







Vision Transformer(ViT) 架构传统上采用基于网格的方法进行标记化,而不考虑图像的语义内容。论文提出了一种模块化的超像素非规则标记化策略,该策略将标记化和特征提取解耦,与当前将两者视为不可分割整体的方法形成了对比。通过使用在线内容感知标记化以及尺度和形状不变的位置嵌入,与基于图像块的标记化和随机分区作为基准进行了对比。展示了在提升归因的真实性方面的显著改进,在零样本无监督密集预测任务中提供了像素级的粒度,同时在分类任务中保持了预测性能。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: A Spitting Image: Modular Superpixel Tokenization in Vision Transformers

Introduction
在卷积架构之后,Vision Transformers(ViTs) 已成为视觉任务的焦点。在最初的语言模型的Transformer中,标记化是一个至关重要的预处理步骤,旨在基于预定的熵度量最佳地分割数据。随着模型被适配于视觉任务,标记化简化为将图像分割为正方形的图像块。这种方法被证明是有效的,很快成为了标准方法,成为架构的一个重要组成部分。
尽管取得了明显的成功,论文认为基于图像块的标记化存在固有的局限性。首先,标记的尺度通过固定的图像块大小与模型架构严格绑定,忽视了原始图像中的冗余。这些局限性导致在较高分辨率下计算量显著增加,因为复杂度和内存随标记数量呈平方级增长。此外,规则的分割假设了语义内容分布的固有均匀性,从而高效地降低了空间分辨率。
随后,若干研究利用注意力图来可视化类标记的归因,以提高可解释性,这常应用于密集预测任务。然而,正方形分割产生的注意力图在图像块表示中会引起分辨率的丧失,进而无法本质上捕捉原始图像的分辨率。对于像素级粒度的密集预测,需要一个单独的解码器进行放大处理。
Motivation
论文从原始的ViT架构中退一步,重新评估基于图像块的标记化的作用。通过关注架构中这个被忽视的组件,将图像分割定义为一个自适应模块化标记器的角色,这是ViTs中未被充分利用的潜力。

与正方形分割相比,超像素提供了一个机会,通过允许尺度和形状的适应性,同时利用视觉数据中的固有冗余来缓解基于图像块的标记化的缺陷。超像素已被证明与图像中的语义结构更好地对齐,这为在视觉Transformer架构中的潜在用途提供了依据。论文将标准ViTs中的经典正方形标记化与超像素标记化模型(SPiT)进行比较,并使用随机Voronoi标记化(RViT)(明确定义的数学对象,用于镶嵌平面)作为对照,后者因其作为平面镶嵌的数学对象而被选中,三种标记化方案在图1中进行了说明。
Contributions
论文的研究引出了三个具体的问题:(a)对正方形图像块的严格遵守是否必要?(b)不规则分割对标记化表示有什么影响?(c)标记化方案是否可以设计为视觉模型中的一个模块化组件?
