






当地时间 5 月 16 日,专注为软件工程师开发热门 AI 工具的初创企业 Windsurf,推出其首个 AI 软件工程模型家族 SWE-1。该系列不仅适用于编码,还针对完整软件工程流程进行优化。
SWE-1 家族目前涵盖三款模型:
- SWE-1:工具调用推理能力与 Claude 3.5 Sonnet 相当,但服务成本更低。付费用户可直接使用,推广期内所有用户能免费通过提示词体验。
- SWE-1-lite:作为轻量级模型,性能优于被其取代的 Cascade Base,免费及付费用户均可无限次使用。
- SWE-1-mini:以速度为优势,为所有用户在 Windsurf Tab 中提供被动体验。
此前 Windsurf 传出被 OpenAI 以 30 亿美元收购的消息,此次自研 AI 模型的发布出人意料,也标志着 Windsurf 正从单纯开发应用程序,向研发底层模型拓展。SWE-1 系列发布后,开发者 Arif 迅速用其构建了 Flutter 应用演示,并称赞 “体验极佳”。
Ian Nuttall 快速试用 Windsurf 的 SWE-1 后,分享了使用体验:该模型响应高效迅捷,执行指令干脆利落,完成任务后不会像 Cursor 那样出现卡顿情况,输出代码质量大致与 Sonnet 3.5 相当。
但他也提醒,若指令缺乏明确规则,SWE-1 容易出现 “幻觉”,例如在处理应用添加路由功能时会出现错误。因此,与 SWE-1 协作编程时,建议将功能拆解为小任务,并在初始阶段提供充足的上下文信息,以此规避 AI 陷入死循环。
Nuttall 总结道:“整体而言,多数场景下我仍更青睐 Gemini 2.5 ,不过 SWE-1 开了个好头,后续迭代值得期待。”
为什么要发布大模型
Windsurf 打造 SWE-1 的初衷,是希望将软件开发效率提升 99%。在他们看来,编码仅是软件工程的一小部分,单纯 “会写代码” 的模型无法满足全流程需求。
近年来,代码生成模型虽进步显著,从简单代码补全发展到能构建简易应用,但 Windsurf 发现其在多方面存在局限。一方面,软件开发中大量时间用于非编码工作,如终端操作、资源检索、产品测试与用户反馈处理等,模型需全面覆盖这些环节;另一方面,现有强大编码模型多聚焦代码编译与单元测试这类战术目标,而实际开发中,功能稳定性、可维护性等战略考量同样关键。以 Cascade 模型为例,它依赖用户引导,独立运行时性能衰减明显,难以应对复杂、未完成的工作状态。
