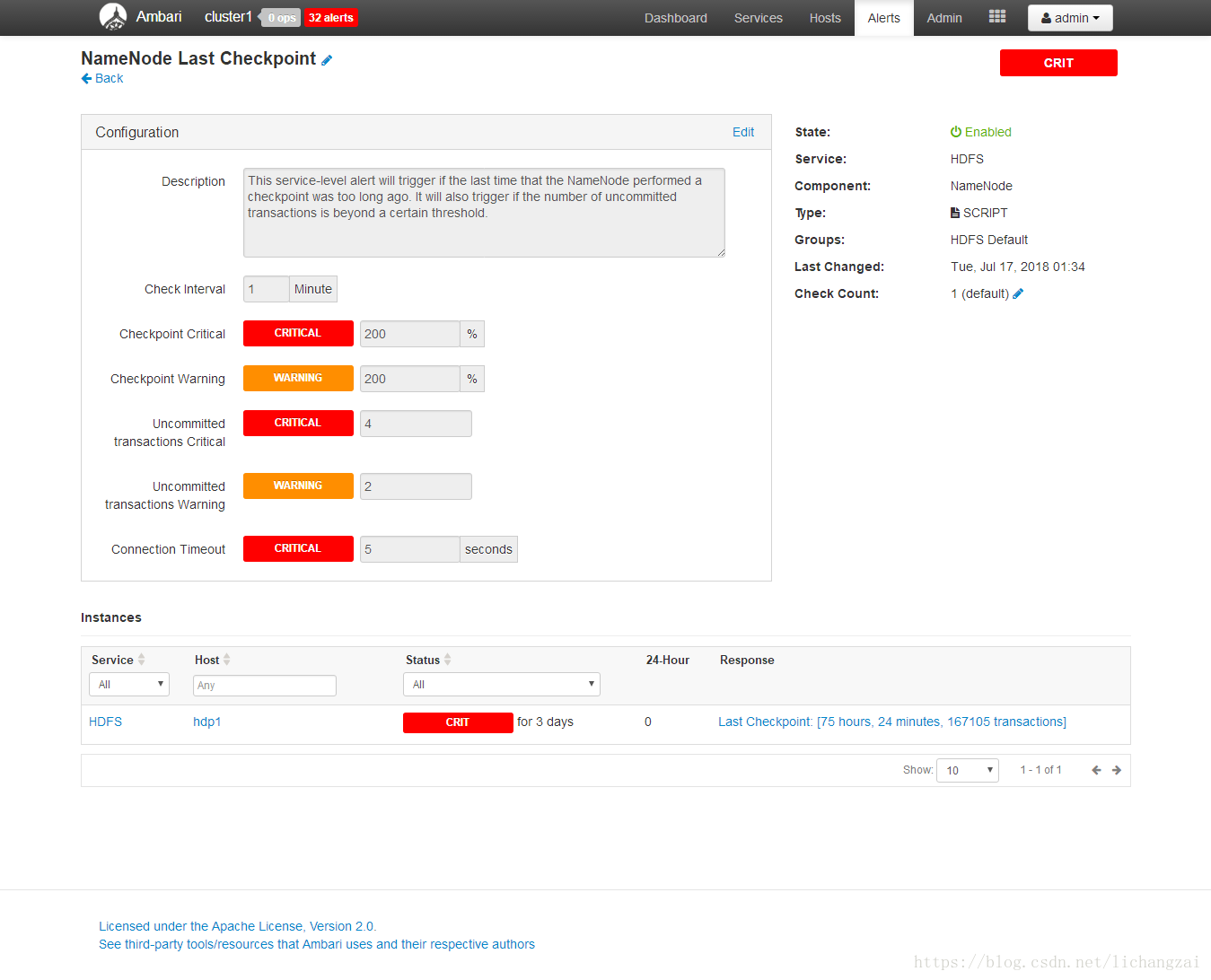
问题解决:
原理:
HDP中的hdfs组件默认的dfs.namenode.checkpoint.period和dfs.namenode.checkpoint.txns分别是6个小时和1000000。
只要达到这两个条件之一,secondarynamenode会执行checkpoint操作
解决:
1.可以到Namenode当前文件夹并检查创建的最后一个fsimage的时间,群集停止了很长时间。
可能需要查看上述两个参数并检查当前文件夹中的时间戳,并找出未发生自动检查点的原因。
2.查看确定系统时间是否同步,ntp服务是否启动。
# service ntpd status
# service ntpd start
# chkconfig ntpd on
3.查看相关参数配置
Ambari UI --> HDFS --> Configs --> Advanced --> (In the search filter enter "dfs.namenode.checkpoint.period")
参考:
https://community.hortonworks.com/questions/80288/last-checkpoint-error-being-reported.html
https://www.cnblogs.com/ljy2013/p/4705537.html














 530
530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