经过实验验证,论文得到了以下结论:
Generalized Framework:超像素标记化作为模块化方案中推广到了ViTs,为视觉任务提供更丰富的Transformer空间,其中Transformer主干与标记化框架是独立的。Efficient Tokenization:提出了一种高效的在线标记化方法,该方法在训练和推理时间上具有竞争力,同时在分类任务中表现出色。Refined Spatial Resolution:超像素标记化提供了语义对齐的标记,具有像素级的粒度。与现有的可解释性方法相比,论文的方法得到更显著的归因,并且在无监督分割中表现出色。Visual Tokenization:论文的主要贡献是引入了一种新颖的方法来思考ViTs中的标记化问题,这是建模过程中的一个被忽视但核心的组成部分。
论文的主要目标是评估ViTs的标记化方案,强调不同标记化方法的内在特性。为了进行公平的比较分析,使用基础的ViT架构和既定的训练协议进行研究。因此,论文设计实验以确保与知名基线进行公平比较,且不进行架构优化。这种受控的比较对于将观察到的差异归因于标记化策略至关重要,并消除了特定架构或训练方案带来的混杂因素。
Methodology
为了评估和对比不同的标记化策略,需要对图像进行分割并从这些分割中提取有意义的特征。虽然可以使用多种深度架构来完成这些任务,但这些方法会给最终模型增加一层复杂性,从而使任何直接比较标记化策略的尝试失效。此外,这也会使架构之间的有效迁移学习变得复杂。基于这一原因,论文构建了一个有效的启发式超像素标记化器,并提出了一种与经典ViT架构一致的非侵入性特征提取方法,以便进行直接比较。
定义 H × W = { ( y , x ) : 1 ≤ y ≤ h , 1 ≤ x ≤ w } H {\mkern1mu\times\mkern1mu} W = \big\{(y, x) : 1 \leq y \leq h, 1 \leq x \leq w\big\} H×W={(y,x):1≤y≤h,1≤x≤w} 表示一个空间维度为 ( h , w ) (h, w) (h,w) 的图像的坐标,并让 I \mathcal I I 为映射 i ↦ ( y , x ) i \mapsto (y, x) i↦(y,x) 的索引集。将一个 C C C 通道的图像视为信号 ξ : I → R C {\xi\colon \mathcal I \to \mathbb R^C} ξ:I→RC ,定义向量化操作符 v e c : R d 1 × … × d n → R d 1 … d n \mathrm{vec}\colon \mathbb{R}^{d_1 {\mkern1mu\times\mkern1mu} \dots {\mkern1mu\times\mkern1mu} d_n} \to \mathbb{R}^{d_1 \dots d_n} vec:Rd1×…×dn→Rd1…dn ,并用 f ( g ( x ) ) = ( f ∘ g ) ( x ) f(g(x)) = (f \circ g)(x) f(g(x))=(f∘g)(x) 表示函数的组合。
Framework
论文通过允许模块化的标记化器和不同的特征提取方法,来对经典ViT架构进行泛化。值得注意的是,经典的ViT通常被呈现为一个由三部分组成的系统,包括一个标记嵌入器
g
g
g 、一个由一系列注意力块组成的主干网络
f
f
f ,以及一个后续的预测头
h
h
h 。实际上,可以将图像块嵌入模块重写为一个由三个部分组成的模块化系统,包含一个标记化器
τ
\tau
τ 、一个特征提取器
ϕ
\phi
ϕ 和一个嵌入器
γ
\gamma
γ ,使得
g
=
γ
∘
ϕ
∘
τ
g = \gamma \circ \phi \circ \tau
g=γ∘ϕ∘τ 。
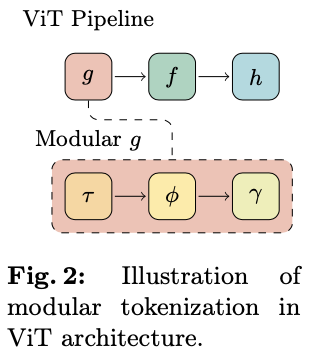
这些是原始架构中的固有组件,但在简化的标记化策略下被掩盖了。这为模型作为一个五部分系统提供了更完整的评估。
KaTeX parse error: Undefined control sequence: \label at position 2: \̲l̲a̲b̲e̲l̲{eqn:pipeline} …