Windsurf 指出:“单纯提升编码能力,不足以推动开发者和模型在软件工程领域进阶。我们的终极目标是助力工程师高效处理全流程工作,这正是研发 SWE 模型家族的初衷。”
为此,Windsurf 基于对编辑器使用场景的洞察,设计出 “共享时间线” 数据模型,并构建了涵盖未完成状态、长周期任务和多接口交互的训练体系。他们希望借此证明,即便团队规模小、计算资源有限,也能研发出具备前沿性能的模型,SWE-1 便是这一理念的初步验证成果。
SWE-1 测评:虽未“遥遥领先”但有一战之力
Windsurf 对 SWE-1 给予高度评价,称其性能 “逼近所有前沿基础模型,且超越非前沿及开放权重类模型”。为精准评估其实际效能,团队开展了离线评估与生产实验盲测。
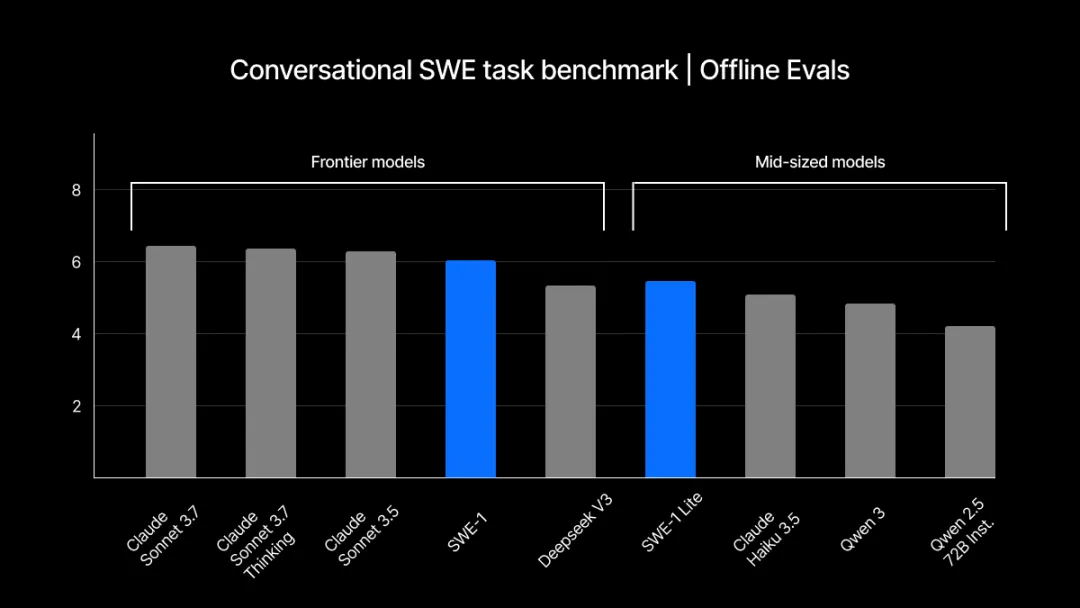
在离线评估环节,Windsurf 将 SWE-1 与 Anthropic 模型家族(Cascade 常用模型之一),以及 DeepSeek、Qwen 等领先的开放权重编码模型进行对比。测试采用对话式 SWE 任务基准,以 Cascade 会话中段、完成一半的任务为起点,考察模型对下一用户查询的处理能力。通过有用性、效率、正确性及目标文件编辑准确率等指标的混合平均得分(10 分制),量化各模型性能。
Windsurf 强调,该基准测试充分体现了 Cascade 首创的 “人机交互” 代理式编码特性。由于模型尚非尽善尽美,能否在任务半程中与用户输入自然衔接,成为衡量其实际应用价值的关键标准。
在端到端 SWE 任务基准测试中,评估从对话起始阶段展开,Cascade 运用一组精选的单元测试,判断模型达成用户输入意图的程度。最终成绩由测试通过率与评委评分的混合平均值确定(以 10 分制呈现)。
该测试聚焦于评估模型独立、完整解决问题的能力。随着模型在无人干预场景下的应用愈发广泛,此类测试所代表的用例价值正与日俱增,成为衡量模型实际效能的重要维度。
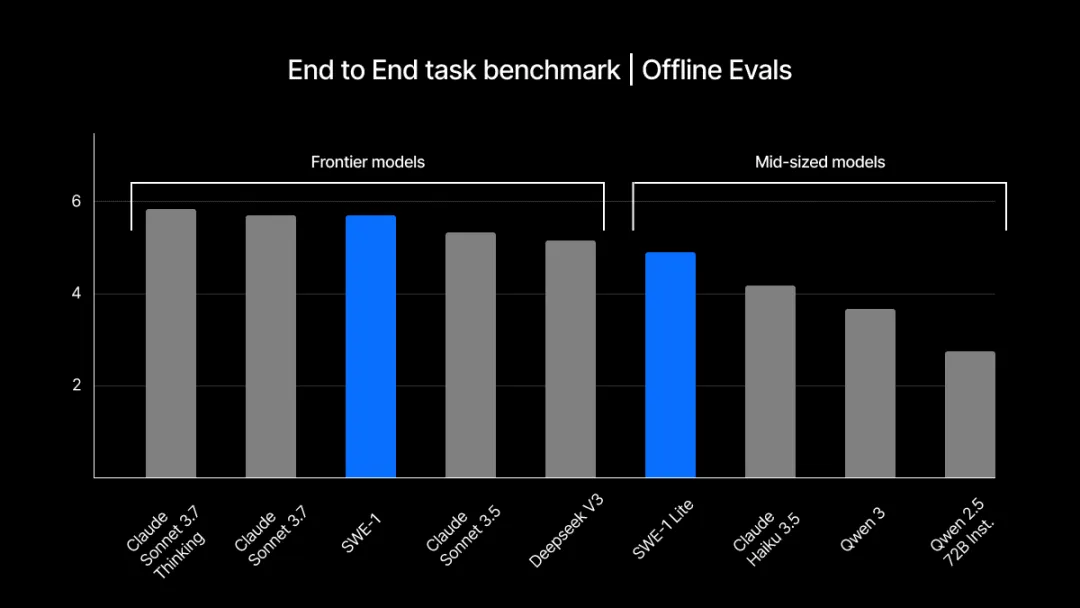
离线评估结果显示,Windsurf 发现 SWE-1 在各项任务中的表现,与头部模型实验室的前沿成果旗鼓相当,且超越了主流中型模型及前沿开放权重模型。尽管尚未达到 “绝对领先”,但 SWE-1 已具备与顶尖成果竞争的实力。