其中
θ
\theta
θ 表示模型的可学习参数集合。在标准的ViT模型中,标记化器
τ
\tau
τ 将图像分割为固定大小的方形区域。这直接提供了向量化的特征,因为这些图像块具有统一的维度和顺序,因此在标准的ViT架构中,
ϕ
=
v
e
c
\phi = \mathrm{vec}
ϕ=vec 。嵌入器
γ
\gamma
γ 通常是一个可学习的线性层,将特征映射到特定架构的嵌入维度。另一种做法是,将
g
g
g 视为一个卷积操作,其卷积核大小和步幅等于所需的图像块大小
ρ
\rho
ρ 。
Partitioning and Tokenization
语言任务中的标记化需要将文本分割为最优信息量的标记,这类似于超像素将空间数据分割为离散的连通区域。层级超像素是一种高度可并行化的基于图的方法,适合用于在线标记化。基于此,论文提出了一种新方法,该方法在每一步 t t t 中进行批量图片图的完全并行聚合,此外还包括对大小和紧凑性的正则化。在每一步产生不同数量的超像素,动态适应图像的复杂性。
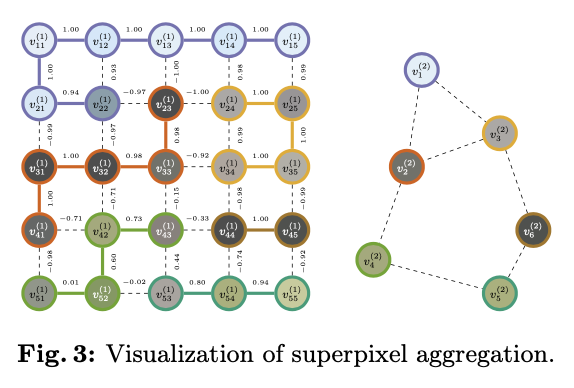
设 E ( 0 ) ⊂ I × I E^{(0)} \subset \mathcal I {\mkern1mu\times\mkern1mu} \mathcal I E(0)⊂I×I 表示在 H × W H {\mkern1mu\times\mkern1mu} W H×W 下的四向邻接边。将超像素视为一个集合 S ⊂ I S \subset \mathcal I S⊂I ,并且如果对于 S S S 中的任意两个像素 p p p 和 q q q ,存在一个边的序列 ( ( i j , i j + 1 ) ∈ E ( 0 ) ) j = 1 k − 1 \big((i_j, i_{j+1}) \in E^{(0)}\big)_{j=1}^{k-1} ((ij,ij+1)∈E(0))j=1k−1 ,使得 i 1 = p i_1 = p i1=p 和 i k = q i_k = q ik=q ,则认为 S S S 是连通的。如果对于任意两个不同的超像素 S S S 和 S ′ ∈ π S' \in \pi S′∈π ,它们的交集 S ∩ S ′ = ∅ S \cap S' = \emptyset S∩S′=∅ ,并且所有超像素的并集等于图像中所有像素位置的集合,即 ⋃ S ∈ π ( t ) S = I \bigcup_{S \in \pi^{(t)}} S = \mathcal I ⋃S∈π(t)S=I ,那么一组超像素就形成了图像的分割 π \pi π 。
设 Π ( I ) ⊂ 2 2 I \Pi(\mathcal I) \subset 2^{2^{\mathcal I}} Π(I)⊂22I 表示图像的所有分割的空间,并且有一系列分割 ( π ( t ) ) t = 0 T (\pi^{(t)})_{t=0}^T (π(t))t=0T 。如果对于 π ( t ) \pi^{(t)} π(t) 中的所有超像素 S S S ,存在一个超像素 S ′ ∈ π ( t + 1 ) S' \in \pi^{(t+1)} S′∈π(t+1) 使得 S ⊆ S ′ S \subseteq S' S⊆S′ ,则认为分割 π ( t ) \pi^{(t)} π(t) 是另分割 π ( t + 1 ) \pi^{(t+1)} π(t+1) 的细化,用 π ( t ) ⊑ π ( t + 1 ) \pi^{(t)} \sqsubseteq \pi^{(t+1)} π(t)⊑π(t+1) 来表示。目标是构造一个 像素索引的 T T T 级层级分割 H = ( π ( t ) ∈ Π ( I ) : π ( t ) ⊑ π ( t + 1 ) ) t = 0 T {\mathcal H = \big( \pi^{(t)} \in \Pi(\mathcal I) : \pi^{(t)} \sqsubseteq \pi^{(t+1)} \big)_{t=0}^T} H=(π(t)∈Π(I):π(t)⊑π(t+1))t=0T ,使得每个超像素都是连通的。
为了构造 H \mathcal H H ,通过并行边收缩(用一个顶点代替多个顶点,被代替的点的内部边去掉,外部边由代替的顶点继承)的方式逐步连接顶点,以更新分割 π ( t ) ↦ π ( t + 1 ) {\pi^{(t)} \mapsto \pi^{(t+1)}} π(t)↦π(t+1) 。通过将每个层级视为图 G ( t ) = ( V ( t ) , E ( t ) ) G^{(t)} = (V^{(t)}, E^{(t)}) G(t)=(V(t),E(t)) 来实现,其中每个顶点 v ∈ V ( t ) v \in V^{(t)} v∈V(t) 是分割 π ( t ) \pi^{(t)} π(t) 中一个超像素的索引,每条边 ( u , v ) ∈ E ( t ) (u, v) \in E^{(t)} (u,v)∈E(t) 代表在 t = 0 , … , T t = 0, \dots, T t=0,…,T 层级中相邻的超像素。因此,初始图像可以表示为一个网格图 G ( 0 ) = ( V ( 0 ) , E ( 0 ) ) {G^{(0)} = (V^{(0)}, E^{(0)})} G(0)=(V(0),E(0)) ,对应于单像素分割 π ( 0 ) = { { i } : i ∈ I } {\pi^{(0)} = \big\{\{i\} : i \in \mathcal I \big\}} π(0)={{i}:i∈I} 。
为了应用边收缩,定义一个边权重函数 w ξ ( t ) : E ( t ) → R w_\xi^{(t)}\colon E^{(t)} \to \mathbb R wξ(t):E(t)→R 。保留图中的自环(超像素包含的节点互指,合并后表现为超像素指向自身。这里保留自环是因为不一定每一次都需要加入新像素,自环权重高于其它节点时则不加),通过相对大小对自环边进行加权作为正则化器,对区域大小的方差进行约束。对于非自环边,使用平均特征 μ ξ ( t ) ( v ) = ∑ i ∈ π v ( t ) ξ ( i ) / ∣ π v ( t ) ∣ \mu_\xi^{(t)}(v) = \sum_{i \in \pi^{(t)}_v} \xi(i) / \lvert \pi^{(t)}_v \rvert μξ(t)(v)=∑i∈πv(t)ξ(i)/∣πv(t)∣ 并应用相似性函数 s i m : E ( t ) → R \mathrm{sim}\colon E^{(t)} \to \mathbb{R} sim:E(t)→R 作为权重。自环的权重使用在层级 t t t 时,区域大小的特征均值 μ ∣ π ∣ ( t ) \mu^{(t)}_{\lvert \pi \rvert} μ∣π∣(t) 和特征标准差 σ ∣ π ∣ ( t ) \sigma^{(t)}_{\lvert \pi \rvert} σ∣π∣(t) 进行加权。
整体权重计算如下:
w ξ ( u , v ) = { s i m ( μ ξ ( t ) ( u ) , μ ξ ( t ) ( v ) ) , for u ≠ v ; ( ∣ π u ( t ) ∣ − μ ∣ π ∣ ( t ) ) / σ ∣ π ∣ ( t ) , otherwise. \begin{align} w_\xi(u, v) = \begin{cases} \mathrm{sim}\Big(\mu_\xi^{(t)}(u), \mu_\xi^{(t)}(v)\Big), & \text{for $u \neq v$;} \\ \Big(\lvert \pi^{(t)}_u \rvert - \mu_{\lvert \pi \rvert}^{(t)}\Big) / \sigma_{\lvert \pi \rvert}^{(t)}, & \text{otherwise.} \end{cases} \end{align} wξ(u,v)=⎩ ⎨ ⎧sim(μξ(t)(u),μξ(t)(v)),(∣πu(t)∣−μ∣π∣(t))/σ∣π∣(t),for u=v;otherwise.