为进一步验证评估结论,坐拥庞大用户社区的 Windsurf 开展生产实验,并通过盲测方式收集数据。测试中,部分用户在不知情的情况下使用不同模型,且分配的模型在整个测试期保持不变,以便追踪用户重复使用情况。实验选取 Claude 模型作为基准,因其长期是 Cascade 中使用最频繁的模型。
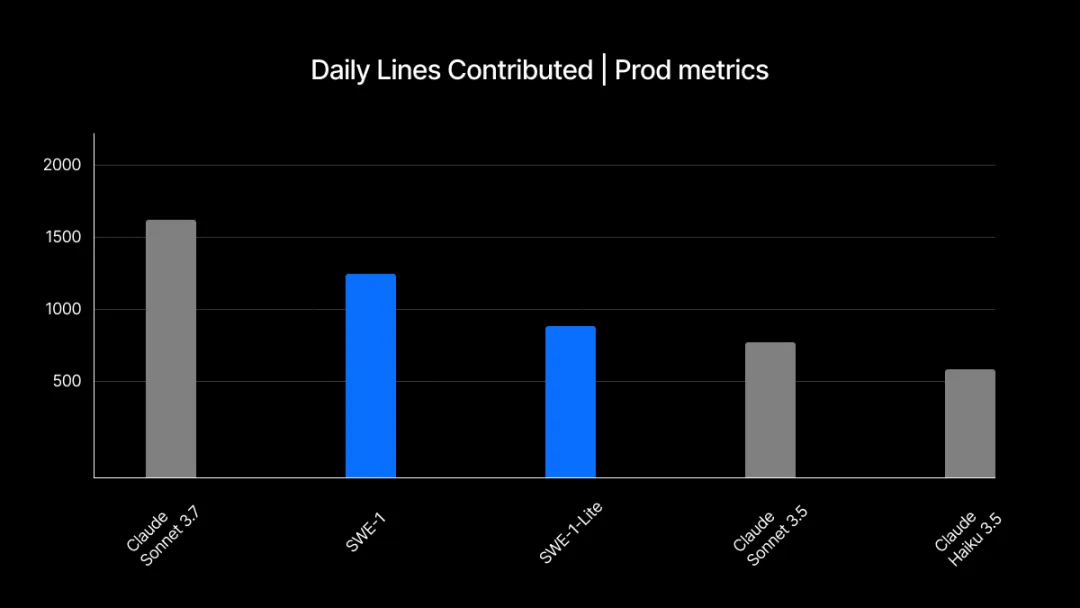
实验采用 “每用户每日贡献行数” 作为核心评估指标,即 Cascade 在固定时间内生成并被用户主动采纳保留的平均代码行数。该指标不仅能体现单次调用时模型输出的实用价值,还能反映用户持续使用意愿。Windsurf 认为,这一指标全面涵盖了模型的主动性、建议质量、输出速度及反馈响应能力,是衡量模型能否留住用户的关键依据。
Cascade 贡献率聚焦于至少经 Cascade 编辑过一次的文件,用以衡量 Cascade 生成的代码变更在文件总变更中的占比。这一指标经用户使用频率与对模型贡献代码的认可程度归一化处理,仅针对模型参与编辑的文件进行评估,能够更精准地反映用户对模型的使用频次,以及对其编辑成果的倾向性偏好,是评估模型实际应用价值的重要依据。
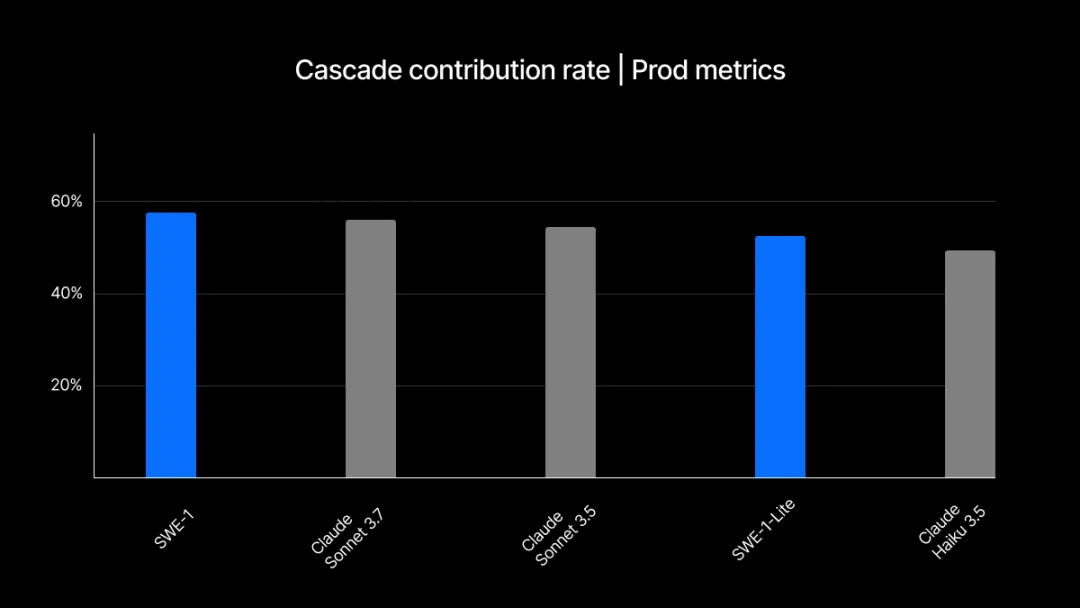
SWE-1 基于用户与 Cascade 的交互数据构建并优化,因此 Windsurf 对其在生产实验中达到行业领先水准的表现并不意外。
除 SWE-1 外,系列中的 SWE-1-lite 作为中型版本,沿用相同训练方法,将替代原 Cascade Base 模型,向所有用户开放无限次使用权限。而 SWE-1-mini 同样采用流程感知训练策略,通过缩小模型规模满足被动预测系统的低延迟要求,并针对预测操作任务定向优化,与前两者形成功能互补。
Windsurf 明确表示:“这只是起点。我们在软件工程领域的终极目标,不仅是对标其他实验室的前沿成果,更要实现超越。我们坚信达成目标的驱动力已然具备,未来将持续加大投入,深耕这一战略方向。”
Windsurf 编辑器如何赋能 SWE-1
此前,Windsurf 曾提及 “基于对 Windsurf 编辑器使用方式的观察”。在官方博文中,也阐述了该编辑器如何为 SWE-1 提供支持,以及确信自身模型能实现性能突破的原因。
Windsurf 指出,核心在于逐步迭代 “流程感知” 这一关键概念。所谓流程感知,即构建 Windsurf 编辑器旨在实现用户与 AI 综合状态间的无缝连接。AI 的操作需能被人类观测并据此行动,人类的操作同样要能被 AI 捕捉并响应。Windsurf 将这种对共享时间线的认知称为 “流程感知”,并把此类协作式智能体命名为 “AI 心流”。