紧凑性可以通过计算无穷范数密度来选择性地进行调节:
δ ∞ ( u , v ) = 4 ( ∣ π u ∣ ( t ) + ∣ π v ∣ ( t ) ) p e r ∞ ( u , v ) 2 , \begin{equation} \delta_\infty(u, v) = \frac{4 (\lvert \pi_u \rvert^{(t)} + \lvert \pi_v \rvert^{(t)})}{\mathrm{per}_\infty(u,v)^2}, \end{equation} δ∞(u,v)=per∞(u,v)24(∣πu∣(t)+∣πv∣(t)),
其中 p e r ∞ \mathrm{per}_\infty per∞ 是包围超像素 u u u 和 v v v 的边界框的周长。这突出了两个相邻的超像素 u u u 和 v v v 在其边界框内的紧密程度,从而得出了一个正则化的权重函数。
w ξ ( t ) ( u , v ; λ ) = λ δ ∞ ( u , v ) + ( 1 − λ ) w ξ ( t ) ( u , v ) \begin{equation} w_\xi^{(t)}(u,v;\lambda) = \lambda \delta_\infty(u,v) + (1 - \lambda)w_\xi^{(t)}(u, v) \end{equation} wξ(t)(u,v;λ)=λδ∞(u,v)+(1−λ)wξ(t)(u,v)
其中 λ ∈ [ 0 , 1 ] \lambda \in [0,1] λ∈[0,1] 作为紧凑性的超参数。
使用贪婪的并行更新规则进行边收缩,使得每个超像素与具有最高边权重的相邻超像素连接,包括所有 G ( t ) G^{(t)} G(t) 中的自环,适用于 t ≥ 1 t \geq 1 t≥1 。设 N ( t ) ( v ) \mathfrak{N}^{(t)}(v) N(t)(v) 表示在第 t t t 层中索引为 v v v 的超像素的相邻顶点的邻域,构造一个中间边集:
E ^ ( t ) = ( v , arg max u ∈ N ( t ) ( v ) w ξ ( u , v ; λ ) : v ∈ V ( t ) ) . \begin{align} \hat E^{(t)} = \bigg(v, \underset{u \in \mathfrak{N}^{(t)}(v)}{\text{arg\ max}}\ w_\xi(u, v; \lambda) : v \in V^{(t)}\bigg). \end{align} E^(t)=(v,u∈N(t)(v)arg max wξ(u,v;λ):v∈V(t)).
然后,传递闭包 E ^ + ( t ) \hat E_+^{(t)} E^+(t) (传递闭包是指多个二元关系存在传递性,通过该传递性推导出更多的关系,比如可从A->B和B->C中推导出A->C,这里即是 E ^ ( t ) \hat E^{(t)} E^(t) 的连通分量)可明确地得出一个映射 V ( t ) ↦ V ( t + 1 ) {V^{(t)} \mapsto V^{(t+1)}} V(t)↦V(t+1) ,使得
π v ( t + 1 ) = ⋃ u ∈ N ^ + ( t ) ( v ) π u ( t ) , \begin{align} \pi^{(t+1)}_v = \bigcup_{u \in \hat{\mathfrak{N}}_+^{(t)}(v)} \pi^{(t)}_u, \end{align} πv(t+1)=u∈N^+(t)(v)⋃πu(t),
其中
N
^
+
(
t
)
(
v
)
\hat{\mathfrak{N}}_+^{(t)}(v)
N^+(t)(v) 表示在
E
^
+
(
t
)
\hat E_+^{(t)}
E^+(t) 中顶点
v
v
v 的连通分量。这个分区更新规则确保了在
(
t
+
1
)
(t+1)
(t+1) 层的每个分区都是一个连通区域,因为它是通过合并具有最高边权重的相邻超像素形成的,如图3中所示。
重复计算聚合映射、正则化边权重和边收缩的步骤,直到达到所需的层级数 T T T 。在每一层,分区变得更加粗糙,表示图像中更大的同质区域。层级结构提供了图像的多尺度表示,捕捉了局部和全局结构。在第 T T T 层,即可获得一系列分区 ( π ( t ) ) t = 0 T (\pi^{(t)})_{t=0}^T (π(t))t=0T ,其中每一层的分区在层级 t t t 时是一个连通区域,并且对所有 t t t 有 π ( t ) ⊑ π ( t + 1 ) {\pi^{(t)} \sqsubseteq \pi^{(t+1)}} π(t)⊑π(t+1) 。
在经典的ViT分词器中,论文尝试验证不同的
T
T
T 和图像块大小
ρ
\rho
ρ 分别产生的标记数量之间的关系。设
N
S
P
i
T
N_\mathrm{SPiT}
NSPiT 和
N
V
i
T
N_\mathrm{ViT}
NViT 分别表示SPiT分词器和ViT分词器的标记数量,这种关系为
E
(
T
∣
N
S
P
i
T
=
N
V
i
T
)
=
log
2
ρ
\mathbb{E}(T \mid N_\mathrm{SPiT} = N_\mathrm{ViT}) = \log_2 \rho
E(T∣NSPiT=NViT)=log2ρ ,无论图像大小如何。
Feature Extraction with Irregular Patches
虽然ViT架构中选择正方形图像块是出于简洁性的考虑,但这自然也反映了替代方案所带来的挑战。非规则的图像块是不对齐的,表现出不同的形状和维度,并且通常是非凸的(形状非常不规则)。这些因素使得将非规则图像块嵌入到一个共同的内积空间中变得不容易。除了保持一致性和统一的维度外,论文还提出任何此类特征需要捕捉的最小属性集;即颜色、纹理、形状、尺度和位置。
ViTs通常为图像网格中的每个图像块使用可学习的位置嵌入。论文注意到这对应于下采样图像的位置直方图,可以通过使用核化方法将可学习的位置嵌入扩展到处理更复杂的形状、尺度和位置,对每个
n
=
1
,
…
,
N
n=1,\dots,N
n=1,…,N 分区的超像素
S
n
S_n
Sn 的坐标应用联合直方图。首先,将位置归一化,使得所有
(
y
′
,
x
′
)
∈
S
n
(y', x') \in S_n
(y′,x′)∈Sn 都落在
[
−
1
,
1
]
2
[-1, 1]^2
[−1,1]2 范围内。设定固定
β
\beta
β 为每个空间方向上的特征维度,特征由高斯核
K
σ
K_\sigma
Kσ 提取:
ξ ^ n , y , x pos = v e c ( ∑ ( y j , x j ) ∈ S n K σ ( y − y j , x − x j ) ) , \begin{equation} \hat\xi^{\text{pos}}_{n,y,x} = \mathrm{vec}\Bigg(\sum_{(y_j, x_j) \in S_n} K_\sigma (y - y_j, x - x_j) \Bigg), \end{equation} ξ^n,y,xpos=vec((yj,xj)∈Sn∑Kσ(y−yj,x−xj)),
通常,带宽 σ \sigma σ 取值较低,范围为 [ 0.01 , 0.05 ] [0.01, 0.05] [0.01,0.05] 。这样,实际上就编码了图像块在图像中的位置,以及其形状和尺度。
为了将原始像素数据中的光强信息编码到特征中,使用双线性插值将每个图像块的边界框插值到固定分辨率
β
×
β
\beta {\mkern1mu\times\mkern1mu} \beta
β×β ,同时屏蔽其他周围图像块中的像素信息。这些特征本质上捕捉了原始图像块的原始像素信息,但经过重采样并缩放到统一的维度。将特征提取器
ϕ
\phi
ϕ 称为插值特征提取器,RGB特征也被归一化到
[
−
1
,
1
]
[-1, 1]
[−1,1] 并向量化,使得
ξ
^
col
∈
R
3
β
2