为何编辑器必须支持流程感知?目前 SWE 模型尚无法独立完成所有任务,而流程感知能在过渡阶段实现正确交互 —— 既能充分发挥模型功能,又能在模型出错时让人类介入修正,随后模型基于人类的修正继续工作,且整个过程需实现无缝、自然切换。
Windsurf 表示:“我们持续关注模型在共享时间线中,有无用户干预情况下的工作步骤,以此明确模型能力边界。通过这种持续跟进,我们能了解用户最期待模型在哪些方面改进,从而快速迭代模型,让 SWE-1 达到现有水平。基于同样逻辑,我们有信心打造性能最优的 SWE 模型。”
此外,Windsurf 强调,构建共享时间线是 Cascade 设计核心功能的指导理念。Cascade 发布时,就支持用户在文本编辑器操作后,输入 “继续” 让 Cascade 自动接管,此为文本编辑器感知;之后将终端输出纳入流程感知,使 Cascade 能感知代码运行错误,即终端感知;在 Wave 4 中引入 “预览”,让 Cascade 了解用户交互的前端组件与错误类型,这是浏览器基础感知。
不仅是 Cascade,Windsurf 的所有产品都基于流程感知理念。Tab 同样遵循共享时间线概念,向 Cascade 添加上下文时也会同步至 Tab,且并非简单填充信息,而是精心构建时间线以贴合用户行动与目标。因此,Tab 在不同版本中新增了感知终端命令(Wave 5)、剪贴板内容(Wave 5)、当前 Cascade 对话(Wave 5)、IDE 内用户搜索(Wave 6)等功能。
Windsurf 称,不会盲目推出新功能,始终致力于完善软件工程中共享时间线的呈现方式。即便使用现成模型,其工具也因共享时间线信息而显著优化,如今拥有自研 SWE 模型,更能充分利用时间线推动模型发展。“我们深知自身应用程序、系统与模型协同运作的强大力量,若无广泛应用场景与基于实际活动的洞察,即便实力强劲的研究实验室也难以实现这种协同效应。”
SWE 系列模型将不断优化更新,Windsurf 表示会持续加大投入,以低成本为用户提供高性能服务。“SWE-1 由我们精简而专注的团队开发,该模型家族充分发挥了我们作为产品及基础设施厂商的优势。这是我们首次打造高质量模型,虽引以为傲,但也明白这只是开端。”


















 888
888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