\hat\xi^{\text{col}} \in \mathbb{R}^{3\beta^2}
ξ^col∈R3β2 。
梯度算子提供了一种简单而稳健的纹理信息提取方法。基于改进的旋转对称性和离散化误差,论文选择使用Scharr提出的梯度算子。将该算子归一化,使得
∇
ξ
∈
[
−
1
,
1
]
H
×
W
×
2
\nabla \xi \in [-1, 1]^{H{\mkern1mu\times\mkern1mu} W{\mkern1mu\times\mkern1mu} 2}
∇ξ∈[−1,1]H×W×2 ,其中最后两个维度对应于梯度方向
∇
y
\nabla y
∇y 和
∇
x
\nabla x
∇x 。与位置特征的处理过程类似,在每个超像素
S
n
S_n
Sn 内部对梯度应用高斯核构建联合直方图,使得
ξ
^
n
grad
∈
R
β
2
\hat\xi^{\text{grad}}_n \in \mathbb{R}^{\beta^2}
ξ^ngrad∈Rβ2 。
最终特征模态被拼接为
ξ
^
n
=
[
ξ
^
n
col
,
ξ
^
n
pos
,
ξ
^
n
grad
]
∈
R
5
β
2
\hat\xi_n = [\hat\xi^{\text{col}}_n, \hat\xi^{\text{pos}}_n, \hat\xi^{\text{grad}}_n] \in \mathbb{R}^{5\beta^2}
ξ^n=[ξ^ncol,ξ^npos,ξ^ngrad]∈R5β2 。虽然论文提出的梯度特征与标准的ViT架构相同,但它们代表了额外的信息维度。因此,论文评估了包括或省略梯度特征的效果。对于那些省略这些特征的模型,即
ξ
^
n
∖
ξ
^
n
grad
=
[
ξ
^
n
col
,
ξ
^
n
pos
]
∈
R
4
β
2
\hat\xi_n \setminus \hat\xi^{\text{grad}}_n = [\hat\xi^{\text{col}}_n, \hat\xi^{\text{pos}}_n] \in \mathbb{R}^{4\beta^2}
ξ^n∖ξ^ngrad=[ξ^ncol,ξ^npos]∈R4β2 ,称该提取器
ϕ
\phi
ϕ 为不包括梯度的提取器。
Generalization of Canonical ViT
在设计上,论文的框架是对标准ViT标记化的一个概括,等同于使用固定图像块大小
ρ
\rho
ρ 和排除梯度的插值特征提取的标准图像块嵌入器。
设
τ
∗
\tau^*
τ∗ 表示一个固定图像块大小
ρ
\rho
ρ 的标准ViT标记化器,
ϕ
\phi
ϕ 表示一个排除梯度的插值特征提取器,
γ
∗
\gamma^*
γ∗ 和
γ
\gamma
γ 表示具有等效线性投影的嵌入层,其中
L
θ
∗
=
L
θ
L^*_\theta = L_\theta
Lθ∗=Lθ 。设
ξ
^
pos
∈
R
N
×
β
2
\hat\xi^{\text{pos}} \in \mathbb{R}^{N {\mkern1mu\times\mkern1mu} \beta^2}
ξ^pos∈RN×β2 表示在
τ
∗
\tau^*
τ∗ 分割下的联合直方图位置嵌入矩阵。那么,对于维度
H
=
W
=
β
2
=
ρ
2
H = W = \beta^2 = \rho^2
H=W=β2=ρ2 ,由
γ
∘
ϕ
∘
τ
∗
\gamma \circ \phi \circ \tau^*
γ∘ϕ∘τ∗ 给出的嵌入与由
γ
∗
∘
ϕ
∗
∘
τ
∗
\gamma^* \circ \phi^* \circ \tau^*
γ∗∘ϕ∗∘τ∗ 给出的标准ViT嵌入在数量上是等效的。
Experiments and Results
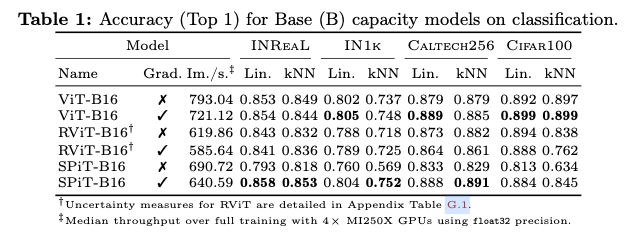
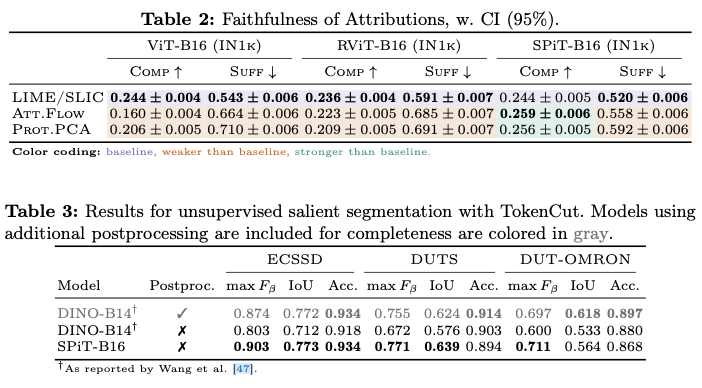



如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









